KubernetesクラスターにMongoDB Search とベクトル検索を配置すると、アプリケーション内で強力な検索エクスペリエンスを直接構築できます。MongoDB Search とベクトル検索を使用すると、オンプレミスのMongoDBデータベースと自動的に同期する従来のテキスト検索とAIを使用したベクトル検索機能の両方を構築できます。これにより、高度な検索機能を提供しながら個別のシステムを同期して維持する必要がなくなります。詳しくは、以下を参照してください。
オンプレミス配置で全文検索やセマンティック検索などの検索機能を有効にするには、 MongoDB Search およびベクトル検索プロセス(mongot)を配置し、それをMongoDBデータベース配置(mongod)に接続する必要があります。mongot の配置は任意であり、提供される検索機能を使用する予定の場合にのみ必要です。
MongoDB Database プロセス(mongod)は、mongot のすべての検索クエリのプロキシとして機能します。mongod はクエリを mongot に転送し、クエリを処理します。mongot はクエリ結果を mongod に返し、ノードはその結果を に転送します。mongot と直接やり取りすることはありません。
各 mongot プロセスには、データベースや他の検索ノードと共有されていない独自の永続ボリュームがあります。ストレージ は、データベースから継続的に提供されるデータから構築されたインデックスを維持するために使用されます。インデックス定義(メタデータ)はデータベース自体に保存されます。
mongot は、次のアクションを実行します。
インデックスを管理します。
mongotは、データベース内のインデックス定義を更新します。データベースからデータを取得します。
mongotノードは、データベースへの永続的な接続を確立し、データベースからインデックスをリアルタイムで更新します。検索クエリを処理します。
When
mongodが$search、$searchMeta、または$vectorSearchクエリを受信すると、そのクエリはmongotノードのいずれかに送信されます。クエリを受け取ったmongotはクエリを処理し、データを集計し、その結果をmongodに返し、ユーザーに転送します。
mongot コンポーネントは 1 つのMongoDBレプリカセットと厳密に結合されているため、複数のデータベースやレプリカセットで共有することはできません。レプリカセット配置の場合、専用検索ノードの 1 つのグループがレプリカセットを提供します。シャーディングされたクラスターの場合、各シャードは mongot ノードの独自のグループを維持します。シャードは mongot インスタンスを共有しません。
mongot と mongod の間のネットワーク接続は両方向で行われます。
mongotは、インデックスの構築とクエリの実行に使用されるデータを取得するためにレプリカセットへの接続を確立します。mongodはmongotに接続して、インデックス管理やデータのクエリなどの検索関連の操作を転送します。
spec.replicasフィールドは、 Kubernetes 演算子が配置する mongot インスタンスの数を制御します。レプリカセットソースの場合、spec.replicas は mongot ポッドの合計数を設定します。シャーディングされたクラスターソースの場合、spec.replicas はシャードあたりの mongot ポッドの数を設定します。
spec.replicas を 1 より大きい値に設定する場合は、mongod と mongot ポッドの間に L7 ロードバランサーを配置する必要があります。mongod プロセスは mongot への単一の永続的な TCP 接続を開くため、L4 ロードバランサーは複数の mongot インスタンスにクエリを分散できません。すべてのトラフィックはその 1 つの接続を介してフローします。L7 ロードバランサーはHTTP/2 と gRPC を理解しているため、クエリカーソルの実行中は各ストリームを単一の mongot に固定しながら、個々の gRPC ストリームを mongot ポッドに分散することができます。
MongoDB Search とベクトル検索の配置
