このページでは、 MongoDB ベクトル検索 パフォーマンス ベンチマークの結果を検索します。
結果の概要
2048 次元で
voyage-3-large埋め込みを使用する 15.3M ベクトルでは、量子化が構成されたMongoDB ベクトル検索 は90-95% の精度を維持し、 クエリレイテンシは 50ms 未満です。完全忠実度ベクトルでの再スコアリングに伴う追加コストにより、候補者数が数百に達すると、バイナリ量子化はパフォーマンスが低下します。ただし、インデックスの提供コストが~1/4の場合、多くの大規模なワークロードにとって好ましいオプションとなる場合があります。
量子化を使用して大規模なワークロードを実行する場合は、1024を超える次元が推奨されます。
選択的フィルターにより、
numCandidatesに選択された値によってパフォーマンスが改善または低下する可能性があります。バイナリ量子化の再スコアリングにかかる追加コストは、並行処理が多いワークロードを実行する際にスループットの低下として現れます。
シャーディングによりスループットが若干向上しますが、スループットを向上させるためには、検索ノード数または検索ノードで使用可能なコアの数をスケールアウトすることをお勧めします。
多次元ベンチマークにおけるリコールとレイテンシの分析
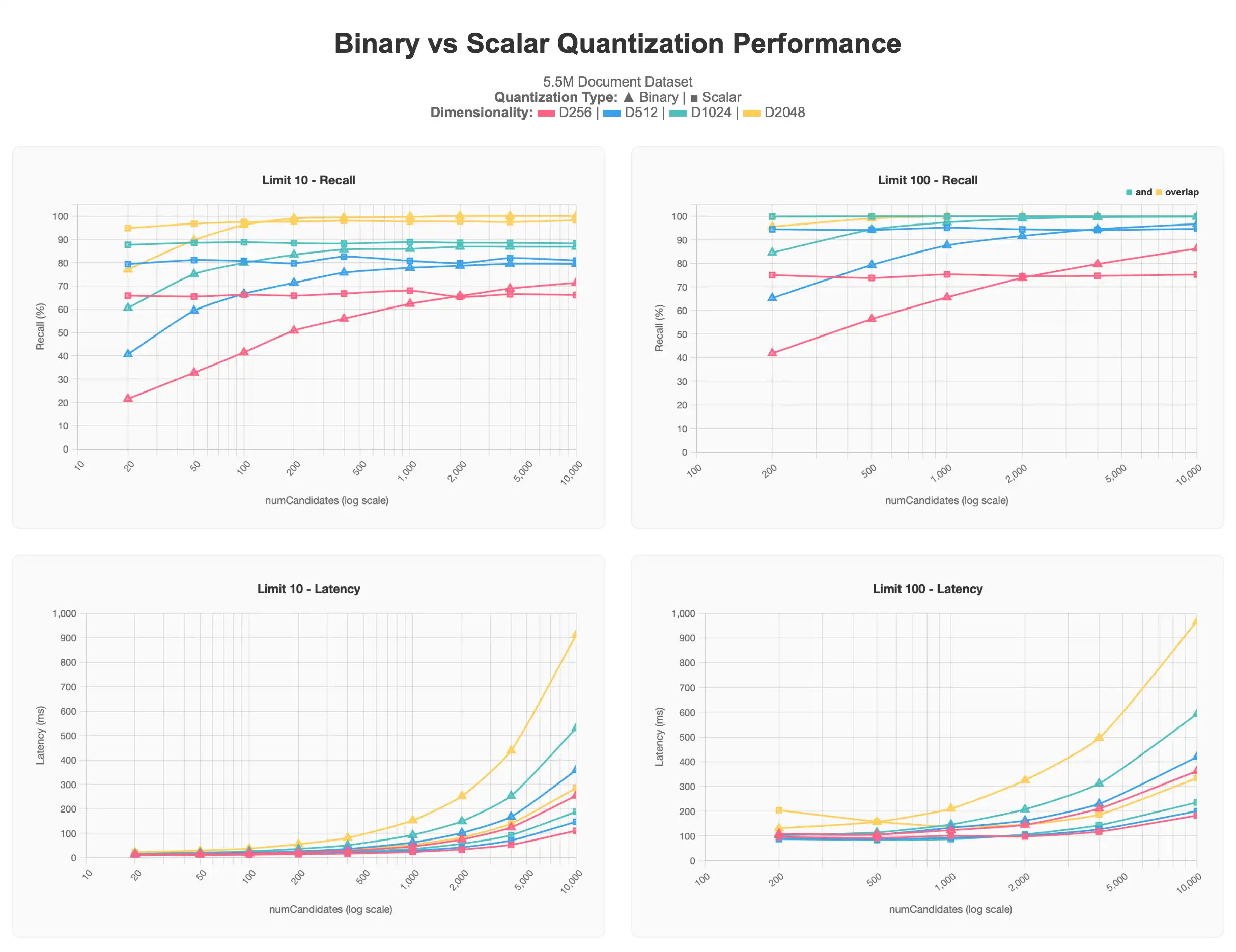
