L'intelligenza artificiale (AI) può essere definita come la capacità delle macchine di pensare razionalmente, risolvere problemi e prendere decisioni senza la supervisione di una mente umana.
Con l'avvento delle tecnologie di machine learning e deep learning, le macchine sono in grado di “pensare“ e “imparare“ in base ai dati che vengono loro forniti e di svolgere compiti che in precedenza potevano essere svolti solo dagli esseri umani. In questo articolo approfondiremo i temi dell'intelligenza artificiale, dell'AI generativa e di come MongoDB stia cambiando il volto dell'AI generativa semplificando l'elaborazione dell'AI, consentendo ricerche basate sul contesto e migliorando l'accuratezza dei modelli linguistici di grandi dimensioni (LLM).
Tabella dei contenuti
- L'intelligenza artificiale (AI) spiegata
- Come l'IA è simile all'intelligenza umana
- AI vs apprendimento automatico
- Deep learning
- Storia dell'intelligenza artificiale
- Tipi di IA
- Modelli di fondazione
- IA generativa
- Modello linguistico di grandi dimensioni (LLM)
- Ricerca vettoriale
- Ricerca vettoriale Atlas di MongoDB
- Come funziona la ricerca vettoriale Atlas?
- Casi d'uso importanti dell'IA
- Uso etico dell'IA, governance dell'IA e regolamenti
- Strumenti e servizi di IA
- FAQs
Intelligenza artificiale (AI) spiegata
L'intelligenza artificiale è un campo dell'informatica che permette alle macchine di ragionare, prendere decisioni intelligenti e analizzare i dati su una scala che si ritiene superi la comprensione e le capacità umane.
L'intelligenza artificiale comprende campi come la scienza dei dati, la statistica, le neuroscienze e l'apprendimento automatico, che comprende anche il deep learning, su cui si basano i nostri moderni algoritmi.
Questi algoritmi sono la base dell'intelligenza artificiale per prendere decisioni simili a quelle umane, comprendendo i dati in schemi e svolgendo compiti difficili con facilità e precisione.
Alcuni esempi popolari di sistemi di intelligenza artificiale sono ChatGPT, assistenti virtuali come Alexa e Siri, auto a guida autonoma e motori di raccomandazione.
Perché l'Intelligenza Artificiale è simile all'intelligenza umana
Il cervello umano funziona in modo complesso. Pensiamo, agiamo e prendiamo decisioni sulla base delle nostre esperienze e dei nostri ricordi passati, ricavando modelli basati sull'ambiente e sulle situazioni. In un certo periodo di tempo, ciò che osserviamo è ciò che il cervello percepisce come vero. Ad esempio, se vediamo costantemente una rosa rossa, il nostro cervello elabora che una rosa è di colore rosso e ha una certa forma e dimensione. Se leggiamo o sentiamo dire che le rose possono essere anche gialle o rosa, in base alla nostra precedente conoscenza di una rosa rossa, immaginiamo che una rosa gialla o rosa, in un certo senso, assomigli molto a una rosa rossa.