Kubernetes演算子 の有無にかかわらず、検索配置アーキテクチャに大きな違いはありません。Kubernetes Operator は、特にデータベースもKubernetes Operator によって管理されている場合に、完全に機能する検索ノードを配置するために必要な手順を簡素化します。
配置するには、MongoDBSearch カスタム リソース(CR)を適用します。これをKubernetes Operator が取得して mongot ポッドを取得して配置を開始し、spec で指定された永続ストレージをリクエストします。Kubernetes Operator を通じて配置されたMongoDB Search とベクトル検索 は、同じKubernetes Operator によって配置されたMongoDBレプリカセットまたはシャーディングされたクラスター、または完全に独立したKubernetesの外部MongoDBデプロイ(レプリカセットまたはシャーディングされたクラスター)を対象にすることができます。使用するように mongot を配置して構成する方法については、以下をご覧ください。
KubernetesのMongoDBレプリカセットについては、MongoDB Community Edition でのインストールと使用またはMongoDB Enterprise Edition での検索のインストールと使用を参照してください。
外部MongoDBレプリカセットは、外部MongoDB Enterprise を使用して検索をインストールする を参照してください。
前提条件
でMongoDB Search とベクトル検索 を使用するには、次の手順に従います。
MongoDB Community を配置するには、 Kubernetes演算子 を使用して、完全に機能するMongoDB 8.2 以降のレプリカセットまたはシャーディングされたクラスターがKubernetesクラスター内に配置されている必要があります。
MongoDB Enterprise配置では、次のいずれかの方法で、完全に機能するMongoDB 8.2 以降のレプリカセットまたはシャーディングされたクラスターが配置されている必要があります。
Kubernetes演算子を使用するKubernetesクラスター内
Kubernetesクラスターの外部
Cloud ManagerまたはMongoDB Ops Manager のインスタンス
始める前に、以下の点を考慮してください。
Kubernetesクラスターで永続ボリュームを作成するには、動作する
StorageClassが必要です。これを行わない場合、PersistentVolumeClaimsは保留中のままになり、 MongoDB には 耐久性があるストレージ が存在しない可能性があります。正しく構成されたクラスターネットワークが必要です。ClusterIP、NodePort、または LoadBalancer などのサービスはトラフィックをルーティングできる必要があります。外部クライアントがアクセスする必要がある場合は、 Ingress またはロードバランサーを設定します。
データベースと検索ノードには、MongoDBデータベースとMongoDB Search およびベクトル検索のワークロードがリソースを集中的に消費するため、十分なCPU、メモリ、ディスク領域が割り当てられている必要があります。エビクションやスロットリングを避けるために、Ped 仕様で リクエストと制限 を使用することをお勧めします。
Kubernetesのバージョンは、使用するMongoDB演算子またはHelmチャートでサポートされている必要があります。一部の CRD または API はバージョン間で異なります。詳細については、Kubernetes演算子互換性のためのMongoDBパラメーター を参照してください。
必要な RBAC ロールとロール バインディングは、 Kubernetes Operator と ポッド内で実行中プロセスがリソースを管理できるようにする必要があります。
複数の
mongotインスタンス(1より大きいspec.replicas)が必要な場合は、 ロードバランサー が必要です。Kubernetes 演算子は、Envy プロキシを自動的に配置するおよび管理することもできます(spec.loadBalancer.managed: {})、または独自の L7 ロードバランサーを提供することもできます(spec.loadBalancer.unmanaged)。複数の
