产品和工具: MongoDB Atlas、MongoDB Atlas集群、MongoDB Change Streams、MongoDB Atlas Triggers、MongoDB Spark Streaming Connector
合作伙伴: Databricks
解决方案概述
该解决方案展示了如何使用MongoDB和 Databricks构建ML 基于 的欺诈解决方案。该解决方案的主要功能包括通过与外部源集成实现的数据完整性、用于及时检测欺诈的实时处理、用于识别潜在欺诈模式的AI/ML 建模、用于即时分析的实时监控以及强大的安全措施。
该系统易于操作,并促进应用程序开发和数据科学团队之间的协作。它还支持端到端 CI/CD 管道,以确保系统最新且安全。
现有挑战
反欺诈解决方案面临以下挑战:
旧版系统的数据可见性不足:无法访问相关数据源,妨碍了欺诈模式的检测。
反欺诈系统中的延迟问题:传统系统缺乏实时处理能力,导致欺诈检测出现延迟。
旧版系统适应困难:灵活性不足阻碍了先进欺诈预防技术的采用。
旧版系统中的安全协议薄弱:过时的安全措施暴露了网络攻击的漏洞。
因技术分散导致的运营挑战:多样化的技术增加了维护和更新的复杂性。
旧版系统运营成本高昂:高昂的维护费用限制了防范欺诈的预算。
团队之间缺乏协作:孤立的工作方式导致解决方案延迟和开销增加。
以下视频概述了现有的挑战和解决方案的参考架构:
参考架构
基于 ML 的反欺诈解决方案适用于对实时处理、 AI/ML 建模、灵活性和团队之间的协作至关重要的行业。系统通过端到端 CI/CD 管道确保最新且安全的操作。该系统可应用于多个行业,包括:
金融服务:交易中的欺诈检测
电子商务:订单中的欺诈检测
医疗保健和保险:理赔中的欺诈检测
下图演示了MongoDB、 Amazon Web Services和 Databricks 如何交互以构建信用卡欺诈解决方案架构:

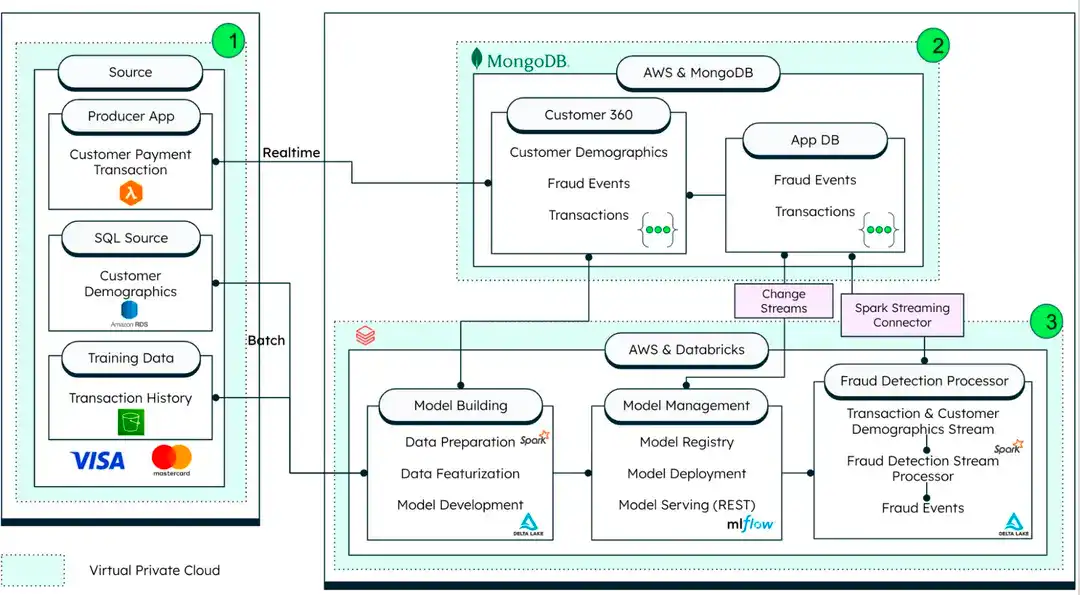
图1。银行卡欺诈解决方案架构
数据模型方法

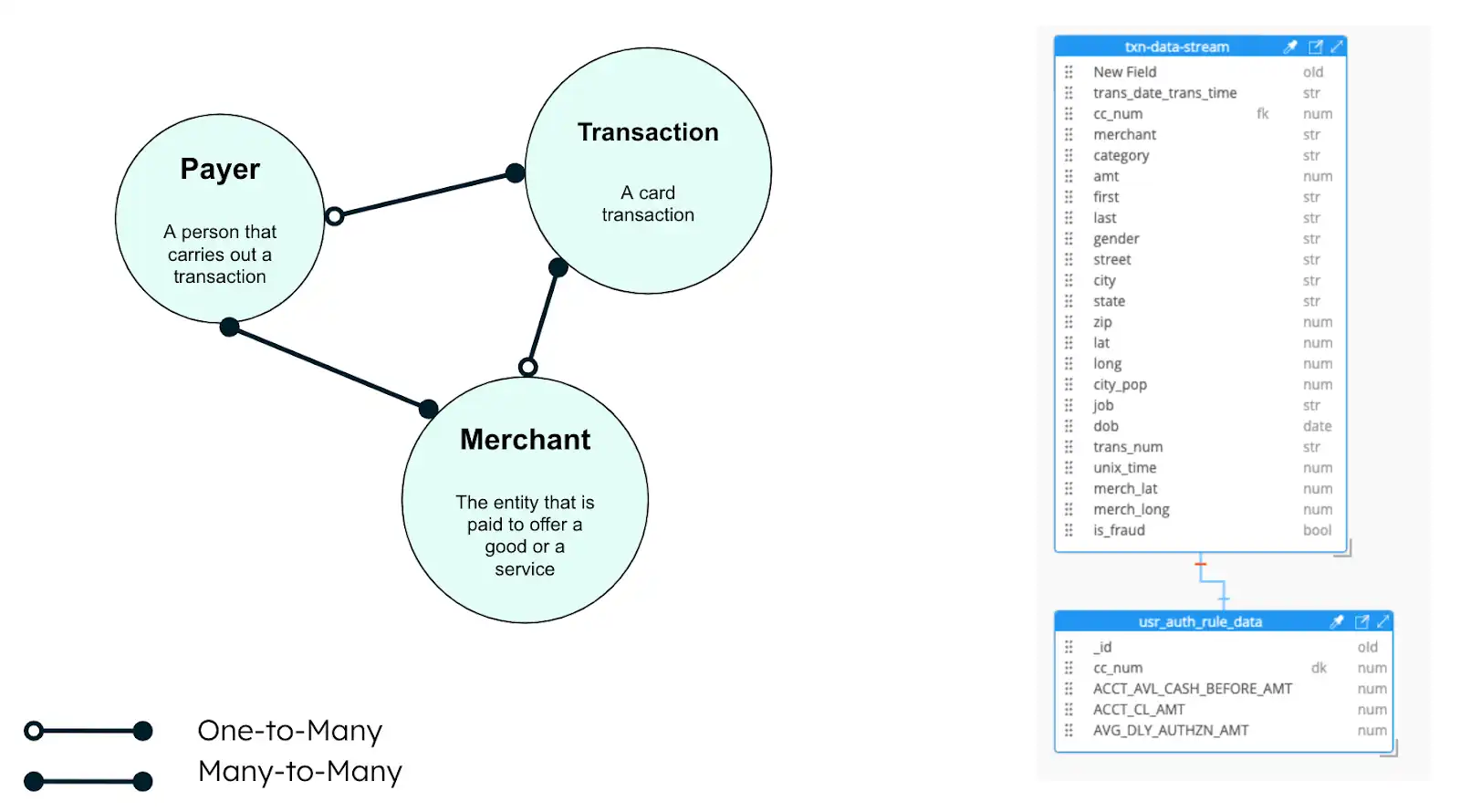
图2.银行卡欺诈解决方案数据模型
