Observação
Atualmente, o Atlas está disponível como base de conhecimento nas regiões AWS localizadas apenas nos Estados Unidos.
Você pode usar o MongoDB Atlas como uma base de conhecimento para a Amazon Leite para criar aplicativos de IA generativa , implementar a geração aumentada de recuperação (RAG) e criar agentes.
Visão geral
A integração da Base de conhecimento do Amazon Bedrock com o Atlas permite os seguintes casos de uso:
Use modelos de base com o MongoDB Vector Search para construir aplicativos de IA e implementar RAG. Para começar, consulte Iniciar.
Habilite a pesquisa híbrida com o MongoDB Vector Search e o MongoDB Search para sua base de conhecimento. Para saber mais, consulte Pesquisa Híbrida com Amazon Cama e Atlas.
Começar
Este tutorial demonstra como começar a usar a Vector Search do MongoDB com o Amazon Camarque. Especificamente, você executa as seguintes ações:
Carregue dados personalizados em um bucket Amazon S3.
Opcionalmente, configure um serviço de endpoint usando o AWS PrivateLink.
Crie um índice do MongoDB Vector Search em seus dados.
Crie uma Base de Conhecimento para armazenar dados no Atlas.
Crie um agente que use o MongoDB Vector Search para implementar o RAG.
Plano de fundo
O Amazon Bedrock é um serviço totalmente gerenciado para criar aplicativos de IA generativa. Ele permite aproveitar os modelos de fundação (FMs) de várias empresas de IA como uma única API.
Você pode usar a Vector Search do MongoDB como uma base de conhecimento para o Amazon Camarock para armazenar dados personalizados no Atlas e criar um agente para implementar o RAG e responder a perguntas sobre seus dados. Para saber mais sobre RAG, consulte Geração Aumentada de Recuperação (RAG) com MongoDB.
Pré-requisitos
Para concluir este tutorial, você deve ter o seguinte:
Um cluster Atlas M10+ executando o MongoDB versão 6.0.11, 7.0.2, ou posterior.
Uma conta da AWS com um segredo que contenha credenciais para seu cluster do Atlas .
Acesso aos seguintes modelos de base usados neste tutorial:
A AWS CLI e npm instalados se você planeja configurar um serviço de ponto de extremidade AWS PrivateLink.
Carregar dados personalizados
Se você ainda não tem um bucket Amazon S3 que contém dados de texto, crie um novo bucket e carregue o seguinte PDF acessível ao público sobre as melhores práticas do MongoDB:
Faça o download do PDF.
Navegue até o Guia de melhores práticas do MongoDB.
Clique em Read Whitepaper ou Email me the PDF para acessar o PDF.
Baixe e salve o PDF localmente.
Carregue o PDF em um bucket do Amazon S.3
Siga os passos para criar um S3 Bucket. Certifique-se de usar um descritivo Bucket Name.
Siga as etapas para carregar um arquivo em seu bucket. Selecione o arquivo que contém o PDF que você acabou de baixar.
Configurar um serviço de endpoint
Por padrão, o Amazon CamaDB se conecta à sua base de conhecimento pela Internet pública. Para proteger ainda mais sua conexão, o MongoDB Vector Search oferece suporte à conexão com sua base de conhecimento em uma rede virtual por meio de um serviço de endpoints do AWS PrivateLink.
Opcionalmente, conclua as etapas a seguir para habilitar um serviço de endpoint que se conecta a um endpoint privado AWS PrivateLink para o seu cluster do Atlas :
Configure um endpoint privado no Atlas.
Siga as etapas para configurar um endpoint privado do AWS PrivateLink para seu cluster Atlas. Certifique-se de usar um VPC ID descritivo para identificar seu endpoint privado.
Para obter mais informações, consulte Saiba mais sobre endpoints privados no Atlas.
Configure o serviço de endpoint.
O MongoDB e os parceiros fornecem um Cloud Development Kit (CDK) que você pode usar para configurar um serviço de endpoint apoiado por um balanceador de carga de rede que encaminha o tráfego para seu endpoint privado.
Siga as etapas especificadas no Repositório do Github do CDK para preparar e executar o script do CDK.
Crie o índice de Vector Search do MongoDB
Nesta seção, você configura o Atlas como um banco de dados de vetor, também chamado de armazenamento de vetor, criando um índice do MongoDB Vector Search em sua coleção.
Acesso necessário
Para criar um índice do MongoDB Vector Search, você deve ter acessoProject Data Access Admin ou superior ao projeto Atlas.
Procedimento
No Atlas, vá Data Explorer para a página do seu projeto.
