高可用性とは、インフラストラクチャの停止、システムメンテナンス、その他の中断時に、アプリケーションが継続的に稼働し、ダウンタイムを最小限に抑える能力です。MongoDB のデフォルトの配置アーキテクチャは、高可用性を実現するように設計されており、データ冗長性や自動フェイルオーバーの機能が組み込まれています。このページでは、ゾーン、リージョン、クラウドプロバイダーの停止時に中断を防ぎ、堅牢なフェイルオーバー メカニズムをサポートするために選択できる追加の構成オプションと配置アーキテクチャの強化について説明します。
高可用性を実現するための Atlas の機能
データベース レプリケーション
MongoDB のデフォルトの配置アーキテクチャは、冗長性を確保するように設計されています。Atlas では各クラスターを レプリカセットとして、最低 3 つのデータベース インスタンス(ノードまたはレプリカセット ノードとも呼ばれる)で構成し、選択したクラウドプロバイダーのリージョン内の個別のアベイラビリティーゾーンに分散して配置します。アプリケーションはレプリカセットのプライマリ ノードにデータを書き込み、その後、Atlas はそのデータを複製し、クラスター内のすべてのノードに保存します。データストレージの耐久性を制御するには、アプリケーションコードの書込み保証(write concern)を調整し、特定の数のセカンダリが書き込みをコミットした後にのみ書き込みを完了させます。デフォルトの動作では、アクションを確認する前に、データが選挙可能なノードの過半数に保持されます。
次の図は、デフォルトの 3 ノードレプリカセットにおけるレプリケーションの動作を示しています。

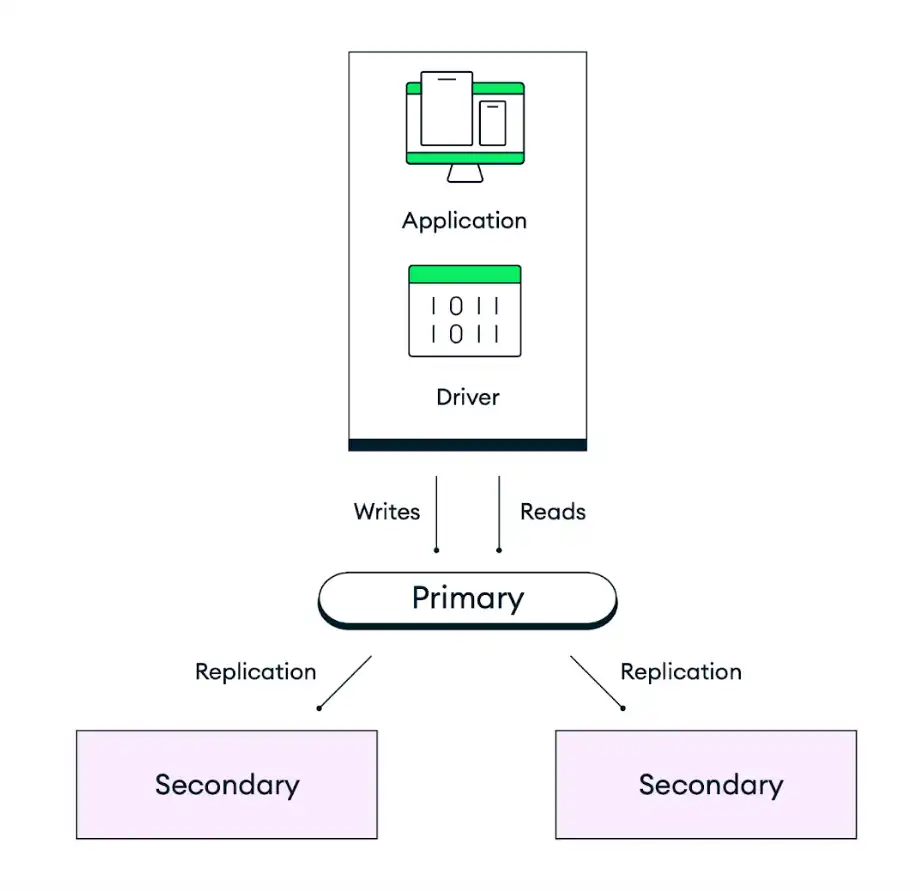
自動フェイルオーバー
インフラストラクチャの停止、定期メンテナンス、またはその他の中断によりレプリカセット内のプライマリ ノードが利用できなくなった場合、Atlas クラスターはレプリカセットの選挙で既存のセカンダリ ノードをプライマリ ノードのロールに昇格させることで自己修復します。このフェイルオーバープロセスは完全に自動で、数秒以内にデータ損失なしで完了します。これには、障害発生時に進行中だった操作も含まれ、再試行可能な書き込みが有効であれば、障害後に再試行されます。レプリカセットの選挙後、Atlas は障害のあるノードを復元または置き換え、クラスターができるだけ早くターゲット構成に戻るようにします。MongoDB クライアント ドライバーは、障害発生中および障害発生後にすべてのクライアント接続を自動的に切り替えます。
次の図は、レプリカセットの選挙プロセスを示しています。

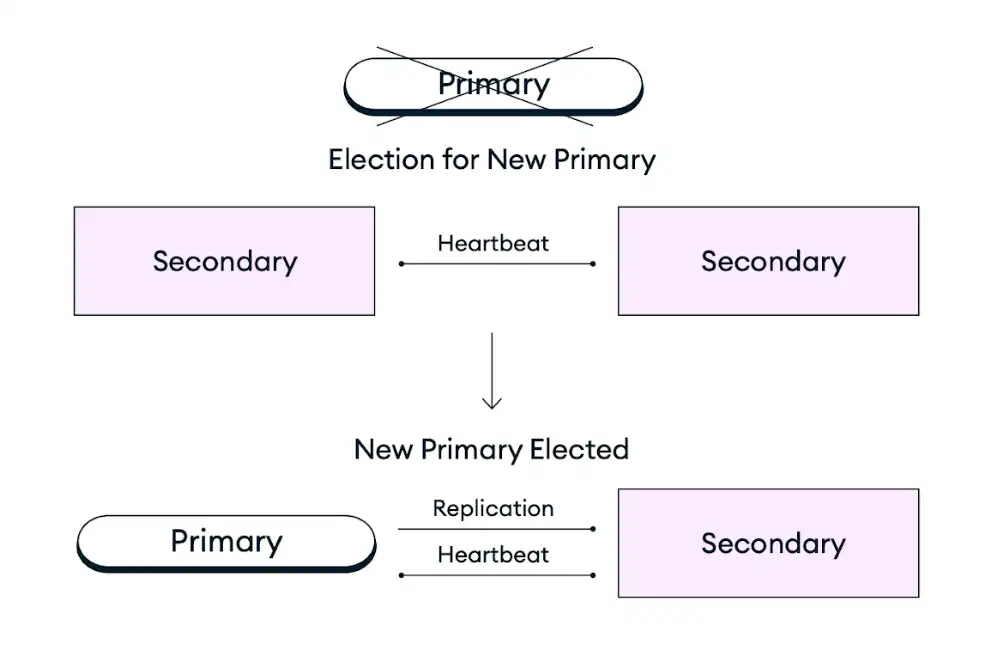
最も重要なアプリケーションの可用性を向上させるために、ノード、リージョン、またはクラウドプロバイダーを追加して、ゾーン、リージョン、またはプロバイダーの停止にそれぞれ耐えられるように配置を増やすことができます。詳細については、以下の「フォールトトレランスに向けた配置パラダイムのスケーリング」の推奨事項を参照してください。
Atlas の高可用性に関する推奨事項
次の推奨事項では、配置の可用性を高めるための追加の設定オプションと配置アーキテクチャの強化について説明します。
配置の目標に合ったクラスター階層を選択
クラスターを新規作成する場合、専用、フレックス、または無料の配置タイプで利用可能なクラスター階層範囲から選択できます。MongoDB Atlas のクラスター階層では、クラスター内の各ノードに対して使用可能なリソース(メモリ、ストレージ、vCPU、IOPS)を指定します。上位階層にスケーリングすると、トラフィックの急増を取り扱うクラスターの能力が向上し、高ワークロードに対する応答が速くなるため、システムの信頼性が向上します。アプリケーションのサイズに応じた推奨クラスター階層を決定するには、「Atlas クラスター サイズ ガイド」を参照してください。
