企业制定灾难恢复计划至关重要。我们强烈建议您准备一份全面的灾难恢复 (DR) 计划,其中包括以下内容:
您指定的恢复点目标 (RPO)
您指定的恢复时间目标 (RTO)
促进实现这些目标的自动化流程
使用此页面上的建议来准备和应对灾难。
如需进一步了解有助于灾难恢复的主动高可用性配置,请参见 Atlas 高可用性建议。
Atlas 灾难恢复功能
要了解支持灾难恢复的 Atlas 功能,请参阅 Atlas 架构中心的以下页面:
Atlas 灾难恢复建议
使用以下灾难恢复建议为您的组织创建 灾难恢复计划。这些建议提供了在发生灾难事件时应采取的步骤的信息。
您必须定期(最好每季度一次,但至少每半年一次)测试本节中的计划。测试通常有助于企业数据库管理 (EDM)团队做好应对灾难的准备,同时也有助于保持说明为最新。
某些灾难恢复测试可能要求执行 EDM 用户无法执行的操作。在这些情况下,请至少在计划运行测试练习之前一周打开支持案例,以便执行人为中断。
下图比较了不同的灾难恢复场景和部署配置。该表显示了每种配置的恢复时间目标(RTO) 和恢复点目标(RPO) 优势与部署复杂性和费用的相对比。请注意,副本集选举(自动故障转移)不会导致数据丢失,而从备份恢复可能会丢失一些数据,具体取决于备份频率。“控制平面故障”是指Atlas管理基础架构的问题,而不是数据节点的问题。

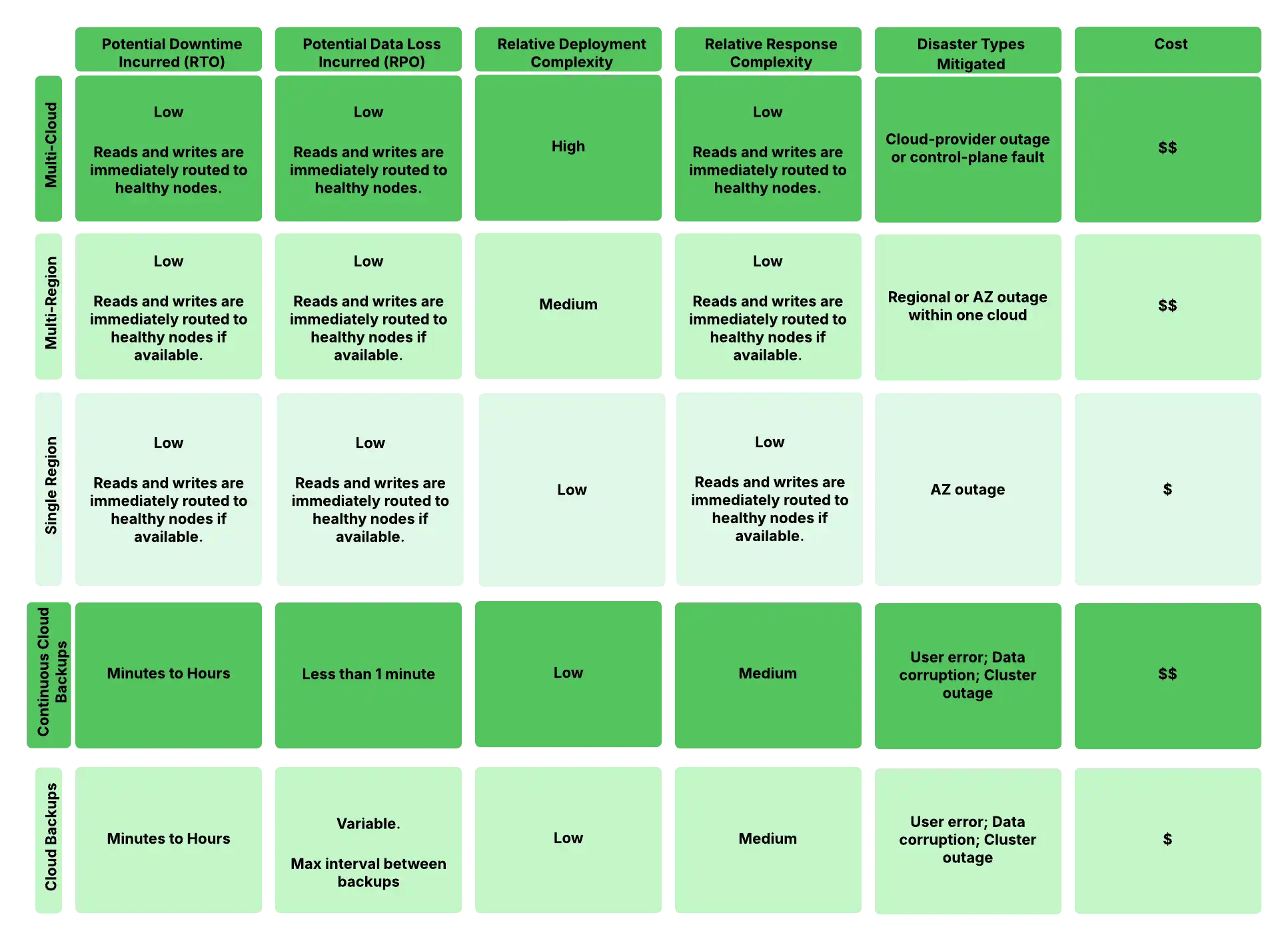
图 1。灾难恢复配置复杂性和 RTO/RPO 权衡。
每个可部署 Atlas 集群的云提供商都提供默认的数据冗余,有助于缓解任何服务中断:
AWS 将对象存储在 AWS 区域中至少三个可用区域的多个设备上。
Microsoft Azure 使用本地冗余存储 (LRS),可在选定区域的单个数据中心内将您的数据复制 3 次。
Google Cloud 将您的数据分布在备份区域的多个区域内。
为了增强您的灾难恢复能力,您可以将 Atlas 配置为在其他区域自动创建快照和 oplog 的副本。这可以确保即使主节点区域发生服务中断,您也可以使用存储在其他区域的快照副本恢复集群。
Atlas可根据区域可用性选择最高效的选项,从而优化恢复速度;如果恢复到这些副本所在的区域,则使用复制的快照。此外,如果由于服务中断而无法访问原始快照,Atlas将使用最近的可用快照副本恢复,从而最大限度地减少停机时间并提高恢复韧性。要学习,了解详情,请参阅 导出云备份快照。
多区域和多云部署通过将集群节点分布在不同的地理位置或云提供商来提供增强的灾难恢复功能。这种分布有助于确保如果一个区域或云提供商遇到服务中断,您的应用程序可以使用未受影响位置的节点继续运行。
配置多区域或多云部署时,请确保备份策略考虑了部署的分布式性质,包括根据特定恢复要求设置适当的备份保留期。
