このチュートリアルでは、 RAGアプリケーション を評価する方法を学びます。評価は、正しいモデルを選択し、モデルのパフォーマンスがプロトタイプから本番環境に変換されることを確認し、パフォーマンスの低下を防ぐのに役立ちます。
具体的には、次のアクションを実行します。
環境を設定します。
評価データセット をダウンロードします。
ドキュメントチャンクと埋め込みを作成します。
埋め込みを Atlas に取り込みます。
取得のために埋め込みモデルを比較します。
生成の完了モデルを比較します。
全体的な RAG パフォーマンスを測定します。
MongoDB Charts でパフォーマンスの一定期間を追跡する。
注意
このチュートリアルでは、LM モデルではなく、LM アプリケーションの評価に焦点を当てています。 LVM モデルを評価するには、さまざまなタスクにわたって特定のモデルのパフォーマンスを測定する必要があります。 LMアプリケーション評価では、プロンプトや検索バーなどの LMアプリケーションのさまざまなコンポーネントと、システム全体を評価する方法について説明します。
このチュートリアルの実行可能なバージョンを Python エディタとして操作します。
バックグラウンド
このチュートリアルでは、RAM オープンソース評価フレームワークを使用して、次のメトリクスで RAG のパフォーマンスを測定します。
検索メトリクス: コンテキスト精度とコンテキスト呼び出しは、検索バーが関連情報をどの程度見つけているかを測定します。
生成メトリクス: 成功率と応答の関連性は、LM が正確で関連性の高い応答をどの程度生成するかを測定します。
全体的なメトリクス: 応答の類似性と応答の正確性は、生成された応答を真実と比較します。
これらのメトリクスの詳細については、RAM ドキュメントの「 R内の メトリクス 」を参照してください。
このチュートリアルでは、Hubingface の las-wikia230 データセットを使用します。このデータセットには、フィールド 真実の応答を持つ約 の一般知識の質問が含まれています。
前提条件
Atlas の サンプル データ セット からの映画データを含むコレクションを使用します。
MongoDBバージョン 以降を実行中MongoDB6.0.11 Atlasクラスター。 IPアドレスがプロジェクトのアクセス リストにあることを確認します。
OpenAI の 埋め込みとチャット完了モデルを使用するための OpenAI APIキー 。
次のように構成されたターミナル。
Python 3.10 以降。
環境を設定する
評価データセットをダウンロード
Hドキュメントから las-wikia データセットをダウンロードし、pandas データフレームに変換します。
from datasets import load_dataset import pandas as pd data = load_dataset("explodinggradients/ragas-wikiqa", split="train") df = pd.DataFrame(data)
データセットには、次の列が含まれています。
question: ユーザーの質問correct_answer: 真実の結果context: 質問に答えるための参照テキストのリスト
ドキュメント チャンクの作成
埋め込み前に、参照テキストを小さなチャンクに分割します。
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text by tokens using the tiktoken tokenizer text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( encoding_name="cl100k_base", keep_separator=False, chunk_size=200, chunk_overlap=30 ) def split_texts(texts): chunked_texts = [] for text in texts: chunks = text_splitter.create_documents([text]) chunked_texts.extend([chunk.page_content for chunk in chunks]) return chunked_texts # Split the context field into chunks df["chunks"] = df["context"].apply(lambda x: split_texts(x)) # Aggregate list of all chunks all_chunks = df["chunks"].tolist() docs = [item for chunk in all_chunks for item in chunk]
Tip
検索を評価するときは、さまざまなチャンク戦略を試してください。このチュートリアルでは、埋め込みモデルの評価に焦点を当てます。
MongoDB Charts への埋め込みと取り込みの作成
チャンクされたドキュメントを埋め込み、Atlas に取り込みます。比較する埋め込みモデルごとに個別のコレクションを作成します。
埋め込み関数を定義する
OpenAI APIを使用して埋め込みを生成する関数を作成します。
from typing import List def get_embeddings(docs: List[str], model: str) -> List[List[float]]: """Generate embeddings using the OpenAI API.""" docs = [doc.replace("\n", " ") for doc in docs] response = openai_client.embeddings.create(input=docs, model=model) return [r.embedding for r in response.data]