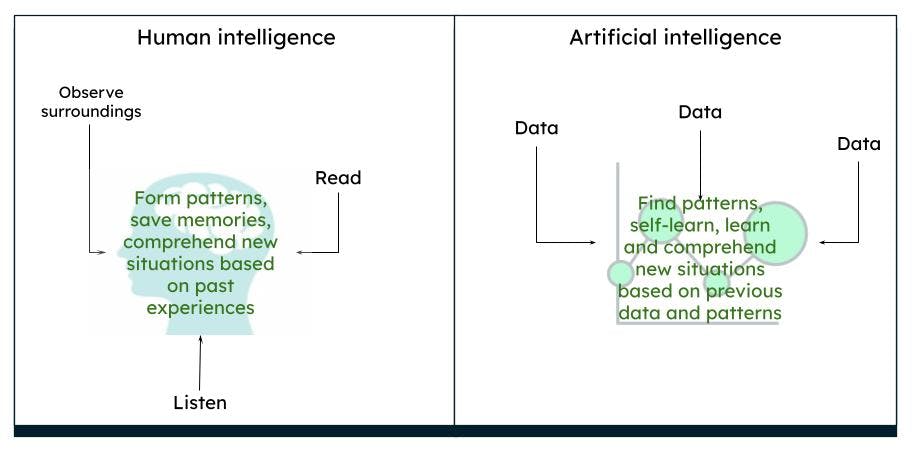 Rappresentazione dell'intelligenza umana e dell'intelligenza artificiale
Rappresentazione dell'intelligenza umana e dell'intelligenza artificiale
L'intelligenza artificiale funziona allo stesso modo. Quando un computer viene alimentato con un numero sufficiente di dati, le macchine sono in grado di ricavare determinati risultati, basati su modelli di dati, attraverso algoritmi. Ad esempio, se si forniscono dati su rose e colori, la volta successiva che il computer vedrà un oggetto simile, potrà identificarlo come una rosa di un determinato colore.
IA e machine learning a confronto
L'IA è un termine più ampio che consiste in teorie e sistemi per la creazione di macchine che eseguono compiti in cui è richiesta l'intelligenza. L'apprendimento automatico è una branca dell'IA che si concentra sull'analisi dei dati, per trovare modelli e prendere decisioni utilizzando vari algoritmi, senza la necessità di una programmazione esplicita. Le tecniche di apprendimento automatico consistono in metodi di apprendimento supervisionati, non supervisionati e di rinforzo.
Deep learning
Il deep learning è un sottoinsieme dell'apprendimento automatico che assomiglia all'intelligenza umana. I modelli di deep learning sono costituiti da reti neurali artificiali profonde - cioè neuroni (o nodi) interconnessi - e hanno molti strati, il che consente loro di elaborare modelli di dati più complessi rispetto agli algoritmi di apprendimento automatico. Le LLM e l'AI generativa sono sottoinsiemi del deep learning. Esistono molte reti neurali artificiali che possono essere utilizzate per compiti specifici.
Tutte queste reti neurali si basano su un “percettrone“, che è la rete neurale più elementare utilizzata per la classificazione binaria. Il percettrone consiste in un singolo strato di neuroni che prende uno strato di input, applica dei pesi e lo invia allo strato di output.
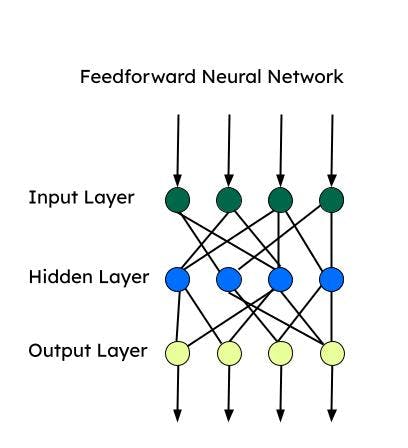
Rete neurale Feedforward (FNN)
La Feedforward è una delle prime reti neurali artificiali sviluppate e consiste in un gruppo di perceptron multipli in ogni strato. È nota anche come perceptron multistrato (MLP). Le informazioni vengono trasmesse in una sola direzione, cioè in avanti, e non ci sono loop. Le reti neurali feedforward hanno un ingresso, un'uscita e uno strato nascosto che elabora l'ingresso. Le FNN sono utilizzate per l'apprendimento supervisionato, quando i dati non dipendono dal tempo o sono sequenziali.
Reti neurali convoluzionali (CNN)
Le CNN sono un tipo di FNN e vengono utilizzate per compiti complessi di classificazione delle immagini, visione computerizzata, analisi delle immagini ed elaborazione del linguaggio naturale. Una CNN analizza una porzione di immagine alla volta e procede con un numero minore di parametri alla volta per imparare/estrarre le caratteristiche più importanti. L'estrazione delle caratteristiche avviene tramite kernel durante un'operazione di convoluzione.