所有部署范式建议
以下建议适用于所有部署范式。
本节介绍以下灾难恢复过程:
单节点中断
如果您的副本集中的单个节点因部分区域性服务中断而发生故障,只要遵循最佳实践,您的部署仍应能够正常运行。如果您从从节点读取,当从节点发生故障时,您可能会遇到性能下降或潜在的服务中断,因为集群在此时由于负载增加而资源不足。
您可以使用Atlas用户界面的“测试主节点 (primary node in the replica set)节点故障转移”功能或“测试故障转移Atlas Administration API”端点在Atlas中测试主节点中断。
区域中断
在发生区域性服务中断事件时,多区域集群将自动进行选举,并在必要时识别新的主节点。这种拓扑结构更改将自动通知应用程序,以便执行必要的更正操作。为了在区域性服务中断事件中保持应用程序的正常运行时间,您的应用程序本身也必须采用多区域拓扑结构进行部署。此要求扩展到包括您的应用程序可能集成的任何第三方服务。要了解更多信息,请参阅多区域部署范式。
如果单地区中断或多区域中断导致集群状态下降,请执行以下步骤:
将节点添加到您识别的区域
在不太可能受到中断原因影响的区域中添加正常状态所需的节点数。
要在服务中断期间通过添加区域或节点重新配置副本集,请参阅在区域服务中断期间重新配置副本集。
您可以使用Atlas用户界面的模拟停电功能或启动停电模拟Atlas Administration API端点来测试Atlas中的地区停电。
云提供商服务中断
With multi-cloud clusters, you can select electable nodes across cloud providers to maintain high availability. Should the provider in which your primary node is deployed become unavailable, Atlas automatically elects new primary nodes to ensure continuous operation. For example, you can create electable nodes on AWS, Google Cloud, and Microsoft Azure to ensure that if one cloud provider experiences an outage, an electable node on a separate provider can automatically take over as your cluster's primary node. To learn more, see Multi-Cloud Deployment Paradigm.
