Observação
As extensões Vertex AI estão em versão prévia e sujeitas a alterações. Entre em contato com seu representante do Google Cloud para aprender como acessar este recurso.
Além de usar a Vertex AI com o MongoDB Vector Search para implementar o RAG, você pode usar o Vertex AI Extensions para personalizar ainda mais como você usa os modelos da Vertex AI para interagir com o Atlas. Neste tutorial, você cria uma extensão Vertex AI que permite consultar seus dados no Atlas em tempo real usando linguagem natural.
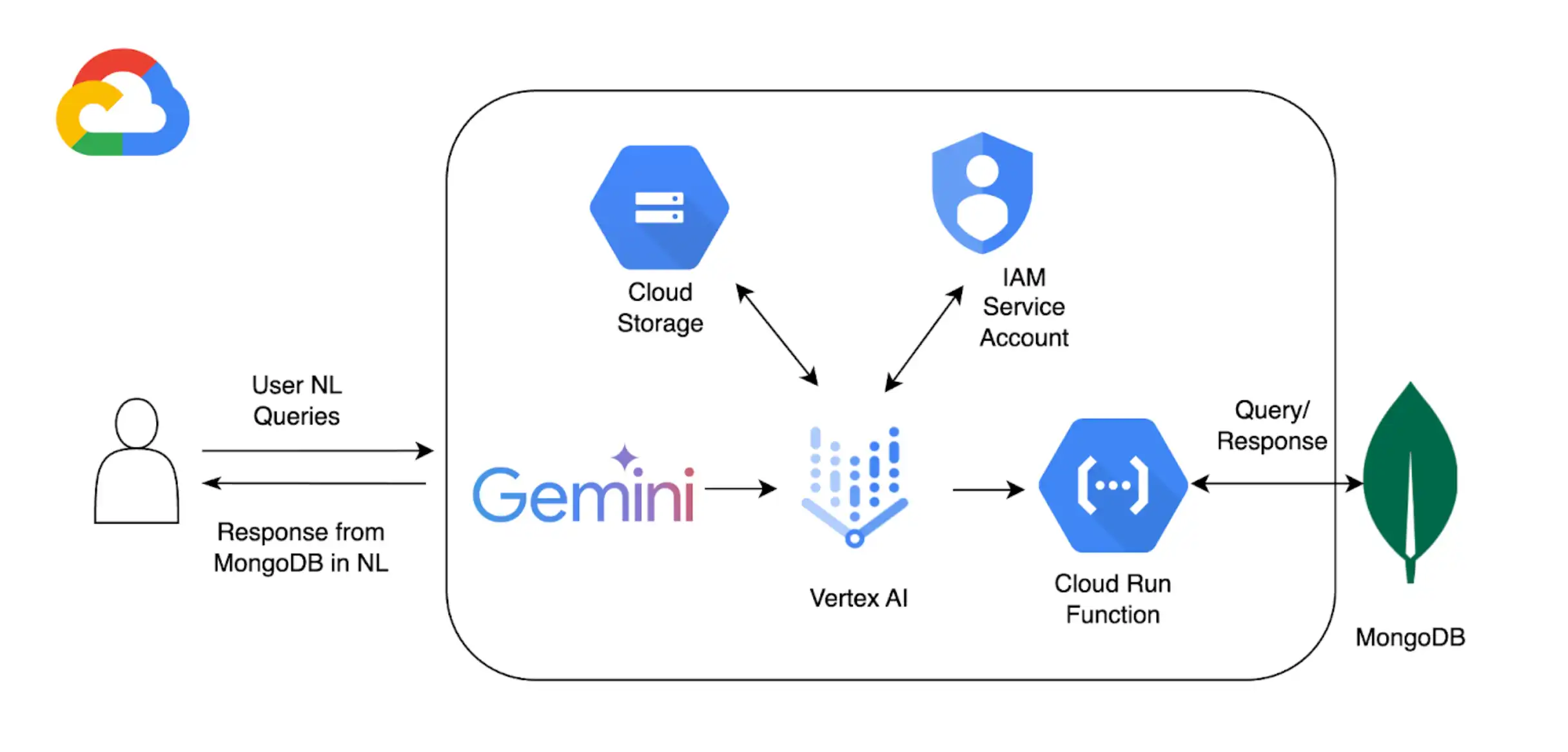
Plano de fundo
Este tutorial utiliza os seguintes componentes para habilitar consultas em linguagem natural com o Atlas:
SDK do Vertex AI do Google Cloud Platform para gerenciar modelos de IA e habilitar extensões personalizadas para o Vertex AI. Este tutorial utiliza o Gêmeos 1.5 Modelo Pro.
