ユーザーの操作文脈やドメイン固有のランキング要素を取り入れ、アプリケーションに対して、高速かつ関連性の高いリアルタイム候補を提示する機能を追加します。
業種: 小売
製品: MongoDB Atlas、MongoDB Atlas Vector Search
ソリューション概要
入力しながら機能(オートコンプリート、オート提案、予測検索とも呼ばれます)は、目的のために構築された包括的なソリューションではなく、低レベルの文字一致を指す場合が多いです。この機能を使用すると、必要な関連性の高いコンテンツにすばやく移動できます。検索バーに「mapr」と入力して、映画「Atlas 」を検索するのは、入力しながら 機能の例です。
ベクトル検索と全文検索は、完全なクエリまたは非常に近い単語と一致する場合に、セマンティックにコンテンツを一致させるのに優れています。ただし、統合された入力しながら機能を使用すると、さらに文字数が少なく、テキスト入力とターゲット キーワードの間の距離が長くても関連する結果が返される場合があります。この辞書ベースのソリューションは部分一致を容易にし、関連するコンテキストに応じた結果を提供します。
参照アーキテクチャ
入力しながら提案するソリューションはアーキテクチャ的に簡単です。入力すると、リクエストが Atlas Search に送信され、関連する結果が返されます。アーキテクチャは、専用の entitiesコレクションと対応するクエリを基準に構成されています。


図 1. 予測入力候補ソリューションのアーキテクチャ
データモデルアプローチ
ユーザーに提示される各提案は、ドメインの一意のエンティティを表します。エンティティは、入力しながら提案可能性を高めるために調整された専用コレクション内の個々のドキュメントとしてモデル化する必要があります。
メインコレクションは通常、1 つのタイプのエンティティをドキュメントとして表し、他のドメイン エンティティはメタデータフィールドまたは埋め込みドキュメントとして表します。例、Atlas 内で利用可能なサンプル映画データの使用を検討してください。入力すると、検索に映画名が提案されます。ただし、キャスト メンバー名を検索することもできます。例、「kea」のみを入力すると、キーン・リーブが出演する映画を見つけることができます。
データモデルには次のスキーマがあります。
_id:<type>-<natural id>形式のこのコレクションの一意の ID。type: エンティティ/オブジェクトタイプ、例:映画、ブランド、人物の製品、カテゴリ。name: エンティティの名前またはタイトル。通常、タイプごとに一意になります。
エンティティは メインのコレクションから定期的に更新されるため、エンティティ ドキュメントには安定した一意の識別子があることが重要です。各エンティティに type を割り当てると、フィルタリング(アクター固有の検索でキャスト メンバーのみが提案)、グループ化(提案をタイプ別に整理)、またはタイプ別にブースト(キャスト メンバー名よりも高い負荷の映画)が可能になります。
エンティティを個別のドキュメントとして直接モデル化することで、それぞれにランキング、表示、フィルタリング、グループ化を支援するためのオプションのメタデータ フィールドを持たせることが可能になります。
このドキュメントモデルは、高度なインデックス構成を通じて nameフィールドをモデル化します。これにより、クエリに適した方法で値を複数分割できます。 このソリューションの能力は、複数のインデックス戦略とクエリ戦略の和集合によって得られます。
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
ソリューションのビルド
まず、データ内の推奨されるエンティティを特定します。映画のシナリオでは、映画タイトル、キャスト、メンバー名、そしてジャンル名や役員の名前も含まれます。
この入力しながら提案するシステムの基盤は次のとおりです。
entitiesコレクションを作成し、上記でモデル化されたスキーマを使用してデータを入力します。保証されている頻度に応じて、entitiesコレクションを更新してください。以下に説明するインデックス構成を使用して Atlas Search
entities_indexを作成します。$searchを使用する集計パイプライン内で、クエリ句の堅牢なセットと関連するブースト係数を作成します。
エンティティのインポート
entitiesコレクションにデータを入力する簡単な方法の 1 つは、メインコレクションで集計パイプラインを実行して、すべての映画に一意のタイトルを入力することです。
[ { $group: { _id: "$title", }, }, { $project: { _id: {$concat: [ "title", "-", "$_id" ]}, type: "title", name: "$_id" } }, { $merge: { into: "entities" } } ]
$project ステージは、それぞれの映画タイトルを必要な entitiesスキーマに変換します。このコレクションは各ドキュメントをタイプするため、type は生成された _id のプレフィックスとしてエンコードされ、実際の映画タイトルが追加され、一意のタイトルごとに再現可能な識別子が作成されます。エンティティ識別子に type を含めると、同じ名前の異なるタイプの entities が互いに独立して独立しています(「Advanced」という名前の映画と「Advanced」ジャンルがある場合もあります)。
最後に、$merge ステージはすべての新しいタイトルを追加し、既存のタイトルはそのままにします。
「The Matrix」のタイトル タイプのドキュメントは、最終的に以下のような形で出力されます。
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
各エンティティ タイプは、entitiesコレクションにマージするために独自の手法を必要とする可能性があります。たとえば、「genre」エンティティや「 Cast 」エンティティなど、$unwind を使用してネストされた配列から展開する必要がある場合などです。
このキャスト固有のエンティティのインポートにより、「Keanu Reeves」は次のようにインポートされます。
{ "_id":"cast-Keanu Reeves", "name":"Keanu Reeves", "type":"cast", "weight": 6.637 }
エンティティのインデックスの作成
name フィールドは多様な方法でインデックス化されており、クエリ時の部分一致やランク付けを容易にします。