大多数多区域 Atlas 集群会在单个区域服务中断后自动恢复。要了解更多信息,请参阅高可用性部分和多区域部署页面。如果区域性服务中断导致大多数节点瘫痪,您必须确定还需要增加多少节点才能使大多数节点恢复正常。
在极不可能发生的整个云提供商不可用的情况下,请按照以下步骤使部署重新上线:
确定要部署新集群的替代云提供商
有关云提供商列表和信息,请参阅云提供商。
如果您在多个云提供商之间存储备份,由于云提供商服务中断意味着存储在主节点上的任何备份都不可用,请查找在服务中断开始之前拍摄的集群的最新可用快照。
要了解如何查看备份快照,请参阅查看 M10+ 备份快照。
将上一步的最新快照恢复到新的集群中
要学习;了解如何恢复快照,请参阅恢复集群。
将连接到旧集群的所有应用程序切换到新创建的集群
要查找新的连接字符串,请参阅通过驱动程序连接。请查看应用程序堆栈,因为您可能需要将其重新部署到新的云提供商上。
Atlas中断
在极不可能发生的 Atlas 控制平面和 Atlas 用户界面不可用的情况下,您的 Atlas 集群仍然可用且可访问。要了解更多信息,请参阅平台 Reliability。打开高优先级支持工单,进一步调查此问题。
资源容量问题
规划不善或意外的数据库流量可能会导致计算资源(如磁盘空间、RAM 或 CPU)容量问题。这种行为可能不是由灾难引起的。
如果计算资源达到最大分配量并导致灾难,请遵循以下步骤:
资源故障
重要
这是一个临时解决方案,旨在缩短整个系统的停机时间。解决根本的问题后,将新创建集群中的数据合并到原始集群,并将所有应用程序点原始集群。
如果计算资源发生故障并导致您的集群不可用,请遵循以下步骤:
删除生产数据
由于人为错误或在数据库上构建的应用程序中的漏洞,生产数据可能会被意外删除。如果集群本身被意外删除,Atlas可能会暂时保留该卷。
如果集合或数据库的内容已被删除,请按照以下步骤恢复您的数据:
创建集合或数据库当前状态的副本(如果其中包含任何数据)
您可以使用mongoexport创建副本。
恢复您的数据
如果删除发生在过去 72 小时内,并且您已配置连续备份,请使用给定时间点 (PIT) 恢复,从删除发生之前的时间点进行恢复。
如果删除操作并非发生在过去 72 小时内,则将删除操作发生之前的最新备份恢复到集群中。
要学习;了解更多信息,请参阅恢复集群。
如果您创建了数据副本,请导入您导出的新数据
您可以使用 mongoimport 与更新或插入模式来导入数据,并确保在集合或数据库中正确反映任何已修改或添加的数据。
驱动程序故障
如果驱动程序出现故障,请按照以下步骤操作:
数据损坏
重要
这是一个临时解决方案,旨在缩短整个系统的停机时间。解决根本的问题后,将新创建集群中的数据合并到原始集群,并将所有应用程序点原始集群。
如果底层数据损坏,请遵循以下步骤:
将最新备份恢复到新创建的集群
要学习;了解如何恢复快照,请参阅恢复集群。