Google Cloud Run para implantar uma função que serve como um ponto de extremidade de API entre o Vertex AI e o Atlas.
Especificação OpenAPI 3 para a API do MongoDB para definir como as queries de linguagem natural são mapeadas para operações do MongoDB. Para saber mais, consulte Especificação OpenAPI.
Vertex AI Extensions para permitir a interação em tempo real com o Atlas a partir da Vertex AI e configurar como as queries de linguagem natural são processadas.
Google Cloud Secrets Manager para armazenar suas chaves de API do MongoDB.
Observação
Para obter instruções detalhadas de código e configuração, consulte o repositório do GitHub para este exemplo.
Pré-requisitos
Antes de começar, você deve ter o seguinte:
Uma conta do MongoDB Atlas. Para cadastrar-se, use o Google Cloud Marketplace ou registre uma nova conta.
Um cluster do Atlas com o conjunto de dados de amostra carregado. Para saber mais, consulte Criar um cluster.
Um projetodo Google Cloud Platform.
Um bucket do Google Cloud Storage para armazenar a especificação do OpenAPI.
As seguintes APIs habilitadas para seu projeto:
API de construção na nuvem
API de funções da nuvem
API de registro na nuvem
API do Cloud Pub/Sub
Um ambiente Colab Enterprise.
Criar uma função do Google Cloud Run
Nesta seção, você cria uma função do Google Cloud Run que serve como um ponto de extremidade da API entre a Extensão Vertex AI e seu cluster Atlas. A função lida com a autenticação, conecta-se ao seu cluster do Atlas e realiza operações de banco de dados com base nas solicitações do Vertex AI.
Crie uma nova função.
No console da Google Cloud Platform, abra a página Cloud Run e clique em Write a function.
Configure a função.
Especifique um nome de função e região do Google Cloud Platform onde você deseja implantar sua função.
Selecione a versão mais recente de Python disponível como Runtime.
No site Authentication section, selecione Allow unauthenticated invocations.
Use os valores padrão para as configurações restantes e clique em Next.
Para obter etapas de configuração detalhadas, consulte a documentação do Cloud Run.
Defina o código da função.
Cole o seguinte código em seus respectivos arquivos:
Após colar o código a seguir, substitua <connection-string> por sua string de conexão do Atlas .
Substitua <connection-string> pela string de conexão do seu cluster do Atlas ou da implantação local do Atlas.
Sua string de conexão deve usar o seguinte formato:
mongodb+srv://<db_username>:<db_password>@<clusterName>.<hostname>.mongodb.net
Para saber mais, consulte Conectar-se a um cluster por meio de bibliotecas de clientes.
Sua string de conexão deve usar o seguinte formato:
mongodb://localhost:<port-number>/?directConnection=true
Para saber mais, consulte Connection strings.
import functions_framework import os import json from pymongo import MongoClient from bson import ObjectId import traceback from datetime import datetime def connect_to_mongodb(): client = MongoClient("<connection-string>") return client def success_response(body): return { 'statusCode': '200', 'body': json.dumps(body, cls=DateTimeEncoder), 'headers': { 'Content-Type': 'application/json', }, } def error_response(err): error_message = str(err) return { 'statusCode': '400', 'body': error_message, 'headers': { 'Content-Type': 'application/json', }, } # Used to convert datetime object(s) to string class DateTimeEncoder(json.JSONEncoder): def default(self, o): if isinstance(o, datetime): return o.isoformat() return super().default(o) def mongodb_crud(request): client = connect_to_mongodb() payload = request.get_json(silent=True) db, coll = payload['database'], payload['collection'] request_args = request.args op = request.path try: if op == "/findOne": filter_op = payload['filter'] if 'filter' in payload else {} projection = payload['projection'] if 'projection' in payload else {} result = {"document": client[db][coll].find_one(filter_op, projection)} if result['document'] is not None: if isinstance(result['document']['_id'], ObjectId): result['document']['_id'] = str(result['document']['_id']) elif op == "/find": agg_query = [] if 'filter' in payload and payload['filter'] != {}: agg_query.append({"$match": payload['filter']}) if "sort" in payload and payload['sort'] != {}: agg_query.append({"$sort": payload['sort']}) if "skip" in payload: agg_query.append({"$skip": payload['skip']}) if 'limit' in payload: agg_query.append({"$limit": payload['limit']}) if "projection" in payload and payload['projection'] != {}: agg_query.append({"$project": payload['projection']}) result = {"documents": list(client[db][coll].aggregate(agg_query))} for obj in result['documents']: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) elif op == "/insertOne": if "document" not in payload or payload['document'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_one(payload['document']) result = {"insertedId": str(insert_op.inserted_id)} elif op == "/insertMany": if "documents" not in payload or payload['documents'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_many(payload['documents']) result = {"insertedIds": [str(_id) for _id in insert_op.inserted_ids]} elif op in ["/updateOne", "/updateMany"]: payload['upsert'] = payload['upsert'] if 'upsert' in payload else False if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/updateOne": update_op = client[db][coll].update_one(payload['filter'], payload['update'], upsert=payload['upsert']) else: update_op = client[db][coll].update_many(payload['filter'], payload['update'], upsert=payload['upsert']) result = {"matchedCount": update_op.matched_count, "modifiedCount": update_op.modified_count} elif op in ["/deleteOne", "/deleteMany"]: payload['filter'] = payload['filter'] if 'filter' in payload else {} if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/deleteOne": result = {"deletedCount": client[db][coll].delete_one(payload['filter']).deleted_count} else: result = {"deletedCount": client[db][coll].delete_many(payload['filter']).deleted_count} elif op == "/aggregate": if "pipeline" not in payload or payload['pipeline'] == []: return error_response("Send a pipeline") docs = list(client[db][coll].aggregate(payload['pipeline'])) for obj in docs: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) result = {"documents": docs} else: return error_response("Not a valid operation") return success_response(result) except Exception as e: print(traceback.format_exc()) return error_response(e) finally: if client: client.close()
Crie uma extensão de IA da Vertex
Nesta seção, você cria uma extensão Vertex AI que habilita consultas de linguagem natural em seus dados no Atlas usando o Gemini 1.5 Modelo Pro. Esta extensão usa uma especificação OpenAPI e a função Cloud Run que você criou para mapear a linguagem natural para operações de banco de dados e consultar seus dados no Atlas.
Para implementar esta extensão, você utiliza um notebook Python interativo, que permite executar trechos de código Python individualmente. Para este tutorial, você cria um notebook chamado mongodb-vertex-ai-extension.ipynb em um ambiente Colab Enterprise.
Configure o ambiente.
Autentique sua conta do Google Cloud e defina o ID do grupo.
from google.colab import auth auth.authenticate_user("GCP project id") !gcloud config set project {"GCP project id"} Instale as dependências necessárias.
!pip install --force-reinstall --quiet google_cloud_aiplatform !pip install --force-reinstall --quiet langchain==0.0.298 !pip install --upgrade google-auth !pip install bigframes==0.26.0 Reinicie o kernel.
import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) Defina as variáveis de ambiente.
Substitua os valores de amostra pelos valores corretos que correspondem ao seu projeto.
import os # These are sample values; replace them with the correct values that correspond to your project os.environ['PROJECT_ID'] = 'gcp project id' # GCP Project ID os.environ['REGION'] = "us-central1" # Project Region os.environ['STAGING_BUCKET'] = "gs://vertexai_extensions" # GCS Bucket location os.environ['EXTENSION_DISPLAY_HOME'] = "MongoDb Vertex API Interpreter" # Extension Config Display Name os.environ['EXTENSION_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # Extension Config Description os.environ['MANIFEST_NAME'] = "mdb_crud_interpreter" # OPEN API Spec Config Name os.environ['MANIFEST_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # OPEN API Spec Config Description os.environ['OPENAPI_GCS_URI'] = "gs://vertexai_extensions/mongodbopenapispec.yaml" # OPEN API GCS URI os.environ['API_SECRET_LOCATION'] = "projects/787220387490/secrets/mdbapikey/versions/1" # API KEY secret location os.environ['LLM_MODEL'] = "gemini-1.5-pro" # LLM Config
Baixe a especificação da API Open.
Baixe a especificação da Open API do GitHub e faça upload do arquivo YAML para o bucket do Google Cloud Storage.
from google.cloud import aiplatform from google.cloud.aiplatform.private_preview import llm_extension PROJECT_ID = os.environ['PROJECT_ID'] REGION = os.environ['REGION'] STAGING_BUCKET = os.environ['STAGING_BUCKET'] aiplatform.init( project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET, )
Crie a extensão Vertex AI.
O seguinte manifesto é um objeto JSON estruturado que configura componentes principais para a extensão. Substitua <service-account> pelo nome da conta de serviço usado pela função do Cloud Run.
from google.cloud import aiplatform from vertexai.preview import extensions mdb_crud = extensions.Extension.create( display_name = os.environ['EXTENSION_DISPLAY_HOME'], # Optional. description = os.environ['EXTENSION_DESCRIPTION'], manifest = { "name": os.environ['MANIFEST_NAME'], "description": os.environ['MANIFEST_DESCRIPTION'], "api_spec": { "open_api_gcs_uri": ( os.environ['OPENAPI_GCS_URI'] ), }, "authConfig": { "authType": "OAUTH", "oauthConfig": {"service_account": "<service-account>"} }, }, ) mdb_crud
Executar queries de linguagem natural
No Vertex AI, clique em Extensions no menu de navegação à esquerda. Sua nova extensão chamada MongoDB Vertex API Interpreter aparece na lista de extensões.
Os exemplos a seguir demonstram duas consultas de linguagem natural diferentes que você pode usar para consultar seus dados no Atlas:
Neste exemplo, você solicita à Vertex AI para encontrar o ano de lançamento de um filme específico intitulado A Corner in Wheat. Você pode executar essa query de linguagem natural usando a plataforma Vertex AI ou seu bloco de anotações do CoLab:
Selecione a extensão chamada MongoDB Vertex API Interpreter e insira a seguinte query de linguagem natural:
Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies


Cole e execute o seguinte código em mongodb-vertex-ai-extension.ipynb para encontrar a data de lançamento de um filme específico:
## Please replace accordingly to your project ## Operation Ids os.environ['FIND_ONE_OP_ID'] = "findone_mdb" ## NL Queries os.environ['FIND_ONE_NL_QUERY'] = "Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" ### Test data setup os.environ['TITLE_FILTER_CLAUSE'] = "A Corner in Wheat" from vertexai.preview.generative_models import GenerativeModel, Tool fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findOneResponse = fc_chat.send_message(os.environ['FIND_ONE_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findOneResponse)
response = mdb_crud.execute( operation_id = findOneResponse.candidates[0].content.parts[0].function_call.name, operation_params = findOneResponse.candidates[0].content.parts[0].function_call.args ) print(response)
Neste exemplo, você solicita à Vertex AI para encontrar todos os filmes lançados no ano 1924. Você pode executar essa query de linguagem natural usando a plataforma Vertex AI ou seu bloco de anotações do CoLab:
Selecione a extensão chamada MongoDB Vertex API Interpreter e insira a seguinte query de linguagem natural:
give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies

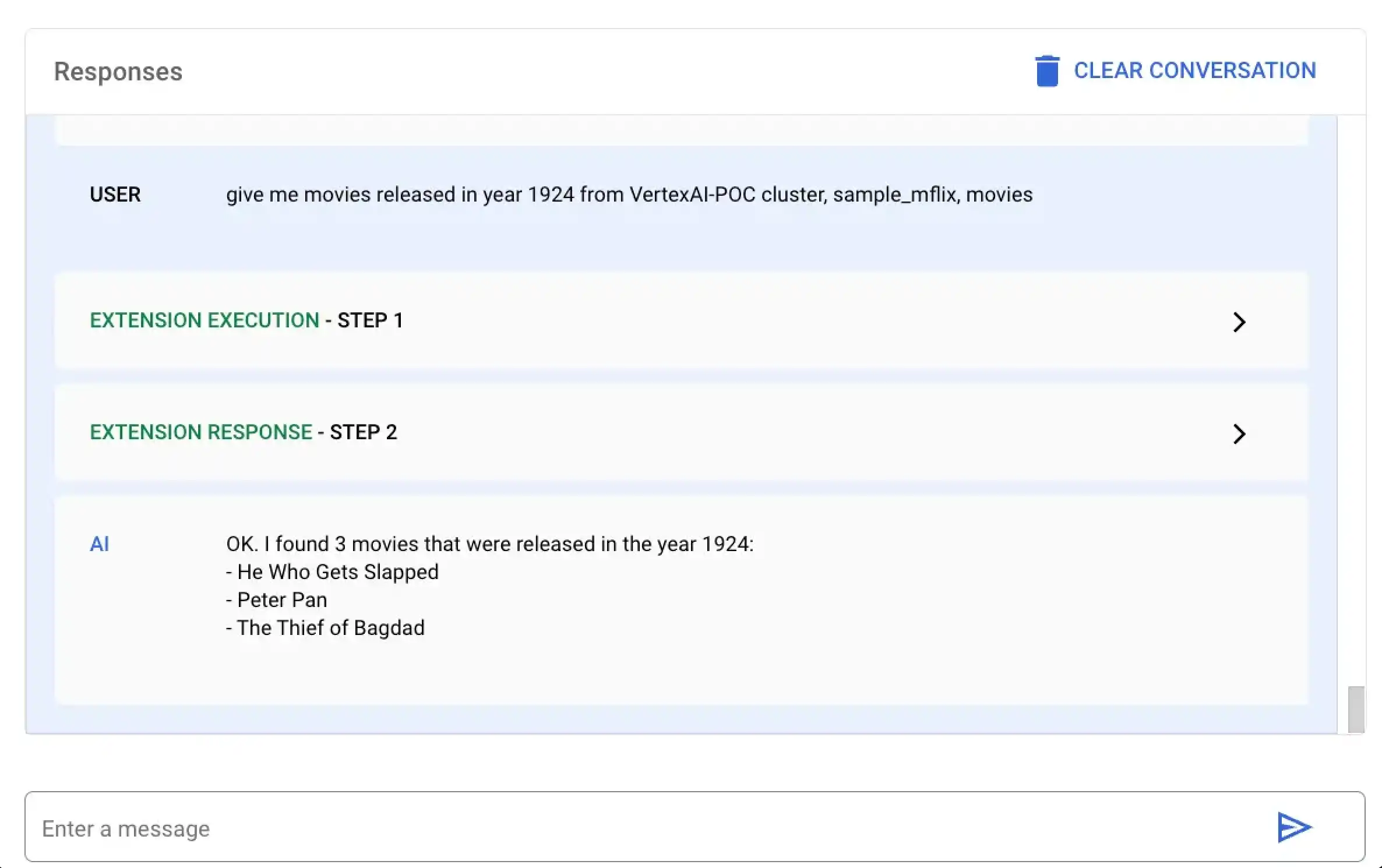
Cole e execute o seguinte código em mongodb-vertex-ai-extension.ipynb para localizar todos os filmes lançados em um ano específico:
## This is just a sample values please replace accordingly to your project ## Operation Ids os.environ['FIND_MANY_OP_ID'] = "findmany_mdb" ## NL Queries os.environ['FIND_MANY_NL_QUERY'] = "give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" os.environ['YEAR'] = 1924 fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findmanyResponse = fc_chat.send_message(os.environ['FIND_MANY_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findmanyResponse)
response = mdb_crud.execute( operation_id = findmanyResponse.candidates[0].content.parts[0].function_call.name, operation_params = findmanyResponse.candidates[0].content.parts[0].function_call.args ) print(response)