L'intelligence artificielle (IA) peut être définie comme la capacité des machines à penser rationnellement, à résoudre des problèmes et à prendre des décisions sans la supervision d'un esprit humain.
Avec l'avènement des technologies d'apprentissage automatique et d'apprentissage profond, les machines sont capables de « penser » et d'« apprendre » à partir des données qui leur sont fournies et d'effectuer des tâches qui, auparavant, ne pouvaient être réalisées que par des humains. Dans cet article, nous en apprendrons davantage sur l'intelligence artificielle, l'IA générative et la façon dont MongoDB révolutionne l'IA générative en simplifiant le traitement de l'IA, en permettant des recherches basées sur le contexte et en améliorant la précision des grands modèles de langage (LLM).
Table des matières
- L'intelligence artificielle (IA) expliquée
- En quoi l'IA est-elle similaire à l'intelligence humaine ?
- L'IA vs l'apprentissage automatique
- L'apprentissage profond
- Évolution de l'intelligence artificielle
- Types d'IA
- Modèles de fondation
- IA générative
- Grand modèle de langage (LLM)
- Recherche vectorielle
- MongoDB Atlas Vector Search
- Comment fonctionne la recherche Atlas Vector ?
- Principaux cas d'utilisation de l'IA
- Utilisation éthique de l'IA, gouvernance de l'IA et réglementation
- Outils et services liés à l'IA
- FAQ
L'intelligence artificielle (IA) expliquée
L'intelligence artificielle est un domaine de l'informatique qui permet aux machines de raisonner, de prendre des décisions intelligentes et d'analyser des données, à une échelle perçue comme dépassant la compréhension et les capacités humaines.
L'IA englobe des domaines tels que la science des données, les statistiques, les neurosciences et l'apprentissage automatique, qui comprend également l'apprentissage profond, sur lequel reposent nos algorithmes modernes.
Ces algorithmes sont la base de l'IA pour prendre des décisions semblables à celles de l'homme en assimilant les données à des modèles et en exécutant des tâches difficiles avec facilité et précision.
Parmi les exemples les plus courants de systèmes d'intelligence artificielle, on peut citer ChatGPT, les assistants virtuels comme Alexa et Siri, les voitures autonomes et les moteurs de recommandation.
En quoi l'IA est-elle similaire à l'intelligence humaine ?
Le cerveau humain est complexe. Nous pensons, agissons et prenons des décisions sur la base de nos expériences passées et de nos souvenirs, en déduisant des schémas basés sur l'environnement et les situations. Au fil du temps, ce que nous observons est ce que le cerveau perçoit comme étant vrai. Par exemple, si nous voyons régulièrement une rose rouge, notre cerveau considère qu'une rose est de couleur rouge et qu'elle a une certaine forme et une certaine taille. Si nous lisons ou entendons que les roses peuvent aussi être jaunes ou roses, sur la base de notre connaissance antérieure d'une rose rouge, nous imaginons qu'une rose jaune ou rose ressemble, d'une certaine manière, à une rose rouge.
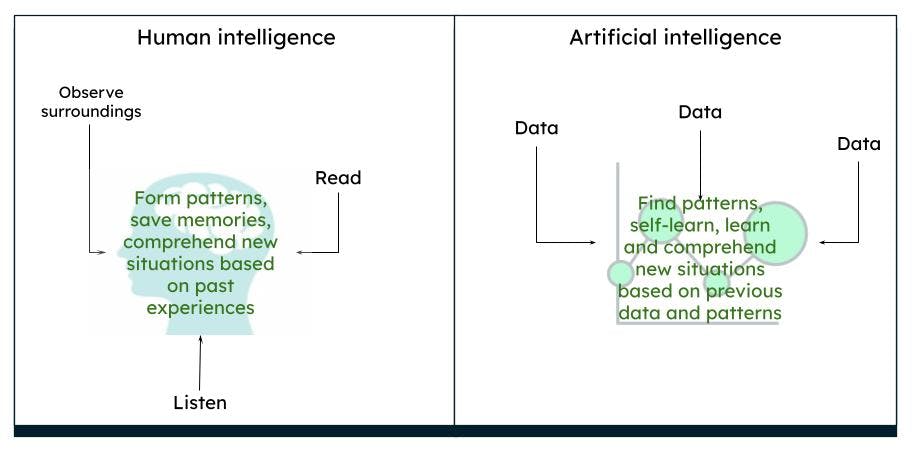 Representation de l'intelligence humaine par rapport à l'intelligence artificielle
Representation de l'intelligence humaine par rapport à l'intelligence artificielle
L'IA fonctionne de la même manière. Lorsqu'un ordinateur est alimenté avec suffisamment de données, les machines sont capables de dériver certains résultats, basés sur les modèles de données, grâce à des algorithmes. Par exemple, si vous fournissez des données sur les roses et les couleurs, la prochaine fois que l'ordinateur verra un objet similaire, il pourra l'identifier comme une rose d'une couleur particulière.
L'IA vs l'apprentissage automatique
L'IA est un terme plus large qui englobe les théories et les systèmes permettant de concevoir des machines qui effectuent des tâches intellectuelles. Apprentissage automatique est une branche de l'IA qui se concentre sur l'analyse des données, afin de trouver des modèles et de prendre des décisions grâce à divers algorithmes, sans qu'il soit nécessaire de recourir à une programmation explicite. Les techniques d'apprentissage automatique se composent de méthodes d'apprentissage supervisé, non supervisé et de renforcement.
L'apprentissage profond
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique qui s'apparente à l'intelligence humaine. Les modèles d'apprentissage profond consistent en des réseaux neuronaux profonds artificiels, c'est-à-dire des neurones (ou nœuds) interconnectés, et comportent de nombreux niveaux, ce qui leur permet de traiter des modèles de données plus complexes que les algorithmes d'apprentissage automatique. Les LLM et l'IA générative sont des sous-ensembles de l'apprentissage profond. Il existe de nombreux réseaux neuronaux artificiels qui peuvent être utilisés pour des tâches spécifiques.
