注意
Atlas 当前仅在位于美国的 AWS 区域作为知识库提供。
您可以使用MongoDB Atlas作为Amazon Bedrock 的 知识库 来构建生成式AI应用程序、实现检索增强生成 (RAG) 以及构建代理。
Overview
Amazon Bedrock 知识库与 Atlas 的集成支持以下使用案例:
将基础模型与MongoDB Vector Search 结合使用来构建AI应用程序并实现RAG。要开始使用,请参阅入门。
使用MongoDB Vector Search 和MongoDB Search 对您的知识库启用混合搜索。要学习;了解更多信息,请参阅 使用Amazon Bedrock 和Atlas 的混合搜索。
开始体验
本教程演示如何开始将MongoDB Vector Search 与Amazon Bedrock 结合使用。具体来说,您执行以下操作:
将自定义数据加载到 Amazon S3 存储桶中。
(可选)使用 AWS PrivateLink 配置端点服务。
对数据创建MongoDB Vector Search索引。
在 Atlas 上创建知识库以存储数据。
创建一个使用MongoDB Vector Search实现RAG 的代理。
背景
Amazon Bedrock 是一项用于构建生成式人工智能应用程序的完全托管服务。通过此项服务,您可以利用来自不同 AI 公司的基础模型 (FM) 作为单个 API。
您可以使用MongoDB Vector Search 作为Amazon Bedrock 的知识库,以便在Atlas中存储自定义数据,并创建代理来实现RAG 并回答有关数据的问题。要学习;了解有关RAG的更多信息,请参阅使用MongoDB进行检索增强生成 (RAG)。
先决条件
如要完成本教程,您必须具备以下条件:
运行 MongoDB 版本 6. 0. 11、7. 0. 2 或更高版本的 Atlas M 10+ 集群。
包含 Atlas 集群凭证的 AWS 账户,该账户有一个秘密。
加载自定义数据
如果您还没有包含文本数据的 Amazon S 3 存储桶,请创建一个新的存储桶并加载以下有关 MongoDB 最佳实践的可公开访问的 PDF:
下载 PDF。
导航至 MongoDB 最佳实践指南。
单击 Read Whitepaper 或 Email me the PDF,即可访问 PDF。
下载并在本地保存 PDF。
配置端点服务
默认下, Amazon Bedrock 通过公共互联网连接到您的知识库。为了进一步保护您的连接, MongoDB Vector Search 支持通过AWS PrivateLink 端点服务通过虚拟网络连接到您的知识库。
(可选)完成以下步骤,启用连接到 AWS PrivateLink 私有端点的 Atlas 集群的端点服务:
