Esta página explora os resultados do nosso benchmark de desempenho do MongoDB Vector Search .
Resumo dos resultados
Em 15.3vetores M usando
voyage-3-largeincorporações em 2048 dimensões, o MongoDB Vector Search com quantização configurada retém 90-95% de precisão com < 50latência de consulta ms.A quantização binária é mais lenta quando o número de candidatos solicitados está na casa das centenas, devido ao custo adicional de rescoring com vetores de fidelidade total. No entanto, a ~1/4 do preço de servir o índice, pode ser uma opção preferível para muitas cargas de trabalho em grande escala.
Recomendamos mais de 1024 dimensões ao executar cargas de trabalho maiores com quantização.
Os filtros seletivos podem melhorar ou piorar o desempenho dependendo do valor selecionado para
numCandidates.O custo adicional da rescoring para quantização binária se manifesta na redução da taxa de transferência ao executar cargas de trabalho altamente concorrentes.
A fragmentação melhora ligeiramente a taxa de transferência, mas ainda recomendamos o dimensionamento do número de nós de pesquisa ou o número de núcleos disponíveis em um nó de pesquisa para melhorar a taxa de transferência.
Análise de recuperação e latência no benchmark multidimensional
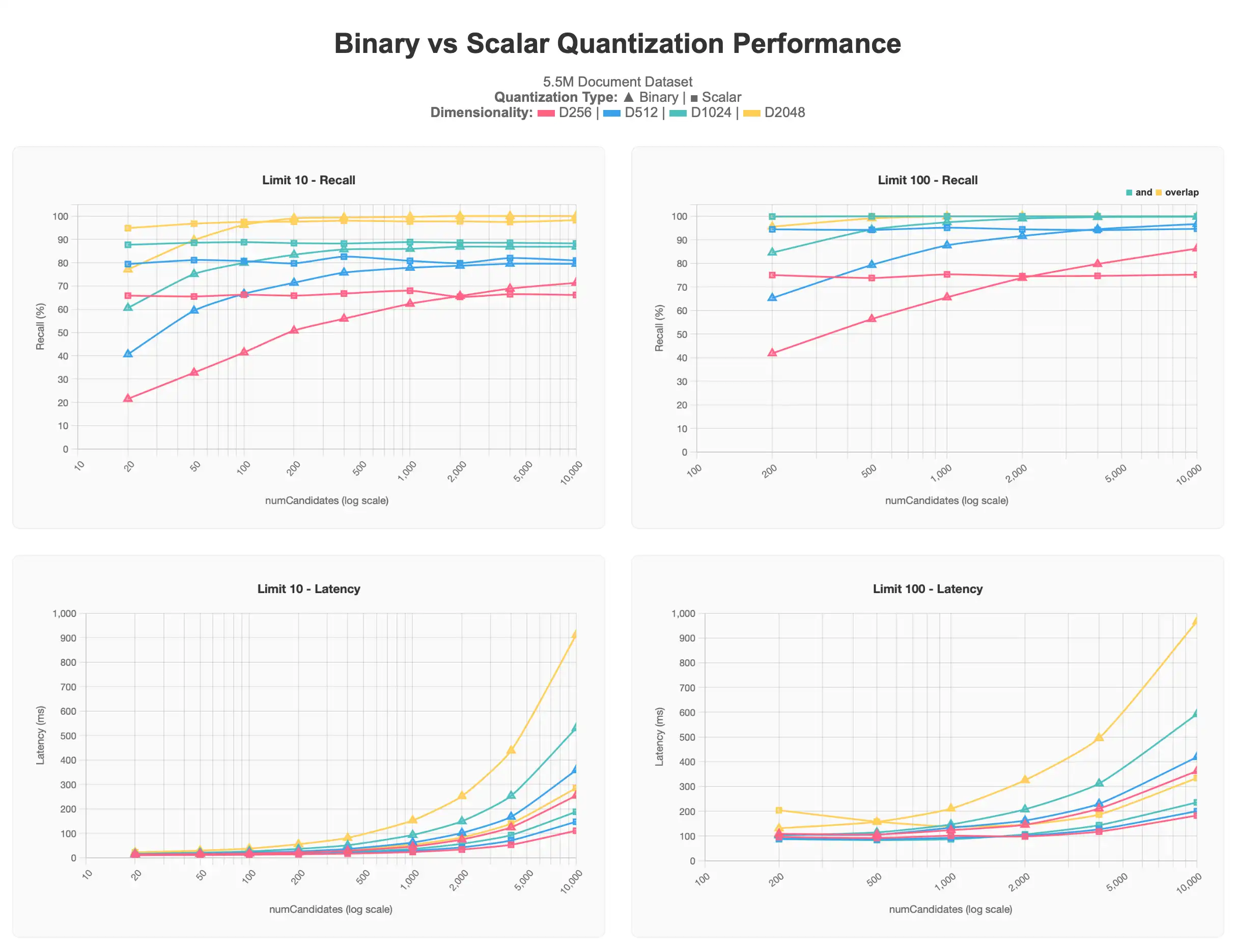
O primeiro conjunto de resultados mostra os testes que executamos em um conjunto de dados de 5,5 mi documentos contendo múltiplas dimensionalidades de vetores (256, 512, 1024, 2048), todos produzidos usando voyage-3-large em cada documento.