Reti neurali ricorrenti (RNN)
Le RNN sono più adatte per i dati sequenziali, dove l'ordine degli input è fondamentale. Le informazioni sequenziali vengono catturate tramite un ciclo nello strato di input. Le RNN sono più adatte alle serie temporali e all'elaborazione del linguaggio naturale. Le memorie a breve termine (LSTM) sono tipi di RNN che dispongono di celle di memoria per memorizzare le dipendenze dei dati sequenziali. Le LSTM sono ottime per il riconoscimento vocale, l'analisi del sentimento e la traduzione.
Autoencoder
Gli autoencoder sono composti da un encoder e da un decoder. Gli encoder comprimono le dimensioni dei dati in uno spazio dimensionale inferiore (spazio latente). I decodificatori ricostruiscono i dati in ingresso utilizzando lo spazio latente. Gli autoencoder possono essere utilizzati per il denoising, la riduzione della dimensionalità e l'apprendimento di caratteristiche.
Reti di auto-attenzione (SAN)
L'architettura encoder-decoder può ricordare sequenze più brevi. Tuttavia, può dimenticare alcune informazioni (in particolare quelle ricevute per prime) in una sequenza lunga. Con un meccanismo di attenzione, il decodificatore può prestare attenzione all'intera sequenza e utilizzare il contesto dell'intera sequenza per produrre l'output. L'auto-attenzione permette di elaborare tutto il testo in ingresso in una sola volta e crea relazioni tra tutte le parole dell'intera sequenza. Grazie a questa caratteristica, l'autoattenzione funziona più velocemente di una RNN o di una CNN per le dipendenze a lungo raggio.
Storia dell'intelligenza artificiale
Benché gli albori dell'intelligenza artificiale risalgano al 750 a.C. attraverso libri e idee basate sulla fantascienza e sulle macchine pensanti, le prime basi per le reti neurali furono gettate nel 1947 da Walter Pitts e Warren McCulloch, che crearono un modello computazionale per l'architettura delle reti neurali.
Nel 1950, Alan Turing introdusse il test di Turing per definire l'intelligenza delle macchine.
Il termine intelligenza artificiale fu coniato nel 1956, quando John McCarthy organizzò un workshop sull'IA e definì il termine come la scienza e l'ingegneria per rendere le macchine intelligenti. All'inizio degli anni '60, Frank Rosenblatt sviluppò il primo computer - il Perceptron - in grado di apprendere per tentativi ed errori. Successivamente, nel 1963, John McCarthy fondò il laboratorio di IA.
Il successivo importante passo avanti nell'IA avvenne grazie ai sistemi esperti, sistemi informatici basati sulla conoscenza in grado di emulare le capacità decisionali di un esperto umano. Questi sistemi furono forme di AI di grande successo e vennero utilizzati nell'assistenza sanitaria, nei simulatori di combattimento e di addestramento e negli ausili per la gestione delle missioni.
Negli anni '80 l'intelligenza artificiale è diventata un settore e sono stati investiti miliardi di dollari in sistemi esperti, sistemi di visione e robotica.
Nel 1997, lo sviluppo di Deep Blue, il computer di IBM che giocò a scacchi e che sconfisse l'allora campione del mondo di scacchi, creò un ulteriore interesse per l'intelligenza artificiale e si registrarono rapidi sviluppi nel campo.
Intorno al 2010, i ricercatori che lavoravano sulla traduzione del linguaggio naturale hanno scoperto che, rispetto ai modelli con sistemi basati su regole, i modelli alimentati con enormi quantità di dati testuali diversi producevano risultati di gran lunga migliori.
Il 2011 ha visto l'arrivo di assistenti personali come Cortana, Siri e Alexa, in grado di rispondere alle domande attraverso l'elaborazione del linguaggio naturale e di eseguire compiti.