mongotインスタンスを含むシャーディングされたクラスターが必要な場合は、すべてのシャードにわたるポッドの合計数に十分なクラスター リソースがあることを確認してください。各シャードは、mongotポッドの独自のグループを取得します。ロードバランサーは正しいmongotグループにトラフィックをディスパッチします。受信トラフィックの TLS SNI フィールドを読み取りて、元のシャードを識別し、そのシャードに属するmongotポッドにトラフィックをルーティングします。そのため、各シャードに異なる検索ホスト名を使用して構成する必要があります。
設定タスク
次の表は、 Kubernetes 演算子が自動的に実行する構成タスクと、 KubernetesにMongoDB Search とベクトル検索を正常に配置するし、 KubernetesのMongoDBレプリカセットまたはシャーディングされたクラスターまたは 外部MongoDB配置に接続するために実行する必要があるアクションを示しています。
タスク | (Kubernetes 内) 実行者 | (外部 MongoDB) 実行者 |
|---|---|---|
Kubernetes内でのMongoDB Ops Managerの配置 | Kubernetes 演算子 | Kubernetes 演算子 |
Kubernetes の外部でのCloud ManagerまたはMongoDB Ops Managerの配置 | あなたの | あなたの |
MongoDBレプリカセットまたはシャーディングされたクラスターの配置 | Kubernetes 演算子 | あなたの |
MongoDBSearch カスタムリソースを作成する | あなたの | あなたの |
MongoDB配置への接続文字列の提供 | Kubernetes 演算子 | あなたの |
| Kubernetes 演算子 | Kubernetes 演算子 |
各 | Kubernetes 演算子 | あなたの |
| Kubernetes Operator と MongoDBUserリソースを適用することで | あなたの |
クエリ検索に必要な権限を持つユーザーでMongoDBレプリカセットを構成する | あなたの | あなたの |
MongoDB Search およびベクトル検索インデックスの作成 | あなたの | あなたの |
各 | 不要 | あなたの |
| 不要 | あなたの |
マネージド ロードバランサーの構成( | Kubernetes 演算子 | Kubernetes 演算子 |
非マネージド ロードバランサーの構成( | あなたの | あなたの |
シャードごとの TLS 証明書のプロビジョニング(TLS を使用したシャーディングされたクラスター) | あなたの | あなたの |
ロードバランサーを外部で公開する(外部MongoDB + マネージド DB) | 不要 | あなたの |
次の図は、 KubernetesクラスターにMongoDB Enterpriseレプリカセット単一のMongoDB Search およびベクトル検索インスタンスの配置アーキテクチャを示しています。

次の図は、 MongoDB Enterprise Editionレプリカセットを持つMongoDB Search およびベクトル検索用のKubernetes Operator がKubernetesクラスターに配置するコンポーネントを示しています。
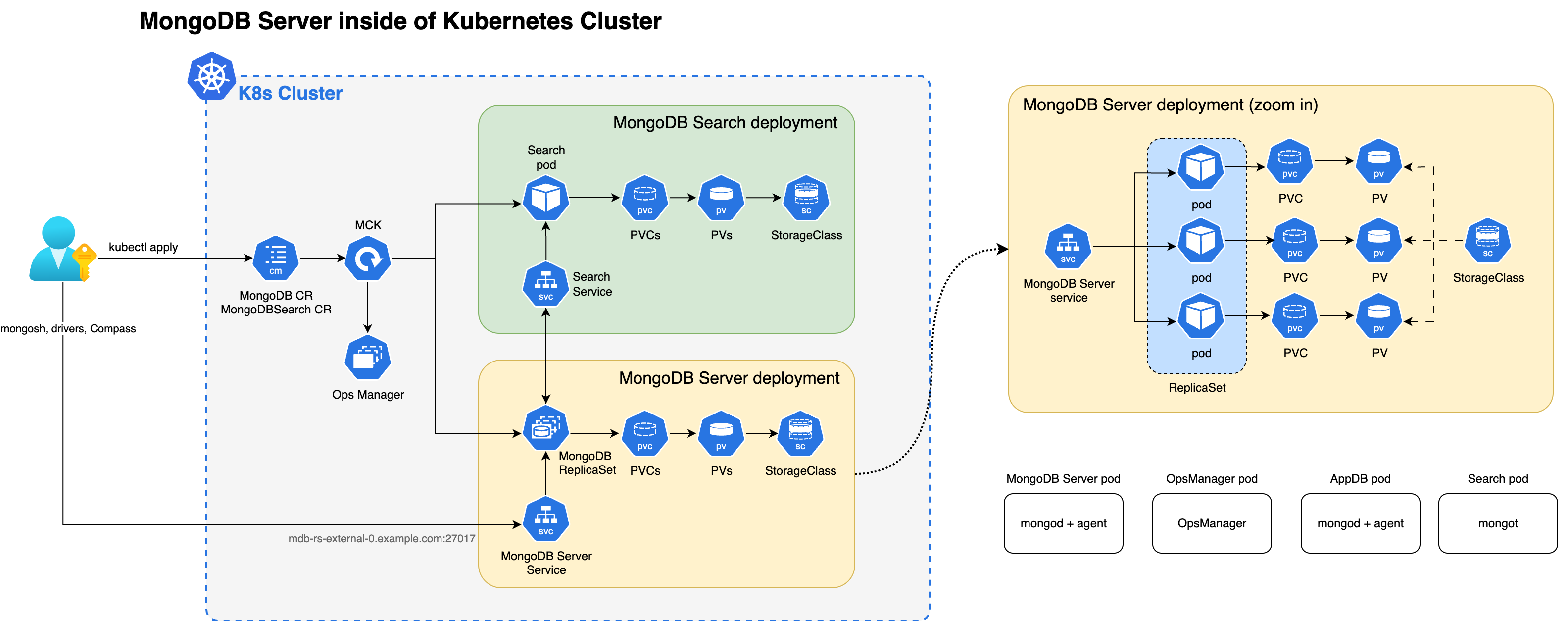
mongot プロセスと mongod プロセスの両方がKubernetesクラスター内に配置されている場合、 Kubernetes Operator は両方のプロセスの構成を自動的に実行します。具体的には、 Kubernetes演算子は次の操作を実行します。
MongoDBSearch が参照する MongoDB CR を検索するには、
spec.source.mongodbResourceRefを使用するか、命名規則によって MongoDBSearch と同じ名前の MongoDB CR を検索します。シャーディングされたクラスターの場合、 Kubernetes Operator は参照先のMongoDBリソースからシャードトポロジー(シャード名、レプリカセットノード、mongos ルーター)を自動検出します。YAMLファイルに