Tous ces réseaux neuronaux sont basés sur un « perceptron », qui est le réseau neuronal le plus élémentaire utilisé pour la classification binaire. Le perceptron se compose d'une seule couche de neurones qui traite une couche d'entrée, applique des coefficients de poids et transmet le résultat à la couche de sortie.
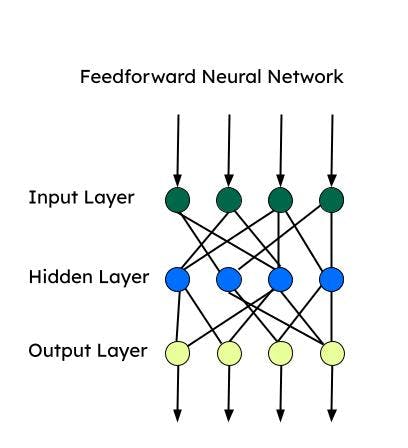
Réseau de neurones à action directe (FNN)
C'est l'un des premiers réseaux neuronaux artificiels développés et consiste en un groupe de perceptrons multiples dans chaque couche. Il est également connu sous le nom de perceptron multicouche (MLP). Il ne transmet l'information que dans un seul sens, à savoir le sens direct, et il n'y a pas de boucle. Ces réseaux neuronaux ont une entrée, une sortie et une couche cachée qui traite l’entrée. Les FNN sont utilisés pour l’apprentissage supervisé, lorsque les données ne sont pas dépendantes du temps ou séquentielles.
Réseaux neuronaux convolutifs (CNN)
Les CNN sont un type de FNN et sont utilisés pour des tâches complexes de classification d'images, de vision par ordinateur, d'analyse d'images et de traitement du langage naturel. Un CNN examine une parcelle d'image à la fois et procède avec un nombre réduit de paramètres à la fois pour apprendre/extraire les caractéristiques les plus importantes. L'extraction des caractéristiques se fait à l'aide de noyaux au cours d'une opération de convolution.
Réseaux neuronaux récurrents (RNN)
Les RNN conviennent mieux aux données séquentielles, pour lesquelles l'ordre d'entrée est crucial. Les informations séquentielles sont capturées par une boucle dans la couche d'entrée. Les RNN conviennent mieux aux données de séries temporelles et au traitement du langage naturel. Les mémoires à long terme (LSTM) sont des types de RNN qui disposent de cellules de mémoire pour stocker les dépendances des données séquentielles. Les LSTM sont très efficaces pour la reconnaissance vocale, l'analyse des sentiments et la traduction.
Auto-encodeur
Les auto-encodeurs se composent d'un encodeur et d'un décodeur. Les encodeurs compressent les dimensions des données dans un espace de moindre dimension (espace latent). Les décodeurs reconstruisent les données d'entrée en utilisant l'espace latent. Les auto-encodeurs peuvent être utilisés pour le débruitage, la compression et l'apprentissage des fonctionnalités.
Réseaux autoattentifs (SAN)
L'architecture codeur-décodeur peut mémoriser des séquences plus courtes. Cependant, elle peut oublier certaines informations (en particulier celles qui sont reçues en premier) dans une longue séquence. Avec un mécanisme d'attention, le décodeur peut s'intéresser à l'ensemble de la séquence et utiliser le contexte de l'ensemble de la séquence pour générer la sortie. Le réseau autoattentifs permet de traiter tout le texte d'entrée en même temps et de créer des relations entre tous les mots de la séquence entière. Grâce à cette fonctionnalité, il fonctionne plus rapidement qu'un RNN ou un CNN pour les dépendances à longue portée.
Évolution de l'intelligence artificielle
Bien que les premières tentatives d'imagination aient commencé dès 750 av. J.-C. par le biais de livres et d'idées basés sur la science-fiction et les machines pensantes, les prémices des réseaux neuronaux ont été jetées en 1947 par Walter Pitts et Warren McCulloch, qui ont créé un modèle de calcul pour l'architecture des réseaux neuronaux.
En 1950, Alan Turing a introduit le test de Turing pour définir l'intelligence des machines.
Le terme « intelligence artificielle » a été inventé en 1956, lorsque John McCarthy a organisé un atelier sur l'IA et a défini le terme comme la science et l'ingénierie permettant de rendre les machines intelligentes. Au début des années 1960, Frank Rosenblatt a mis au point le premier ordinateur, le Perceptron, capable d'apprendre en faisant des essais et des erreurs. Plus tard, en 1963, John McCarthy a fondé le laboratoire d'IA.
L'avancée majeure suivante dans le domaine de l'IA est due aux systèmes experts, des systèmes informatiques basés sur la connaissance qui peuvent émuler les capacités de prise de décision d'un humain. Ces systèmes étaient des formes d'IA très réussies et ont été utilisés dans les secteurs de la santé, des simulateurs de combat et d'entraînement, et des aides à la gestion des missions.
Dans les années 1980, l'intelligence artificielle est devenue une industrie et des milliards de dollars ont été investis dans les systèmes experts, les systèmes de vision et la robotique.
En 1997, le développement de Deep Blue, l'ordinateur capable de jouer aux échecs d'IBM qui a battu le champion du monde d'échecs de l'époque, a suscité un regain d'intérêt pour l'intelligence artificielle, et des développements rapides ont été observés dans ce domaine.
Vers 2010, des chercheurs travaillant sur la traduction en langue naturelle ont constaté que, comparés aux modèles basés sur des règles, les modèles alimentés par d'énormes quantités de données textuelles diverses généraient de bien meilleurs résultats.
L'année 2011 a vu l'arrivée d'assistants personnels tels que Cortana, Siri et Alexa, capables de répondre à des questions par le biais du traitement du langage naturel et d'exécuter des tâches.
En 2014, les modèles de langage ont commencé à tenir compte du contexte dans lequel un mot apparaissait. D'autres travaux ont abouti à des modèles de langage généraux qui fournissaient des modèles de base ou de fondation qui pouvaient être développés en aval pour un cas d'utilisation ou un domaine spécifique.
Ces modèles de fondation nous ont menés vers l'IA générative et les grands modèles de langage (LLM) (LLM) tels que ChatGPT.