Nel 2014, i modelli linguistici hanno iniziato a comprendere il contesto in cui una parola appare. Ulteriori lavori hanno portato alla creazione di modelli linguistici generali che fornivano modelli di base che potevano essere adattati a un caso d'uso o a un dominio specifico.
Questi modelli di base ci hanno portato verso l'IA generativa e i modelli linguistici di grandi dimensioni (LLM) come ChatGPT.
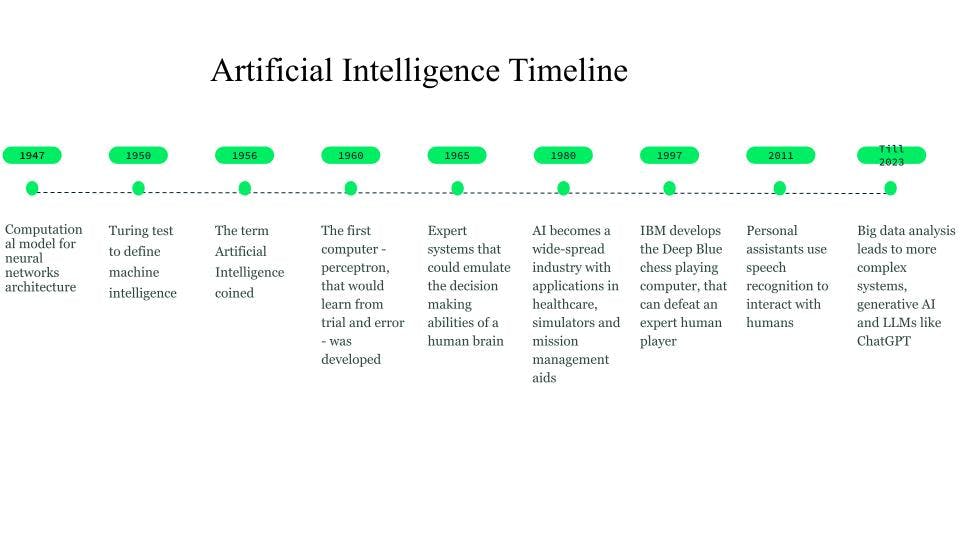 Storia e cronologia dell'IA
Storia e cronologia dell'IA
Tipi di IA
Una classificazione generale dell'intelligenza artificiale, basata sulle sue capacità, è IA stretta (o debole) e IA forte. Grazie alla ricerca e ai progressi nel campo dell'apprendimento automatico, del deep learning e dell'IA, stiamo passando dall'IA debole all'IA forte.
Narrow AI
I sistemi Weak AI/Narrow AI, o Artificial Narrow Intelligence (ANI), sono addestrati per eseguire compiti specifici e hanno capacità limitate in base ai dati su cui sono stati addestrati. Sono noti anche come sistemi di IA tradizionali, in cui il sistema è in grado di rispondere in modo intelligente sulla base di una certa serie di input e regole. Tuttavia, non può creare nulla di nuovo.
Le IA tradizionali o deboli sono ulteriormente classificate in due categorie: macchine reattive e memoria limitata.
Macchine reattive
La forma più antica di intelligenza artificiale è rappresentata dalle macchine reattive, che non hanno una memoria. Tuttavia, possono emulare la capacità di un essere umano di rispondere a diversi stimoli. Non possono imparare dall'esperienza (non hanno memoria) e basano la loro risposta su una combinazione limitata di input. La macchina Deep Blue di IBM è una macchina reattiva.
AI a memoria limitata
I sistemi a memoria limitata hanno una memoria e possono imparare e prendere decisioni in base ai dati di input forniti. La maggior parte delle IA che vediamo - le auto a guida autonoma, i chatbot, gli assistenti personali come Alexa e i sistemi di raccomandazione come quello di Netflix - sono tutti esempi di IA a memoria limitata.