Para ver o gráfico completo, consulte o artefato laudo.
Todos os resultados quantizados escalares começam em níveis mais altos do que os resultados quantizados binários, mas permanecem em seu nível assintético mesmo com o aumento de numCandidates. Por outro lado, as queries quantizadas binárias produzem resultados mais precisos à medida que mais numCandidates são solicitadas, abordando a assíntota da quantização escalar e, em alguns casos, passando-a, ao custo de maior latência, especialmente acima de numCandidates de 1000.
Geralmente, valores mais baixos de limit são mais difíceis de se aproximar de 100% de precisão devido à dificuldade na identificação dos principais resultados. Muitas vezes, é preciso ter numCandidates mais altos para alcançar resultados melhores. Isso é particularmente observável no gráfico de quantização binária. Também podemos observar que vetores de dimensões inferiores 256d e 512d sofrem particularmente em grande escala com qualquer forma de quantização. 256d nunca excede 70% de recall e 512d nunca excede 80% de recall nos testes de limite 10, com limite 100 exigindo valores mais altos numCandidates para alcançar a zona alvo de 90–95%.
Com essas informações, determinamos que, ao trabalhar com um grande conjunto de dados, é recomendável ter uma dimensionalidade de pelo menos 1024d e aplicar a quantização para dimensionar, em vez de ter uma dimensionalidade mais baixa e não usar a quantização, sendo a quantidade de vetores solicitados para o caso de uso também um fator.
Resultados de benchmark maiores
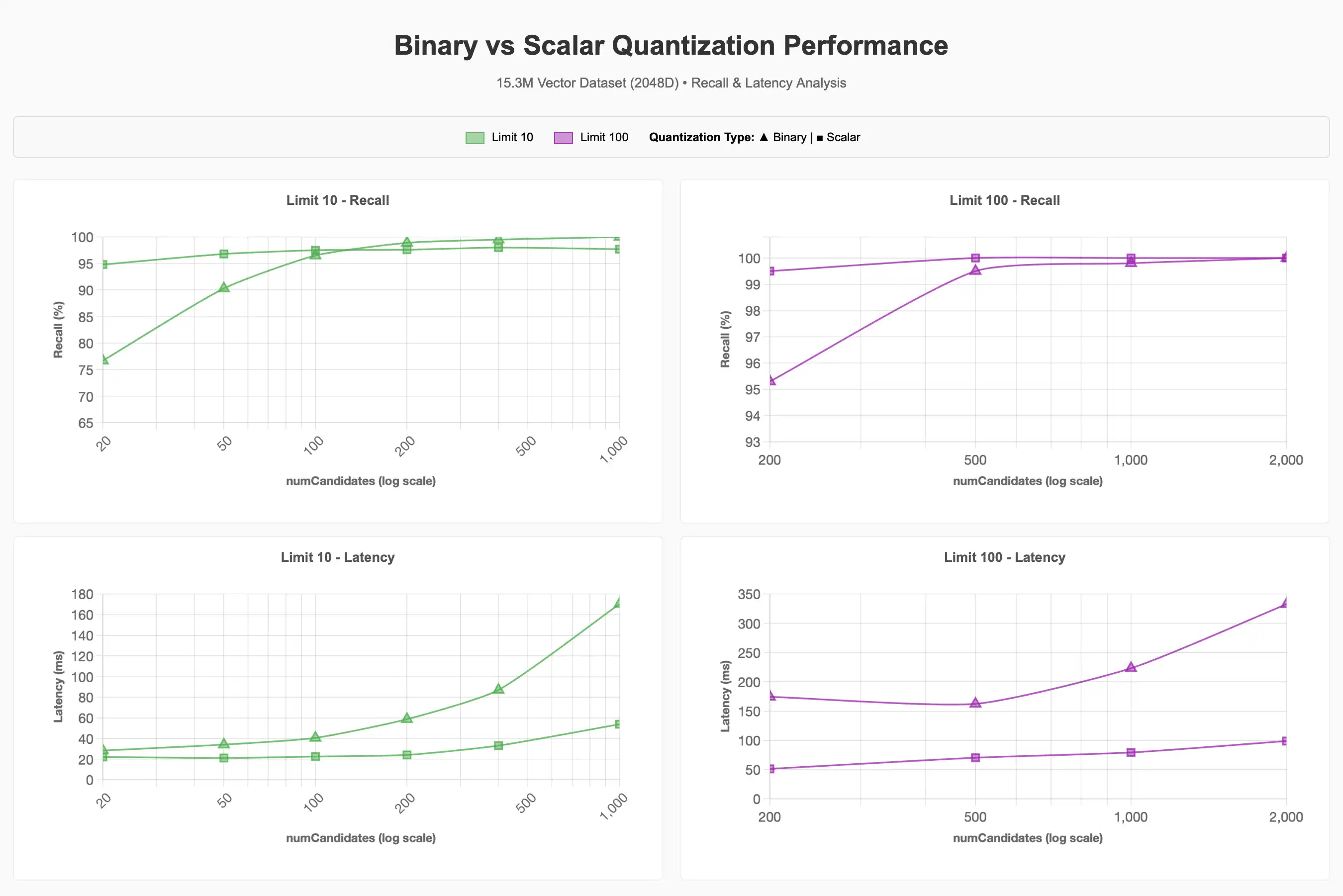