Se ainda não tiver sido exibido, selecione a organização que contém seu projeto no menu Organizations na barra de navegação.
Se ainda não estiver exibido, selecione seu projeto no menu Projects na barra de navegação.
Na barra lateral, clique em Data Explorer sob o título Database.
O Data Explorer é exibido.
No Atlas, vá Search & Vector Search para a página para seu cluster.
Você pode acessar a página de pesquisa do MongoDB a partir da opção Search & Vector Search ou do Data Explorer.
Se ainda não tiver sido exibido, selecione a organização que contém seu projeto no menu Organizations na barra de navegação.
Se ainda não estiver exibido, selecione seu projeto no menu Projects na barra de navegação.
Na barra lateral, clique em Search & Vector Search sob o título Database.
Se você não tiver clusters, clique em Create cluster para criar um. Para saber mais, consulte Criar um cluster.
Se o seu projeto tiver vários clusters, selecione o cluster que deseja usar no menu suspenso Select cluster e clique em Go to Atlas Search.
A página Pesquisa & Pesquisa Vetorial é exibida.
Se ainda não tiver sido exibido, selecione a organização que contém seu projeto no menu Organizations na barra de navegação.
Se ainda não estiver exibido, selecione seu projeto no menu Projects na barra de navegação.
Na barra lateral, clique em Data Explorer sob o título Database.
Expanda o banco de dados e selecione a coleção.
Clique na guia Indexes da coleção.
A página Atlas Search é exibida.
Inicie a configuração do seu índice.
Faça as seguintes seleções na página e clique em Next.
Search Type | Selecione o tipo de índice Vector Search. |
Index Name and Data Source | Especifique as seguintes informações:
|
Configuration Method | For a guided experience, select Visual Editor. To edit the raw index definition, select JSON Editor. |
IMPORTANTE:
Seu índice do MongoDB Search é denominado default por padrão. Se você manter esse nome, seu índice será o índice de pesquisa padrão para qualquer consulta do MongoDB Search que não especifique uma opção index diferente em seus operadores. Se você estiver criando vários índices, recomendamos que mantenha uma convenção de nomenclatura descritiva consistente em seus índices.
Defina o índice do MongoDB Vector Search .
Essa definição de índice do tipo vectorSearch indexa os seguintes campos:
embeddingcampo como o tipo de vetor . O campoembeddingcontém as inserções de vetor criadas usando o modelo de inserção que você especifica ao configurar a base de dados de conhecimento. A definição de índice especifica1024dimensões vetoriais e mede a similaridade usandocosine.bedrock_metadata, camposbedrock_text_chunkex-amz-bedrock-kb-document-page-numbercomo o tipo de filtro para pré-filtrar seus dados. Você também especificará esses campos no Amazon Bedrock ao configurar a base de conhecimento.
Observação
Se você já criou um índice com o campo de filtro page_number, é necessário atualizar a definição do índice para usar o novo nome do campo de filtro x-amz-bedrock-kb-document-page-number. O Amazon Bedrock atualizou o nome do campo, e os índices que usam o nome do campo antigo não funcionam mais corretamente com as Bases de Conhecimento do Amazon Bedrock.
Especifique embedding como o campo a ser indexado e 1024 como o número de dimensões.
Para configurar o índice, faça o seguinte:
Selecione Cosine no menu suspenso Similarity Method.
Na seção Filter Field, especifique os campos
bedrock_metadata,bedrock_text_chunkex-amz-bedrock-kb-document-page-numberpara filtrar os dados.
Cole a seguinte definição de índice no editor JSON:
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
Verifique o status.
O índice recém-criado é exibido na aba Atlas Search. Enquanto o índice está construindo, o campo Status lê Build in Progress. Quando o índice terminar de construir, o campo Status lê Active.
Observação
Collections maiores demoram mais tempo para indexar. Você receberá uma notificação por e-mail quando seu índice terminar a criação.
Crie uma base de conhecimento
Nesta seção, você cria uma base de conhecimento para carregar dados personalizados em seu repositório de vetores.
Navegue até o console de gerenciamento do Amazon Leigo.
Faça login no Console do Amazon Web Services.
No canto superior esquerdo, clique no menu suspenso Services.
Clique em Machine Learning e selecione Amazon Bedrock.
Gerenciar o acesso ao modelo.
O Amazon Bedrock não concede acesso aos FMs automaticamente. Se ainda não o fez, siga as etapas para adicionar acesso ao modelo para os modelos Titan Embeddings G1 - Text e Anthropic Claude V2.1 .
Crie a base de conhecimento.
Na navegação à esquerda do console do Amazon Bedrock, clique em Knowledge Bases.