Atlas への取り込み
チャンクされたドキュメントを Atlas コレクションに埋め込み、取り込みます。
from pymongo import MongoClient from tqdm.auto import tqdm client = MongoClient(MONGODB_URI) DB_NAME = "ragas_evals" db = client[DB_NAME] batch_size = 128 EVAL_EMBEDDING_MODELS = ["text-embedding-ada-002", "text-embedding-3-small"] for model in EVAL_EMBEDDING_MODELS: embedded_docs = [] print(f"Getting embeddings for the {model} model") for i in tqdm(range(0, len(docs), batch_size)): end = min(len(docs), i + batch_size) batch = docs[i:end] batch_embeddings = get_embeddings(batch, model) batch_embedded_docs = [ {"text": batch[i], "embedding": batch_embeddings[i]} for i in range(len(batch)) ] embedded_docs.extend(batch_embedded_docs) collection = db[model] collection.delete_many({}) collection.insert_many(embedded_docs) print(f"Finished inserting embeddings for the {model} model")
ベクトル検索インデックスの作成
各コレクションに対してMongoDB ベクトル検索インデックスを作成します。インデックス名 vector_index を持つ次のインデックス定義を使用します。
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
インデックスの作成方法については、 「 MongoDB ベクトル検索インデックスの作成 」を参照してください。
Tip
text-embedding-ada-002 と text-embedding-3-small の両方に 1536 次元があるため、同じインデックス定義が両方のコレクションで機能します。
埋め込みモデルの比較
LM に適したコンテキストを取得するには、さまざまな埋め込みモデルを比較します。このチュートリアルでは、text-embedding-ada-002 とtext-embedding-3-small を比較します。
検索関数の作成
LgChuin とMongoDB Atlasを使用してベクトルストア検索を取得する関数を作成します。
from langchain_openai import OpenAIEmbeddings from langchain_mongodb import MongoDBAtlasVectorSearch from langchain_core.vectorstores import VectorStoreRetriever def get_retriever(model: str, k: int) -> VectorStoreRetriever: """ Get a vector store retriever for a given embedding model. Args: model (str): Embedding model to use k (int): Number of results to retrieve Returns: VectorStoreRetriever: A vector store retriever object """ embeddings = OpenAIEmbeddings(model=model) vector_store = MongoDBAtlasVectorSearch.from_connection_string( connection_string=MONGODB_URI, namespace=f"{DB_NAME}.{model}", embedding=embeddings, index_name="vector_index", text_key="text", ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": k} ) return retriever
検索を評価する
RAM ライブラリの context_precision と context_recall メトリクスを使用して、各埋め込みモデルを評価します。
