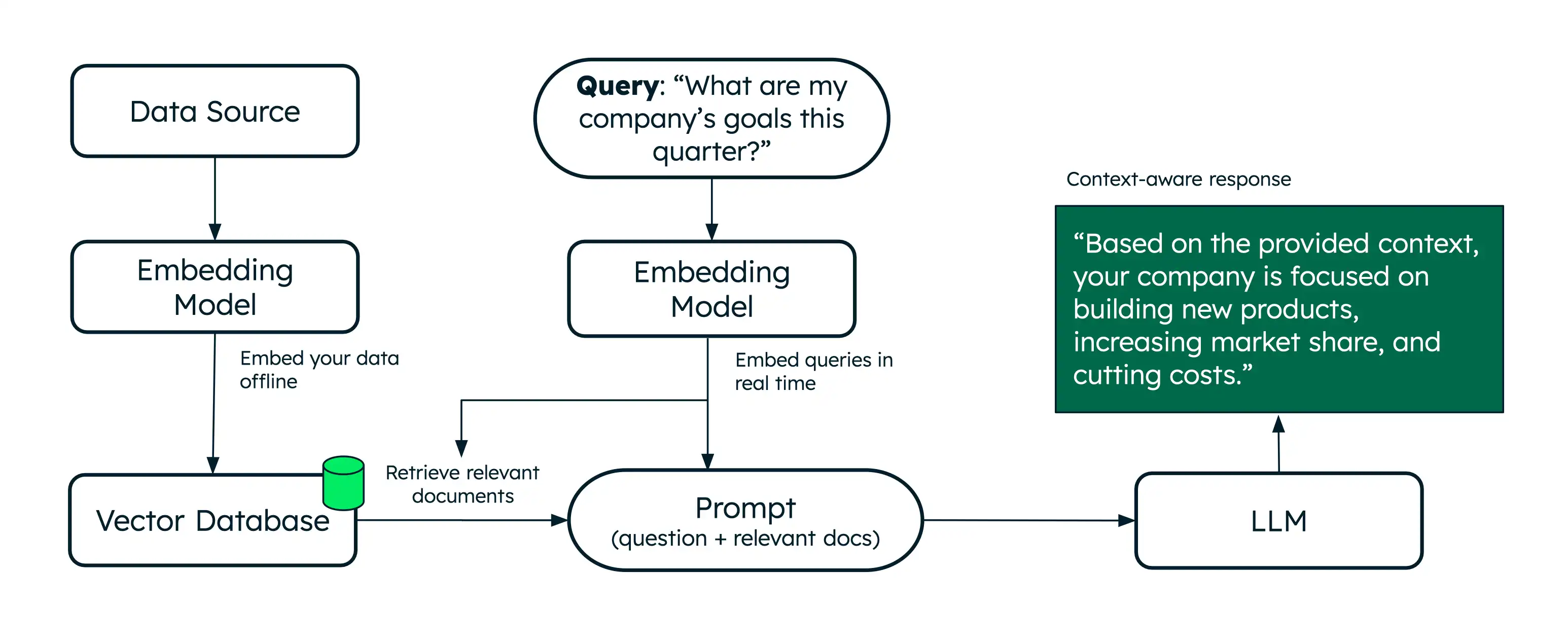
検索拡張生成(RAG)は、セマンティック検索を使用して、大規模な言語モデル(llm)に追加のデータを増やして、より正確な応答を生成できるようにするアーキテクチャです。
セマンティック検索では意味に基づいて関連するドキュメントが検索されますが、RAG では検索されたドキュメントをコンテキストとして LLM に提供することで、さらにステップが進められます。この追加のコンテキストは、LLM がユーザーのクエリに対してより正確な応答を生成し、プロンプトを軽減するのに役立ちます。Voyage AI は、RAG アプリケーションの取得を強化するためのクラス最高の埋め込みと再ランク付けモデルを提供します。
コードを記述せずに RAG を試すには、Playground を使用して、Voyage AIによって強化されたAIチャットボットを構築します。詳しくは、チャットボット デモ ビルダ を参照してください。
Tutorial
次のチュートリアルでは、Voyage 埋め込みを使用して RAG を実装する方法を説明します。
RAG を使用する理由
LLM を使用する際、以下の制限事項に直面する可能性があります。
古いデータ: LM は一定の点まで静的データセットで訓練されます。つまり、知識ベースが限られており、古いデータを使用する可能性があります。
追加データへのアクセスなし: LM は、ローカル データ、パーソナライズされたデータ、またはドメイン固有のデータにアクセスできません。そのため、特定のドメインに関する知識が不足することがあります。
説明: 不完全なデータまたは古くなったデータを使用する場合、LVM は不正確な応答を生成する可能性があります。
RAG は、関連するドキュメントをリアルタイムで取得するために、取得ステップ(通常はセマンティック検索によって強化)を追加することでこれらの制限に対処します。追加のコンテキストを提供すると、TLM はより正確な応答を生成するのに役立ちます。これにより、RAG は、パーソナライズされたドメイン固有の質問応答とテキスト生成を提供するAIチャットボットを構築するための効果的なアーキテクチャになります。
ベクトルデータベースとは
ベクトルデータベースは、ベクトル埋め込みを保存し、効率的に検索するように設計された特殊データベースです。メモリにベクトルを保存することはプロトタイプ作成や実験に適していますが、本番環境の RAG アプリケーションでは通常、より大きなコレクションから効率的な検索を実行するためにベクトルデータベースが必要です。
MongoDB はベクトルストレージと検索のネイティブ サポートを備えているため、他のデータと並行してベクトル埋め込みを保存および検索するのに便利です。詳細については、 MongoDB Vector Search 概要を参照してください。
次のステップ
その他のチュートリアルについては、次のリソースを参照してください。
一般的な LLM フレームワークとAIサービスを使用して RAG を実装する方法については、MongoDB AI統合を参照してください。
AIエージェントを構築し、エージェント RAG を実装するには、 MongoDBでAIエージェントをビルドするを参照してください。