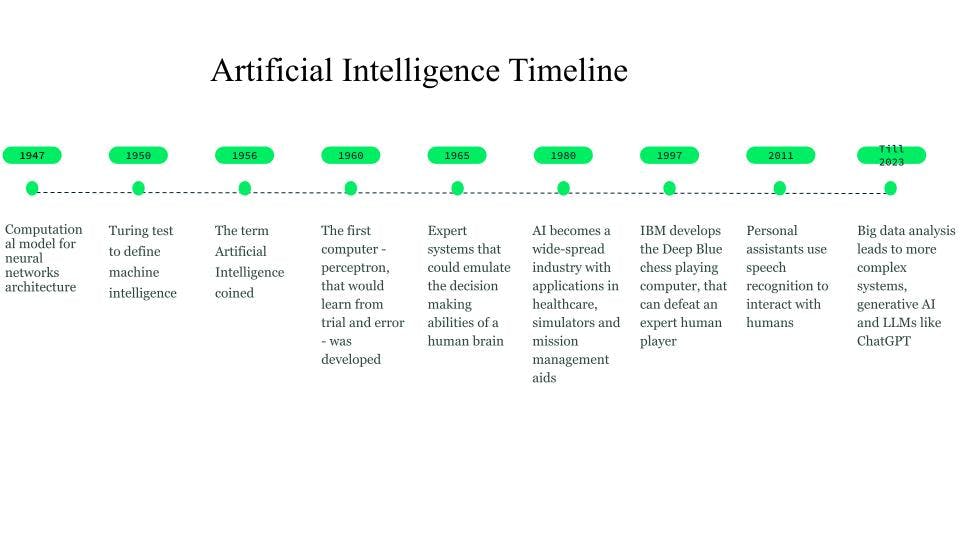 Évolution et chronologie de l'IA
Évolution et chronologie de l'IA
Types d'IA
Une classification générale de l'intelligence artificielle, basée sur ses capacités, est l'IA étroite (ou faible) et l'IA forte. Grâce à la recherche et aux avancées dans le domaine de l'apprentissage automatique, de l'apprentissage profond et de l'IA, nous passons d'une IA faible à une IA forte.
L'IA étroite
Les systèmes d'IA faible ou étroite, ou d'intelligence artificielle étroite (ANI), sont formés pour effectuer des tâches spécifiques et ont des capacités limitées en fonction des données sur lesquelles ils ont été entraînés. Ils sont également connus sous le nom de systèmes d'IA traditionnels, dans lesquels le système peut réagir de manière intelligente sur la base d'un certain ensemble d'entrées et de règles. Cependant, il ne peut rien créer de nouveau.
Les systèmes d'IA traditionnels ou faibles sont classés en deux catégories : les machines réactives et les systèmes à mémoire limitée.
Les machines réactives
Les plus anciennes formes d'intelligence artificielle étaient les machines réactives, qui n'avaient pas de mémoire. Cependant, elles peuvent imiter la capacité d'un être humain à répondre à différents stimuli. Elles ne peuvent pas tirer de leçons de leur expérience (pas de mémoire) et fondent leur réponse sur une combinaison limitée de données. La machine Deep Blue d'IBM est une machine réactive.
L'IA à mémoire limitée
Les systèmes à mémoire limitée ont une mémoire et peuvent apprendre et prendre des décisions sur la base des données d'entrée fournies. La plupart des IA que nous rencontrons, qu'il s'agisse des voitures autonomes, des chatbots, des assistants personnels comme Alexa ou des systèmes de recommandation comme celui de Netflix, sont des exemples d'IA à mémoire limitée.
L'IA forte
Avec l'innovation de ChatGPT et d'autres modèles d'IA générative similaires, nous entrons lentement dans la phase d'IA forte. L'IA générative est une sorte d'IA de nouvelle génération, qui peut créer quelque chose de nouveau sur la base des données fournies par l'utilisateur. ChatGPT est un exemple d'IA générative basée sur le grand modèle de langage (LLM). Il reste encore beaucoup à faire dans le domaine de l'IA forte, qui peut être catégorisée comme suit :
Théorie de l'esprit (ToM)
La ToM est une compétence cognitive qui permet de comprendre les différents états mentaux, tels que les croyances, les pensées et les sentiments d'autrui, afin d'expliquer leurs comportements et leurs actions. Les chercheurs travaillent sur l'application de la ToM à l'IA dans le but de permettre aux systèmes d'IA de comprendre les émotions et l'état d'esprit humains. ChatGPT, le nouveau système d'IA capable d'interagir avec les humains en langage naturel et de produire de nouveaux contenus, a fait preuve d'une certaine forme de théorie de l'esprit au cours des tests. Toutefois, il n'est pas encore en mesure de comprendre les désirs, les croyances ou les émotions. Les réponses de ChatGPT sont basées sur des données et des modèles communs.
L'intelligence artificielle générale (AGI)
L'intelligence artificielle générale est la prochaine étape du développement de l'IA, où un système ou un agent d'IA se comportera exactement comme un humain, y compris en développant de manière indépendante de multiples compétences et fonctionnalités, en établissant des connexions et en généralisant, avec peu ou pas d'entraînement.
Conscience artificielle
La prochaine étape est la singularité de l'IA, quand les machines seront conscientes d'elles-mêmes. Elles auront leurs propres désirs, croyances et émotions, en plus de comprendre les émotions, désirs et croyances des humains. Les agents doués de conscience peuvent être utilisés dans les domaines de la santé et de la robotique, et se révèlent plus puissants et plus précis dans l'accomplissement des tâches que les humains.
Superintelligence artificielle (ASI)
L'IA douée de conscience peut conduire à l'ASI, où les agents d'IA peuvent devenir extrêmement intelligents et surpasser les humains en termes de valeurs et de motivations. Les IA douées de conscience et les ASI pourraient soulever des problèmes d'emploi et d'éthique, pour lesquels les chercheurs et les gouvernements doivent être vigilants et élaborer des règles et des directives. Toutefois, il s'agit là d'objectifs très ambitieux dont la réalisation pourrait prendre des dizaines d'années.