在 Atlas 中设置私有端点。
按照步骤为您的 Atlas 集群设置 AWS PrivateLink 私有端点。确保使用描述性的 VPC ID 来标识您的私有端点。
要了解更多信息,请参阅了解 Atlas 中的私有端点。
配置端点服务。
MongoDB 和合作伙伴提供了一个云开发工具包 (CDK),您可以使用它来配置由网络负载均衡器支持的端点服务,将流量转发到您的私有端点。
按照 CDK GitHub 存储库所指定的步骤准备和运行 CDK 脚本。
创建MongoDB Vector Search 索引
在本部分中,您将通过在集合上创建MongoDB Vector Search索引,将Atlas设立为向量数据库(也称为向量存储) 。
必需的访问权限
要创建MongoDB Vector Search索引,您必须对Atlas项目拥有Project Data Access Admin或更高访问权限。
步骤
在Atlas中,转到项目的 Data Explorer 页面。
如果尚未显示,请从导航栏上的 Organizations 菜单中选择包含项目的组织。
如果尚未显示,请从导航栏的 Projects 菜单中选择您的项目。
在侧边栏中,单击 Database 标题下的 Data Explorer。
显示数据浏览器。
在Atlas中,转到集群的 Search & Vector Search 页面。
您可以从 Search & Vector Search 选项或 Data Explorer go 到 MongoDB搜索页面。
如果尚未显示,请从导航栏上的 Organizations 菜单中选择包含项目的组织。
如果尚未显示,请从导航栏的 Projects 菜单中选择您的项目。
在侧边栏中,单击 Database 标题下的 Search & Vector Search。
如果没有集群,则请单击 Create cluster 来创建一个。要了解更多信息,请参阅创建集群。
如果您的项目有多个集群,请从 Select cluster 下拉列表中选择要使用的集群,然后单击 Go to Search。
开始您的索引配置。
在页面上进行以下选择,然后单击 Next。
Search Type | 选择 Vector Search 索引类型。 |
Index Name and Data Source | 指定以下信息:
|
Configuration Method | For a guided experience, select Visual Editor. To edit the raw index definition, select JSON Editor. |
重要提示:
默认下, MongoDB Search索引名为 default。如果保留此名称,则该索引将是任何未在运算符中指定其他 index 选项的MongoDB搜索查询的默认搜索索引。如果您要创建多个索引,我们建议您在所有索引之间保持一致的描述性命名约定。
定义MongoDB Vector Search索引。
此 vectorSearch 类型索引定义可对以下字段编制索引:
embedding字段作为向量类型。embedding字段包含使用您在配置知识库时指定的嵌入模型创建的向量嵌入。索引定义指定了1024个向量维度,并使用cosine来衡量相似性。bedrock_metadata、bedrock_text_chunk和x-amz-bedrock-kb-document-page-number字段作为 filter 类型,用于预过滤数据。配置知识库时,您也需在 Amazon Bedrock 中指定这些字段。
注意
如果您之前使用过滤器字段 page_number 创建了索引,则必须更新索引定义以使用新的过滤器字段名称 x-amz-bedrock-kb-document-page-number。Amazon Bedrock 已更新字段名称,使用旧字段名称的索引不再能与 Amazon Bedrock 知识库正常工作。
指定 embedding 作为索引字段,并指定 1024 个维度。
要配置该索引,请执行以下操作:
从 Similarity Method 下拉列表中选择 Cosine。
在 Filter Field 部分,指定
bedrock_metadata、bedrock_text_chunk和x-amz-bedrock-kb-document-page-number字段以按它们来过滤该数据。
在 JSON 编辑器中粘贴以下索引定义:
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
创建知识库
在本节中,您将创建一个知识库,以便将自定义数据加载到向量存储中。
将 Atlas 连接到知识库。
在 Vector database 部分,选择 Use an existing vector store。
选择 MongoDB Atlas 并配置以下选项:
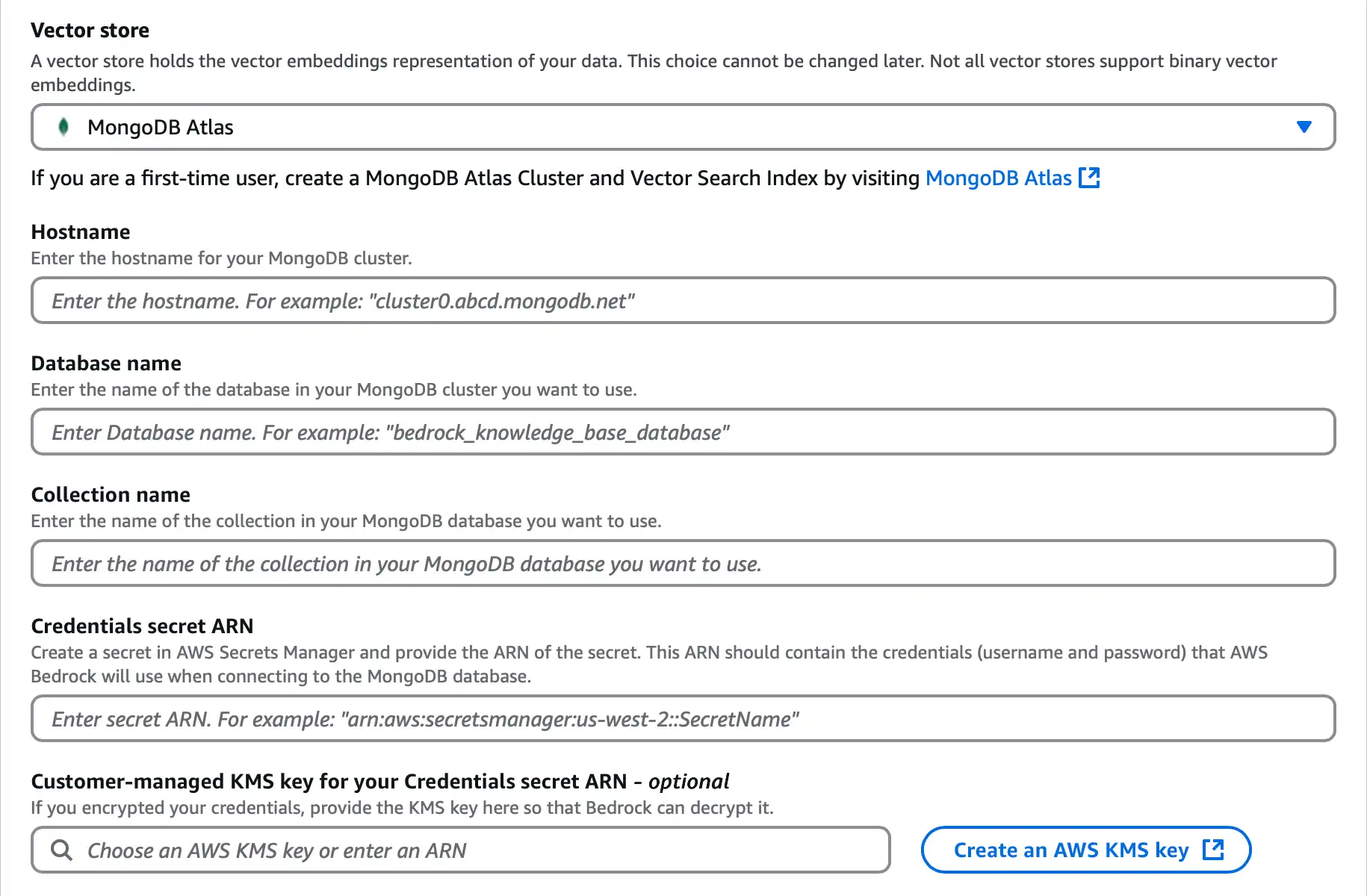
![Amazon Bedrock 矢量存储配置部分的屏幕截图。]() 点击放大
点击放大在Hostname 中,输入 Atlas 集群连接字符串中的 URL。该主机名使用以下格式:
<clusterName>.mongodb.net 对于 Database name,输入
bedrock_db。对于 Collection name,输入
test。对于 Credentials secret ARN,输入包含 Atlas 集群凭证的密钥的 ARN。要了解更多信息,请参阅 AWS Secrets Manager 概念。