Atlas は、クラスターが需要の急増に自動的に適応できるように、オートスケーリングをサポートしています。このアクションを自動化することで、リソース制約による停止のリスクを軽減できます。詳細については、「Atlas の自動インフラストラクチャ プロビジョニングに関するガイダンス」を参照してください。
フォールトトレランスに向けた配置パラダイムのスケーリング
Atlas 配置の耐障害性は、配置が稼働したままの状態で利用できなくなる可能性がある レプリカセット のメンバー数として測定できます。アベイラビリティゾーン、リージョン、またはクラウドプロバイダーに停止が発生した場合、Atlas クラスターは既存のセカンダリ ノードをプライマリ ノードに昇格させることで自己修復し、レプリカセットの選挙を実行します。レプリカセット内の投票ノードの過半数が稼働している必要があり、これによりプライマリ ノードに停止が発生した際に選挙が行われます。
部分的なリージョン停止が発生した場合でも、レプリカセットがプライマリを選出できるようにするには、少なくとも 3 つのアベイラビリティゾーンにわたってクラスターを配置する必要があります。アベイラビリティゾーン は、単一のクラウドプロバイダー リージョン内で電源、冷却、ネットワーク インフラを個別に備えたデータセンターのグループとして区分されています。Atlas は、クラウドプロバイダー リージョンが対応している場合、クラスターを複数のアベイラビリティゾーンに自動的に分散します。これにより、1 つのゾーンで停止が発生しても、残りのノードが引き続きリージョナル サービスをサポートします。Atlas が対応するほとんどのクラウドプロバイダー リージョンには、少なくとも 3 つのアベイラビリティゾーンがあります。これらのリージョンは、Atlas UI 内で星アイコン付きで表示されます。推奨リージョンの詳細については、「クラウドプロバイダーとリージョン」を参照してください。
最も重要なアプリケーションの耐障害性をさらに向上させるには、ノード、リージョン、またはクラウドプロバイダーを追加して、アベイラビリティーゾーン、リージョン、またはプロバイダーの停止にそれぞれ耐えられるように配置を増やすことができます。ノード数を任意の奇数に増やすことができます。選挙可能なノードの最大数は 7、合計ノード数は 50 です。クラスターを複数のリージョンに配置することで、広域にわたる可用性を高め、プライマリ リージョン内のすべてのアベイラビリティゾーンが無効になるような全リージョン停止の際にも、自動フェイルオーバーを可能にします。同様のパターンは、クラスターを複数のクラウドプロバイダーに配置する場合にも適用され、クラウドプロバイダー全体の停止に耐えられるようにします。
高可用性、低レイテンシ、コンプライアンス、コストのニーズをバランスよく満たす配置を選択するためのガイダンスについては、「Atlas 配置パラダイム」のドキュメントをご覧ください。
クラスターの誤削除を防止する
終了保護を有効にすると、クラスターが誤って終了してバックアップからの復元にダウンタイムが必要になることがなくなります。終了保護が有効になっているクラスターを削除するには、まず終了保護を無効にする必要があります。デフォルトでは、Atlas はすべてのクラスターの終了保護を無効にします。
Terraform のような IaC ツールを活用する際、再配置が新しいインフラをプロビジョニングしないようにするために、終了保護を有効にすることは特に重要です。