该图显示了信用交易的三个实体:
ACID 事务
商家
付款人
这三个实体使用扩展引用模式,将经常访问的相关数据字段嵌入在一起。欺诈检测应用程序将这些实体的字段包含在单个文档中。
构建解决方案
该解决方案使用以下组件:
数据源
生产者应用程序:生产者移动应用模拟实时事务的生成。
传统数据源: SQL外部数据源用于了解客户人口统计信息。
训练数据:模型培训所需的历史ACID 事务数据来自云对象存储— Amazon S3 或Microsoft Azure Blob Storage。
MongoDB Atlas:用作卡交易的操作数据存储 (ODS) 并实时处理事务。该解决方案利用MongoDB聚合框架执行应用内分析,并根据预配置的规则进程事务。它还通过原生Spark Connector与 Databricks 通信,以进行基于AI /ML 的高级欺诈检测。
Databricks:托管AI/ML 平台以补充MongoDB Atlas应用内分析。欺诈检测算法使用受 Databricks 欺诈框架MLFlow 启发的笔记本,并管理用于管理该模型的 MLOps。经过训练的模型是 REST 端点。
数据源
首先,汇总所有相关来源的数据,如上面的架构图所示。该图表使用事件驱动的架构来进程来自实时源的数据,例如生产者应用程序、 SQL数据库和历史培训数据集。
这种方法支持从ACID 事务摘要、客户人口统计和商户信息等方面获取数据。
此外,这种事件驱动架构还具有以下优点:
统一实时交易,允许实时收集卡数据事件,例如金额、位置和支付设备。
帮助重新训练监控模型,实时打击欺诈行为。
生产者应用程序是一个Python脚本,它以预定义的速率生成实时ACID 事务信息。
MongoDB 用于事件驱动、左移分析架构
MongoDB Atlas是一个有效的多云数据库平台,用于对信用卡欺诈ACID 事务进行分类。它提供了一些有用的功能,例如:
灵活的数据模型,可存储各种数据类型。
高可扩展性,满足事务需求。
高级安全功能,支持合规监管要求。
实时数据处理,实现快速、准确的欺诈检测。
基于云的部署,可将数据存储在距离客户更近的地方,并遵守当地的数据隐私法规。