Clique em Create e depois selecione Knowledge base with vector store.
Especifique
mongodb-atlas-knowledge-basecomo Knowledge Base name.Clique em Next.
Por padrão, o Amazon Leite cria uma nova função IAM para acessar a base de conhecimento.
Adicione uma fonte de dados.
Especifique um nome para a fonte de dados usada pela base de conhecimento.
Insira o URI para o bucket S3 que contém sua fonte de dados. Ou clique em Browse S3 e localize o bucket S3 que contém sua fonte de dados na lista.
Clique em Next.
O Amazon Leitor exibe modelos de incorporação disponíveis que você pode usar para converter os dados de texto da fonte de dados em incorporações vetoriais.
Selecione o modelo Titan Embeddings G1 - Text.
Conecte o Atlas à base de conhecimento.
Na seção Vector database, selecione Use an existing vector store.
Selecione MongoDB Atlas e configure as seguintes opções:
![Captura de tela da seção de configuração do armazenamento de vetores do Amazon Bedrock.]() clique para ampliar
clique para ampliarPara o Hostname, insira o URL do seu cluster do Atlas localizado em sua string de conexão. O nome de host usa o seguinte formato:
<clusterName>.mongodb.net Para o Database name, insira
bedrock_db.Para o Collection name, insira
test.Para o Credentials secret ARN, insira o ARN para o segredo que contém suas credenciais do Atlas cluster. Para saber mais, consulte os conceitos do Amazon Web Services Secrets Manager.
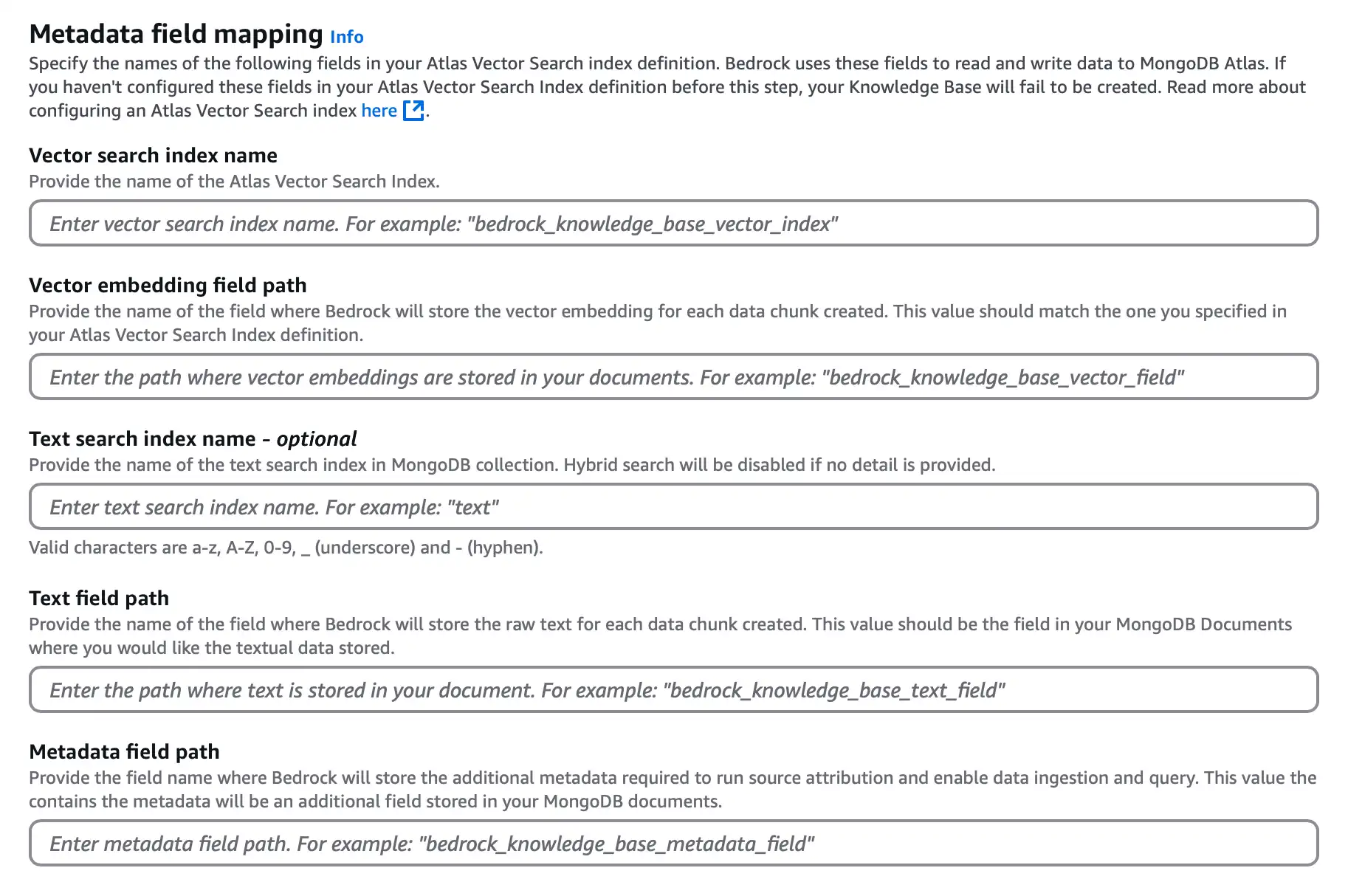
Na seção Metadata field mapping , configure as seguintes opções para determinar o índice do MongoDB Vector Search e os nomes de campo que o Atlas utiliza para incorporar e armazenar sua fonte de dados:
![Captura de tela da seção de configuração do mapeamento de campos do armazenamento vetorial.]() clique para ampliar
clique para ampliarPara o Vector search index name, insira
vector_index.Para o Vector embedding field path, insira
embedding.Para o Text field path, insira
bedrock_text_chunk.Para o Metadata field path, insira
bedrock_metadata.
