注意
Atlas は現在、知識ベースとして利用可能なのは、米国にある AWS リージョンのみです。
MongoDB Atlas をAmazon Advisor の 知識ベース として使用して、生成系AIアプリケーションの構築、検索拡張生成 (RAG)(RAG)の実装、エージェントの構築を行えます。
Overview
Atlas と Amazon Bedrock の知識ベース統合により、以下のユースケースが可能になります。
MongoDB ベクトル検索の基礎モデルを使用してAIアプリケーションを構築し、RAG を実装します。使用を開始するには、使用を開始するを参照してください。
知識ベースに対してMongoDB ベクトル検索とMongoDB Search を使用してハイブリッド検索を有効にします。詳しくは、Amazon Web Services と Atlas を使用したハイブリッド検索を参照してください。
はじめる
このチュートリアルでは、 Amazon Advisor でMongoDB ベクトル検索 の使用を開始する方法を説明します。具体的には、次のアクションを実行します。
カスタム データを Amazon S 3バケットにロードします。
オプションで、AWS PrivateLink を使用してエンドポイント サービスを構成します。
データにMongoDB ベクトル検索インデックスを作成します。
Atlas にデータを保存するための知識ベースを作成します。
MongoDB ベクトル検索を使用して RAG を実装するエージェントを作成します。
バックグラウンド
Amazon Advisor は、生成系AIアプリケーションを構築するためのフルマネージド サービスです。これにより、さまざまなAI会社の基礎モデル(DM)を単一のAPIとして活用できます。
MongoDB ベクトル検索 をAmazon Web Services の知識ベースとして使用すると、Atlas にカスタム データを保存し、RAG を実装してデータの質問に答えるためのエージェントを作成できます。RG の詳細については、RAG、「MongoDBによる検索拡張生成(RAG)」を参照してください。
前提条件
Atlas の サンプル データ セット からの映画データを含むコレクションを使用します。
MongoDB バージョン6.0.11を実行している Atlas M 10 + クラスター 、 7.0.2 、またはそれ以降
AWS PrivateLink エンドポイント サービスを構成する場合にインストールされるAmazon Web Services CLI とnpm 。
カスタム データのロード
テキストデータを含む Amazon S 3バケットがまだない場合は、新しいバケットを作成し、MongoDB のベストプラクティスに関する一般にアクセス可能な次の PDF をロードします。
PDF をAmazon S3 バケットにアップロードします。
S3 バケット を作成するには、手順に従ってください。わかりやすい Bucket Name を使用していることを確認してください。
バケットにファイルをアップロードするには、手順に従います。.先ほどダウンロードした PDF を含むファイルを選択します。
エンドポイント サービスの構成