最初の結果セットは、ベクトルの複数次元(256、512、1024、2048)を含む5.5Mドキュメントデータセットに対して実行されたテストを示します。すべては、各ドキュメント内でvoyage-3-largeを使用して生成されました。

完全なチャートを表示するには、Claudeアーティファクトをご覧ください。
スカラー量子化された結果は、すべてバイナリ量子化された結果よりも高いレベルで始まりますが、numCandidates が増加しても非単調レベルに維持されます。逆に、バイナリ定量化クエリでは、numCandidates が要求されるにつれて、より正確な結果が得られ、スカラー量子化の非公式に近似し、場合によってはそれを渡すと、レイテンシが高く、特に 1000 の numCandidates を超えるようにコストます。
一般的に、limitの値が低いほど100%の精度に近づくのが難しくなります。これは、上位の結果を特定するのが難しいためであり、より良い結果を得るためには、しばしばnumCandidatesを高くする必要があります。これは、バイナリ量子化プロットで特に観察されています。また、低次元のベクトル256dと512dは、どちらの形式の量子化でも特に大規模な場合に影響を受けることが観察されています。256dは、限界10テストで70%のリコールを超えることはなく、512dは80%のリコールを超えることはありません。限界100では、90~95%のターゲットゾーンに到達するために、より高い値numCandidatesが必要になります。