from datasets import Dataset from ragas import evaluate, RunConfig from ragas.metrics import context_precision, context_recall import nest_asyncio # Allow nested use of asyncio (used by RAGAS) nest_asyncio.apply() for model in EVAL_EMBEDDING_MODELS: data = {"question": [], "ground_truth": [], "contexts": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH retriever = get_retriever(model, 2) # Get relevant documents for the evaluation dataset for i in tqdm(range(0, len(QUESTIONS))): data["contexts"].append( [doc.page_content for doc in retriever.invoke(QUESTIONS[i])] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[context_precision, context_recall], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
サンプルデータセットの埋め込みモデルの評価結果は次のとおりです。
モデル | コンテキストの精度 | コンテキスト呼び出し |
|---|---|---|
text- embedded-da-002 | 0.9310 | 0.8561 |
text- embedded-3-small | 0.9116 | 0.8826 |
これらの結果に基づいて、text-embedding-ada-002 は最も関連性の高い結果をより高くランク付けしますが、text-embedding-3-small は除外された結果とより整合性のあるコンテキストを検索します。このチュートリアルでは、埋め込みモデルとして text-embedding-3-small を使用します。
完了モデルの比較
最適な埋め込みモデルを選択したので、 RGアプリケーションの生成コンポーネントの完了モデルを比較します。
RAG チェーンの作成
LgChuin を使用して RG チェーンを構築する関数を作成します。
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.runnables.base import RunnableSequence from langchain_core.output_parsers import StrOutputParser def get_rag_chain(retriever: VectorStoreRetriever, model: str) -> RunnableSequence: """ Create a basic RAG chain. Args: retriever (VectorStoreRetriever): Vector store retriever object model (str): Chat completion model to use Returns: RunnableSequence: A RAG chain """ # Generate context using the retriever, and pass the user question through retrieve = { "context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough(), } template = """Answer the question based only on the following context: \ {context} Question: {question} """ # Define the chat prompt prompt = ChatPromptTemplate.from_template(template) # Define the model for chat completion llm = ChatOpenAI(temperature=0, model=model) # Parse output as a string parse_output = StrOutputParser() # RAG chain rag_chain = retrieve | prompt | llm | parse_output return rag_chain
完了モデルを評価する
faithfulness と answer_relevancy メトリクスを使用して、さまざまな完了モデルを評価します。
from ragas.metrics import faithfulness, answer_relevancy for model in ["gpt-3.5-turbo-1106", "gpt-3.5-turbo"]: data = {"question": [], "ground_truth": [], "contexts": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) rag_chain = get_rag_chain(retriever, model) for i in tqdm(range(0, len(QUESTIONS))): question = QUESTIONS[i] data["answer"].append(rag_chain.invoke(question)) data["contexts"].append( [doc.page_content for doc in retriever.invoke(question)] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
サンプルデータセットの完了モデルの評価結果は次のとおりです。