mongot構成を生成し、それを<MongoDBSearch.metadata.name>-search-configという名前の構成マップに保存します。コンフィギュレーション マップは検索ポッドによってマウントされ、YAML 構成はスタートアップ時に
mongotのプロセスによって使用されます。生成された YAML には、レプリカセットへの接続方法、TLS 設定などに関するすべての情報が含まれています。CR の
spec.persistenceとspec.resourceRequirements設定に従って構成されたストレージとリソースの要件を持つ、<MongoDBSearch.metadata.name>-searchという名前のMongoDB Search とベクトル検索ステートメントセットを配置します。シャーディングされたクラスターソースの場合、 Kubernetes Operator はシャードごとに 1 つのステートフルセットを作成します。各StatulSet は命名パターン<name>-search-0-<shardName>を使用し、spec.replicasポッドを含みます。デフォルトは1です。命名パターンの0は、将来のマルチクラスター互換性のためにクラスターインデックスを予約します。ロードバランサーが必要な場合(
spec.loadBalancer.managed)、 MongoDBクラスター用に単一の Envy プロキシ配置 を配置します。Envy プロキシは、L7 ルーティング、mTLS 終了、およびmongodポッドとmongotポッド間での gRPC ストリームの固定を処理します。mongotホストのホスト名やポート番号など、必要なsetParameterオプションを追加して、すべてのmongodプロセスの構成を更新します。ロードバランサーを構成する場合、mongotHostとsearchIndexManagementHostAndPortはmongotポッドではなく、ロードバランサーエンドポイントを点。シャーディングされたクラスターの場合、各シャードのmongodプロセスは、そのシャードのロードバランサーエンドポイントを受け取ります。
次のアクションを実行する必要があります。
MongoDBUserカスタムリソースを使用してレプリカセットにユーザーを作成します。mongotは、このユーザーの認証情報を使用してレプリカセットに接続し、データをソースします。ユーザー名は任意ですが(例では
search-sync-source-userを使用しています)、searchCoordinatorロールが設定されている必要があります。このユーザーのユーザー名とパスワードは、それぞれ
MongoDBSearch.spec.source.usernameとMongoDBSearch.spec.source.passwordSecretRefで渡されます。パスワードシークレットは、
MongoDBUser仕様(MongoDBUser.spec.source.passwordSecretKeyRef)の作成に使用されたものと同じシークレットを参照できます。
MongoDBSearch カスタムリソースを構成して適用します。
mongot プロセスの CR 設定の詳細については、 MongoDB Search とベクトル検索設定 を参照してください。
次の図は、外部MongoDB Enterprise Editionレプリカセットを使用するKubernetesクラスターでのMongoDB Search とベクトル検索の配置アーキテクチャを示しています。

次の図は、 Kubernetes Operator がMongoDB Search およびベクトル検索用のKubernetesクラスターに配置するコンポーネントを示しています。

Kubernetes外 でMongoDBデプロイいる場合にMongoDB Search とベクトル検索を使用するには、 Kubernetes演算子を使用して mongot を配置し、いくつかのステップを手動で実行します。Kubernetes Operator は、検索ポッドの構成を処理します。ただし、 MongoDB配置がKubernetesの外部にある場合は、 MongoDBノードとネットワークを再構成する必要があります。
以下の手動設定はユーザーが管理します。
外部レプリカセットの構成
外部レプリカセット内のすべての