この情報を踏まえ、大規模なデータセットを扱う際は、量子化を使用せず低次元で行う代わりに、1024d以上の次元を使用してスケーリングに量子化を適用することをお勧めします。ユースケースにリクエストされたベクトル量も要因として働きます。
より大規模なベンチマーク結果
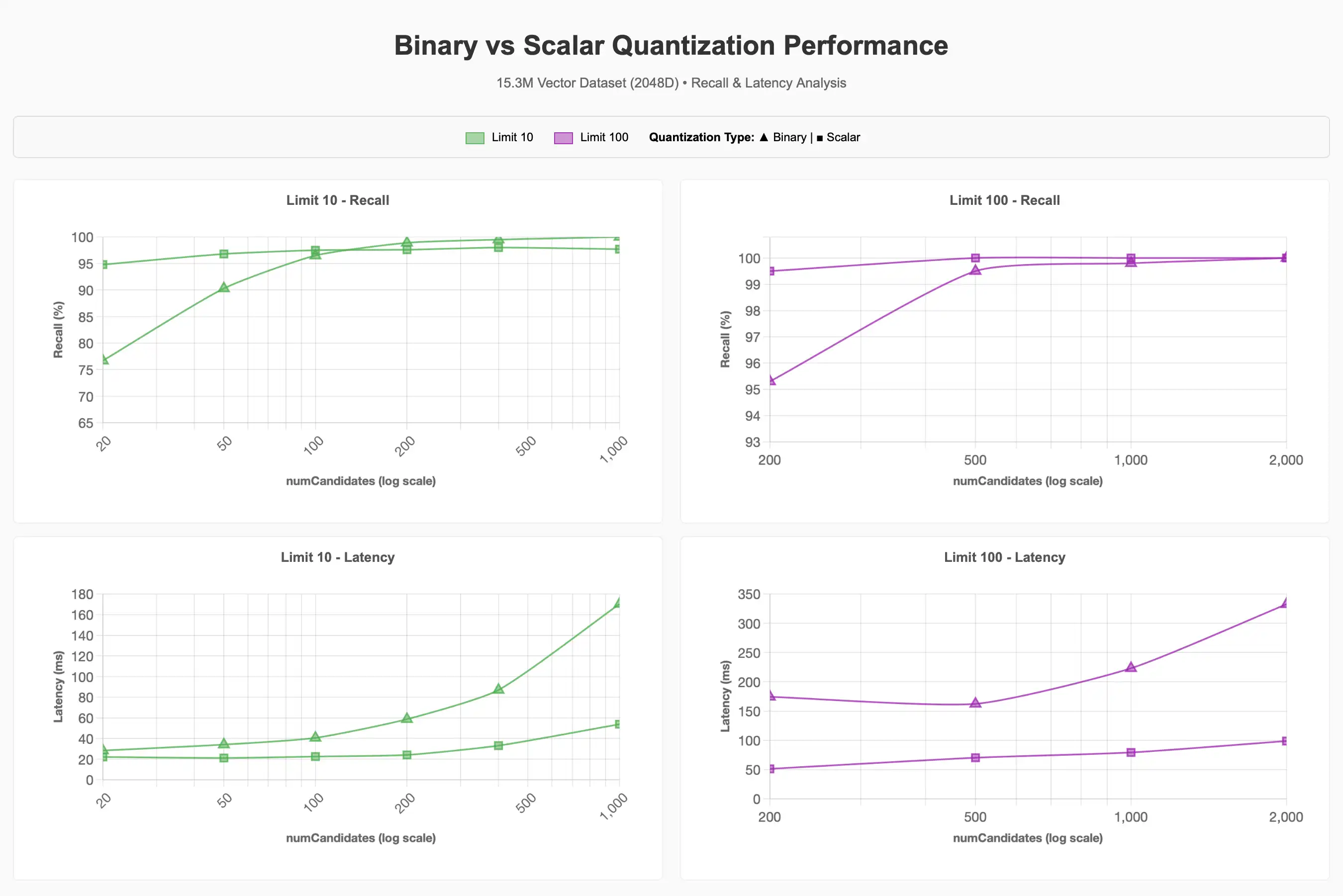
大規模な15.3Mベクトルデータセットでは、次元を2048dに固定し、量子化、フィルター、同時実行性がパフォーマンスに与える影響を調査しました。前回の一連のテスト結果から、次元が高いほどリコールがより有利に維持されることが示されたため、2048dに固定することにしましたが、1024dも90~95%のリコール目標を達成するために有益であることが考えられます。
リコールとレイテンシの分析
バイナリ量子化を使用して90-95%のリコール目標を達成する場合、ベースラインと比べてはるかに大量のnumCandidatesが必要になることを観察しました。一般的にnumCandidatesが高いほどレイテンシが高くなりますが、状況によっては異なる場合があります。

完全なチャートを表示するには、 Crude アーティファクトを参照してください。
フィルタリング
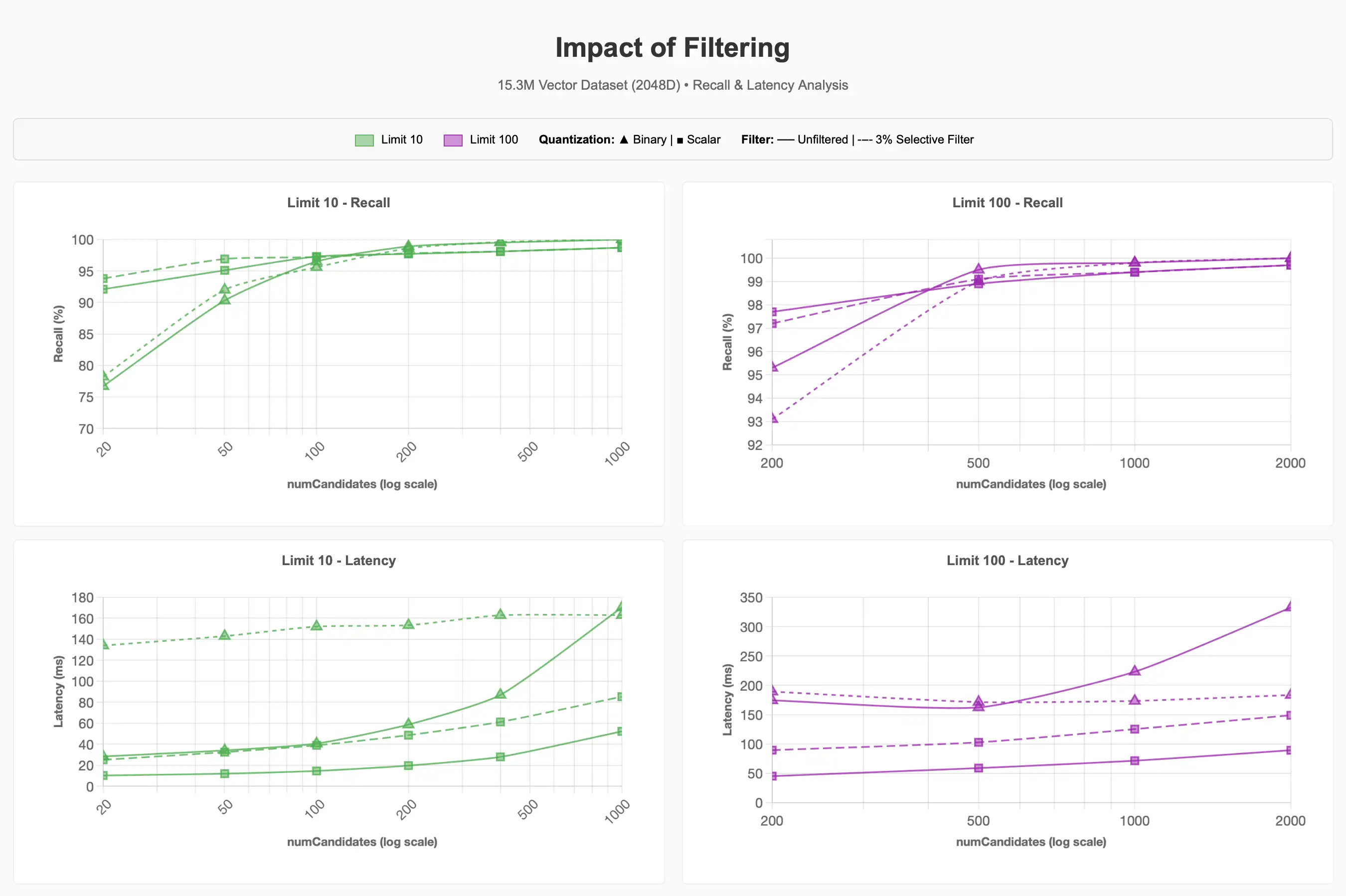