デフォルトでは 、 Amazon Advisor はパブリック インターネット経由で知識ベースに接続します。接続をさらに保護するために、 MongoDB ベクトル検索 はAWS PrivateLink エンドポイント サービスを介して仮想ネットワーク経由で知識ベースに接続することをサポートしています。
任意。次の手順を実行して、Atlas クラスターの AWS PrivateLink プライベートエンドポイントに接続するエンドポイント サービスを有効にします。
Atlasでプライベートエンドポイントを設定します。
AWS PrivateLinkクラスター用に プライベートエンドポイントを設定する Atlasには、手順に従います。プライベートエンドポイントを識別するには、わかりやすいVPC IDを使用していることを確認します。
エンドポイント サービスを構成します。
MongoDB とその提携パートナーは、クラウド開発キット(CDK)を提供しており、トラフィックをプライベートエンドポイントに転送するネットワーク ロード バランサーを基盤としたエンドポイント サービスを構成できます。
CDK Githubリポジトリ に指定された手順に従って、 CDKスクリプトを準備して実行します。
MongoDB ベクトル検索インデックスの作成
このセクションでは、コレクションにMongoDB ベクトル検索インデックスを作成し 、Atlas をベクトルデータベース(ベクトルストアと呼ばれる)として設定します。
必要なアクセス権
MongoDB ベクトル検索インデックスを作成するには、Atlasプロジェクトへの Project Data Access Admin 以上のアクセス権が必要です。
手順
Atlas で、プロジェクトの Data Explorer ページに移動します。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの Organizations メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Database見出しの下のData Explorerをクリックします。
Data Explorerが表示されます。
In Atlas で、クラスターの Search & Vector Search ページに移動します。
MongoDB 検索するページには、Search & Vector Search オプションまたは Data Explorer から移動できます。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの Organizations メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Database見出しの下のSearch & Vector Searchをクリックします。
クラスターがない場合は、Create clusterをクリックしてクラスターを作成してください。詳細については、「 クラスターの作成 」を参照してください。
プロジェクトに複数のクラスターがある場合は、Select cluster ドロップダウンから使用するクラスターを選択し、[Go to Search] をクリックします。
