Neste tutorial, você aprenderá como avaliar um aplicaçãoRAG. A avaliação ajuda você a escolher o modelo correto, garantir que o desempenho do seu modelo seja convertido do protótipo para a produção e capturar regressões de desempenho.
Especificamente, você executa as seguintes ações:
Configure o ambiente.
Baixe um conjunto de dados de avaliação.
Crie chunks e incorporações de documento .
Faça a ingestão das incorporações no Atlas.
Compare modelos de incorporação para recuperação.
Compare modelos de conclusão para geração.
Meça o desempenho geral do RAG.
Acompanhe o desempenho ao longo do tempo com MongoDB Charts.
Observação
Este tutorial se concentra em avaliar aplicativos LLM, não modelos LLM. A avaliação de modelos de LLM envolve a medição do desempenho de um determinado modelo em diferentes tarefas. A avaliação do aplicaçãoLLM trata da avaliação de diferentes componentes de um aplicação LLM , como prompts e recuperadores, bem como do sistema como um todo.
Trabalhe com uma versão executável deste tutorial como um bloco de anotações Python.
Plano de fundo
Este tutorial usa a estrutura de avaliação de código aberto RAGAS para medir o desempenho do RAG com as seguintes métricas:
Métricas de recuperação: a precisão do contexto e a recuperação do contexto medem a eficiência com que o recuperador encontra informações relevantes.
Métricas de geração: a fidelidade e a relevância da resposta medem a eficiência com que seu LLM gera respostas precisas e relevantes.
Métricas gerais: a similaridade da resposta e a correção da resposta comparam as respostas geradas com a verdade fundamental.
Para saber mais sobre essas métricas, consulte Métricas RGAS na documentação do RGAS.
Este tutorial usa o conjunto de dados rasas-wikiqa do Abraçando o Face, que contém aproximadamente 230 perguntas de conhecimento geral com respostas de verdade.
Pré-requisitos
Para concluir este tutorial, você deve ter o seguinte:
Um cluster do MongoDB Atlas executando o MongoDB versão 6.0.11 ou posterior. Certifique-se de que seu endereço IP esteja na lista de acesso do seu projeto.
Uma chave de API OpenAI para usar os modelos de incorporação e conclusão de chat do OpenAI.
Um terminal configurado com o seguinte:
Python 3.10 ou posterior.
Um ambiente para executar blocos de anotações Python interativos, como VS Code ou Jupyter Notebook.
Configurar o ambiente
Configurar suas credenciais
Execute o seguinte código em seu bloco de anotações para configurar a string de conexão do MongoDB e a chave de API OpenAI:
import getpass import os from openai import OpenAI MONGODB_URI = getpass.getpass("Enter your MongoDB connection string:") os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API Key:") openai_client = OpenAI()
Baixe o conjunto de dados de avaliação
Baixe o conjunto de dados rasas-wikiqa do Abraçando o Face e converta-o em um dataframe de Pandas:
from datasets import load_dataset import pandas as pd data = load_dataset("explodinggradients/ragas-wikiqa", split="train") df = pd.DataFrame(data)
O conjunto de dados contém as seguintes colunas:
question: Perguntas do usuáriocorrect_answer: Respostas da verdade fundamentalcontext: Lista de textos de referência para responder às perguntas
Criar chunks de documentos
Divida os textos de referência em blocos menores antes de incorporar:
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text by tokens using the tiktoken tokenizer text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( encoding_name="cl100k_base", keep_separator=False, chunk_size=200, chunk_overlap=30 ) def split_texts(texts): chunked_texts = [] for text in texts: chunks = text_splitter.create_documents([text]) chunked_texts.extend([chunk.page_content for chunk in chunks]) return chunked_texts # Split the context field into chunks df["chunks"] = df["context"].apply(lambda x: split_texts(x)) # Aggregate list of all chunks all_chunks = df["chunks"].tolist() docs = [item for chunk in all_chunks for item in chunk]
Dica
Experimente diferentes estratégias de agrupamento ao avaliar a recuperação. Este tutorial se concentra em avaliar modelos de incorporação.