mongodプロセスでsetParameterを使用して、次のパラメータを構成します。構成する際、<search-service-hostname>:27028を MongoDBSearch サービスの実際の解決可能なホスト名とポートに置き換えます。setParameter: mongotHost: "<search-service-hostname>:27028" searchIndexManagementHostAndPort: "<search-service-hostname>:27028" skipAuthenticationToSearchIndexManagementServer: false searchTLSMode: "disabled" # or "requireTLS" for TLS deployments useGrpcForSearch: true 単一の
mongotインスタンス(ロードバランサーなし)の場合、mongotHostはmongotサービス ホスト名(<name>-search-svc:27028)を直接指します。ロードバランサーを持つ複数の
mongotインスタンスの場合、mongotHostは代わりにロードバランサーエンドポイントを点ようにします。マネージド ロード バランサーの場合、 Kubernetes Operator は
spec.source.mongodbResourceRefを使用してmongotHostを自動的に構成します。MongoDB の外部配置の場合、
spec.loadBalancer.managed.externalHostnameまたはspec.loadBalancer.unmanaged.endpointで指定したロードバランサーエンドポイントにmongotHostを設定する必要があります。
検索同期プロセス用の外部レプリカセットにユーザーを作成します。このユーザーには
searchCoordinatorロールが必要です。- userName: "search-sync-source" password: "<your-search-sync-password>" database: "admin" roles: - role: "searchCoordinator" db: "admin"
外部クラスターの構成
重要
標準のMongoDBシャーディングされたクラスターの配置では、クライアントは mongos ルーターにのみ接続し、シャードレプリカセットに直接接続することはありません。ただし、mongot を配置すると、各シャードグループ内の mongot プロセスが mongos ルーターとそのシャード内のすべての mongod プロセスに接続します。したがって、各シャードのレプリカセットをmongot プロセスに直接公開する必要があります。ネットワークとファイアウォールのルールで、 Kubernetesクラスターから各シャードの mongod インスタンスへの直接接続が許可されていることを確認します。mongos ルーターだけでなく、
spec.source.external.shardedCluster.shards で指定する shardName 値は、 Kubernetes の命名規則に従う必要があります。
小文字の英数字、
-、または.のみを含みます。英数字で始まり、英数字で終わる。
アンダースコアを含めないでください。MongoDBシャード名でアンダースコアが使用されている場合は、ダッシュに置き換えます。
MongoDBSearch.metadata.nameとshardNameの合計の長さは、50 文字未満である必要があります。
shardName はMongoDB内のシャード名と正確に一致する必要はありません。Kubernetes Operator は、 Kubernetesリソースの名前付けにのみ使用します。
MongoDBSearch を 外部のシャーディングされたクラスターに接続する場合は、次の操作を行う必要があります。
MongoDBSearch CR で
mongosルーターホストとシャードごとのレプリカセットホストを使用してspec.source.external.shardedClusterを構成します。各シャードの
mongodプロセスでmongotHostパラメータとsearchIndexManagementHostAndPortパラメータを設定します。各シャードを独自のmongotグループ(または複数のmongotインスタンスを使用する場合は独自のロードバランサーエンドポイント)に向けます。以下間で双方向ネットワーク接続を確保します。
