중요
$rankFusion MongoDB 8.0 이상을 사용하는 배포서버에만 사용할 수 있습니다.
정의
$rankFusion$rankFusion먼저 모든 입력 파이프라인을 독립적으로 실행한 다음 입력 파이프라인 결과를 중복 제거하고 최종 순위가 지정된 결과 설정하다 로 결합합니다.$rankFusion입력 문서가 입력 파이프라인에 나타나는 순위와 파이프라인 가중치를 기반으로 순위가 지정된 문서 설정하다 출력합니다. 이 단계에서는 상호 순위 퓨전 알고리즘 사용하여 입력 파이프라인의 결합된 결과의 순위를 매깁니다.여러 기준을 기반으로 단일 컬렉션 에서 문서를 검색 하고 지정된 모든 기준을 고려하여 최종 순위가 설정하다 결과 집합을 조회
$rankFusion를 사용합니다.
구문
이 단계에는 다음 구문이 있습니다.
{ $rankFusion: { input: { pipelines: { <myPipeline1>: <expression>, <myPipeline2>: <expression>, ... } }, combination: { weights: { <myPipeline1>: <numeric expression>, <myPipeline2>: <numeric expression>, ... } }, scoreDetails: <bool> } }
명령 필드
$rankFusion 은(는) 다음 필드를 사용합니다.
필드 | 유형 | 설명 |
|---|---|---|
| 객체 |
|
input.pipelines | 객체 | 해당 파이프라인 정의하는 집계 단계에 대한 파이프라인 이름 맵이 포함되어 있습니다. 입력 파이프라인 제한 사항에 대한 자세한 내용은 입력 파이프라인 및 입력 파이프라인 이름을 참조하세요. |
| 객체 | 선택 사항. |
combination.weights | 객체 | 선택 사항. 가중치를 지정하지 않으면 기본값 은 1입니다. |
| 부울 | 기본값은 false입니다. |
행동
컬렉션
$rankFusion 는 단일 컬렉션 에만 사용할 수 있습니다. 데이터베이스 범위에서는 이 집계 단계를 사용할 수 없습니다.
De-Duplication
$rankFusion 최종 출력에서 여러 입력 파이프라인에서 결과의 중복을 제거합니다. 각 고유 입력 문서 입력 파이프라인 출력에 문서 나타나는 횟수에 관계없이 $rankFusion 출력에 최대 한 번 표시됩니다.
입력 파이프라인
각 input 파이프라인 선택 파이프라인과 순위 파이프라인 모두여야 합니다.
선택 파이프라인
선택 파이프라인은 검색 후 수정을 수행하지 않고 컬렉션 에서 문서 설정하다 검색합니다. $rankFusion 은(는) 서로 다른 입력 파이프라인의 문서를 비교하므로 모든 입력 파이프라인이 수정되지 않은 동일한 문서를 출력해야 합니다.
참고
$rankFusion로 검색 한 문서를 수정하려면 $rankFusion 단계 이후에 수정하세요.
선택 파이프라인 다음 단계만 포함되어야 합니다.
순위 지정 파이프라인
순위가 지정된 파이프라인 문서를 정렬하거나 순서를 지정합니다. $rankFusion 은(는) 순위가 매겨진 파이프라인 결과의 순서를 사용하여 출력 순위에 영향을 줍니다. 순위가 매겨진 파이프라인은 다음 기준 중 하나를 충족해야 합니다.
다음의 순서가 지정된 단계 중 하나부터 시작합니다.
명시적인
$sort단계를 포함합니다.
입력 파이프라인 이름
input 의 파이프라인 이름은 다음 제한 사항을 충족해야 합니다.
빈 문자열이 아니어야 합니다.
다음으로 시작하면 안 됩니다.
$문자열의 어느 곳에도 ASCII null 문자 구분 기호
\0를 포함하지 않아야 합니다.다음을 포함해서는 안 됩니다.
.
RRF(Reciprocal Rank 퓨전) 공식
$rankFusion RRF(Reciprocal Rank Federation) 공식에 따라 결과를 정렬합니다. 이 단계에서는 각 문서 의 RRF 점수를 출력 결과의 score 메타데이터 필드 에 배치합니다. RRF 공식은 다음 요소를 조합하여 문서의 순위를 매깁니다.
입력 파이프라인 결과의 문서 배치
문서 다양한 입력 파이프라인에 나타나는 횟수
입력 파이프라인의
weights입니다.
예시 를 들어, 문서 여러 파이프라인 결과 세트에서 높은 순위를 가진 경우, 해당 문서 의 RRF 점수는 동일한 문서 일부 입력 파이프라인에서 순위가 동일하지만 존재하지 않는 경우(또는 순위가 더 낮은 경우)보다 높습니다. 다른 파이프라인에서
RRF(Reciprocal Rank Federation) 공식은 다음 대수 연산과 동일합니다.

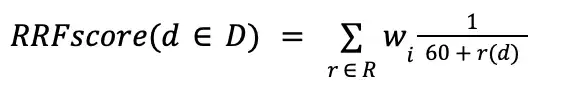
참고
이 수식에서 60 은 MongoDB 결정한 민감도 매개 변수입니다.
아래 표에는 RRF 공식이 사용하는 변수가 포함되어 있습니다.
변수 | 설명 |
|---|---|
D | 전체 작업에 대한 결과 문서 설정하다 . |
d | RRF 점수가 계산되는 문서 입니다. |
R |
|
r(d) | 이 입력 파이프라인 에 있는 문서 |
w |
|
요약의 각 텀 는 input 파이프라인 중 하나에 있는 문서 d 의 모양을 나타냅니다. d 의 총 RRF 점수는 d 가 나타나는 모든 입력 파이프라인에서 이러한 각 용어의 합계입니다.
RRF 계산 예제
하나의 $search 입력 파이프라인과 하나의 $vectorSearch 입력 파이프라인 있는 $rankFusion 파이프라인 단계를 생각해 보세요.
모든 입력 파이프라인은 동일한 3 문서( Document1, Document2, Document3)를 출력합니다.
$search 파이프라인 다음 순서로 문서의 순위를 지정합니다.
Document3Document2Document1
$vectorSearch 파이프라인 다음 순서로 문서의 순위를 지정합니다.
Document1Document2Document3.
rankFusion 다음 연산을 통해 Document1 에 대한 RRF 점수를 계산합니다.
RRFscore(Document1) = 1/(60 + search_rank_of_Document1) + (1/(60 + vectorSearch_rank_of_Document1)) RRFscore(Document1) = 1/63 + 1/61 RRFscore(Document1) = 0.0322664585
Document1 의 score 메타데이터 필드 0.0322664585입니다.
점수 상세 정보
scoreDetails 을(를) true(으)로 설정하다 $rankFusion 이(가) 각 문서 에 대해 scoreDetails 메타데이터 필드 생성합니다. scoreDetails 필드 에는 최종 순위에 대한 정보가 포함되어 있습니다.
참고
scoreDetails 를 true로 설정하다 $rankFusion 가 각 문서 에 대해 scoreDetails 메타데이터 필드 설정하지만 scoreDetails 메타필드를 자동으로 출력하지는 않습니다.
scoreDetails 메타데이터 필드 보려면 다음 중 하나를 수행해야 합니다.
$rankFusion다음에$project단계를 사용하여scoreDetails필드 프로젝트.$rankFusion다음에$addFields단계를 사용하여 파이프라인 출력에scoreDetails필드 추가합니다.
scoreDetails 필드 에는 다음과 같은 하위 필드가 포함되어 있습니다.
필드 | 설명 |
|---|---|
| 이 문서에 대한 RRF 점수의 숫자 값입니다. |
|
|
| 각 배열 항목에 이 문서 출력하는 입력 파이프라인에 대한 정보가 포함된 배열 입니다. |
details 필드 의 각 배열 항목에는 다음 하위 필드가 포함되어 있습니다.
필드 | 설명 |
|---|---|
| 이 문서 출력하는 입력 파이프라인 의 이름입니다. |
| 입력 파이프라인 에서 이 문서 의 순위입니다. 다른 파이프라인 단계 출력에서 반환된 문서 이 파이프라인 단계의 출력에 없는 경우 파이프라인 단계 출력의 순위는 |
| 입력 파이프라인 의 가중치입니다. |
| 선택 사항. 입력 파이프라인 이 문서 에 대해 |
| 선택 사항. 입력 파이프라인 이 문서 에 대한 |
| 입력 파이프라인 의 |
경고
MongoDB scoreDetails에 대한 특정 출력 형식을 보장하지 않습니다.
예시 들어 다음 코드 블록은 $search, $vectorSearch 및 $match 입력 파이프라인이 있는 $rankFusion 작업에 대한 scoreDetails 필드 보여줍니다.
{ value: 0.030621785881252923, description: "value output by reciprocal rank fusion algorithm, computed as sum of weight * (1 / (60 + rank)) across input pipelines from which this document is output, from:" details: [ { inputPipelineName: 'search', rank: 2, weight: 1, value: 0.3876491287, description: "sum of:", details: [... omitted for brevity in this example ...] }, { inputPipelineName: 'vector', rank: 9, weight: 3, value: 0.7793490886688232, details: [ ] }, { inputPipelineName: 'match', rank: 10, weight: 1, details: [] } ] }
결과 설명
MongoDB $rankFusion 연산을 기존 집계 단계 설정하다 로 변환하여, 이를 조합하여 쿼리 실행 전에 출력 결과를 계산합니다. 결과 설명 $rankFusion 작업에 대한 결과 설명은 $rankFusion 가 최종 결과를 구성하는 데 사용하는 기본 집계 단계의 전체 실행을 보여줍니다.
예시
이 예시 임베딩 및 텍스트 필드가 있는 컬렉션 사용합니다. 컬렉션 에 search 및 vectorSearch 유형 인덱스를 만듭니다.
다음 인덱스 정의는 인덱싱된 필드에 대해 쿼리를 실행 위해 컬렉션 에서 동적으로 인덱싱할 수 있는 모든 필드를 자동으로 인덱싱합니다.$search
db.embedded_movies.createSearchIndex( "search_index", { mappings: { dynamic: true } } )
다음 인덱스 정의는 해당 필드에 대해 $vectorSearch 쿼리를 실행하기 위해 컬렉션의 임베딩이 있는 필드를 인덱싱합니다.
db.embedded_movies.createSearchIndex( "vector_index", "vectorSearch", { "fields": [ { "type": "vector", "path": "<FIELD_NAME>", "numDimensions": <NUMBER_OF_DIMENSIONS>, "similarity": "dotProduct" } ] } );
다음 집계 파이프라인 다음 입력 파이프라인과 함께 $rankFusion 을(를) 사용합니다.
파이프라인 | 반환된 문서 수 | 설명 |
|---|---|---|
| 20 | 임베딩으로 지정된 텀 에 대해 |
| 20 | 동일한 텀 에 대해 전체 텍스트 검색 실행하고 결과를 20 개 문서로 제한합니다. |
1 db.embedded_movies.aggregate( [ 2 { 3 $rankFusion: { 4 input: { 5 pipelines: { 6 searchOne: [ 7 { 8 "$vectorSearch": { 9 "index": "<INDEX_NAME>", 10 "path": "<FIELD_NAME>", 11 "queryVector": <QUERY_EMBEDDINGS>, 12 "numCandidates": 500, 13 "limit": 20 14 } 15 } 16 ], 17 searchTwo: [ 18 { 19 "$search": { 20 "index": "<INDEX_NAME>", 21 "text": { 22 "query": "<QUERY_TERM>", 23 "path": "<FIELD_NAME>" 24 } 25 } 26 }, 27 { "$limit": 20 } 28 ], 29 } 30 } 31 } 32 }, 33 { $limit: 20 } 34 ] )
이 작업은 다음 조치를 수행합니다.
input파이프라인을 실행합니다.반환된 결과를 결합합니다.
$rankFusion파이프라인 의 상위 20 순위 결과인 첫 번째 20 문서를 출력합니다.
이 페이지의 Node.js 예제에서는 Atlas 샘플 데이터 세트의 sample_mflix 데이터베이스 사용합니다. 무료 MongoDB Atlas cluster 생성하고 샘플 데이터 세트를 로드하는 방법을 학습하려면 MongoDB Node.js 운전자 설명서에서 시작하기 를 참조하세요.
MongoDB Node.js 운전자 사용하여 집계 파이프라인 에 $rankFusion 단계를 추가하려면 파이프라인 객체 에서 $rankFusion 연산자 사용합니다.
다음 예시 실행 전에 default이라는 이름의 Atlas Search 인덱스 만들어야 합니다. 애플리케이션 에 다음 코드를 포함하여 movies 컬렉션 에 검색 인덱스 생성합니다.
const index = { name: "default", definition: { mappings: { dynamic: true } } } const result = collection.createSearchIndex(index);
다음 예시 default 검색 인덱스 사용하여 $search 작업을 수행하는 두 파이프라인 searchPlot 및 searchGenre를 실행하는 파이프라인 단계를 만듭니다. 그런 다음 $rankFusion 단계에서는 각 $search 파이프라인에 할당된 가중치를 기준으로 검색 결과의 순위를 지정하고 정렬된 결과를 반환합니다. $addFields 단계에는 반환 문서에 scoreDetails 필드 포함되어 있습니다. 그런 다음 이 예시 에서는 집계 파이프라인 실행합니다.
const pipeline = [ { $rankFusion: { input: { pipelines: { searchPlot: [ { $search: { index: "default", text: { query: "space", path: "plot"} } } ], searchGenre: [ { $search: { index: "default", text: { query: "adventure", path: "genres" } } } ] } }, combination: { weights: {searchPlot: 0.6, searchGenre: 0.4} }, scoreDetails: true } }, { $addFields: { scoreDetails: { $meta: "searchScoreDetails" } } } ]; const cursor = collection.aggregate(pipeline); return cursor;