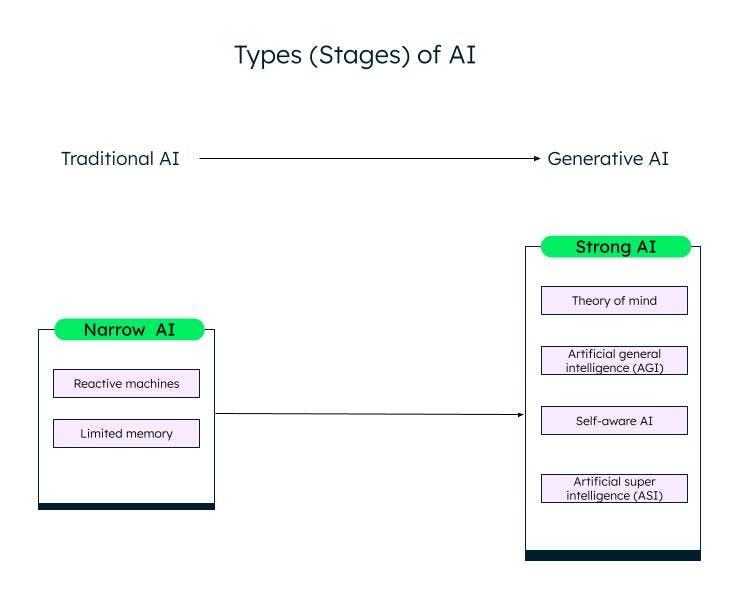 Différents stades (types) d'IA
Différents stades (types) d'IA
Modèles de fondation
Les modèles de fondation sont des réseaux neuronaux profonds artificiels généralisés formés sur d'énormes quantités de données non structurées. Ils sont conçus pour servir de modèles à usage général. Nous pouvons concevoir des modèles plus spécifiques pour les tâches d'IA et d'apprentissage automatique en personnalisant ces modèles de base (fondation) pré-entraînés.
Par exemple, un modèle de fondation tel que le grand modèle de langage (LLM) entraîné sur des données textuelles peut être utilisé pour une variété de tâches, telles que la recherche d'informations et les questions-réponses. Le transformeur génératif pré-entraîné ou GPT (sur lequel est basé le célèbre ChatGPT) et le BERT (représentations d'encodeurs bidirectionnels à partir de transformeurs) sont des exemples de modèles de fondation LLM. ResNet (réseau résiduel) est un type de modèle de fondation populaire dans le domaine de la vision par ordinateur pour la classification d'images et les tâches de vision par ordinateur. Ils peuvent s'auto-superviser et se perfectionner grâce à des invites et au peaufinage.
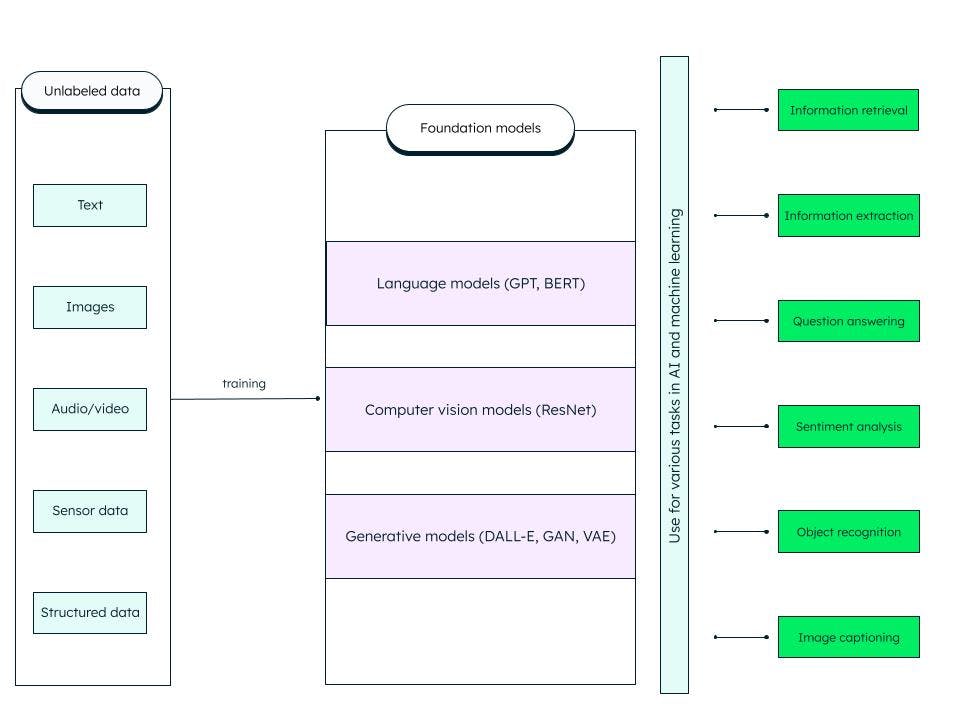
Qu'inclut les modèle de fondation ?
AI générative
Les technologies d'IA peuvent produire de nouveaux contenus tels que des images, des vidéos, des audios, des textes et à peu près n'importe quoi d'autre, une IA capable de générer du contenu s'appelle l'IA générative !
L'IA générative repose sur des modèles de base capables d'effectuer des tâches telles que la classification, la rédaction de phrases, la génération d'images ou de voix et de données synthétiques (générées artificiellement). Les modèles de fondation sont affinés pour s'adapter à la tâche générative spécifique à accomplir.
Le succès d'un modèle d'IA générative dépend de la qualité et de la diversité des données, ainsi que de la vitesse de génération.