Para o maior conjunto de dados vetoriais de 15,3 milhões, fixamos a dimensionalidade em 2048d e examinamos o impacto da quantização, filtro e simultaneidade no desempenho. Escolhemos fixar em 2048d com base nos resultados do conjunto anterior de testes, que mostraram que dimensões maiores mantiveram a recuperação de modo mais favorável, embora 1024d provavelmente teria servido igualmente bem para atingir a meta de recuperação de 90-95%.
Análise de recall e latência
Observamos que é necessário significativamente mais numCandidates ao utilizar a quantização binária para alcançar a meta de recall de 90–95% em comparação com a linha de base. Valores mais altos de numCandidates geralmente significam maior latência, mas isso pode variar.

Para ver o gráfico completo, consulte o artefato Class.
Filtragem
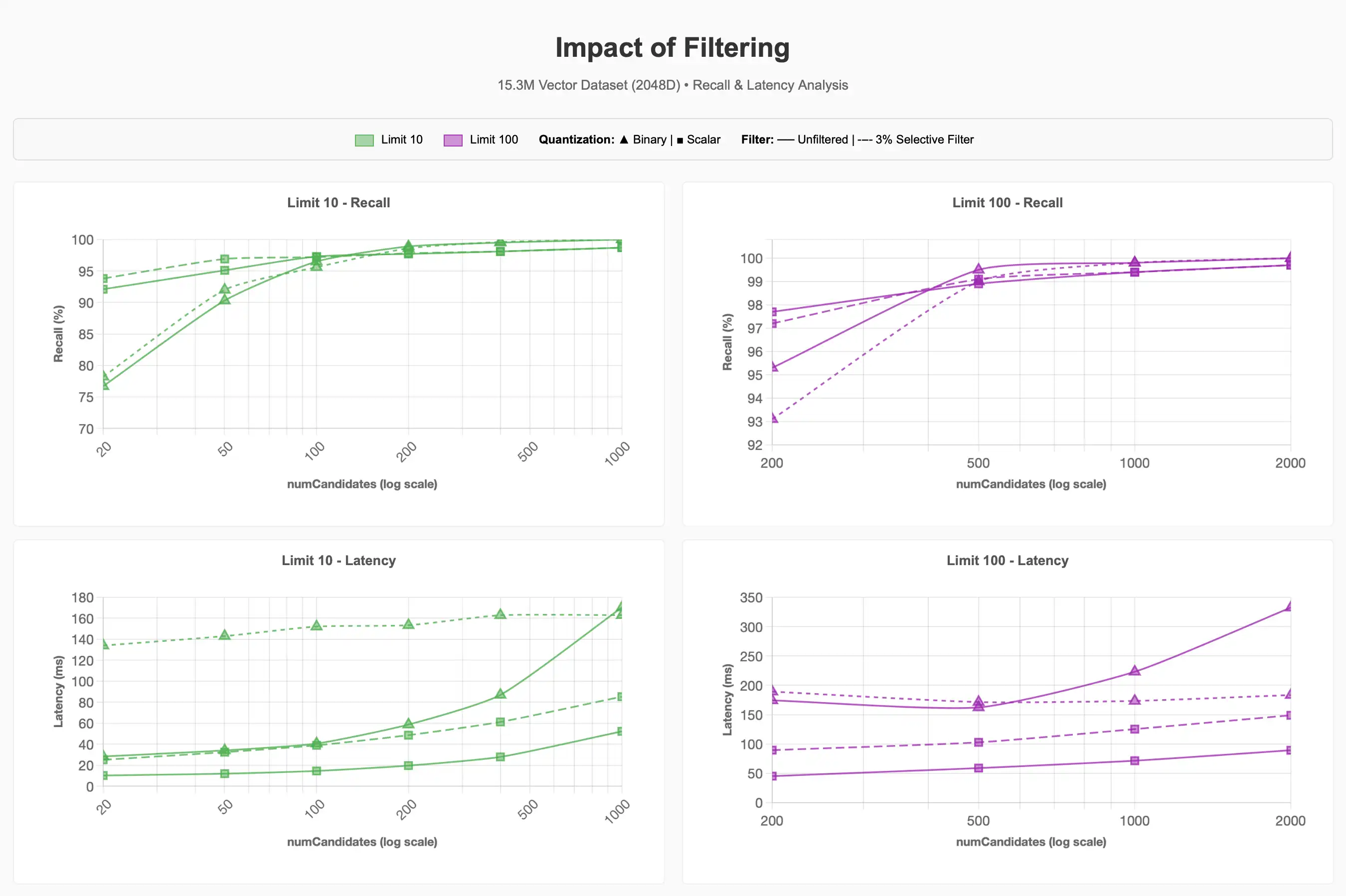
Observamos o que acontece com a recuperação e a latência ao usar um filtro seletivo no conjunto de dados para ~500 mil dos 15,3 milhões de itens da categoria de suprimentos para animais (~3% do corpus):

Para ver o gráfico completo, consulte o artefato Class.
Podemos observar que o filtro seletivo de 3% pode tornar as consultas significativamente mais custosas. Para a quantização binária em valores limit mais baixos, isso foi aproximadamente 4x mais caro para alcançar 90-95% de recall em comparação com as queries não filtradas.
Melhorias futuras no Lucene 10, que dão suporte a estratégias de pesquisa Acorn-1 para Hierarchical Navigable Small Worlds, podem aprimorar este processo. No entanto, executar ENN quando o número de candidatos solicitados excede o número de vetores correspondentes ao filtro de metadados dentro de um segmento demonstra que a seletividade do filtro tem um papel importante no desempenho da query, independentemente do regime de quantização selecionado.
