生成系AIが詳細なリスク評価を生成する方法と、 MongoDB が包括的なリスク分析を可能にする方法を学習します。
業種別: 金融サービス
製品とツール: MongoDB Atlas、地理空間データ
パートナー: Google Maps API、 Fireworks.AI
ソリューション概要
ビジネスマネージドは金融操作にとって重要であり、金融組織と経済に大きなメリットを与えます。例、2023 では、米国のコマンドラインおよびインライン インデックスの値が $2.8 億 に達しました。ロンにはビジネスプランが含まれます。これにより、ドライバーのプランと財務予測が詳細になり、所有者がビジネスの目的と収益を評価するのに役立ちます。ただし、時間の制約とデータの複雑さにより、金融機関のクレジット情報の読み取りは困難です。さらに、保証がデフォルトになった場合のクレジットリスクや、経済状況が下回ると、ドライバーの支払い能力に影響場合など、フレーズ自体にリスクが生じます。
このソリューションでは、 MongoDBとジェネレーティブAI (生成AI) を使用して、ビジネス プランを分析し、ビジネス 金融の詳細なリスク評価を生成します。これはMongoDBを使用してコンテキスト データを保存し、特定のリスク評価についてクエリが可能なAIチャットボットを強化します。
生成系 AI 搭載のチャットボットによるインタラクティブなリスク分析
以下の図 1 は、ビジネス クレジットのリスクを評価するように要求した場合に、ChartGPT-4o がどの例に応答するかを示しています。保証目的とビジネス説明の入力は簡単ですが、ジェネレーティブAIにより詳細な分析が提供されます。


