このガイドでは、Voyage AIを使用して最初のベクトル埋め込みを生成し、 基本的なアプリケーションを構築する 方法を学習します。
このチュートリアルの実行可能なバージョンをPythonノートとして操作します。
モデルAPIキーの作成
Voyage AIモデルにアクセスするには、 MongoDB Atlas UIでモデルAPIキーを作成します。
無料の Atlas アカウントにサインアップするか、ログます。
Atlas を初めて使用する場合、組織とプロジェクトが作成されます。
詳細については、Atlas アカウントの作成 を参照してください。
プロジェクトのモデルAPIキー を作成します。
Atlasプロジェクトで、ナビゲーション バーから AI Models を選択します。
[Create model API key] をクリックします。
APIキーに名前を指定し、[Create] をクリックします。
詳しくは、モデルAPIキーを参照してください。
最初の埋め込みを生成する
このセクションでは、Voyage AI埋め込みモデルとPythonクライアントを使用してベクトル埋め込みを生成します。

スクリプトを作成します。
プロジェクトに quickstart.py という名前のファイルを作成し、次のコードをそのファイルに貼り付けます。このコードは、Voyage AIクライアントを初期化し、サンプルテキストを定義し、クライアントを使用してVoyage APIにアクセスし、voyage-4-large モデルのベクトル埋め込みを生成します。
詳細については、Pythonクライアントを参照するか、完全なAPI仕様を調べてください。
import voyageai # Initialize Voyage client vo = voyageai.Client() # Sample texts texts = [ "hello, world", "welcome to voyage ai!" ] # Generate embeddings result = vo.embed( texts, model="voyage-4-large" ) print(f"Generated {len(result.embeddings)} embeddings") print(f"Each embedding has {len(result.embeddings[0])} dimensions") print(f"First embedding (truncated): {result.embeddings[0][:5]}...")
基本的な RAG アプリケーションをビルド
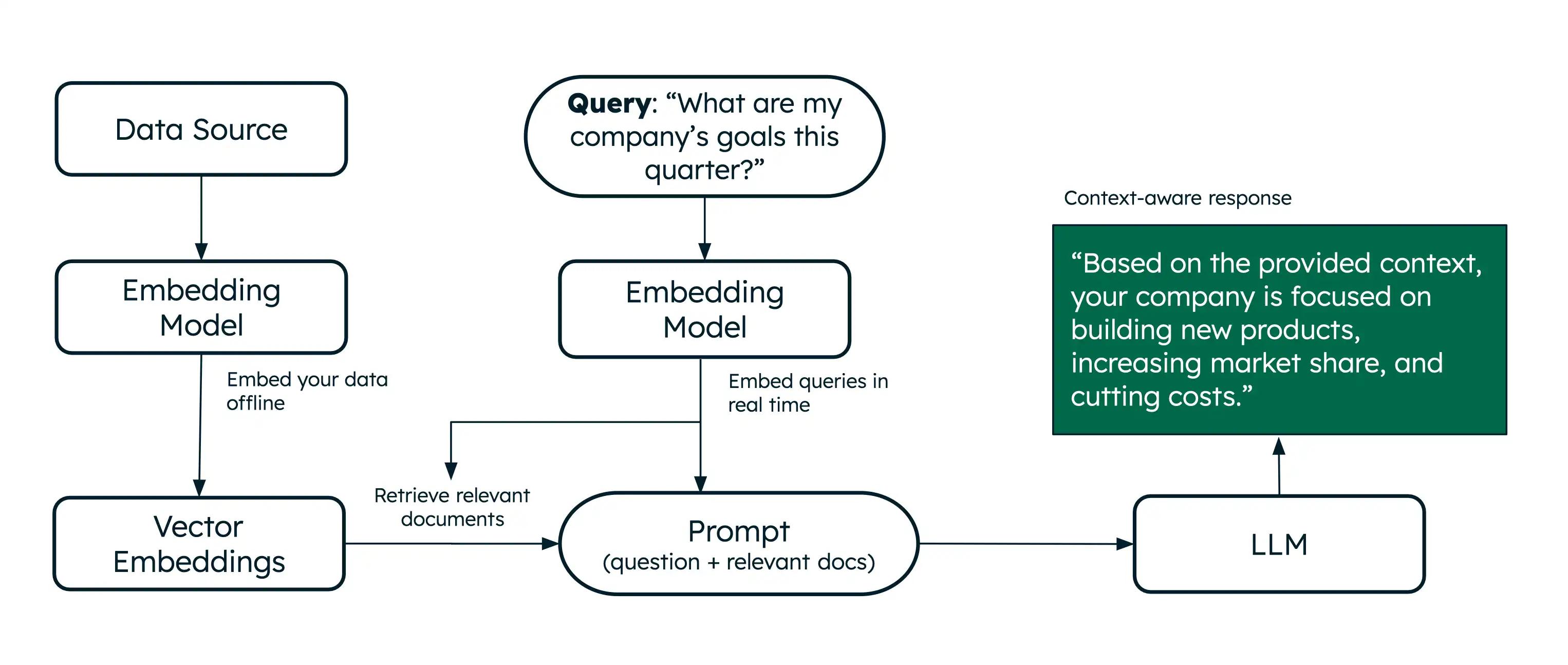