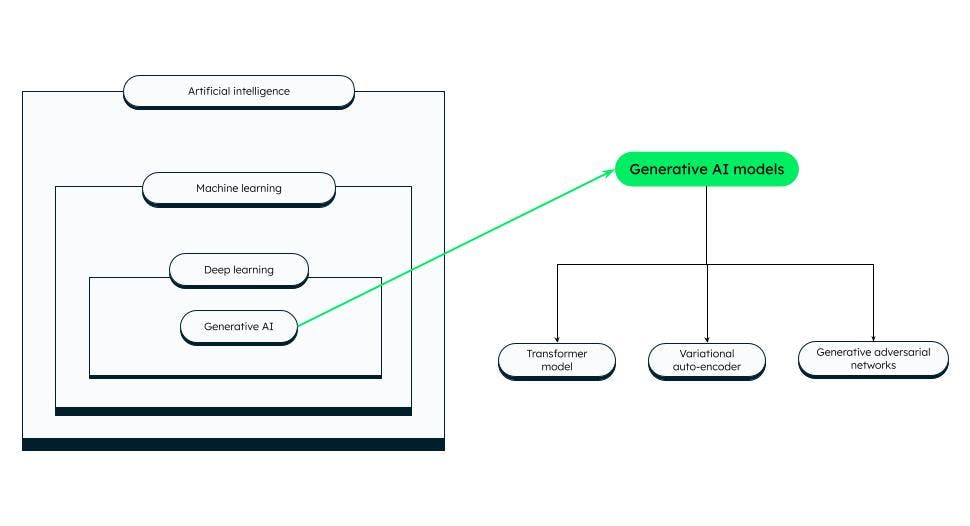 Modèles d'IA générative
Modèles d'IA générative
Il existe différentes catégories de modèles d'IA générative, dont les principales sont les suivantes :
Modèle transformeur
Les architectures basées sur les transformeurs se sont avérées très précises dans l'identification des relations contextuelles entre les mots (données). Elles sont utilisées pour la génération de textes, la traduction automatique et la modélisation linguistique. Les LLM, comme GPT (utilisé dans ChatGPT), sont un exemple d'architecture basée sur des transformeurs.
L'attention est de rigueur !
Le modèle transformeur fonctionne sur la base d'un mécanisme auto-attentif, où l'importance de chaque élément d'une séquence d'entrée est évaluée au cours du traitement du texte, ce qui permet de collecter efficacement les informations contextuelles.
Par exemple, si vous souhaitez traduire le texte français « J'aime disserter sur l'intelligence artificielle » en espagnol, le modèle transformeur transmettra cette séquence de mots (tokens) à l'encodeur (réseau neuronal). Les mots en entrée sont tous convertis parallèlement en une représentation vectorielle numérique (plongement lexical), composée des vecteurs de la requête (la transformation nécessaire), de la clé (entrée) et de la valeur (sortie).
Par exemple, pour le mot « aime » dans notre phrase, nous aurions les vecteurs q_aime, k_aime, et v_aime.Une matrice est créée à partir du score de similarité de chaque mot par rapport à un autre. Par exemple, la similarité du mot “aime“ avec tous les autres mots de la phrase sera générée, un score plus élevé indique une plus grande similitude.
L'étape suivante consiste à calculer les coefficients de poids qui déterminent l'importance à accorder à chaque mot de la phrase par rapport au mot-clé principal (« aime », dans notre cas).
Ensuite, nous ajoutons les encodages positionnels aux représentations vectorielles. Les encodages positionnels (similarité + encodage positionnel) aident le décodeur (un autre réseau neuronal) à décider de l'ordre dans lequel les tokens de sortie (mots) doivent être placés.
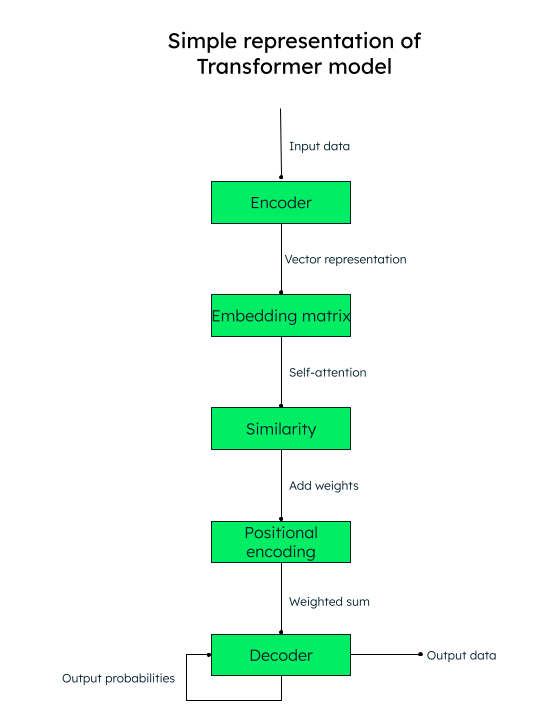
Représentation du modèle transformeur
Auto-encodeur variationnel (VAE)
Les VAE sont très populaires pour la génération d'images, la compression de données et le débruitage d'images. Dans un VAE, le réseau neuronal codeur prend les points de données d'entrée et les met en correspondance avec une représentation de l'espace latent. Un espace latent est la représentation des données dans une dimension inférieure en extrayant les caractéristiques les plus importantes des données et en écartant les autres. Le réseau neuronal décodeur reconstruit les données de sortie sur la base de la représentation latente.
Les réseaux antagonistes génératifs (GAN)
Les GAN sont largement utilisés pour créer des images réalistes, des œuvres d'art, de fausses vidéos, des traductions d'image à image et des images en super résolution. Un GAN se compose d'un générateur (réseau neuronal) qui prend un bruit aléatoire ou du matériel en entrée et crée des échantillons de données synthétiques (comme une image). Les échantillons de données synthétiques sont ensuite transmis à un autre réseau neuronal, le discriminateur, qui utilise la classification binaire pour déterminer si les échantillons sont faux ou réels. Grâce à l'entraînement antagoniste, le générateur et le discriminateur sont entraînés simultanément jusqu'à ce qu'un équilibre de Nash soit atteint, le générateur devenant capable de produire des données réalistes de haute qualité (comme des images) et le discriminateur de les classer avec précision comme réelles ou non.
Les grands modèles de langage (LLM)
Les LLM sont un modèle de base qui s'entraîne sur d'énormes ensembles de données et fournit une expérience à la fois précise et attrayante pour les utilisateurs. Pour pouvoir développer de tels modèles, il est nécessaire de collecter d'énormes quantités de données provenant de sources multiples, de les stocker correctement, de les traiter et de les extraire en fonction de leur pertinence, lorsque cela est nécessaire.