在 Metadata field mapping 部分中,配置以下选项,以确定Atlas用于嵌入和存储数据源的MongoDB Vector Search索引和字段名称:
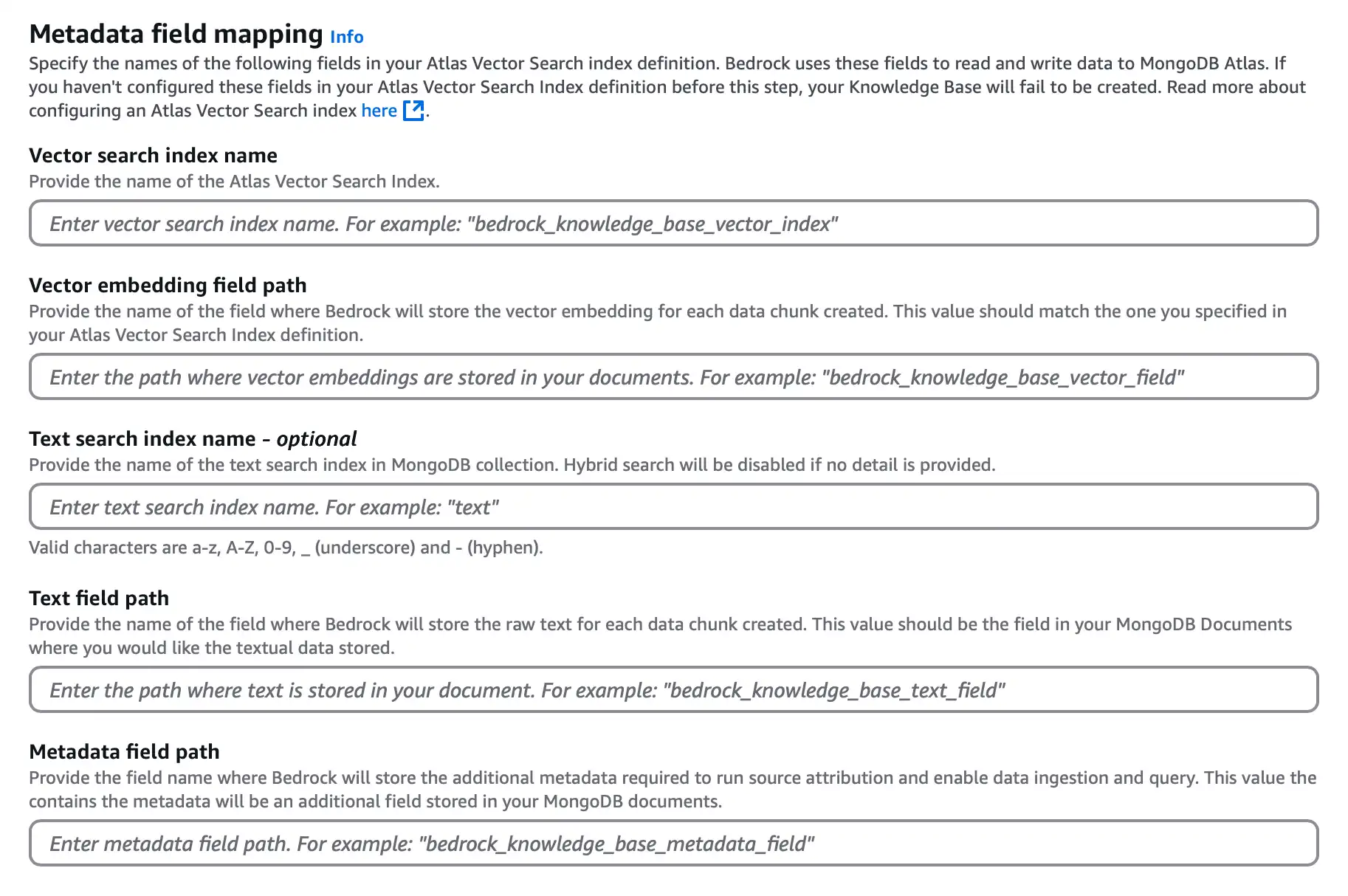
![矢量存储字段映射配置部分的截图。]() 点击放大
点击放大对于 Vector search index name,输入
vector_index。对于 Vector embedding field path,输入
embedding。对于 Text field path,输入
bedrock_text_chunk。对于 Metadata field path,输入
bedrock_metadata。
注意
或者,您可以指定 Text search index name 字段来配置混合搜索。要了解更多信息,请参阅使用 Amazon Bedrock 和 Atlas 进行混合搜索。
如果您 配置了端点服务,请输入 PrivateLink Service Name。
单击 Next(连接)。


同步数据源。
Amazon Bedrock 创建知识库后,会提示您同步数据。在 Data source 部分,选择数据源并单击 Sync,同步 S3 存储桶中的数据并将其加载到 Atlas 中。
同步完成后,如果您使用的是Atlas ,则可以导航到Atlas用户用户界面中的 bedrock_db.test命名空间,以验证向量嵌入。
构建代理
在本部分中,您部署一个代理,该代理使用MongoDB Vector Search 来实现RAG并回答有关数据的问题。当您提示此代理时,它会执行以下操作:
连接到知识库,访问存储在 Atlas 中的自定义数据。
使用MongoDB Vector Search 根据提示从向量存储中检索相关文档。
利用 AI 聊天模型,根据这些文档生成情境感知响应。
完成以下步骤以创建和测试RAG代理:
测试该代理。
单击 Prepare 按钮。
单击Test 。 Amazon BedRock 会在助手详细信息的右侧显示一个测试窗口(如果尚未显示)。
在测试窗口中,输入提示。该代理会提示模型,使用MongoDB Vector Search检索相关文档,然后根据这些文档生成响应。
如果使用了示例数据,请输入以下提示。 生成的响应可能会有所不同。
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] 提示
单击代理响应中的注释,查看MongoDB Vector Search 检索到的文本数据块。
其他资源
要排除故障,请参阅 Amazon Bedrock 知识库集成故障排除。