検索とベクトル検索ページが表示されます。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの Organizations メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Database見出しの下のData Explorerをクリックします。
データベースを展開し、コレクションを選択します。
コレクションのIndexesタブをクリックします。
バナー内の Search and Vector Search リンクをクリックします。
検索とベクトル検索ページが表示されます。
インデックスの設定を開始します。
ページで次の選択を行い、Next をクリックしてください。
Search Type | Vector Search のインデックスタイプを選択します。 |
Index Name and Data Source | 以下の情報を指定してください。
|
Configuration Method | For a guided experience, select Visual Editor. To edit the raw index definition, select JSON Editor. |
重要:
MongoDB Searchインデックスの名前はデフォルトで default です。この名前を維持する場合、インデックスは、演算子に別の index オプションを指定していないMongoDB Search クエリのデフォルトの検索インデックスになります。複数のインデックスを作成する場合は、インデックス間で一貫した記述的な命名規則を維持することをお勧めします。
MongoDB ベクトル検索インデックスを定義します。
この vectorSearch タイプのインデックス定義は、次のフィールドをインデックス化します。
embeddingベクトル型としての フィールド。embeddingフィールドには、知識ベースを構成するときに指定した埋め込みモデルを使用して作成されたベクトル埋め込みが含まれます。 インデックス定義では、1024ベクトル次元を指定し、cosineを使用して類似性を測定します。bedrock_metadata、bedrock_text_chunk、x-amz-bedrock-kb-document-page-numberフィールドを filter 型として指定して、データを事前にフィルタリングします。知識ベースを設定する際に、Amazon Bedrock でもこれらのフィールドを指定します。
注意
以前にフィルターフィールド page_number を使用してインデックスを作成した場合は、代わりに新しいフィルターフィールド名 x-amz-bedrock-kb-document-page-number を使用するようにインデックス定義を更新する必要があります。Amazon Bedrock ではフィールド名が Amazon によって更新され、古いフィールド名を使用したインデックスは Amazon Bedrock の知識ベースで正しく機能しなくなりました。
embedding をインデックスするフィールドとして指定し、1024 次元を指定します。
インデックスを設定するには、次の操作を行う必要があります。
Similarity MethodドロップダウンからCosineを選択します。
Filter Field セクションで、
