MongoDB は、Voyage AI のベストインクラスの埋め込みと再ランク付けモデル用のAPIを提供します。ベクトルデータベースや大規模言語モデル(llm)など、 AIスタックの他の部分 とともに使用されることで、正確なAI検索と取得で本番環境に対応できるアプリケーションを構築できます。
構築の開始
開始するには次のリソースを使用してください。
APIキーの作成、最初の埋め込みの生成、RAGアプリケーションのビルド を行います。
MongoDB AtlasでAPIキーを管理する方法を学びます。
API仕様 をご覧ください。
Voyage AIモデル
Voyage AI の埋め込みモデルと再ランク付けモデルは、検索精度の点で最新の状態です。モデルの詳細については、モデルの概要を参照してください。
torage-4-Large
最高の汎用および多言語検索品質。すべての 4 シリーズ モデルは同じ埋め込みスペースを共有します。
任意のコンテキスト-3
汎用および多言語検索品質を最適化するために最適化されたコンテキスト化されたチャンク埋め込み。
ストレージマルチモーダル-3.5
PDF、スライド、表、数値、ビデオなどのインターリーブされたテキストと視覚的データをベクトル化できる豊富なマルチモーダル埋め込みモデル。
rerank-2.5
指示に従い、多言語をサポートすることで品質に最適化された一般的なリランカー。
ユースケース
Voyage AIモデルは次のユースケースをサポートしています。
セマンティック検索を使用して、コンテキストに関連する情報を検索します。
RAG を実装してデータ内の LRM をグラウンドし、プロ認証を軽減します。
より優れた選択
MongoDB ベクトル検索とAI統合で Voyage AIを活用して、 AIアプリケーション開発 を効率化します。
Voyage AI モデルと MongoDB Vector Search を組み合わせて、AIアプリケーションをビルドできます。
LgChuin、LlamaIndex、およびその他の一般的なAIフレームワークと統合します。
重要な概念
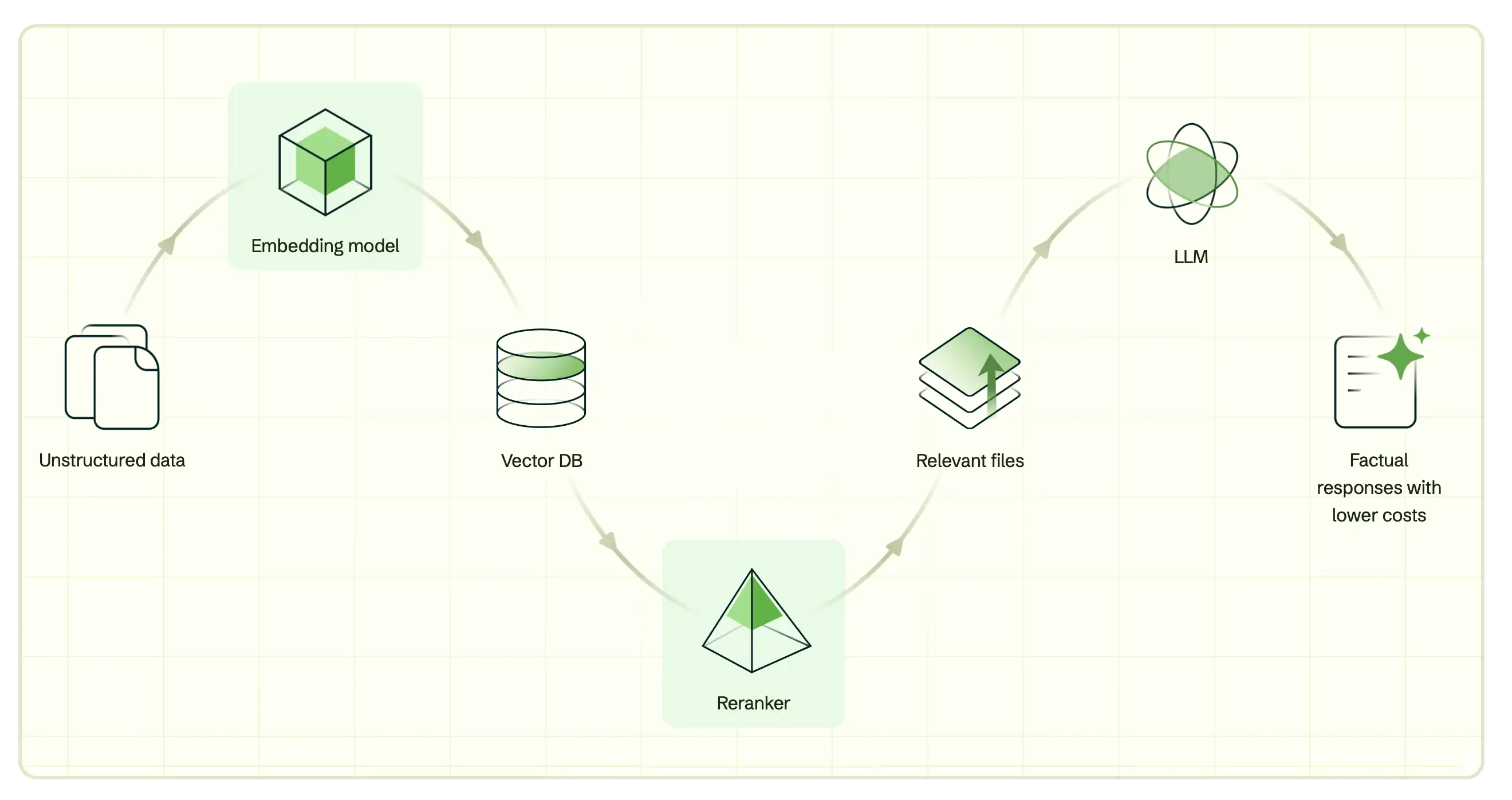
- 埋め込みモデル
- 埋め込みモデルは、データのセマンティックまたは基礎となる意味を取得するベクトル埋め込みにデータを変換するアルゴリズムです。これらのベクトルはベクトル検索を可能にし、信頼できるAIアプリケーションを構築するための主要なアプローチである検索拡張生成 (RAG)に必須のビルド ブロックとして機能します。