Concurrency
Esses testes dimensionam solicitações simultâneas entre 1, 10 e 100 nos vários valores de limit ao usar quantização escalar e binária. numCandidates são selecionados escolhendo valores que permitem alcançar uma recuperação de 90–95%:


Para ver o gráfico completo, consulte o artefato Class.
Observamos que a quantização escalar alcança QPS substancialmente mais alto em todos os valores de limite, provavelmente porque há menos trabalho realizado por query com menor numCandidates e porque o rescoring não é realizado. Observamos gargalos substanciais na CPU, conforme indicado pelos gráficos de simultaneidade 10 e simultaneidade 100, que geralmente estão muito próximos um do outro, indicando que seria notada uma latência mais alta.
Um ponto de dados excepcional é o limite 10, simultaneidade 100 para quantização escalar, resultando em QPS significativamente mais alto. Isso provavelmente ocorre devido à falta de rescoring, e valores mais baixos de limit significam que menos comparações são realizadas para essa query, permitindo que cada solicitação retorne mais rapidamente e disponibilize os núcleos para atender outras queries.
O dimensionamento do número de vCPUs disponíveis para servir solicitações, aumentando o nível do nó de pesquisa ou o número de nós de pesquisa do mínimo de 2 até 32 nós, pode ajudar a resolver gargalos de simultaneidade e permitir que você dimensione bem até milhares de QPS.