bedrock_metadata、bedrock_text_chunk、x-amz-bedrock-kb-document-page-numberの各フィールドを指定してデータをフィルタリングします。
次のインデックス定義を JSON エディターに貼り付けます。
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
[1] You're All Set!ボタンをクリックして、 Closeモーダル ウィンドウを閉じます。
知識ベースの作成
このセクションでは、カスタム データをベクトルストアにロードするための知識ベースを作成します。
モデル アクセスを管理します。
Amazon Advisor は FC へのアクセスを自動的に許可しません。もしまだ行っていない場合は、手順に従って、Tiger 埋め込み G1 - テキストとアンスループット V2 1のモデル アクセスを追加します。モデル。
Atlas を KB に接続します。
Vector databaseセクションで、[Use an existing vector store] を選択します。
MongoDB Atlasを選択し、以下のオプションを構成します。
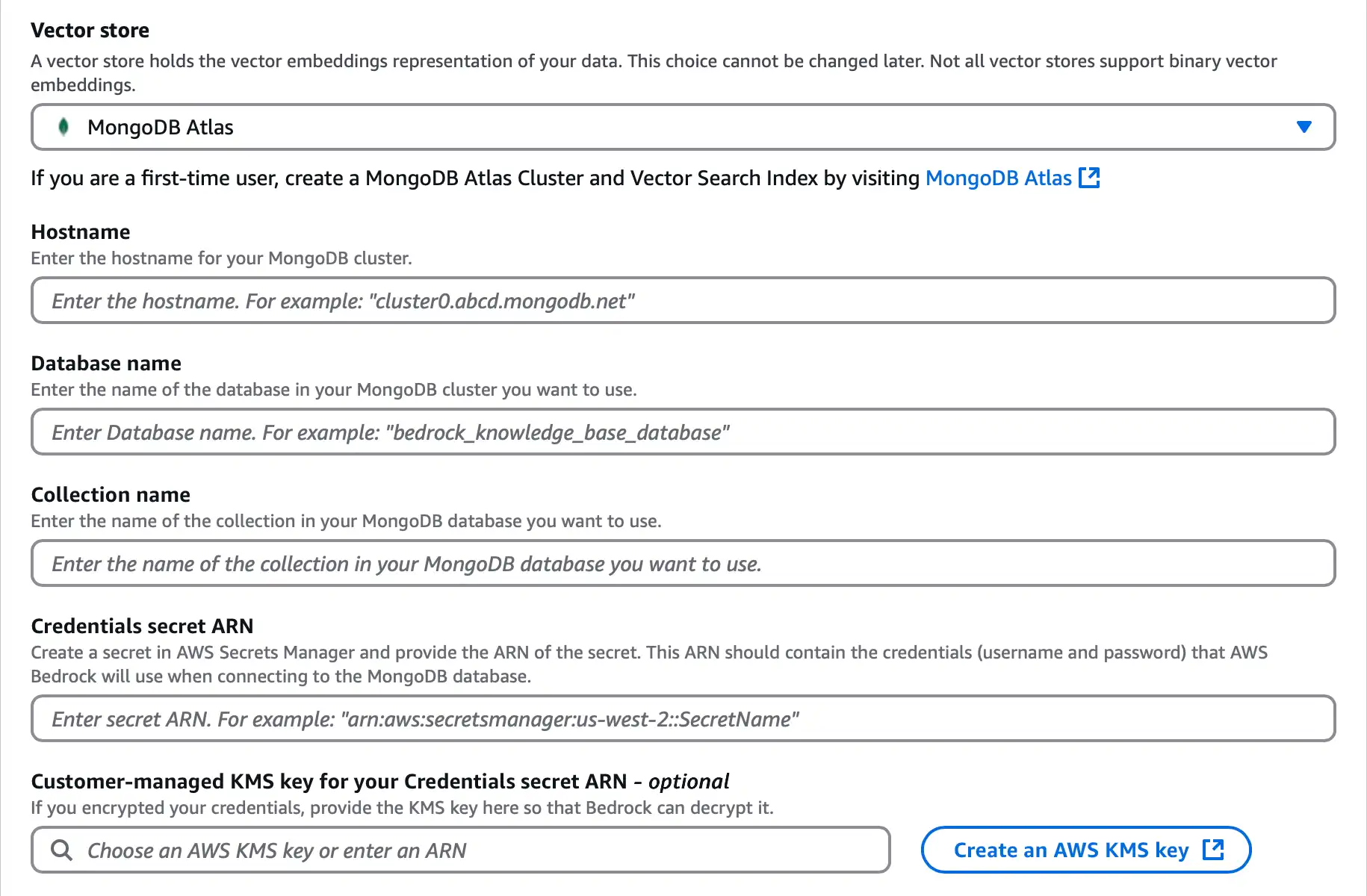
![Amazon Bedrock のベクトル ストア設定セクションのスクリーンショット。]() クリックして拡大します
クリックして拡大しますHostnameURLの場合、Atlas 接続文字列 にある クラスターの を入力します。ホスト名は次の形式を使用します。
<clusterName>.mongodb.net Database name に
bedrock_dbと入力します。Collection name に
testと入力します。には、Atlas Credentials secret ARNクラスター認証情報を含むシークレットの ARN を入力します。詳細については、 Amazon Web Services Secrets Manager の概念 を参照してください。
Metadata field mapping セクションでは、 Atlas がデータソースの埋め込みと保存に使用するMongoDB ベクトル検索インデックスとフィールド名を決定するために、次のオプションを構成します。
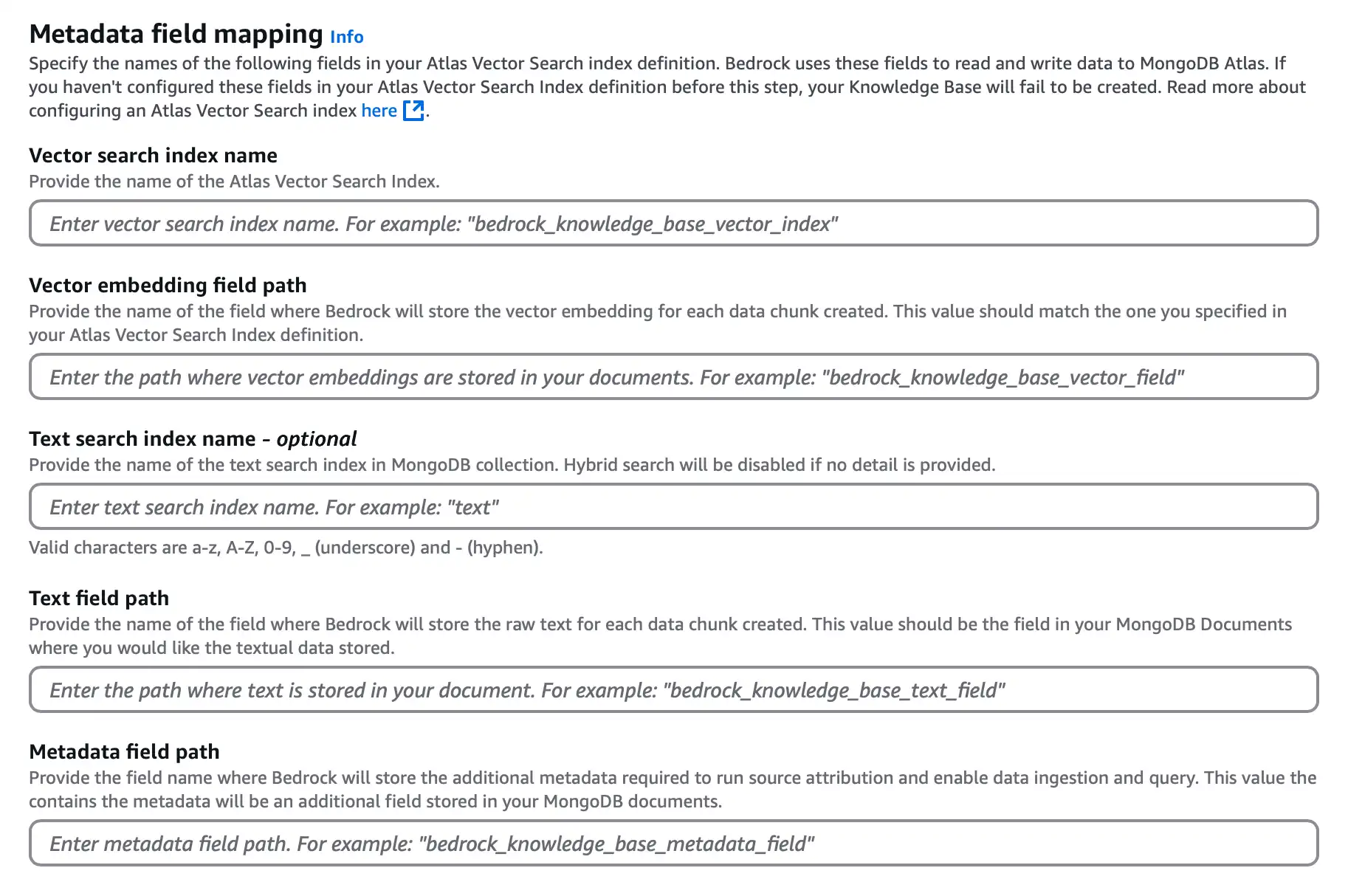
![ベクトル ストアのフィールド マッピング設定セクションのスクリーンショット。]() クリックして拡大します
クリックして拡大しますVector search index name に
vector_indexと入力します。Vector embedding field path に
embeddingと入力します。Text field path に
bedrock_text_chunkと入力します。Metadata field path に
bedrock_metadataと入力します。
注意
必要に応じて、Text search index name フィールドを指定してハイブリッド検索を設定することができます。詳細については、「Amazon Bedrock と Atlas を使用したハイブリッド検索」を参照してください。
エンドポイント サービス を構成した場合は、 PrivateLink Service Nameを入力します。