自動フェイルオーバーをテストする
本番環境にアプリケーションを配置する前に、自動ノード フェイルオーバーが必要となるさまざまなシナリオをシミュレーションし、そのようなイベントへの対応準備ができているかを確認することを強く推奨します。Atlasを使用すると、レプリカセットのプライマリノードのフェイルオーバーをテストや、マルチリージョン配置におけるリージョン停止のシミュレーションを実行できます。
majority 書込み保証を使用
MongoDBは、書込み保証 (write concern) を使用して、書き込み操作に要求される確認応答のレベルを指定できます。Atlas のデフォルトの書込み保証は majority であり、つまり、データは Atlas が成功を報告する前に、クラスター内のノードの過半数で複製される必要があります。2 のような固定値ではなく majority を使用することで、Atlas は一時的なノード停止が発生した場合でも、より少ないノード間でのレプリケーションに自動的に対応し、フェイルオーバー後も一括書き込みを継続できるようにします。これにより、すべての環境で一貫した設定が維持され、テスト環境でノードが 3 つの場合でも、本番環境でより多くのノードがある場合でも、接続文字列は変わりません。
再試行可能なデータベース読み取りおよび書き込みの構成
Atlas は、再試行可能な読み取りおよび再試行可能な書き込み操作をサポートしています。有効化すると、Atlas は断続的なネットワーク停止や、アプリケーションが一時的に正常なプライマリ ノードを検出できないレプリカセット選挙に対する保護として、読み取りおよび書き込み操作を 1 回再試します。再試行可能な書き込みには、確認済みの 書込み保証 (write concern) が必要です。つまり、書込み保証 (write concern) は {w:
0} に設定できません。
リソース利用状況のモニターとプラン
リソース容量の問題を回避するため、リソース利用状況を監視し、定期的にキャパシティー プラン セッションを実施することを推奨します。MongoDB のProfessional Services では、これらのセッションを提供しています。また、リソース容量障害復旧プランに関する推奨事項を確認し、リソース容量の問題からの復旧方法をご参照ください。。
リソース使用率に関するアラートとモニタリングのベストプラクティスについては、Atlas のモニタリングとアラートのガイダンスを参照してください。
MongoDB バージョンの変更を計画する
新機能を活用し、セキュリティ保証を強化するために、最新の MongoDB バージョンを使用することを推奨します。また、現在使用しているバージョンが終了に到達する前に、常に最新の MongoDB メジャー バージョンにアップグレードするようにしてください。
Atlas UIを使用して MongoDB のバージョンをダウングレードすることはできません。このため、MongoDB の Professional Services またはテクニカル サービスと直接連携し、メジャーバージョンのアップグレードを計画・実行することを推奨します。これにより、アップグレード プロセス中に発生し得る問題を回避できます。
メンテナンスウィンドウの構成
Atlas は、一度に 1 つのノードにローリング方式で更新を適用することで、スケジュールされたメンテナンス中にアップタイムを維持します。メンテナンス中に現在のプライマリがオフラインになると、Atlas は新しいプライマリを自動レプリカセット選挙により選出します。これは、計画外のプライマリ ノード停止に対応する自動フェイルオーバー中に発生するプロセスと同じです。