Criar incorporações e ingestão em MongoDB Charts
Incorpore os documentos em partes e ingira-os no Atlas. Crie collections separadas para cada modelo de incorporação que você deseja comparar:
Definir uma função de incorporação
Crie uma função para gerar incorporações usando a API OpenAI:
from typing import List def get_embeddings(docs: List[str], model: str) -> List[List[float]]: """Generate embeddings using the OpenAI API.""" docs = [doc.replace("\n", " ") for doc in docs] response = openai_client.embeddings.create(input=docs, model=model) return [r.embedding for r in response.data]
Ingerir incorporações no Atlas
Incorpore e ingira os documentos fragmentados nas collections do Atlas :
from pymongo import MongoClient from tqdm.auto import tqdm client = MongoClient(MONGODB_URI) DB_NAME = "ragas_evals" db = client[DB_NAME] batch_size = 128 EVAL_EMBEDDING_MODELS = ["text-embedding-ada-002", "text-embedding-3-small"] for model in EVAL_EMBEDDING_MODELS: embedded_docs = [] print(f"Getting embeddings for the {model} model") for i in tqdm(range(0, len(docs), batch_size)): end = min(len(docs), i + batch_size) batch = docs[i:end] batch_embeddings = get_embeddings(batch, model) batch_embedded_docs = [ {"text": batch[i], "embedding": batch_embeddings[i]} for i in range(len(batch)) ] embedded_docs.extend(batch_embedded_docs) collection = db[model] collection.delete_many({}) collection.insert_many(embedded_docs) print(f"Finished inserting embeddings for the {model} model")
Criar índices de pesquisa vetorial
Crie um índice do MongoDB Vector Search para cada coleção. Use a seguinte definição de índice com o nome de índice vector_index:
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
Para saber como criar o índice, consulte Criar um índice de Vector Search do MongoDB .
Dica
text-embedding-ada-002 e text-embedding-3-small têm dimensões 1536, portanto, a mesma definição de índice funciona para ambas as coleções.
Comparar modelos de incorporação
Para garantir a recuperação do contexto correto para o LLM, compare diferentes modelos de incorporação. Este tutorial compara text-embedding-ada-002 e.text-embedding-3-small
Criar uma função de recuperação
Crie uma função para obter um recuperador de armazenamento de vetor usando LangChain e MongoDB Atlas:
from langchain_openai import OpenAIEmbeddings from langchain_mongodb import MongoDBAtlasVectorSearch from langchain_core.vectorstores import VectorStoreRetriever def get_retriever(model: str, k: int) -> VectorStoreRetriever: """ Get a vector store retriever for a given embedding model. Args: model (str): Embedding model to use k (int): Number of results to retrieve Returns: VectorStoreRetriever: A vector store retriever object """ embeddings = OpenAIEmbeddings(model=model) vector_store = MongoDBAtlasVectorSearch.from_connection_string( connection_string=MONGODB_URI, namespace=f"{DB_NAME}.{model}", embedding=embeddings, index_name="vector_index", text_key="text", ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": k} ) return retriever
Avalie o recuperador
Use as métricas context_precision e context_recall da biblioteca RGAS para avaliar cada modelo de incorporação:
from datasets import Dataset from ragas import evaluate, RunConfig from ragas.metrics import context_precision, context_recall import nest_asyncio # Allow nested use of asyncio (used by RAGAS) nest_asyncio.apply() for model in EVAL_EMBEDDING_MODELS: data = {"question": [], "ground_truth": [], "contexts": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH retriever = get_retriever(model, 2) # Get relevant documents for the evaluation dataset for i in tqdm(range(0, len(QUESTIONS))): data["contexts"].append( [doc.page_content for doc in retriever.invoke(QUESTIONS[i])] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[context_precision, context_recall], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
Os resultados da avaliação dos modelos de incorporação no conjunto de dados de amostra são os seguintes:
Modelo | Precisão de contexto | Lembrete de contexto |
|---|---|---|
text-embedding-ada-002 | 0.9310 | 0.8561 |
text-embedding-3-small | 0.9116 | 0.8826 |
Com base nesses resultados, text-embedding-ada-002 classifica os resultados mais relevantes em primeiro lugar, mas text-embedding-3-small recupera contextos que estão mais alinhados com as respostas da verdade fundamental. Para este tutorial, utilize text-embedding-3-small como modelo de incorporação.
Comparar modelos de conclusão
Agora que você selecionou o melhor modelo de incorporação, compare os modelos de conclusão para o componente de geração do seu aplicação RAG.