MongoDB Spark Streaming Connector 集成了Apache Spark和MongoDB。由 Databricks 托管的Apache Spark允许实时处理和分析大量数据。
Change Streams 和Atlas Triggers还提供实时数据处理功能。您可以使用Atlas触发对 Databricks MLFlow框架中托管的AI /机器学习模型进行 REST 服务调用。
该示例解决方案通过存储用户定义的支付限额和用户设置数据来管理基于规则的欺诈预防。通过在调用AI/ML 模型之前使用这些规则筛选交易,可以降低预防欺诈费用。
将 Databricks 用作 AI/机器学习操作平台
Databricks 是一个AI/ML 平台,用于开发识别欺诈交易的模型。Databricks 的主要功能之一是支持现代欺诈检测系统的实时分析。
Databricks 包含 MLFlow,这是一种用于管理端到端机器学习生命周期的工具。MLFlow 允许用户追踪实验、重现结果和扩展部署模型,从而更轻松地管理复杂的机器学习工作流程。
MLFlow 还提供针对性能和调试的模型可观测性。这包括访问权限模型指标和日志,以随着时间的推移提高模型的准确性。这些功能还支持基于AI/ML 的现代欺诈检测系统的设计。
关键要点
采用MongoDB和 Databricks 的基于机器学习的欺诈解决方案可为您提供以下功能:
数据完整性:与外部来源集成,以确保数据分析的准确性。
实时处理:能及时检测欺诈活动。
AI/机器学习建模:识别潜在的欺诈模式和行为。
实时监控:允许即时进行数据处理和分析。
模型可观测性:确保对欺诈模式的全面可见性。
灵活性和可扩展性:满足不断变化的业务需求。
强大的安全措施: 防止潜在的安全漏洞。
易于操作:降低操作复杂性。
应用程序与数据科学团队的协作:统一目标并促进协作。
端到端 CI/CD 管道支持:确保系统保持最新且安全。
作者
Shiv Pullepu,MongoDB
Luca Napoli,MongoDB
Ashwin Gangadhar,MongoDB
Rajesh Vinayagam,MongoDB