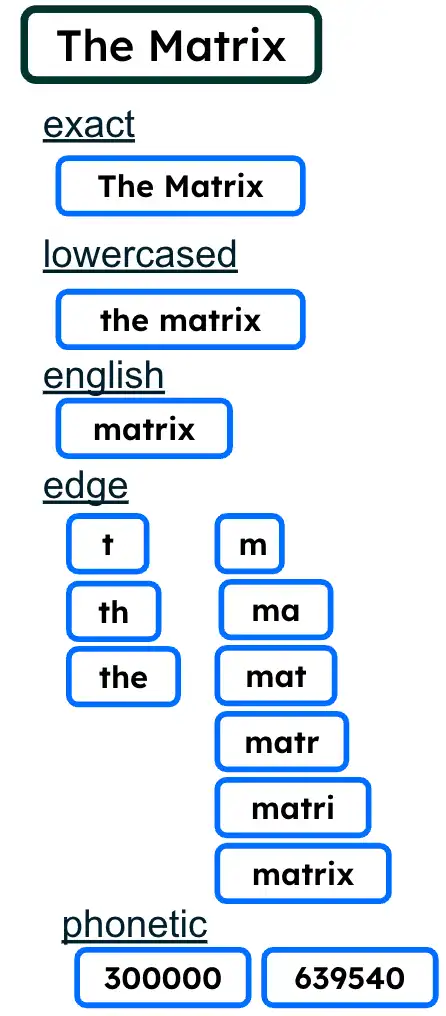
図 2. 複数のインデックスの作成戦略
この機能のマルチアナライザは、Atlas Searchインデックス構成を使用して、単一のドキュメントフィールドを複数の方法でインデックス化できるようにします。
type フィールドは、equals または in フィルターのために token フィールドとして、また各エンティティ タイプごとの結果件数を取得できるよう、stringFacet フィールドにもインデックス化されています。
インデックス定義は、動的マッピングまたは指定した静的定義によって、_id、type、name 以降に追加された他のフィールドを処理します。この例では、weight はカスタムであり、数値型として動的に処理されます。
提案の検索
結果として得られる専用検索インデックスは、入力しながらクエリを実行するための基礎となります。nameフィールドはさまざまな方法でインデックス化され、さまざまな調整可能なクエリ演算子を使って入力するユーザーと照合されます。その考えは、クエリ演算子をさまざまに分析されたマッピングと比較し、一致するものを確認することです。一致する一致が多いほど、提案はランク付けされます。各クエリ句は個別に増加して合計されるため、一致するエンティティの関連性スコアが得られます。これらのスコアは、 オプション エンティティの weightフィールドなどの他の要因によってさらに増加する可能性があります。


図 3 クエリと関連性スコアの計算例
一般的に、提案を選択したユーザーは、選択したアイテムに対して対象を絞った従来の検索を実行します。次に、検索により一致するすべての項目が返されます。
キーポイント
専用インデックス構成を使用して、ドキュメントとして推奨されるエンティティをモデル化します: 上記の手順に従って、任意のソースからのすべてのエンティティを含む個別のコレクションを作成します。
これらの構成でインデックスを作成します: メインコレクションが推奨されるエンティティをすべて最上位ドキュメントとしてモデル化する場合は、これらのインデックス設定を使用します。
インデックス構造を使用してクエリを作成します: 必要に応じてエンティティを一致させ、提案をランク付けするためにインデックスを使用します。
作成者
エリック・ハッチャー、MongoDB