図 1。ChatGPT-4.0 の例ビジネスローンリスク評価の応答
ジェネレーティブAI をリスク評価に適用することで、自然災害のリスクや広範な気象リスクなど、ジェネレーティブAIが評価できる追加のリスク要因を調べることができます。図の 2 では、ユーザーは前の質問の要素として具体的には、ユーザーが フラッシュ リスクを追加しています。

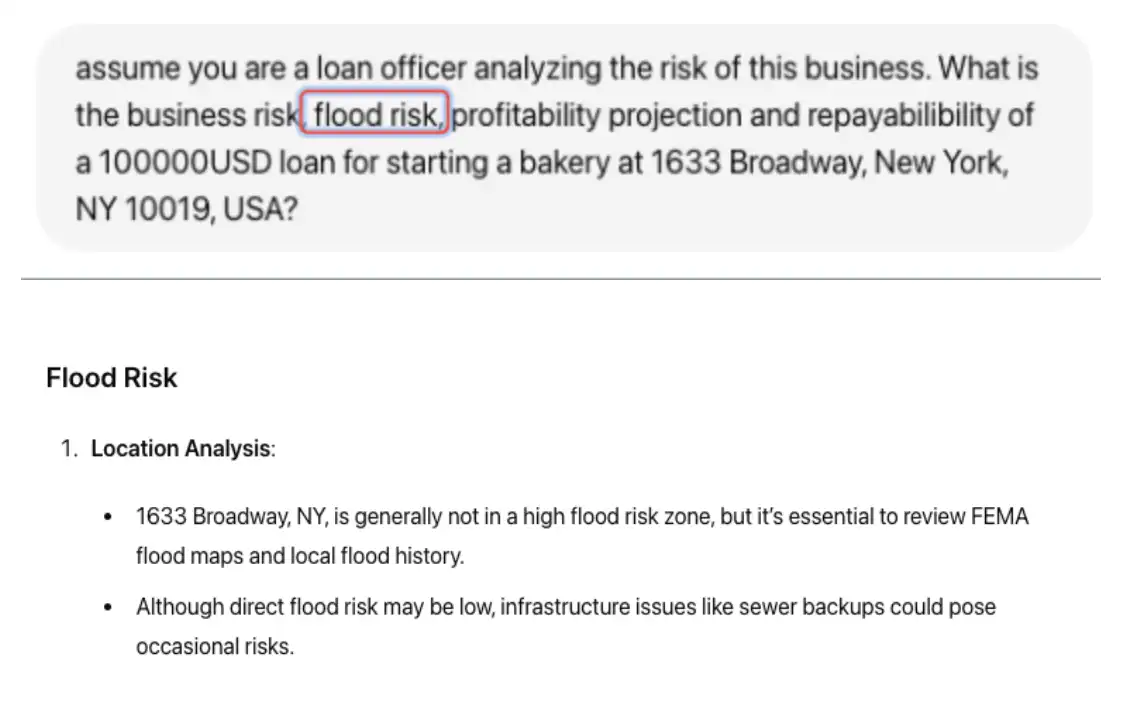
図 2。ChatGPT-4.0 の例洪水リスクを要因とした対応
応答に基づいて、フラッシュのリスクは低くなっています。ただし、 FEMA アップデート マップとローカルアップデート履歴の確認が推奨され 、最新情報がない可能性があることが示されています。情報を検証するには、HatGPT-4 に、別の方法でフレーズを並べ替えた同じ質問をすることができます。この質問と応答の例については、図 3 を参照してください。

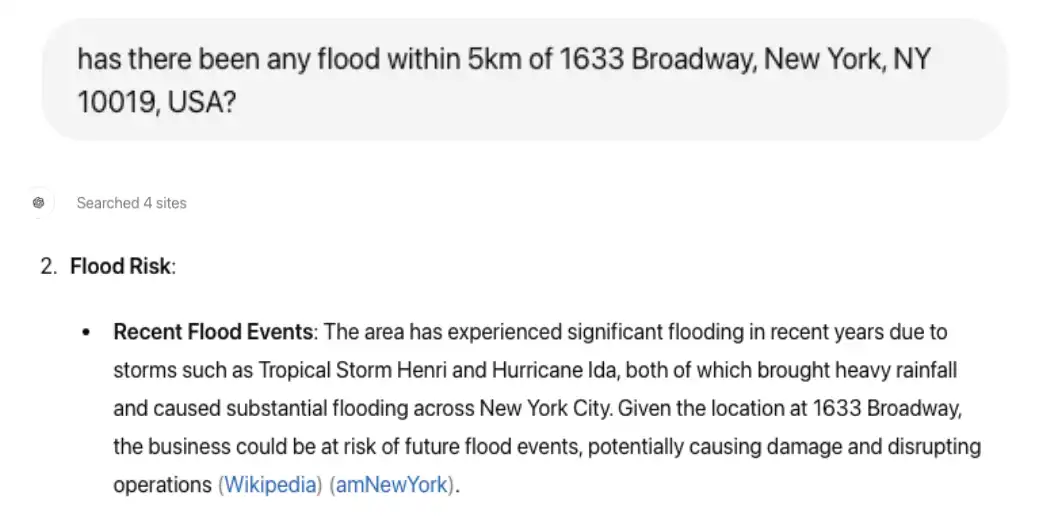
図 3。地域固有の洪水に関する質問の例
表示されているクエリでは、ChartGPT-4o は、以前は実行されなかった 4 サイトにわたるインターネット検索を実行した後に、近くで重大なアップデートが発生したことを示し、エビクションへの参照を提供するようになりました。
ChartGPT-4o に関連データがない場合、情報が不足しているため、最初の 2 つのクエリで按分リスクが低いことが示されている場合など、誤ったクレームや説明が必要になることがあります。ただし、知識ギャップを埋め込むために、追加のデータソースを認識し、インテリジェントに検索することもできます。