各シャードの
mongodノードと対応するmongotポッド(またはロードバランサー)。mongotポッドとmongosルーター(クエリ ルーティング用)。mongotポッドと各シャードのmongodノード(データ同期用)。
マネージド ロードバランサー を外部のシャーディングされたクラスターで使用する場合は、{shardName} プレースホルダーとともに spec.loadBalancer.managed.externalHostname を指定します(例: 、{shardName}.search-lb.example.com)。Envy サービスを外部で公開すると、各シャードの mongod ノードがそのシャードに一意のホスト名を使用してこのサービスにアクセスできるようになります。ロードバランサーは着信接続からTLS SNIフィールドを読み取り、トラフィックの発信元がどのシャードであるかを判断し、そのシャードに属する mongot ポッドにディスパッチします。この SNI ベースのルーティングは、ロードバランサーがシャード間のトラフィックを区別するために使用する唯一のメカニズムであるため、各シャードは異なるホスト名を介して接続する必要があります。
Kubernetes の構成
外部MongoDBホストを指すように MongoDBSearch CR を構成して適用する
spec.source.external。検索同期ユーザーのパスワード用にKubernetesシークレットを作成します。
apiVersion: v1 kind: Secret metadata: name: search-sync-source-password stringData: password: "your-search-sync-password" ネットワークと DNS を設定して、外部MongoDBと検索ポッド間の双方向接続を確保します。外部MongoDB環境は検索サービスのホスト名(
<search-service-hostname>)を解決できる必要があります。
外部の mongod プロセスに接続するための mongot プロセスの CR 設定の詳細については、MongoDB Search とベクトル検索の設定を参照してください。
セキュリティ
次の画像は、mongot プロセスのセキュリティ構成を示しています。MongoDBサーバーがKubernetesクラスター内にある場合、 Kubernetes Operator はMongoDB Search とベクトル検索の キーファイル認証 を自動的に設定します。MongoDBサーバーが外部の場合は、レプリカセットのキーファイル認証情報を含むkubernetes secretを作成し、MongoDBSearch CRで参照する必要があります。
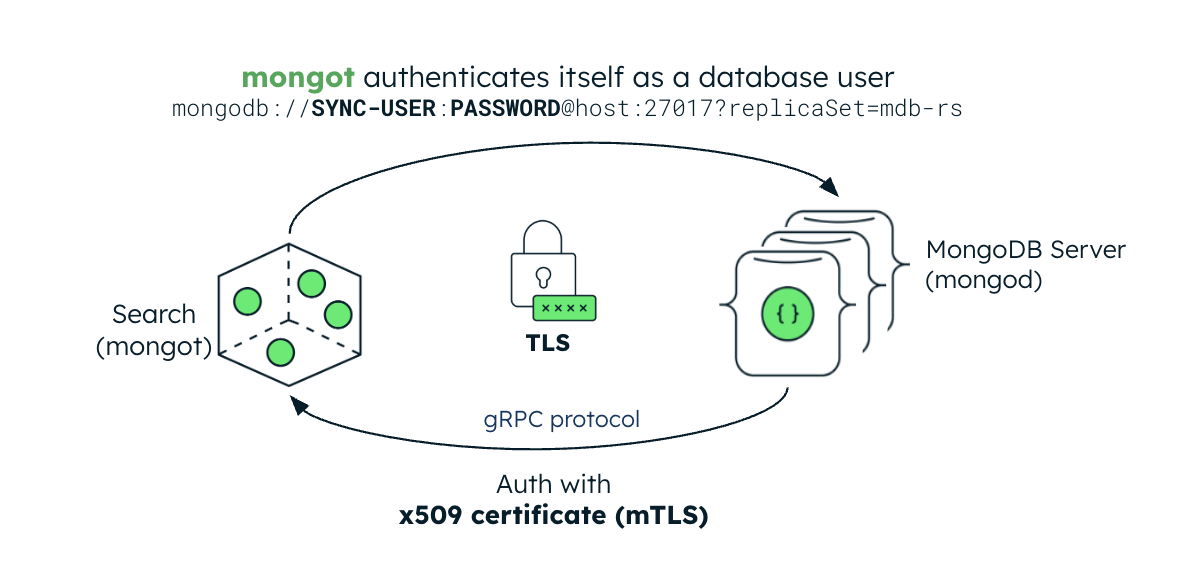
認証
mongot プロセスは、mTLS を使用して mongod 接続を認証します。TLS を有効にすると、mongot プロセスは認証のクライアント証明書としてMongoDBサーバーの TLS 証明書を使用します。この証明書は、mongot が構成されている CA 証明書に対して検証されます。認証を正しく機能させるには、TLS を有効にして、mongot と mongod の両方を構成する必要があります。
同じKubernetesクラスター内のMongoDBリソースをインデックスように構成された場合、MongoDB と MongoDBSearch リソースの両方が TLS 用に構成されている場合、 Kubernetes Operator は mongod CA 証明書を mongot に自動的に伝達し、検索クエリ接続で mTLS を有効にします。MongoDBレプリカセットがKubernetesの外部に配置されている場合は、レプリカセットのCA証明書を含むKubernetes secretを作成し、MongoDBSearch.spec.source.external.tls.caフィールドで参照、検索クエリリクエストでmTLS認証を有効にする必要があります。
トランスポート層のセキュリティ
MongoDBSearch は、TLS を使用して転送中のデータと認証情報を保護できます。インデックス マネジメント コマンドと検索クエリの場合は、spec.security.tlsフィールドを設定し、TLS 証明書を提供します。このフィールドを空のオブジェクト({})に設定すると、デフォルト設定でTLSを有効にできます。