Criar uma cadeia RAG
Crie uma função que construa uma cadeia RAG usando LangChain:
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.runnables.base import RunnableSequence from langchain_core.output_parsers import StrOutputParser def get_rag_chain(retriever: VectorStoreRetriever, model: str) -> RunnableSequence: """ Create a basic RAG chain. Args: retriever (VectorStoreRetriever): Vector store retriever object model (str): Chat completion model to use Returns: RunnableSequence: A RAG chain """ # Generate context using the retriever, and pass the user question through retrieve = { "context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough(), } template = """Answer the question based only on the following context: \ {context} Question: {question} """ # Define the chat prompt prompt = ChatPromptTemplate.from_template(template) # Define the model for chat completion llm = ChatOpenAI(temperature=0, model=model) # Parse output as a string parse_output = StrOutputParser() # RAG chain rag_chain = retrieve | prompt | llm | parse_output return rag_chain
Avalie os modelos de conclusão
Use as métricas faithfulness e answer_relevancy para avaliar diferentes modelos de conclusão:
from ragas.metrics import faithfulness, answer_relevancy for model in ["gpt-3.5-turbo-1106", "gpt-3.5-turbo"]: data = {"question": [], "ground_truth": [], "contexts": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) rag_chain = get_rag_chain(retriever, model) for i in tqdm(range(0, len(QUESTIONS))): question = QUESTIONS[i] data["answer"].append(rag_chain.invoke(question)) data["contexts"].append( [doc.page_content for doc in retriever.invoke(question)] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
Os resultados da avaliação para os modelos de conclusão no conjunto de dados de amostra são os seguintes:
Modelo | Fidelidade | Relevância da resposta |
|---|---|---|
gpt-3.5-turbo | 0.9714 | 0.9087 |
gpt-3.5-turbo-1106 | 0.9671 | 0.9105 |
Com base nesses resultados, o gpt-3.5-turbo mais recente produz resultados mais consistentes em termos de fato, enquanto a versão mais antiga produz respostas mais pertinentes ao prompt fornecido. Para este tutorial, use gpt-3.5-turbo como modelo de conclusão.
Dica
Se você não quiser escolher entre métricas, considere criar métricas consolidadas usando uma soma ponderada ou personalizar os prompts usados para avaliação.
Avalie o desempenho geral
Avalie o desempenho geral do seu aplicação RAG usando os modelos de melhor desempenho:
from ragas.metrics import answer_similarity, answer_correctness data = {"question": [], "ground_truth": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) # Use the best completion model from the generator evaluation rag_chain = get_rag_chain(retriever, "gpt-3.5-turbo") for question in tqdm(QUESTIONS): data["answer"].append(rag_chain.invoke(question)) dataset = Dataset.from_dict(data) run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[answer_similarity, answer_correctness], run_config=run_config, raise_exceptions=False, ) print(f"Overall metrics: {result}")