Observação
Opcionalmente, você pode especificar o campo Text search index name para configurar a pesquisa híbrida. Para aprender mais, veja Pesquisa híbrida com Amazon Bedrock e Atlas.
Se você configurou um serviço de endpoint, informe seu PrivateLink Service Name.
Clique em Next.



Sincronize a fonte de dados.
Depois que o Amazon Bedrock cria a Base de Conhecimento, ele solicita que você sincronize seus dados. Na seção Data source, selecione sua fonte de dados e clique em Sync para sincronizar os dados do bucket S3 e carregá-los no Atlas.
Quando a sincronização for concluída, se você estiver usando o Atlas, poderá verificar suas incorporações vetoriais navegando até o namespace bedrock_db.test na interface do usuário do Atlas.
Construir um agente
Nesta seção, você implementa um agente que usa o MongoDB Vector Search para implementar o RAG e responder a perguntas sobre seus dados. Quando você solicita a este agente, ele faz o seguinte:
Conecta-se à sua base de conhecimento para acessar os dados personalizados armazenados no Atlas.
Utiliza a Vector Search do MongoDB para recuperar documentos relevantes do seu armazenamento de vetor com base no prompt.
Utiliza um modelo de bate-papo com AI para gerar uma resposta sensível ao contexto com base nesses documentos.
Conclua as etapas a seguir para criar e testar o agente RAG :
Selecione um modelo e forneça um prompt.
Por padrão, o Amazon Leitor cria uma nova função do IAM para acessar o agente. Na seção Agent details , especifique o seguinte:
Nos menus suspensos, selecione Anthropic e Claude V2.1 como o provedor e o modelo de AI usado para responder a perguntas sobre seus dados.
Observação
O Amazon Bedrock não concede acesso aos FMs automaticamente. Se ainda não o fez, siga os passos para adicionar acesso ao modelo para o modelo Anthropic Claude V2.1 modelo.
Forneça instruções para o agente para que ele saiba como concluir a tarefa.
Por exemplo, se você estiver usando os dados de amostra, cole as seguintes instruções:
You are a friendly AI chatbot that answers questions about working with MongoDB. Clique em Save.
Adicione a base de conhecimento.
Para conectar o agente à base de conhecimento que você criou:
Na seção Knowledge Bases, clique em Add.
Selecione mongodb-atlas-knowledge-base no menu suspenso.
Descreva a base de dados de conhecimento para determinar como o agente deve interagir com a fonte de dados.
Se você estiver usando os dados de amostra, cole as seguintes instruções:
This knowledge base describes best practices when working with MongoDB. Clique em Add e depois em Save.
Teste o agente.
Clique no botão Prepare.
Clique Test. O Amazon Camado exibe uma janela de teste à direita dos detalhes do seu agente, se ela ainda não tiver sido exibida.
Na janela de teste, insira um prompt. O agente solicita o modelo, usa o MongoDB Vector Search para recuperar documentos relevantes e, em seguida, gera uma resposta com base nos documentos.
Se você usou os dados de amostra, insira o seguinte prompt. A resposta gerada pode variar.
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] Dica
Clique na anotação na resposta do agente para visualizar o bloco de texto que o MongoDB Vector Search recuperou.
Outros recursos
Para solucionar problemas, consulte Solução de problemas da integração da base de conhecimento do Amazon Bedrock.