モデル | 忠実度 | 応答の関連性 |
|---|---|---|
gpt-3.5-turbo | 0.9714 | 0.9087 |
gpt-3.5-turbo-1106 | 0.9671 | 0.9105 |
これらの結果に基づいて、最新の gpt-3.5-turbo はより因果整合性のある結果を生成しますが、古いバージョンでは特定のプロンプトに合った結果が生成されます。このチュートリアルでは、完了モデルとして gpt-3.5-turbo を使用します。
全体的なパフォーマンスの測定
最もパフォーマンスの高いモデルを使用して、RAMアプリケーションの全体的なパフォーマンスを評価します。
from ragas.metrics import answer_similarity, answer_correctness data = {"question": [], "ground_truth": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) # Use the best completion model from the generator evaluation rag_chain = get_rag_chain(retriever, "gpt-3.5-turbo") for question in tqdm(QUESTIONS): data["answer"].append(rag_chain.invoke(question)) dataset = Dataset.from_dict(data) run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[answer_similarity, answer_correctness], run_config=run_config, raise_exceptions=False, ) print(f"Overall metrics: {result}")
この評価は、RG チェーンがサンプルデータセットに対して0.8873 の応答類似性と0.5922 の応答正確性を生成することを示しています。
結果を分析します。
結果をさらに調査するには、結果を pandas データフレームに変換し、低スコアの回答をフィルタリングします。
result_df = result.to_pandas() result_df[result_df["answer_correctness"] < 0.7]
視覚的な分析用に、質問とメトリクスのヒートマップを作成します。
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) sns.heatmap( result_df[1:10].set_index("question")[["answer_similarity", "answer_correctness"]], annot=True, cmap="flare", ) plt.show()
上記のコードは、次のヒートマップを出力します。

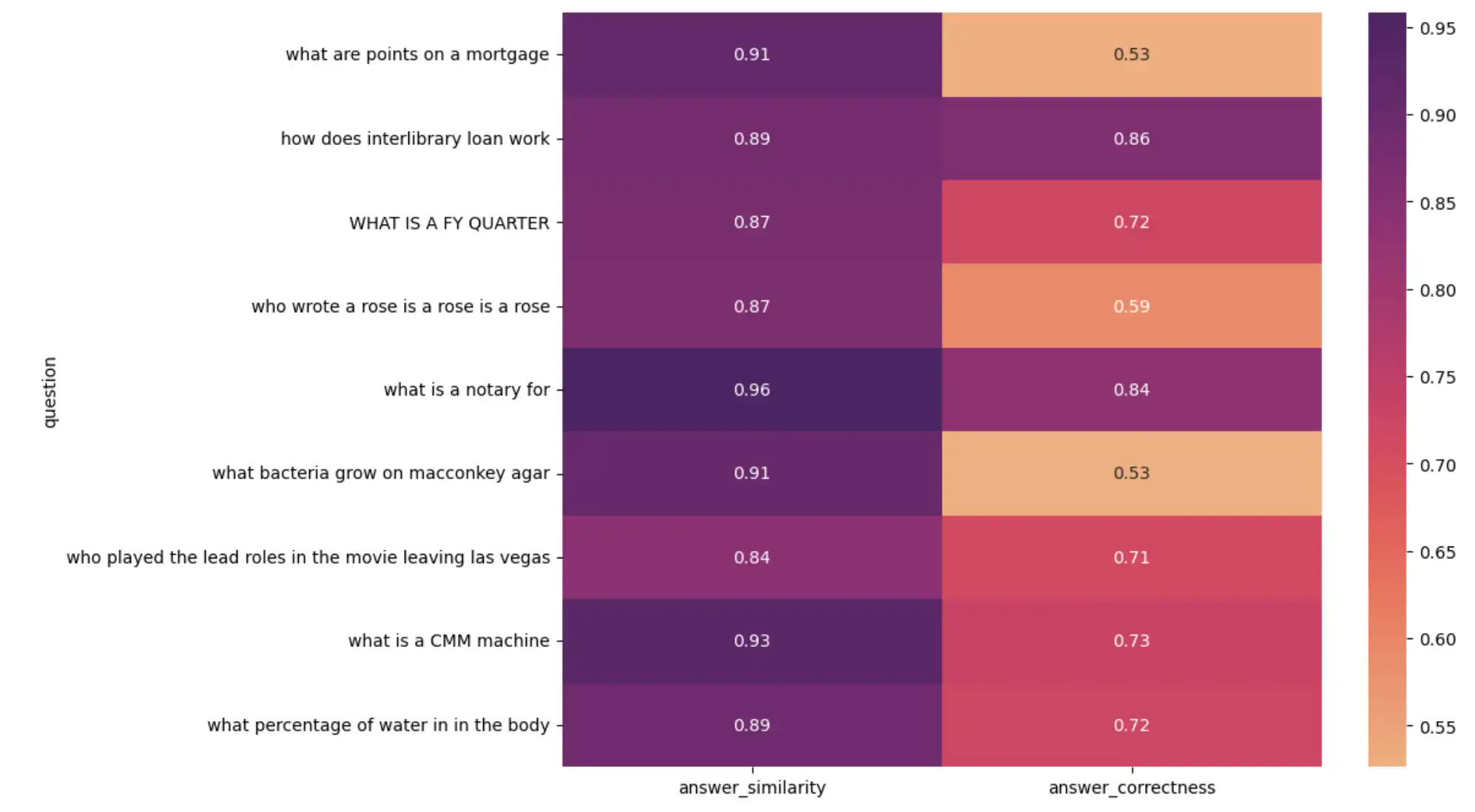
RGアプリケーションのパフォーマンスを可視化するヒートマップ
低スコアの結果を調べると、次の結果が見つかる場合があります。
評価データセット内の一部のフィールドの結果が誤っています。 LM で生成された応答は正しいですが、証明機関の結果と一致しないため、スコアが低くなります。
一部のデータ処理の結果は完全な文ですが、 LM で生成された応答は 1 つの単語または数字で表されます。
これらの結果は、LM 評価を特権チェックし、正確な評価データセットを管理することの重要性を強調します。
一定時間のパフォーマンスの追跡
評価は 1 回限りのイベントであっては なりません 。システム内のコンポーネントを変更するたびに、その変更を評価して、パフォーマンスにどのように影響かを評価してください。アプリケーションが本番環境になると、パフォーマンスをリアルタイムでモニターし、変更を検出します。
Charts を使用して、 LMアプリケーションのパフォーマンスを監視します。評価結果と追跡したいフィードバックメトリクスを Atlasコレクションに書き込みます。
from datetime import datetime result["timestamp"] = datetime.now() collection = db["metrics"] collection.insert_one(result)
このコードは評価結果に timestampフィールドを追加し、それを ragas_evalsデータベース内の metricsコレクションに書込みます。 Atlas のドキュメントは次のようになります。
{ "answer_similarity": 0.8873, "answer_correctness": 0.5922, "timestamp": "2024-04-07T23:27:30.655+00:00" }
MongoDB Charts で ダッシュボードを作成 し、一定期間にわたるメトリクスを視覚化します。チャートとダッシュボードの作成方法については、「 Chartsの構築 」を参照してください。
概要
このチュートリアルでは、 RAGASフレームワークとMongoDB Atlasを使用して RAGアプリケーションを評価する方法を学習しました。検索 用の埋め込みモデルと、生成用の完了モデルを比較し、アプリケーションの全体的なパフォーマンスを測定しました。また、 MongoDB Charts を使用して、一定の期間パフォーマンスを追跡する方法も学びます。
MongoDBを使用して RG アプリケーションを構築する方法の詳細については、次のリソースを参照してください。