バージョン 1.8.0 から非推奨となっています。: spec.security.tls.certificateKeySecretRef は非推奨となっています。レプリカセット配置の場合、Kubernetes Operator は今でも certificateKeySecretRef をサポートしていますが、spec.security.tls.certsSecretPrefix に移行する必要があります。シャーディングされたクラスター配置の場合、Kubernetes Operator はシャードごとに別々の mongot サーバー証明書シークレットを読み取るため、certificateKeySecretRef を使用できません。
spec.security.tls.certsSecretPrefix は、任意フィールドです。これを指定すると、 Kubernetes Operator は読み込むすべての証明書シークレット名に <certsSecretPrefix>- を先頭に追加します。Kubernetes Operator は、次の証明書シークレットを読み取ります。
mongot 証明書
クラスター トポロジー | mongot 証明書 |
|---|---|
レプリカセット |
|
シャーディングされたクラスター |
|
ロード バランサー証明書
spec.loadBalancer.managed を設定すると、ロードバランサーのクライアント証明書は [<certsSecretPrefix>-]<name>-search-lb-0-client-cert になります。次の表は、ロードバランサーのサーバー証明書を示しています。
クラスター トポロジー | 証明書 |
|---|---|
レプリカセット |
|
シャーディングされたクラスター |
|
TLS 証明書は、 MongoDBレプリカセットが使用する CA 証明書を発行したのと同じ CA によって発行され、署名されている必要があります。
MongoDBSearch と MongoDB の両方がKubernetes Operator によって配置されると、基礎の mongot と mongod の構成は大部分がKubernetes Operator 自体によって処理されます。MongoDBレプリカセットをKubernetesクラスターの外部に配置する場合、次のようにします。
.spec.source.external.tlsフィールドには、mongodの構成に使用したのと同じ CA 証明書を含むKubernetes Secret を入力する必要があります。searchTLSModeパラメータは、mongod構成でrequireTLSに設定する必要があります。
ロード バランサー mTLS
ロードバランサーがない場合、mongod は mTLS を使用して mongot に直接接続します。mongod は独自のクライアント証明書を提示し、mongot は信頼できる CA に対してそれを検証します。
マネージド ロードバランサー(spec.loadBalancer.managed)を構成すると、Envy プロキシは mongod からの mTLS 接続を終了し、mongot への新しい mTLS 接続を確立します。ロードバランサーは接続を終了して再確立するため、mongot に接続するときに、元の mongod 証明書ではなく、独自のクライアント証明書が使用されます。mongot CA は、ロード バランサーのクライアント証明書を発行した認証局を信頼する必要があります。Kubernetes 演算子 は、Envy TLS 構成を自動的に管理します。次の証明書が必要です。
mongodが接続する Envy プロキシのサーバー証明書。ロードバランサーはこの証明書を使用して受信 mTLS 接続を終了します。Envy プロキシのクライアント証明書。アップストリーム mTLS 接続を確立するときにロードバランサーが
mongotに提示するもの。
spec.security.tls.certsSecretPrefix が定義する命名規則に従って、これらの証明書をKubernetes Secret としてプロビジョニングします。完全な命名パターンについては、 MongoDB Search とベクトル検索の設定 を参照してください。