プロジェクトにカスタム メンテナンスウィンドウを構成し、ビジネスに重要な時間帯におけるメンテナンス関連のレプリカセット選挙を回避することを推奨します。メンテナンスウィンドウ設定で保護時間を指定し、標準アップデートを開始できない日次の時間帯を定義することも可能です。標準更新には、クラスターの再起動や再同期は含まれません。
オートメーションの例:Atlas の高可用性
次の例では、Atlas のオートメーション用ツールを使用して、単一リージョン、3 ノード レプリカセット / シャード配置トポロジーを構成します。
これらの例では、次のようなその他の推奨される構成も適用されます。
開発およびテスト環境用にクラスター階層が
M10に設定されました。クラスター サイズ ガイドを使用して、アプリケーションのサイズに合った推奨クラスター階層を確認してください。単一リージョン、3 ノード レプリカ セットまたはシャード配置トポロジー。
当社の例では、AWS、Azure、および Google Cloud を互換的に使用します。これら 3 つのクラウド プロバイダーのいずれかを使用できますが、クラウド プロバイダーに一致するようにリージョン名を変更する必要があります。クラウドプロバイダーとそのリージョンに関する詳細は、「クラウドプロバイダー」をご覧ください。
中規模アプリケーション用のクラスター階層が
M30に設定されました。クラスター サイズ ガイドを使用して、アプリケーションのサイズに合った推奨クラスター階層を確認してください。単一リージョン、3 ノード レプリカ セットまたはシャード配置トポロジー。
当社の例では、AWS、Azure、および Google Cloud を互換的に使用します。これら 3 つのクラウド プロバイダーのいずれかを使用できますが、クラウド プロバイダーに一致するようにリージョン名を変更する必要があります。クラウドプロバイダーとそのリージョンに関する詳細は、「クラウドプロバイダー」をご覧ください。
注意
Atlas CLI を使用してリソースを作成する前に、次の手順を実行する必要があります。
Programmatic Useの手順に従って Atlas CLI から接続します。
プロジェクトごとに 1 つのデプロイメントを作成
開発環境およびテスト環境においては、各プロジェクトに対して以下のコマンドを実行してください。以下の例では、ID や名前を変更し、お使いの値に置き換えてください。
注意
次の例では、開発およびテスト環境におけるコスト管理のため、オートスケーリングは有効になっていません。ステージングおよび本番環境では、オートスケーリングを有効にする必要があります。オートスケーリングを有効にした例については、「ステージングと本番環境」タブをご参照ください。
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=dev \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
ステージング環境と本番環境において、各プロジェクトごとに次の cluster.json ファイルを作成します。ID と名前を変更して、自分の値を使用します。
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
cluster.json ファイルを作成した後、各プロジェクトで次のコマンドを実行します。このコマンドは、cluster.json ファイルを使用してクラスターを作成します。
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
この例に関する追加の構成オプションや情報については、atlas clusters create コマンドを参照してください。
注意
重要