MongoDB の MAAP提携するである Fireworks がホストする Llama3 でも同様のテストが実行されました。 AI.この実験では、Llama 3 のフラッシュデータに関する知識がテストされ、ChartGPT-4o と同様の知識ギャップが示されています。ただし、不特定の結果を提供するのではなく、Llama 3 はフローロード データの完全なリストを提供しましたが、このデータは架空であり、デモ目的のみであることを強調しました。


図4。架空の洪水地点に対する LLM の応答
検索拡張生成(RAG)リスク分析
生成系AI はビジネス クレジットの分析を強化できますが、チャットボットと対話する場合、金融担当者は繰り返しボットにプロンプトを表示し、関連情報で質問を増やす必要があります。プロンプトを操作する能力や必要なデータが不足しているため、これには時間がかかり、非効率的になる可能性があります。
このソリューションでは、 生成AIを使用してリスク分析プロセスを強化し、 LM の知識ギャップを埋めます。MongoDBを使用してデータを保存し、地理空間クエリを使用して、提案されたビジネスロケーションから 5 キロ以内にあるアップデートを検出します。
このデモでは、ビジネスロケーション、ビジネス目的、ビジネスプランの説明を選択します。また、[Example] ボタンも含まれているため、簡単なビジネス説明を生成できます。

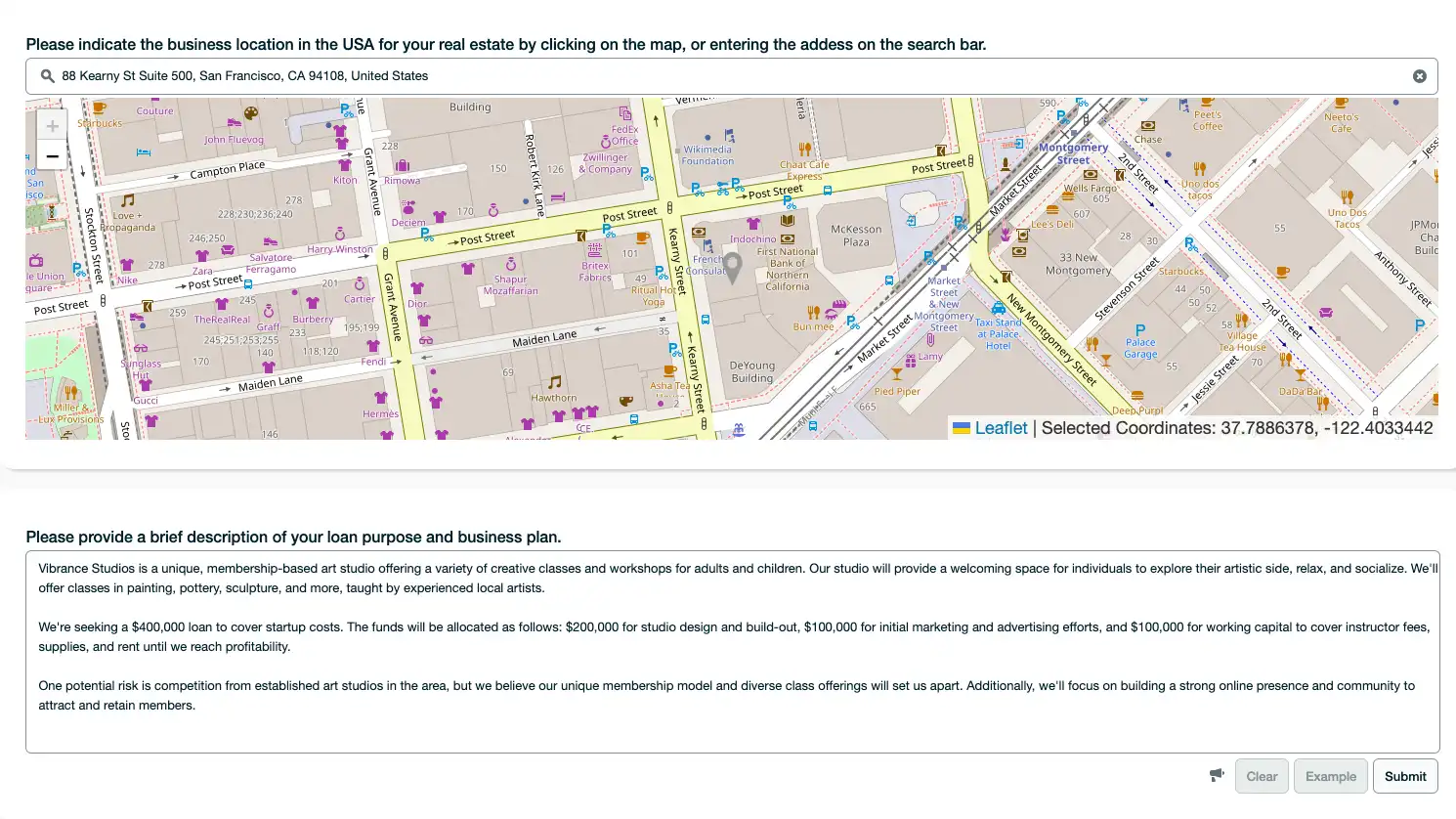