Les LLM peuvent être utilisés pour la résolution de problèmes généraux, comme la réponse à des questions, la génération de textes, la classification et le résumé de textes, et le peaufinage en utilisant des réglages et des invites pour s'entraîner sur un ensemble minimal de données afin de résoudre des problèmes spécifiques.
Comment fonctionne un LLM ?
Les modèles de fondation apprennent à partir de modèles de données et produisent un résultat modulable et généralisable, qui peut ensuite être appliqué à différents cas spécifiques. L'un de ces exemples est le LLM, qui est appliqué aux entrées textuelles.
Les LLM regroupent des données, une architecture et un entraînement. Les données sont généralement des pétaoctets de livres volumineux, de conversations et de contenu textuel. L'architecture est un réseau neuronal profond et, dans le cas de GPT, il s'agit du [transformeur] (#transformer-model). Au cours de l'entraînement, le modèle apprend à prédire le mot suivant d'une phrase donnée.
Cependant, le LLM pose trois problèmes :
Si des informations ont été développées ou modifiées après l'entraînement complet du modèle, ce dernier n'en aura pas connaissance et risque de générer des résultats obsolètes. Par exemple, si vous demandez au modèle « Donnez-moi une liste de bons films comiques de ces six derniers mois », le modèle n'en sera pas capable s'il n'a pas été entraîné six mois auparavant !
Le modèle peut contenir des informations incorrectes dans sa représentation interne.
Le modèle ne peut pas accéder à vos données privées et pourrait fournir des informations biaisées ou incomplètes en raison de ses connaissances limitées.
Génération augmentée de récupération (RAG)
Le cadre RAG IA vise à résoudre les problèmes susmentionnés et à améliorer la qualité des réponses LLM en fournissant au modèle des informations véridiques sur une base de connaissances externe qui complètent les informations présentées en interne dans le LLM. Cela réduit les risques que le modèle identifie incorrectement un modèle ou un objet inexistant (hallucinations), ainsi que les informations incorrectes, trompeuses et obsolètes.
L'architecture de récupération utilise une base de données vectorielles et renforce les capacités du LLM grâce à la recherche vectorielle.
MongoDB Atlas, la plateforme de données unifiée pour les développeurs, propose une recherche vectorielle au sein de la plateforme, que vous pouvez mettre en place en quelques étapes simples, afin d'améliorer les résultats de votre LLM et de produire des résultats plus précis.
Recherche vectorielle
Dans la section précédente, nous avons appris que le modèle transformeur et les vecteurs sont des représentations numériques de données textuelles. Par exemple, la représentation vectorielle de notre phrase précédente, « J'aime disserter sur l'intelligence artificielle », pourrait être similaire à : « J'aime à » = [0,33 ; 0,45 ; 0,72 ; -0,23.....]
La représentation vectorielle ci-dessus inclut la relation entre chaque mot, comme la relation entre le mot « artificiel » et le mot « intelligence » ou le mot « disserter », ou encore le contexte du mot « aime » dans cette phrase.
Ces vecteurs sont générés (comme nous l'avons vu dans le modèle tranformeur) en envoyant les données d'entrée à travers un réseau neuronal profond (encodeur).
En réalité, les représentations vectorielles peuvent avoir un nombre quelconque de dimensions. Plus les données ont de paramètres, plus elles ont de dimensions. Pour donner un sens à ces chiffres et comprendre ce qui se passe après la génération de ces vecteurs, traçons un graphique à deux dimensions pour faciliter la compréhension.
Tous les vecteurs sont tracés selon leur représentation numérique. Notez que les plongements lexicaux (vecteurs) qui ont une signification similaire seront représentés à proximité les uns des autres, formant ainsi un cluster.
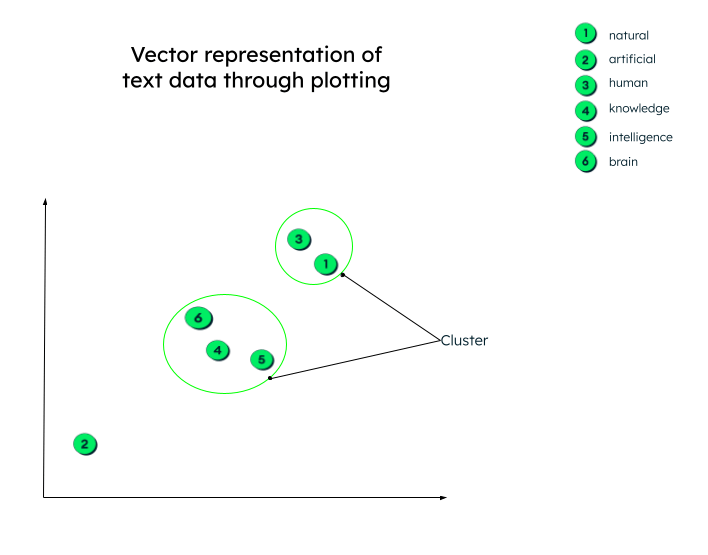 Représentation graphique des vecteurs
Représentation graphique des vecteurs
Il peut y avoir de nombreux contextes dans lesquels les données peuvent être regroupées. La relation dépend de la manière dont l'encodeur incorpore les données sources et de la manière dont la distance entre les vecteurs est calculée. Dans l'exemple ci-dessous, deux types de relations peuvent être établis :
- Le chat et le chien sont tous deux des animaux domestiques, tandis que le tigre et le loup sont des animaux sauvages.
- Le chat et le tigre appartiennent à la même famille, tandis que le chien et le loup appartiennent à la même famille d'animaux.