- reranker
- Reranker は、検索クエリーと検索結果の間の関連性をスコアリングするアルゴリズムです。Rerankers は、関連性スコアに基づいてドキュメントの順序付けを変更することで初期結果を調整し、より正確な結果のサブセットを生成するのに役立ちます。
- ベクトル埋め込み
- ベクトル埋め込みは数値の配列であり、各次元はデータの異なる機能または属性を表します。ベクトルは、テキスト、画像、ビデオから非構造化データまで、任意のタイプのデータを表すために使用できます。埋め込みモデルにデータを渡すことでベクトル埋め込みを作成し、これらの埋め込みをMongoDBのようなベクトル埋め込みをサポートするデータベースに保存できます。
- vectorSearch
- ベクトル検索は、セマンティック検索と RAG を強化する検索メソッドです。ベクトル間の距離を測定することで、異なるデータ点間のセマンティック類似性を判断できます。これにより、ベクトル化されたクエリをベクトル埋め込みと比較して、関連性の高い検索結果を得ることができます。任意のベクトル検索ソリューションとベクトルデータベースでVoyage AIモデルを使用できますが、これらはMongoDB Vector SearchおよびMongoDB Atlasとシームレスに統合されます。
- RAG
- 検索拡張生成(RAG)は、大規模言語モデル(llm)を追加のデータで強化して、より正確な応答を生成できるようにするために使用されるアーキテクチャです。詳細については、Voyage AI を使用した RAG を参照してください。
- tokens
- 埋め込みモデルと LVM のコンテキストでは、トークンとは、埋め込みの作成やテキストの生成のためにモデルが処理する単語、サブワード、文字などのテキストの基本単位です。トークンは、埋め込みモデルと LM の使用量に対して課金される方法を示します。
- レート制限
- レート制限は、ユーザーが特定の時間枠内で実行できるリクエスト数に対してAPIプロバイダーによって課せられる制限であり、1 分あたりのトークン(TPM)または 1 分あたりのリクエスト数(RPM)で測定されます。これらの制限により、均等な使用が確保され、不正を防ぎ、すべてのユーザーに対してサービスの安定性とパフォーマンスが維持されます。