図5。融資リスク評価デモのためのユーザー入力
入力を送信すると、デモは RAG を使用したリスク分析を提供します。プロンプトエンジニアリング を使用して、外部の更新データソースからダウンロードされたロケーションと更新リスクを考慮して、ビジネスを簡素化して分析します。

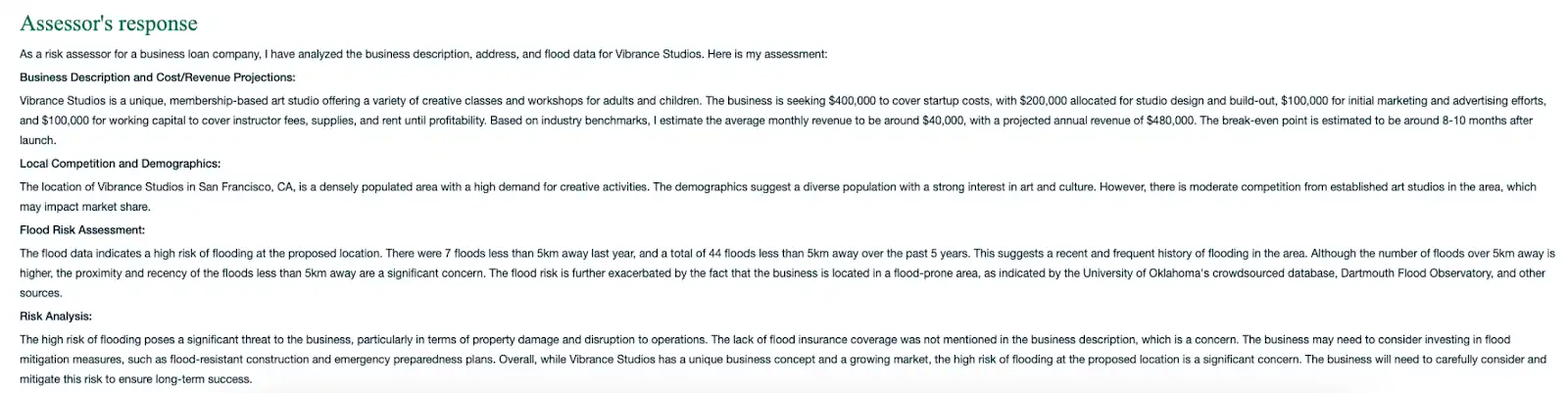
図6。RAG アーキテクチャによる融資リスクの回答
デモで「Pin」アイコンをクリックすると、すべてのサンプルフラッシュ ロケーションを表示できます。この画像では、地理ロケーション ピンは大規模なロケーションを表し、青い円は埋め込みデータがクエリされる 5 キロの半径を示します。

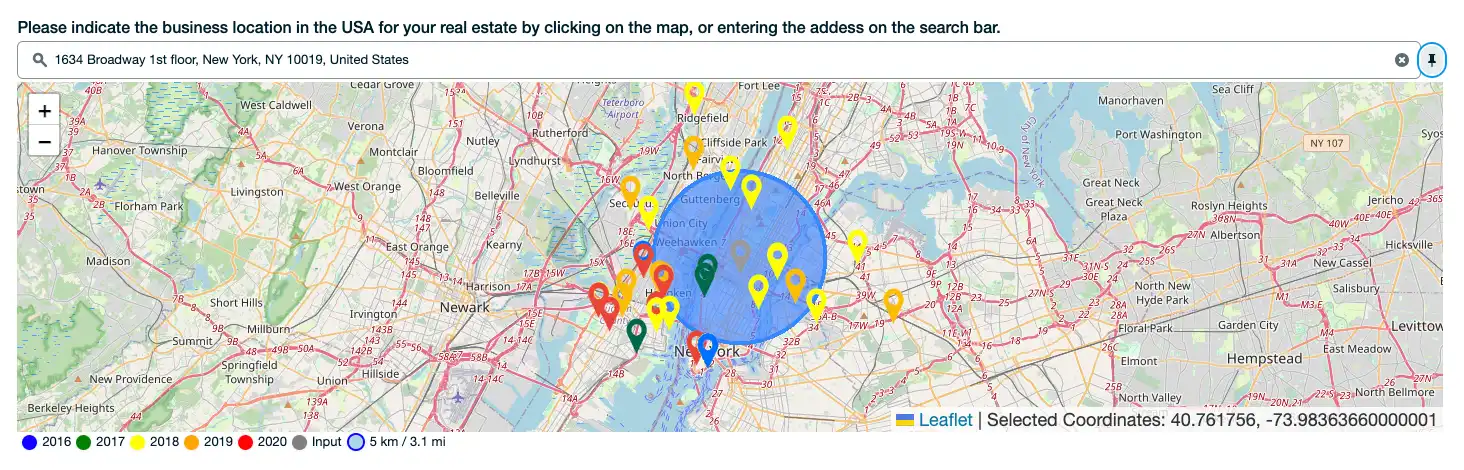
図7。デモに表示される洪水の場所
参照アーキテクチャ
以下の図は、このソリューションのアーキテクチャの概要を示しています。

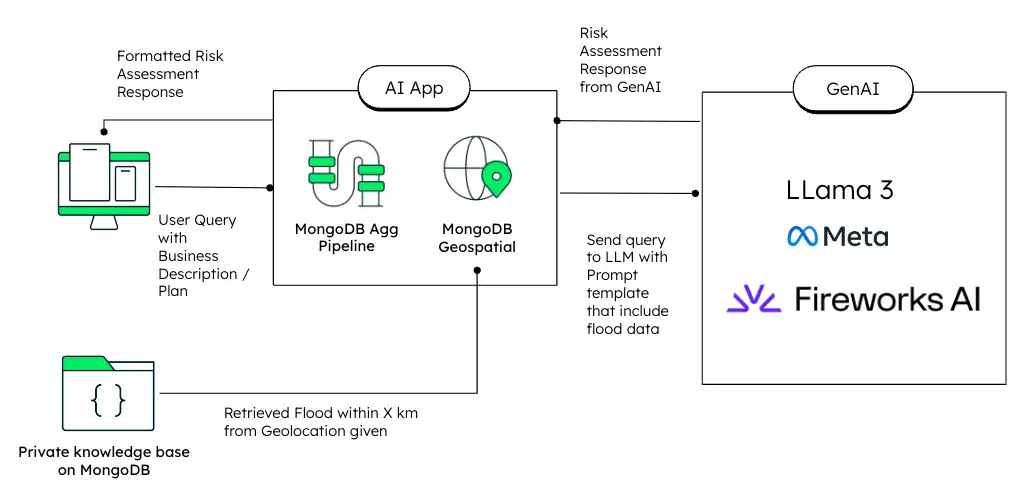
図 8。RAG データフロー アーキテクチャ図
MongoDBを使用すると、開発者はネットワーク グラフ、時系列コレクション、ベクトル検索などの機能を利用して、RAG プロセスを強化できます。結果、これにより、地理空間データを使用して大多数のリスクのある場所を識別するなど、 生成AIエージェントのコンテキストが強化され、パラメータに含まれるのを軽減できます。
RG プロセスの反復処理であるため、モデルは新しいデータとフィードバックから継続的に学習と改善を行うことができ、結果的にリスク評価の正確性が向上し、後の化する可能性が減ります。
データモデルアプローチ
以下のコード スニペットは、地理空間クエリの例です。この例では、$geoNear集計ステージを使用します。これにより、ユーザーは経度と緯度で指定された点の特定の距離内にあるすべてのロケーションを取得できます。集計パイプラインを使用して、$projectを使用して特定のフィールドを選択したり、$matchを使用して特定の条件に基づいてフィルタリングしたりするなど、他のデータ処理操作を含めることができます。
このデモで使用されるデータは、 を最新のデータセットとして、複数のソースを含む米国 Flud Database2020 から取得されます。
pipeline = [ {"$geoNear": {"near": {"type": "Point", "coordinates": [longitude, latitude]}, "distanceField": "DISTANCE", "spherical": True, "maxDistance": radius * 1000}}, {"$project": {"year": 1, "COORD": 1, "DISTANCE": 1}}, {"$match": {"year": {"$gte": 2016}}} ]
ソリューションのビルド
このソリューションを構築するための MongoDB のすべての機能を実証するコードは、次のGitHub リポジトリで入手できます。
作成者
Wei You Pan、グローバル ディレクター、金融業界向けソリューション、MongoDB