Fragmentação
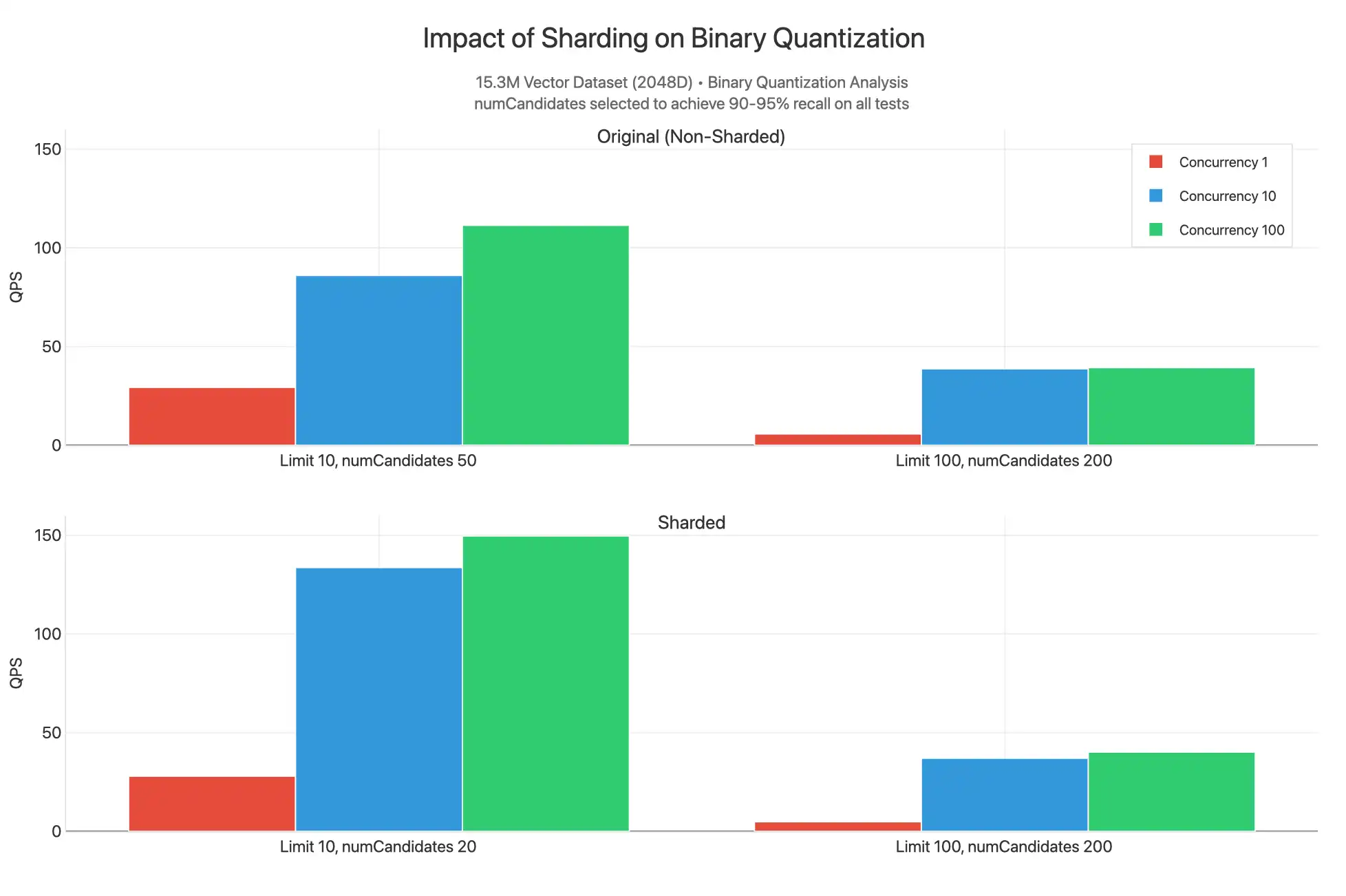
Também observamos o que aconteceria se o cluster e a coleção fossem fragmentados (em _id) e queries não filtradas fossem emitidas contra um índice quantizado binário.

Para ver o gráfico completo, consulte o artefato Class.
Aqui, vemos que os resultados fragmentados têm um QPS mais alto no limite 10, pois o valor mais baixo de numCandidates pode ser fornecido para produzir resultados na faixa de recuperação 90-95%. Isso ocorre porque o conjunto de dados 15.3M é divisão em três fragmentos, cada um dos quais tem seus próprios índices preenchidos com vetores 5.1M espalhados por segmentos contendo gráficos HNSW. Funcionalmente, estamos fazendo uma pesquisa menos avançada, em que é mais provável que cada dispersão de consulta reunida em fragmentos 3 simultaneamente possa encontrar os vetores n mais próximos. Por esse motivo, o QPS é um pouco maior ao fragmentar, pois você pode reduzir numCandidates e ter mais núcleos disponíveis para atender às queries, mas a diferença não é tão significativa para justificar o aumento do custo da fragmentação do cluster. Na maioria das vezes, você deve fragmentar seu cluster por motivos relacionados ao volume de trabalho operacional, não porque precise escalar a taxa de transferência para pesquisa vetorial.
Observação
Os valores são semelhantes para o limite 100 e o número de candidatos 200. Podemos esperar que isso tenha um desempenho melhor para consultas filtradas com uma correspondência inteligente da chave de fragmento usada como filtro.