Esta avaliação mostra que a cadeia RAG produz uma similaridade de resposta de e uma 0.8873 0.5922 correção de resposta de no conjunto de dados de amostra.
Analisar os resultados
Para investigar mais os resultados, converta-os em um dataframe do Pandas e filtre para respostas de baixa pontuação:
result_df = result.to_pandas() result_df[result_df["answer_correctness"] < 0.7]
Para uma análise visual, crie um mapa térmico de perguntas versus métricas:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) sns.heatmap( result_df[1:10].set_index("question")[["answer_similarity", "answer_correctness"]], annot=True, cmap="flare", ) plt.show()
O código anterior gera o seguinte mapa de calor:

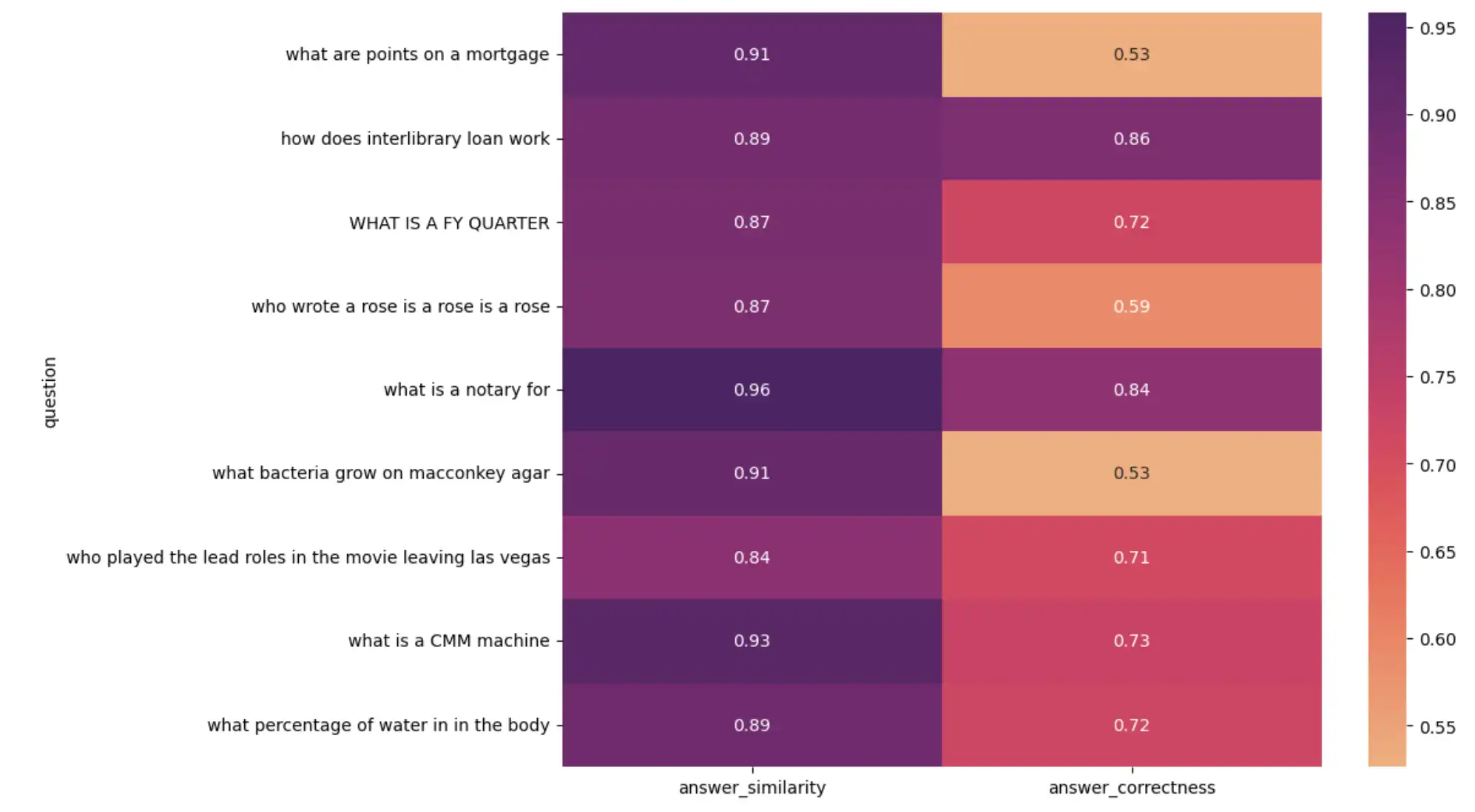
Mapa de calor visualizando o desempenho do aplicação RAG
Ao investigar resultados de baixa pontuação, você pode encontrar:
Algumas respostas confiáveis no conjunto de dados de avaliação estão incorretas. Embora a resposta gerada pelo LLM esteja correta, ela não corresponde à verdade, resultando em uma pontuação baixa.
Algumas respostas da verdade do camposão frases completas, enquanto a resposta gerada pelo LLM é uma única palavra ou número.
Essas descobertas enfatizam a importância de verificar avaliações pontuais de LLM e de selecionar conjuntos de dados de avaliações precisos.
Acompanhe o desempenho ao longo do tempo
A avaliação não deve ser um evento único . Cada vez que você alterar um componente em seu sistema, avalie as alterações para avaliar como elas impacto o desempenho. Quando seu aplicação estiver em produção, monitore o desempenho em tempo real e detecte alterações.
Use Charts para monitorar o desempenho do seu aplicação LLM. Anote os resultados da avaliação e quaisquer métricas de feedback que você queira acompanhar em uma collection do Atlas :
from datetime import datetime result["timestamp"] = datetime.now() collection = db["metrics"] collection.insert_one(result)
Este código adiciona um campo timestamp ao resultado da avaliação e o escreve em uma coleção metrics no banco de dados ragas_evals. O documento no Atlas é apresentado assim:
{ "answer_similarity": 0.8873, "answer_correctness": 0.5922, "timestamp": "2024-04-07T23:27:30.655+00:00" }
Crie um dashboard no MongoDB Charts para visualizar suas métricas ao longo do tempo. Para saber como criar gráficos e painéis, consulte Criar Charts.
Resumo
Neste tutorial, você aprenderam como avaliar um aplicação RAG utilizando a estrutura RAGAS e MongoDB Atlas. Você comparou modelos de incorporação para recuperação, modelos de conclusão para geração e mediu o desempenho geral do seu aplicação. Você também aprendera a acompanhar o desempenho ao longo do tempo usando o MongoDB Charts.
Para saber mais sobre como criar aplicativos RAG com MongoDB, consulte os seguintes recursos: