참고
Atlas는 현재 미국에 위치한 AWS 리전에서만 지식 기반으로 제공됩니다.
MongoDB Atlas Amazon 베드락의 지식 베이스 로 사용하여 제너레이티브 AI 애플리케이션을 빌드 , RAG(검색 강화 생성)를 구현 , 에이전트를 빌드 .
개요
Amazon Bedrock 지식 기반과 Atlas의 통합으로 다음과 같은 사용 사례가 가능합니다.
MongoDB Vector Search와 함께 기초 모델을 사용하여 AI 애플리케이션을 빌드 하고 RAG를 구현 . 시작하려면 시작하기를 참조하세요.
지식 기반에 대한 MongoDB Vector Search 및 MongoDB Search를 사용하여 하이브리드 검색 활성화하세요. 자세한 학습 은 Amazon 기반 및 Atlas 사용한 하이브리드 검색을 참조하세요.
시작하기
이 튜토리얼에서는 Amazon 베드락과 함께 MongoDB Vector Search를 사용하는 방법을 설명합니다. 구체적으로 다음 조치를 수행합니다.
사용자 정의 데이터를 Amazon S3 버킷에 로드합니다.
필요 시 AWS PrivateLink를 사용하여 엔드포인트 서비스를 구성합니다.
데이터에 MongoDB Vector Search 인덱스 생성합니다.
지식 기반을 생성하여 Atlas에 데이터를 저장합니다.
MongoDB Vector Search를 사용하여 RAG를 구현 에이전트 생성합니다.
배경
Amazon Bedrock은 생성형 인공지능 애플리케이션을 빌드하기 위한 완전 관리형 서비스입니다. 이를 통해 다양한 AI 회사의 파운데이션 모델(FM)을 단일 API로 활용할 수 있습니다.
MongoDB Vector Search를 Amazon 기반의 지식 베이스로 사용하여 Atlas 에 사용자 지정 데이터를 저장 하고 에이전트 만들어 RAG를 구현 하고 데이터에 대한 질문에 답변 . RAG에 대해 자세히 학습 RAG, MongoDB 사용한 검색-증강 생성(RAG)을 참조하세요.
전제 조건
이 튜토리얼을 완료하려면 다음 조건을 충족해야 합니다.
사용자 지정 데이터 로드
텍스트 데이터를 포함하는 Amazon S3 버킷이 아직 없는 경우, 새 버킷을 생성하고 공개적으로 액세스할 수 있는 다음과 같은 MongoDB 권장사항에 대한 PDF를 로드합니다.
PDF를 다운로드하세요.
MongoDB 모범 사례 가이드로 이동합니다.
Read Whitepaper 또는 Email me the PDF를 클릭하여 PDF에 액세스하세요.
PDF를 다운로드하여 로컬에 저장합니다.
PDF를 Amazon S3 버킷에 업로드합니다.
단계에 따라 S3 버킷을 생성합니다. 설명이 포함된 Bucket Name를 사용해야 합니다.
단계에 따라 버킷에 파일 업로드합니다. 방금 다운로드한 PDF가 포함된 파일 을 선택합니다.
엔드포인트 서비스 구성
기본값 으로 Amazon 베드락은 공용 인터넷을 통해 지식창고에 연결합니다. 연결을 더욱 안전하게 보호하기 위해 MongoDB Vector Search는 AWS PrivateLink 엔드포인트 서비스를 통해 가상 네트워크를 통해 지식창고에 연결할 수 있도록 지원합니다.
필요 시 다음 단계를 완료하여 Atlas 클러스터의 AWS PrivateLink 비공개 엔드포인트에 연결하는 엔드포인트 서비스를 활성화합니다.
Atlas에서 비공개 엔드포인트를 설정합니다.
단계에 따라 Atlas 클러스터에 대한 AWS PrivateLink 비공개 엔드포인트를 설정하세요. 프라이빗 엔드포인트를 식별할 수 있도록 설명적인 VPC ID를 사용해야 합니다.
자세한 내용은 Atlas의 비공개 엔드포인트에 대해 알아보세요.
엔드포인트 서비스를 구성합니다.
MongoDB와 파트너사는 트래픽을 비공개 엔드포인트로 전달하는 네트워크 로드 밸런서가 지원하는 엔드포인트 서비스를 구성하는 데 사용할 수 있는 클라우드 개발 키트(CDK)를 제공합니다.
CDK Github 리포지토리 에 지정된 단계에 따라 CDK 스크립트를 준비하고 실행.
MongoDB Vector Search 인덱스 만들기
이 섹션에서는 컬렉션 에 MongoDB Vector Search 인덱스 생성하여 Atlas 벡터 저장 라고도 하는 벡터 데이터베이스 로 설정하다 .
필요한 액세스 권한
MongoDB Vector Search 인덱스 만들려면 Atlas 프로젝트에 대한 Project Data Access Admin 이상의 액세스 있어야 합니다.
절차
Atlas 에서 프로젝트 의 Data Explorer 페이지로 이동합니다.
아직 표시되지 않은 경우 탐색 표시줄의 Organizations 메뉴에서 프로젝트가 포함된 조직을 선택합니다.
아직 표시되지 않은 경우 내비게이션 바의 Projects 메뉴에서 프로젝트를 선택합니다.
사이드바에서 Database 제목 아래의 Data Explorer를 클릭합니다.
데이터 탐색기 가 표시됩니다.
Atlas에서 클러스터의 Search & Vector Search 페이지로 이동합니다.
Search & Vector Search 옵션 또는 Data Explorer에서 MongoDB 검색하다 페이지로 이동할 수 있습니다.
아직 표시되지 않은 경우 탐색 표시줄의 Organizations 메뉴에서 프로젝트가 포함된 조직을 선택합니다.
아직 표시되지 않은 경우 내비게이션 바의 Projects 메뉴에서 프로젝트를 선택합니다.
사이드바에서 Database 제목 아래의 Search & Vector Search를 클릭합니다.
클러스터가 없는 경우 Create cluster를 클릭하여 클러스터를 생성합니다. 자세히 알아보려면 클러스터 생성을 참조하세요.
프로젝트에 여러 클러스터가 있는 경우 Select cluster 드롭다운에서 사용할 클러스터를 선택한 후 Go to Search를 클릭합니다.
검색 & 벡터 검색 페이지가 표시됩니다.
아직 표시되지 않은 경우 탐색 표시줄의 Organizations 메뉴에서 프로젝트가 포함된 조직을 선택합니다.
아직 표시되지 않은 경우 내비게이션 바의 Projects 메뉴에서 프로젝트를 선택합니다.
사이드바에서 Database 제목 아래의 Data Explorer를 클릭합니다.
데이터베이스를 확장하고 컬렉션을 선택합니다.
컬렉션의 Indexes 탭을 클릭합니다.
배너에서 Search and Vector Search 링크를 클릭합니다.
검색 & 벡터 검색 페이지가 표시됩니다.
인덱스 구성을 시작합니다.
페이지에서 다음 항목을 선택한 후 Next를 클릭합니다.
Search Type | Vector Search 인덱스 유형을 선택합니다. |
Index Name and Data Source | 다음 정보를 지정합니다.
|
Configuration Method | For a guided experience, select Visual Editor. To edit the raw index definition, select JSON Editor. |
중요:
MongoDB Search 인덱스 의 이름은 기본값 으로 default 으로 지정됩니다. 이 이름을 유지하면 해당 인덱스 연산자에 다른 index 옵션을 지정하지 않는 모든 MongoDB Search 쿼리 대한 기본값 검색 인덱스 됩니다. 여러 인덱스를 생성하는 경우 인덱스 전체에서 일관적인 되고 설명이 포함된 명명 규칙을 유지하는 것이 좋습니다.
MongoDB Vector Search 인덱스 정의합니다.
이 vectorSearch 유형의 인덱스 정의는 다음 필드를 인덱싱합니다.
embedding필드를 벡터 유형으로 인덱싱합니다.embedding필드에는 지식 기반을 구성할 때 지정한 임베딩 모델을 사용하여 생성된 벡터 임베딩이 포함됩니다. 인덱스 정의는1024벡터 차원을 지정하고cosine을 사용하여 유사성을 측정합니다.bedrock_metadata,bedrock_text_chunk및x-amz-bedrock-kb-document-page-number필드를 데이터 사전 필터링을 위한 필터 유형으로 사용합니다. 또한 지식 기반을 구성할 때 Amazon Bedrock에서 이러한 필드를 지정합니다.
참고
이전에 필터 필드 page_number로 인덱스를 생성한 경우, 인덱스 정의를 새 필터 필드 이름 x-amz-bedrock-kb-document-page-number로 업데이트해야 합니다. Amazon Bedrock이 필드 이름을 업데이트했으며, 이전 필드 이름을 사용하는 인덱스는 더 이상 Amazon Bedrock 지식 기반에서 제대로 작동하지 않습니다.
embedding을 인덱싱할 필드로 지정하고 1024개의 차원을 지정합니다.
인덱스를 구성하려면 다음을 수행합니다.
Similarity Method 드롭다운 메뉴에서 Cosine을(를) 선택합니다.
Filter Field 섹션에서 데이터를 필터링하기 위해
bedrock_metadata,bedrock_text_chunk및x-amz-bedrock-kb-document-page-number필드를 지정합니다.
JSON 편집기에 다음 인덱스 정의를 붙여넣습니다.
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
기술 자료 만들기
이 섹션에서는 사용자 지정 데이터를 벡터 저장소에 로드하기 위한 지식 기반을 생성합니다.
모델 액세스를 관리합니다.
Amazon 베드락은 FM 에 대한 액세스 자동으로 부여하지 않습니다. 아직 추가하지 않았다면 단계에 따라 타이탄1 임베딩 G - 텍스트 및 인간 클로드 V2 1 에 대한 모델 액세스 추가합니다. 모델.
Atlas를 지식 기반에 연결하세요.
Vector database 섹션에서 Use an existing vector store를 선택합니다.
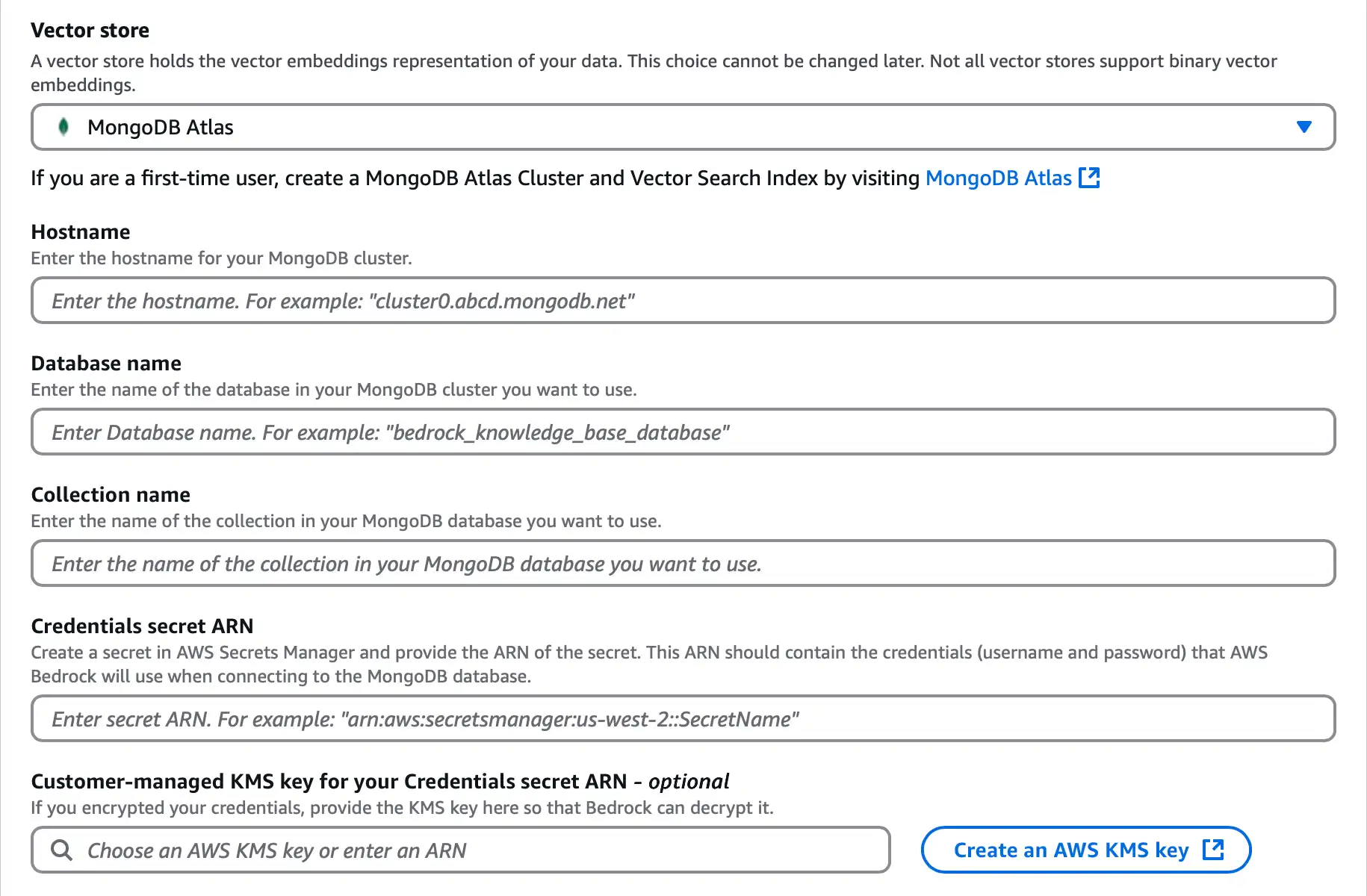
MongoDB Atlas를 선택하고 다음 옵션을 구성합니다.
![Amazon Bedrock 벡터 저장소 구성 섹션의 스크린샷]() 클릭하여 확대
클릭하여 확대의 Hostname 경우 연결 문자열 에 있는 Atlas 클러스터의 URL을 입력하세요. 호스트 이름은 다음 형식을 사용합니다:
<clusterName>.mongodb.net Database name에
bedrock_db을(를) 입력합니다.Collection name에
test을(를) 입력합니다.에 Atlas cluster 자격 Credentials secret ARN 증명 포함된 시크릿의 ARN을 입력합니다. 자세한 학습 은 Amazon Web Services Secret 관리자 개념을 참조하세요.
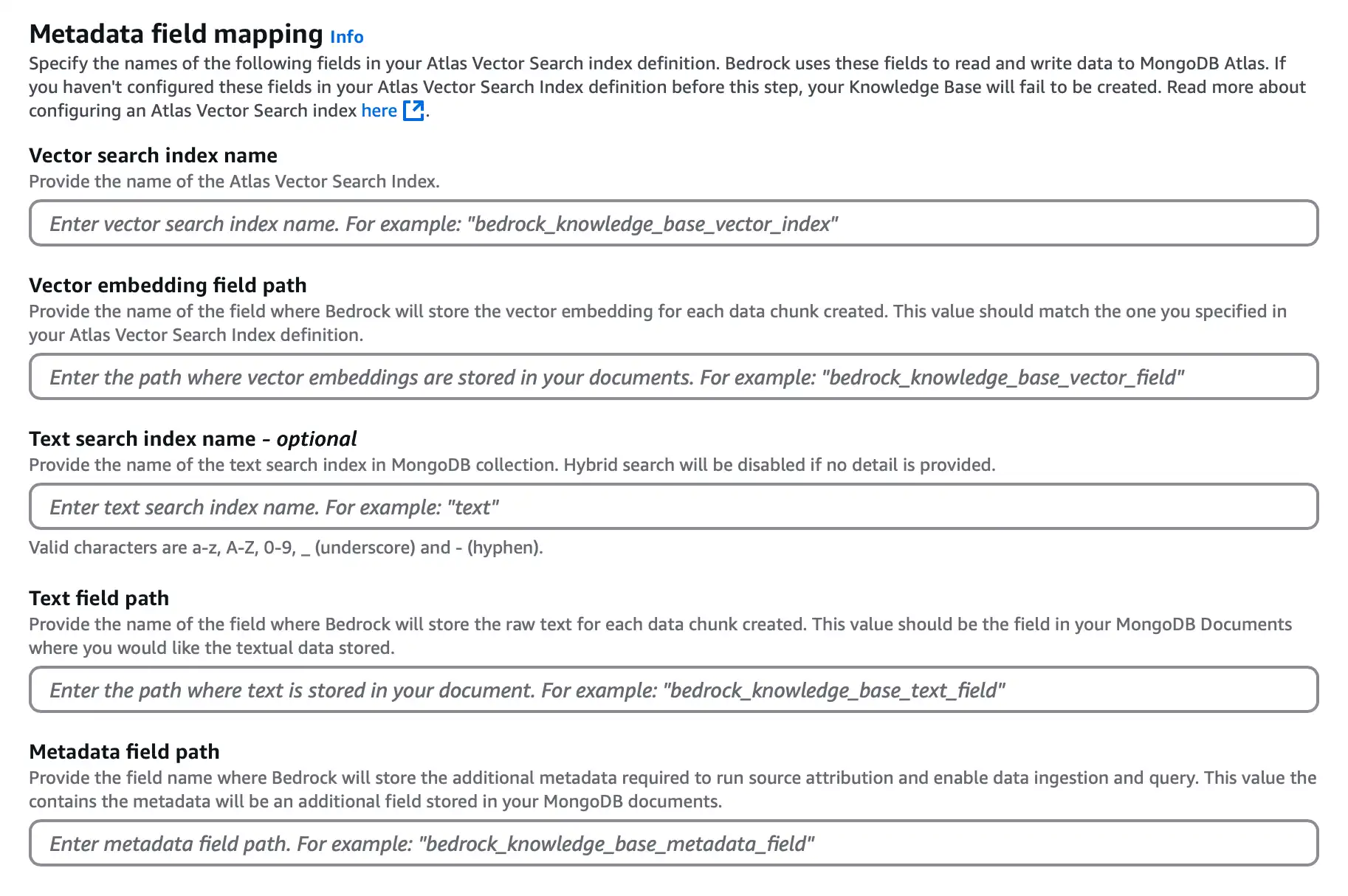
Metadata field mapping 섹션에서 다음 옵션을 구성하여 Atlas 데이터 소스 포함하고 저장 사용하는 MongoDB Vector Search 인덱스 와 필드 이름을 결정합니다.
![벡터 저장소 필드 매핑 구성 섹션의 스크린샷]() 클릭하여 확대
클릭하여 확대Vector search index name에
vector_index을(를) 입력합니다.Vector embedding field path에
embedding을(를) 입력합니다.Text field path에
bedrock_text_chunk을(를) 입력합니다.Metadata field path에
bedrock_metadata을(를) 입력합니다.
참고
선택 사항으로 Text search index name 필드를 지정하여 하이브리드 검색을 구성할 수 있습니다. 자세히 알아보려면 Amazon Bedrock 및 Atlas를 사용한 하이브리드 검색을 참조하세요.
엔드포인트 서비스를 구성한 경우 PrivateLink Service Name를 입력합니다.
Next를 클릭합니다.


데이터 소스를 동기화합니다.
Amazon Bedrock이 지식 기반을 생성한 후에는 데이터를 동기화하라는 메시지가 표시됩니다. Data source 섹션에서 데이터 소스를 선택하고 Sync를 클릭하여 S3 버킷의 데이터를 동기화하고 Atlas에 로드합니다.
동기화 가 완료되면 Atlas 사용하는 경우 bedrock_db.test Atlas UI 의 네임스페이스 로이동하여 벡터 임베딩을 확인할 수 있습니다.
에이전트 빌드
이 섹션에서는 MongoDB Vector Search를 사용하여 RAG를 구현 하고 데이터에 대한 질문에 답변 에이전트 배포 . 이 에이전트 에 메시지를 표시하면 다음을 수행합니다.
Atlas에 저장된 사용자 지정 데이터에 액세스하기 위해 지식 기반에 연결합니다.
MongoDB Vector Search를 사용하여 프롬프트에 따라 벡터 저장 에서 관련 문서를 조회 .
AI 채팅 모델을 활용하여 이러한 문서를 기반으로 상황 인식 응답을 생성합니다.
다음 단계를 완료하여 RAG 에이전트를 생성하고 테스트합니다.
모델을 선택하고 프롬프트를 제공합니다.
기본적으로 Amazon 베드락은 에이전트에 액세스할 수 있는 새 IAM 역할을 생성합니다. Agent details 섹션에서 다음을 지정합니다.
드롭다운 메뉴에서 데이터에 대한 질문에 답하는 데 사용하는 제공자 및 AI 모델로 Anthropic 및 Claude V2.1을 선택합니다.
참고
Amazon Bedrock은 FM에 대한 액세스 권한을 자동으로 부여하지 않습니다. 아직 추가하지 않았다면, Anthropic Claude V2.1 모델에 대한 모델 액세스 추가 단계를 따르세요.
에이전트가 작업을 완료하는 방법을 알 수 있도록 지침을 제공합니다.
예를 들어 샘플 데이터 를 사용하는 경우 다음 지침을 붙여넣습니다.
You are a friendly AI chatbot that answers questions about working with MongoDB. Save를 클릭합니다.
에이전트를 테스트합니다.
Prepare 버튼을 클릭합니다.
Test 을(를) 클릭합니다. 테스트 Amazon 아직 표시되지 않은 경우 에이전트 세부 정보 오른쪽에 테스트 창이 표시됩니다.
테스트 창 에서 프롬프트를 입력합니다. 에이전트 모델에 프롬프트를 표시하고, MongoDB Vector Search를 사용하여 관련 문서를 조회 다음, 문서를 기반으로 응답을 생성합니다.
샘플 데이터를 사용한 경우 다음 프롬프트를 입력합니다. 생성된 응답은 다를 수 있습니다.
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] 팁
에이전트의 응답에서 주석을 클릭하면 MongoDB Vector Search가 검색한 텍스트 청크 볼 수 있습니다.
기타 리소스
문제를 해결하려면 Amazon Bedrock 지식 기반 통합 문제 해결을 참조하세요.