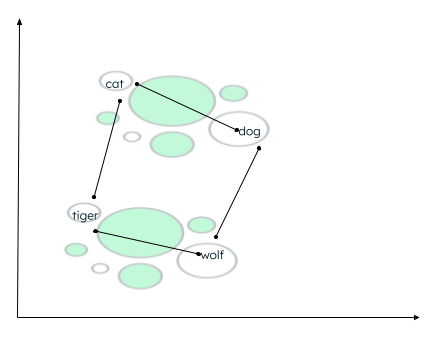
Calcul de la distance entre mots similaires
Une fonction de similarité détermine quels mots sont les plus proches et qualifie les mots proches de voisins. Ce regroupement est effectué en utilisant l'algorithme des plus proches voisins, où la valeur de k représente le nombre de voisins à identifier. Pour trouver les similitudes, la recherche vectorielle s'appuie sur de nombreuses méthodes, comme la recherche de/du :
- La distance euclidienne entre les extrémités des deux vecteurs.
- Cosinus (angle) entre les deux vecteurs.
- Produit de points (scalaire) des vecteurs.
MongoDB Atlas fournit les fonctionnalités de recherche vectorielle au sein de la plateforme Atlas elle-même, par le biais de cadres d'intelligence artificielle, et prend en charge toutes les fonctions de similarité susmentionnées.
MongoDB Atlas Vector Search
MongoDB a toujours pris en charge la recherche vectorielle en deux dimensions. Cependant, la nouvelle recherche vectorielle offre des capacités puissantes grâce à l'intégration et permet des dimensions plus élevées. Les applications peuvent saisir les données ainsi que l'intégration des vecteurs dans la base de données. Les vecteurs de données sont générés à l'aide d'un modèle d'encodage. La recherche dans l'Atlas utilise l'algorithme du plus proche voisin (ANN) via le graphique Hierarchical Navigable Small World (HNSW). L'algorithme ANN est une variante de l'algorithme du plus proche voisin k, mais avec une vitesse de récupération plus élevée.
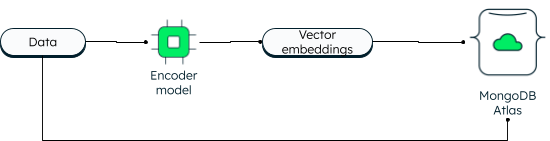
Comment les vecteurs sont-ils stockés dans MongoDB Atlas ?
Lors de la lecture, la requête est encodée et soumise à l'étape d'agrégation $recherche avec le vecteur cible. Si vous voulez en savoir plus, suivez le tutoriel sur la construction d'applications d'IA générative à l'aide de MongoDB.
L'avantage d'avoir des vecteurs avec les données opérationnelles est que vous pouvez accéder à toutes les informations au sein d'une seule plateforme, même à vos données privées, qui ne seraient pas accessibles autrement.
La recherche vectorielle d'Atlas simplifie l'architecture de votre application. Comme Atlas est entièrement géré, tout ce qui concerne la synchronisation des données, la sécurité et la confidentialité est pris en charge par la plateforme MongoDB Atlas. Les développeurs peuvent travailler avec la base de données et la recherche vectorielle en utilisant la MongoDB Query API unifiée. Vous pouvez déployer Atlas dans plus de 125 régions à travers les trois principaux fournisseurs cloud. Atlas vous assure une disponibilité continue grâce à une automatisation avancée qui garantit des performances élevées quelle que soit l'échelle de l'application.
Les principaux cas d'utilisation de la recherche vectorielle d'Atlas sont les suivants :
- Recherche sémantique.
- Systèmes de questions-réponses.
- Extraction de fonctionnalités.
- Évaluation des recommandations et de la pertinence.
- Génération de synonymes.
- Recherche d'images.
Comment fonctionne la recherche Atlas Vector ?
L'application client envoie les données brutes. Le modèle d'intégration vectorielle crée des vecteurs pour chaque texte de la requête initiale (données brutes). Des cadres tels que Llamaindex et LangChain s'intègrent bien à MongoDB Atlas pour créer des enchâssements et envoyer des données à MongoDB afin de prendre en compte le contexte. La requête contextuelle, connue sous le nom d'invite, est ensuite envoyée à un LLM, qui génère une réponse codée, à traiter par le modèle d'intégration vectorielle (décodeur) et à envoyer au client après décodage.
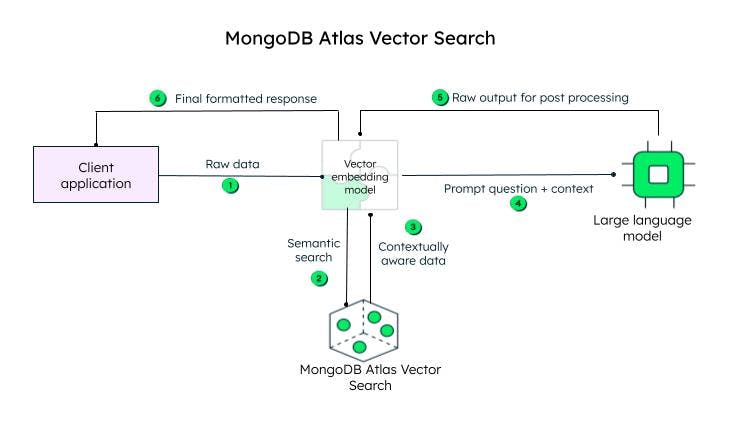 Étapes de la recherche vectorielle dans l'Atlas MongoDB.
Étapes de la recherche vectorielle dans l'Atlas MongoDB.
Les enchâssements vectoriels peuvent être stockés dans le document de la base de données MongoDB sous la forme d'un tableau de valeurs flottantes, en même temps que le contenu, dans le champ content_embeddings.
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... other fields......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]Si le nombre de dimensions dans les données d'entrée est plus élevé, le nombre de points flottants sera plus élevé.
Ensuite, vous définissez la définition de l'index en l'ajoutant au générateur de définitions :
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}La définition de l'index comprend le modèle qui permettra de trouver les groupes de similarité, les dimensions et la fonction de similarité (parmi les trois méthodes prises en charge par MongoDB) qui sera utilisée par le modèle.
C'est à peu près tout ! Deux étapes suffisent et c'est terminé.