[Next] をクリックします。


データソースを同期します。
Amazon は、データを同期するように要求します。 Data sourceセクションで、データソースを選択し、 SyncをクリックしてS 3バケットのデータを同期し、Atlas に読み込みます。
Atlasbedrock_db.test を使用している場合は、同期が完了したら、Atlas UIの 名前空間に移動してベクトル埋め込みを確認できます。
エージェントを構築する
このセクションでは、 MongoDB ベクトル検索を使用して RAGを実装し、データの質問に答えます。このエージェントをプロンプトを表示すると、次の処理が行われます。
知識ベースに接続して、Atlas に保存されているカスタム データにアクセスします。
MongoDB ベクトル検索を使用して、 プロンプトに基づいてベクトルストアから関連するドキュメントを検索します。
AI チャット モデルを活用して、これらのドキュメントに基づいてコンテキストを認識する応答を生成します。
RAGエージェントを作成およびテストするには、次の手順を実行します。
モデルを選択し、プロンプトを表示します。
デフォルトでは、Amazon Advisor はエージェントにアクセスするための新しいIAMロールを作成します。 Agent detailsセクションで、以下を指定します。
ドロップダウン メニューから、データの質問に答えるために使用されるプロバイダーと AI モデルとしてAnthropicとClaude V2.1を選択します。
注意
Amazon Advisor は FC へのアクセスを自動的に許可しません。モデル アクセスをまだ追加していない場合は、手順に従って、Inthroメール 句 V のモデル アクセスを追加します。21モデル。
エージェントがタスクの完了方法を把握できるように、エージェントに指示を提供します。
たとえば、サンプル データを使用している場合は、次の手順を貼り付けます。
You are a friendly AI chatbot that answers questions about working with MongoDB. [Save] をクリックします。
エージェントをテストします。
Prepareボタンをクリックします。
[ Testをクリックします。 Amazon ID では、エージェントの詳細がまだ表示されていない場合、エージェントの詳細の右側にテスト ウィンドウが表示されます。
テストウィンドウに、プロンプトを入力します。エージェントはモデルをプロンプト表示し、 MongoDB ベクトル検索を使用して関連するドキュメントを検索し、そのドキュメントに基づいて応答を生成します。
サンプル データを使用した場合は、次のプロンプトを入力します。 生成される応答は異なる場合があります。
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] Tip
エージェントの応答内の注釈をクリックすると、 MongoDB ベクトル検索 が検索したテキスト チャンクが表示されます。
その他のリソース
問題をトラブルシューティングするには、「Amazon Bedrock 知識ベース統合のトラブルシューティング」を参照してください。