ベクトル埋め込みを生成する方法がわかったので、基本的なRAGアプリケーションを構築して、Voyage AIモデルを使用してAI検索と取得を実装する方法を学びます。RAG を使用すると、応答を生成する前にデータから関連情報を取得することで、LDM がコンテキストに対応した応答を生成できるようになります。
注意
RAG アプリケーションは LLM へのアクセスが必要です。このチュートリアルでは、Anthropic または OpenAI を使用する例を提供しますが、お好みの任意の LLM プロバイダーを使用できます。

学習の概要
Voyage AIを使用して最初のアプリケーションを作成したので、次のセクションを展開して、このクイック スタートで説明されている概念の詳細を学習してください。
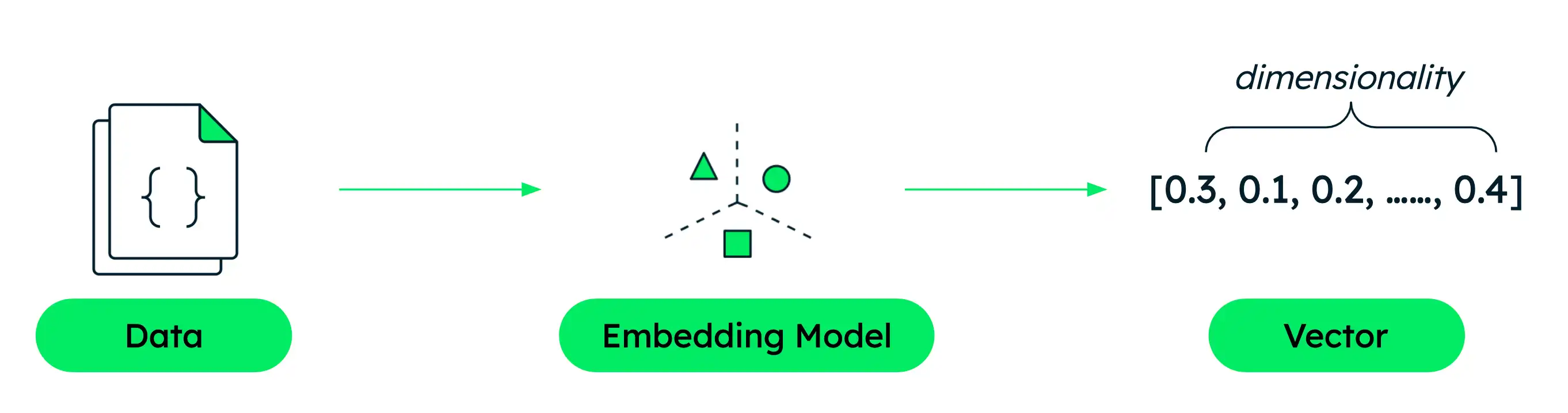
voyage-4-large 埋め込みモデルを使用してテキストを 1024 次元ベクトルに変換しました。各次元は、テキストの意味の要素をキャプチャする学習された機能を表します。
また、 rerank-2.5 再ランク付けモデルを使用して、クエリに対する検索結果を絞り込みました。スコアが高いほど、クエリとドキュメントの内容間の類似性が強いことを示します。
詳細については、モデルの概要 を参照してください。
voyageai Python SDK を使用して埋め込みと再ランクAPIにアクセスしました。SDK を使用してモデルを呼び出すときに、検索精度を向上させるために input_type パラメーターを指定しました。
document: データを表す埋め込みを最適化します。query: クエリ埋め込みを最適化します。
詳細については、テキスト埋め込みの使用 と 入力タイプの指定 を参照してください。
ドット積類似度 関数を使用して、セマンティックに似たドキュメントを検索しました。Numpy はベクトル操作用の組み込み関数を提供するオープンソースのライブラリであり、このアプリケーションはdot() と argsort() 関数を使用してクエリとドキュメント埋め込み間のドット積の類似性を計算し、ドキュメントを類似性スコアでソートします。
セマンティック検索について詳しくは、 Voyage AI埋め込みを使用したセマンティック検索 を参照してください。テキスト埋め込みの使用状況と input_type パラメータの詳細については、使用状況を参照してください。
セマンティック検索と再ランク付けを LLM と組み合わせて、基本的な RAG システムを作成しました。システムはセマンティック検索を使用して関連するドキュメントを検索し、それらを再ランク付けしてから、最も関連性の高いドキュメントをLLM に提供して、クエリに対する正確でベースのある応答を生成します。
RAG の詳細については、Voyage AIを使用した検索拡張生成(RAG)を参照してください。
次のステップ
学習を続けるには、次のリソースを参照してください。