以下の例は、MongoDB Atlas Terraform プロバイダー バージョン 2.x(~> 2.2)を使用しています。プロバイダーのバージョン1.x からアップグレードする場合は、「2.0.0 アップグレードガイド」を参照してください。このガイドには、重大な変更点や移行手順が記載されています。例では、mongodbatlas_advanced_cluster リソースが v2.x 構文で使用されています。
プロジェクトとデプロイメントを作成する
開発環境およびテスト環境では、アプリケーションと環境のペアごとに次のファイルを作成します。各アプリケーションと環境ペアのファイルを 独自のディレクトリに配置します。ID と名前を変更して、 値を使用します。
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
注意
マルチリージョンクラスターを作成するには、各リージョンをそれぞれの region_configs オブジェクトに指定し、それらを replication_specs オブジェクトにネストします。priority フィールドは降順で定義され、次の例に示すように 7 から 1 までの値で構成される必要があります。
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
ファイルを作成した後、各アプリケーションと環境ペアのディレクトリに移動し、次のコマンドを実行して Terraform を初期化します。
terraform init
Terraform プランを表示するには、次のコマンドを実行します。
terraform plan
次のコマンドを実行して、アプリケーションと環境のペアに対して 1 つのプロジェクトと 1 つのデプロイメントを作成します。コマンドは、ファイルと MongoDB & HashiCorp Terraform を使用して、プロジェクトとクラスターを作成します。
terraform apply
プロンプトが表示されたら、yes を入力し、Enter を押して設定を適用します。
ステージング環境と本番環境において、各アプリケーションと環境のペアごとに以下のファイルを作成します。各アプリケーションと環境のペアごとに、それぞれのディレクトリ内でファイルを配置します。ID と名前を変更して、自分の値を使用します。
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
注意
マルチリージョンクラスターを作成するには、各リージョンをそれぞれ独自のregion_configs で指定し、それらをreplication_specs オブジェクトにネストします。以下の例をご覧ください。
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
ファイルを作成した後、各アプリケーションと環境ペアのディレクトリに移動し、次のコマンドを実行して Terraform を初期化します。
terraform init
Terraform プランを表示するには、次のコマンドを実行します。
terraform plan
次のコマンドを実行して、アプリケーションと環境のペアに対して 1 つのプロジェクトと 1 つのデプロイメントを作成します。コマンドは、ファイルと MongoDB & HashiCorp Terraform を使用して、プロジェクトとクラスターを作成します。
terraform apply
プロンプトが表示されたら、yesと入力し、Enterを押して設定を適用してください。
この例に関するその他の設定オプションや情報については、「MongoDB & HashiCorp Terraform」およびMongoDB Terraform のブログ記事をご覧ください。