ペット用品カテゴリ(コーパスの~3%)の15.3Mアイテムのうち~500kアイテムのデータセットで選択的フィルターを使用した場合、リコールとレイテンシで何が起こるかを観察したところ、

完全なチャートを表示するには、 Crude アーティファクトを参照してください。
3%の選択フィルターがクエリのコストが大幅に高くなる可能性があることを確認しました。より低いlimit値でのバイナリ量子化に関しては、フィルタリングされていないクエリと比べて、90-95%のリコールの達成に約4倍のコストがかかりました。
Hierarchical Navigable Small Worlds の Agon-1 検索戦略をサポートする Lucene 10 の将来の改善によって、このプロセスが改善される可能性があります。ただし、リクエストされた候補の数がセグメント内のメタデータフィルターに一致するベクトルの数を超える場合に ENN を実行すると、選択された量子化スキームに関係なく、フィルターの選択性がクエリ パフォーマンスの大部分を占めることが示されます。
同時実行性
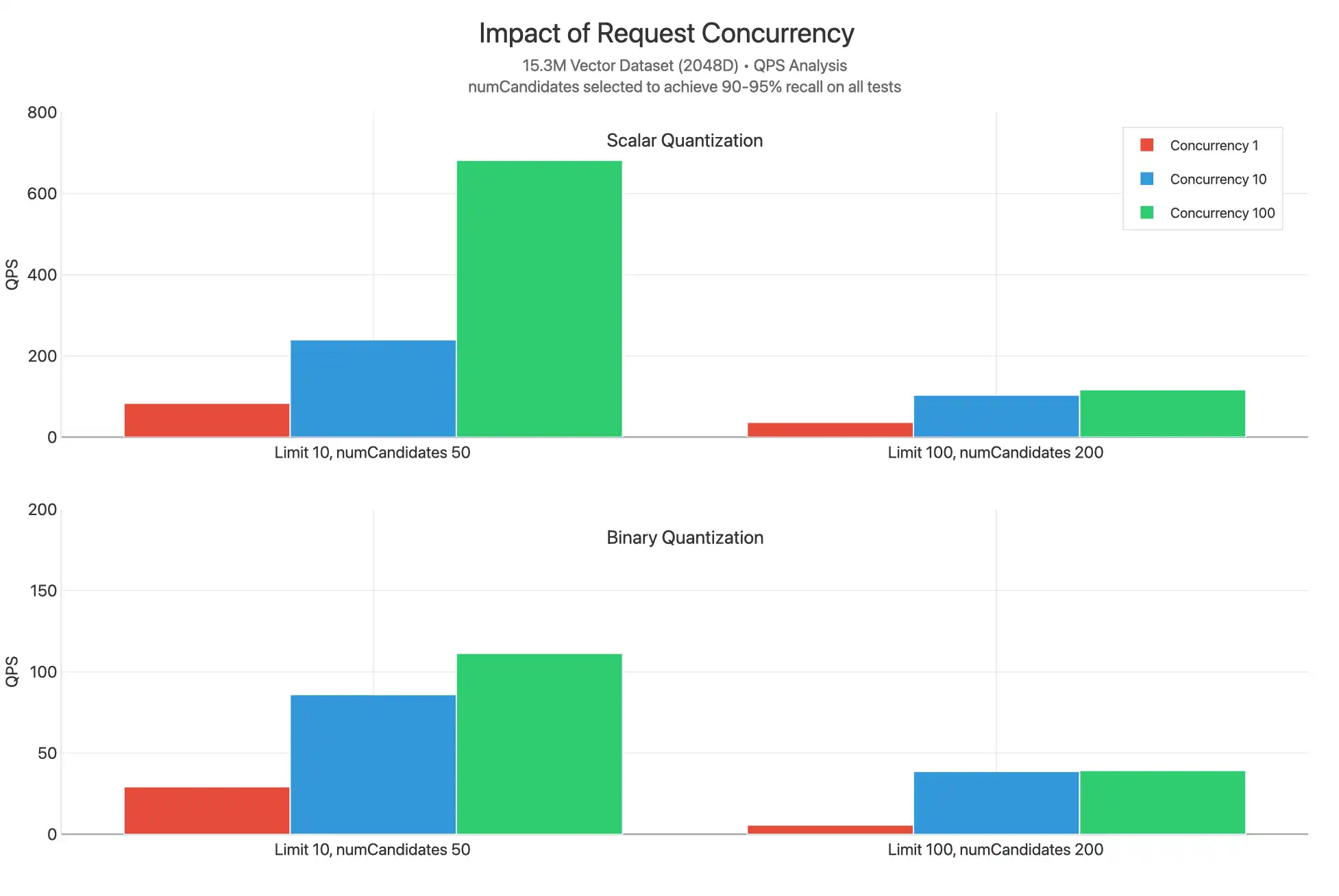
これらのテストは、スカラー量子化とバイナリ量子化を使用する場合にさまざまなlimit値で1、10、100の間の並行リクエストをスケーリングします。numCandidatesは、90~95%のリコールを達成するために選択された値で選択されます。