Pour pouvoir effectuer une recherche, vous pouvez utiliser l'opérateur d'agrégation $recherche en spécifiant l'opérateur knnBeta et en indiquant les enchâssements vectoriels de la requête dans le champ vecteur. Vous devez également spécifier le chemin du contenu des enchâssements qui doit être pris en compte pour la recherche vectorielle. MongoDB fournit également des filtres supplémentaires pour restreindre la recherche, et le nombre de voisins les plus proches que l'algorithme du plus proche voisin doit renvoyer.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Étant donné que les enchâssements vectoriels et les données résident dans la même plateforme, vous pouvez accéder à votre charge de travail opérationnelle et à vos vecteurs à l'aide d'une seule MongoDB Quety API unifiée. Pour apprendre à utiliser la fonctionnalité étape par étape, reportez-vous à notre tutoriel sur le développement d'applications d'IA générative à l'aide de la recherche vectorielle.
Principaux cas d'utilisation de l'IA
L'IA est appliquée avec succès dans divers domaines, notamment la vente au détail, les soins de santé et la fabrication. Voici quelques cas d'utilisation courants de l'IA :
le traitement du langage naturel (NLP) : l'IA est activement utilisée dans l'analyse des sentiments, les assistants virtuels, les chatbots, la reconnaissance vocale et la traduction de textes. Comme nous l'avons vu précédemment, en utilisant la puissance du LLM et de la recherche vectorielle, les systèmes d'IA peuvent générer des résultats en langage humain.
Vision par ordinateur : grâce aux réseaux neuronaux modernes, les systèmes d'IA sont capables d'effectuer avec précision la classification d'images, la reconnaissance de visages et d'objets, et la génération d'images.
Systèmes de recommandation et filtrage de contenu : les systèmes d'IA sont capables de recommander des contenus aux utilisateurs en utilisant des modèles d'apprentissage profond et d'apprentissage automatique sans aucune intervention humaine.
Santé : la technologie de l'intelligence artificielle a porté le secteur de la santé à un niveau supérieur en aidant les médecins dans le diagnostic précoce des maladies, la recherche médicale et la découverte de médicaments, et en stockant en toute sécurité les dossiers médicaux électroniques des patients.
Voitures autonomes : les voitures autonomes sont alimentées par des algorithmes d'IA, des données de capteurs et la vision par ordinateur.
Robotique : les robots industriels augmentent la productivité en exécutant des tâches complexes avec précision. De même, les robots utilitaires sont capables d'accomplir efficacement leurs tâches dans les domaines de la santé et de l'hôtellerie.
Utilisation éthique de l'IA, gouvernance de l'IA et réglementation
Avec les développements rapides dans le domaine de l'IA, il est important d'établir des règles et des réglementations et d'aborder les considérations éthiques afin que les systèmes d'IA soient utilisés de manière équitable, transparente et à bon escient. L'éthique de l'IA se concentre sur les implications morales et éthiques des outils et des technologies de l'IA, à savoir l'équité, la protection de la vie privée, la transparence et la responsabilité.
Les cadres, la structure et les règles de conformité sont établis par le gouvernement pour garantir une utilisation responsable de l'IA.
Le gouvernement crée également des réglementations en matière d'IA, à savoir des cadres juridiques, afin de garantir la sécurité des données, la protection des consommateurs et le respect des normes de sécurité.
Outils et services liés à l'IA
Les données sont au cœur de toutes les opérations d'IA, et MongoDB est une plateforme sur laquelle vous pouvez compter pour développer de puissantes applications d'IA. En tant que base de données avec un schéma modulable, MongoDB fournit une solution de stockage centralisée, avec des capacités intégrées de gestion des données, de traitement avancé des données, d'analyse en temps réel, d'évolutivité, et bien plus encore. Parmi les autres outils et services les plus populaires, citons :
ChatGPT : ChatGPT fait presque partie de la vie quotidienne : poser des questions simples, planifier des vacances, coder, écrire des poèmes, résumer des textes, etc.
Dall-E 2 : Dall-E 2 est un projet OpenAI, tout comme ChatGPT, qui génère des images de synthèse telles que des images, des peintures et des dessins à partir d'invites textuelles.
Stable Diffusion 2 : il s'agit d'un outil d'IA texte-image pour les applications d'IA générative. Contrairement aux outils OpenAI, qui sont accessibles via des portails de navigation, Stable Diffusion 2 peut être téléchargé et installé, et les utilisateurs peuvent accéder publiquement au code source et aux algorithmes.
FAQ
Qu'est-ce que l'intelligence artificielle (IA) ?
La capacité des machines à penser, à apprendre et à prendre des décisions, comme un être humain, lorsqu'elles sont confrontées à différents scénarios, est connue sous le nom d'intelligence artificielle.
L'IA, comment ça marche ?
L'intelligence artificielle (IA) comprend l'apprentissage automatique (machine learning) et l'apprentissage profond (deep learning), tous deux constitués de plusieurs algorithmes pour répondre aux différents cas d'utilisation. Ces algorithmes travaillent sur d'énormes quantités de données collectées à partir de diverses sources, triées, transformées et prétraitées pour alimenter les algorithmes. Les algorithmes utilisent les données pour s'entraîner, obtenir un feedback et se perfectionner, jusqu'à ce qu'à obtenir le résultat escompté.
Pourquoi l'intelligence artificielle est-elle un enjeu majeur ?
L'IA est essentielle car elle peut permettre l'automatisation de tâches banales et répétitives, améliorer l'efficacité, réduire le nombre d'erreurs humaines, fournir des analyses prédictives pour une prise de décision plus rapide et plus précise, fournir des recommandations personnalisées aux utilisateurs, aider au diagnostic des maladies, accélérer la recherche en médecine et en science, et promouvoir l'innovation.
Quand l'IA a-t-elle été inventée ?
Quels sont les types d'IA ?
Un exemple d'intelligence artificielle ?
L'exemple le plus récent et le plus populaire d'IA est ChatGPT, qui peut fournir une réponse semblable à celle d'un être humain à des questions posées par ce dernier. Il peut également se souvenir du contexte de la conversation. ChatGPT est entraîné sur un grand modèle linguistique et enrichi par la suite. MongoDB Atlas fournit une excellente plateforme pour développer de puissantes applications d'IA générative via n'importe quel grand fournisseur cloud.