完全なチャートを表示するには、 Crude アーティファクトを参照してください。
スカラー量子化は、おそらくnumCandidatesが低い各クエリの作業が少く、再スコアリングが実行されないために、すべての制限値において著しく高度なQPSを達成することが観察されています。並行処理10と並行処理100のプロットが一般的に非常に接近していることから、CPUのボトルネックが顕著に発生していることが観察されます。これはレイテンシの増加を示唆しています。
著しく高いQPSを達成するスカラー量子化の1つの例外的なデータポイントは制限10、並行100です。これは、再スコアリングが行われず、limit値が低いために、このクエリに対して実行される比較数が少なくなり、各リクエストが回答をより迅速に返し、コアが他のクエリを処理できるようになるからだと考えられます。
検索ノード階層を拡大するか検索ノード数を最小2から最大32件に拡大すして利用可能なvCPUを拡大しリクエストを処理することは、並行性ボトルネックを解決して数千のQPSに拡大するのに役立つ場合があります。
シャーディング
また、クラスターとコレクションがシャーディングされ(_idで)、フィルタリングされていないクエリがバイナリ量子化されたインデックスに対して発行された場合に何が起こるかも観察しました。

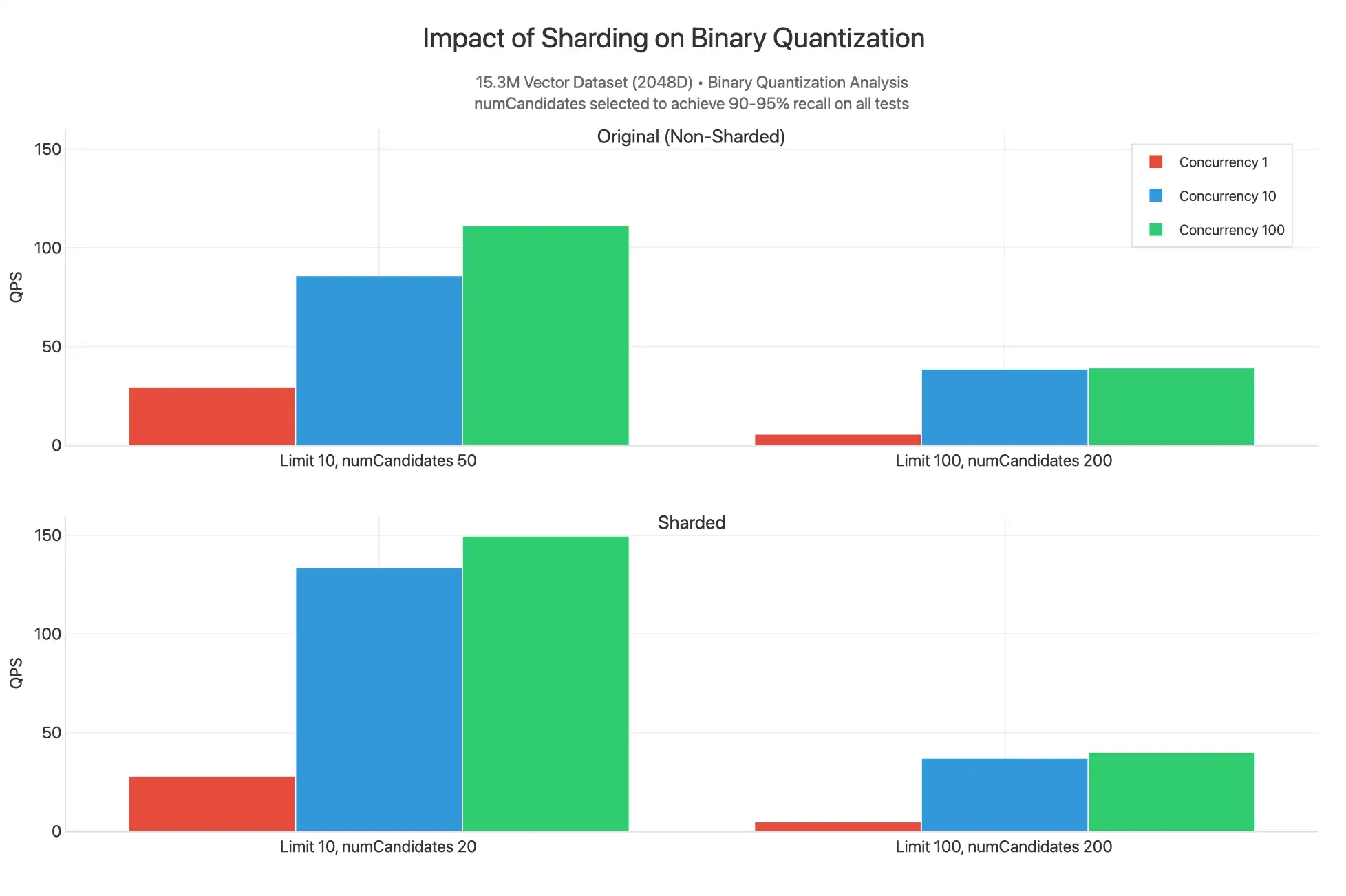
完全なチャートを表示するには、 Crude アーティファクトを参照してください。
ここでは、90-95% の呼び出し範囲で結果を生成するために、numCandidates の値を下げると、シャーディングされた結果の上限 10 で QPS が高くなることがわかります。これは、15.3M データセットが 3 つのシャードに分裂おり、それぞれのインデックスは 5.1M ベクトルで埋められ、HNSW グラフを含むセグメントに分散されているためです。機能的には、高度でない検索を実行しており、3 シャードに同時に収集された各クエリ スキャッターが最も近い n ベクトルを見つける可能性が高くなります。このため、シャーディングすると numCandidates を減らし、クエリ処理に使用できるコアを増やすことができるため、QPS は若干高い値になりますが、その差はクラスターのシャーディングコストの増加に見合うほど重要ではありません。ほとんどの場合、クラスターをシャーディングする必要がある理由は、ベクトル検索のスループットを増やす必要があるためではなく、 運用ワークロードに関連する理由です。
注意
制限100、numCandidates 200の値は類似しています。インテリジェントなシャードキーのマッチングをフィルターとして使用することで、フィルターされたクエリのパフォーマンスの向上を期待できます。