IA forte
Con l'innovazione di ChatGPT e altri modelli di IA generativa simili, stiamo lentamente entrando nella fase dell'IA forte. L'IA generativa è una sorta di IA di nuova generazione, in grado di creare qualcosa di nuovo sulla base degli input dell'utente. ChatGPT è un esempio di IA generativa basata sul Large Language Model (LLM). C'è ancora molto lavoro da fare nella Strong AI, che può essere classificata come segue:
Teoria della mente (ToM)
La ToM è un'abilità cognitiva che permette di comprendere i diversi stati mentali - come le credenze, i pensieri e i sentimenti degli altri - per spiegare il loro comportamento e le loro azioni. I ricercatori stanno lavorando all'applicazione della ToM all'IA con l'obiettivo di consentire ai sistemi di IA di comprendere le emozioni e gli stati d'animo umani. ChatGPT, il nuovo sistema di IA in grado di interagire con gli esseri umani in linguaggio naturale e di produrre nuovi contenuti, ha dimostrato una certa forma di teoria della mente durante i test. Tuttavia, non possiede ancora la capacità di comprendere desideri, credenze o emozioni. Le risposte di ChatGPT si basano su dati e schemi comuni.
Intelligenza generale artificiale (AGI)
L'intelligenza artificiale generale è la fase successiva dello sviluppo dell'IA, in cui un sistema o un agente di IA si comporterà esattamente come un essere umano, compresa la creazione indipendente di competenze e funzionalità multiple, la formazione di connessioni e generalizzazioni, con un addestramento minimo o nullo.
Autoconsapevole
La fase successiva è un punto di singolarità dell'IA, in cui le macchine saranno consapevoli di sé. Avranno desideri, convinzioni ed emozioni proprie, oltre a comprendere le emozioni, i desideri e le convinzioni degli esseri umani. Gli agenti autocoscienti potranno essere utilizzati nell'assistenza sanitaria e nella robotica e si dimostreranno più potenti e precisi nello svolgimento dei compiti rispetto agli esseri umani.
Superintelligenza artificiale (ASI)
L'IA autoconsapevole può portare all'ASI, in cui gli agenti di IA potrebbero diventare super intelligenti e superare gli esseri umani in termini di valori e motivazioni. Le IA autoconsapevoli e le ASI potrebbero sollevare problemi di occupazione e di etica, per i quali i ricercatori e i governi devono prestare attenzione e definire regole e linee guida. Tuttavia, si tratta di obiettivi lontani e che potrebbero richiedere decenni per essere raggiunti.
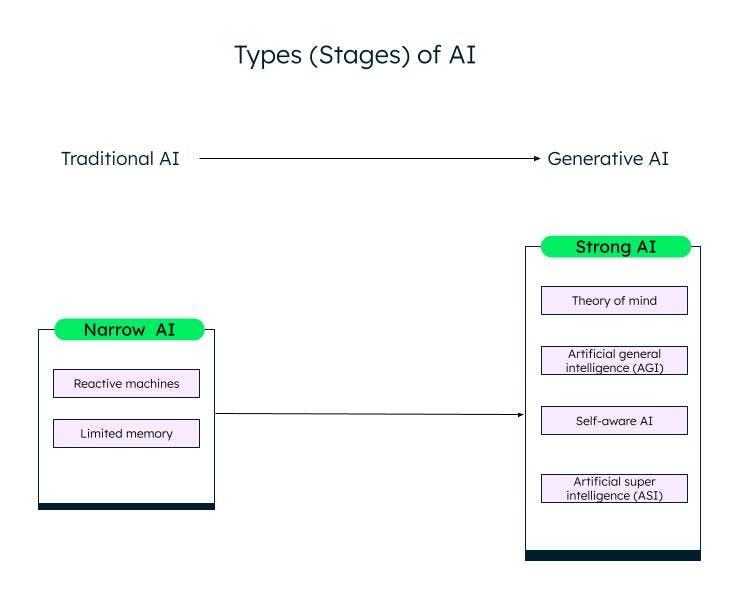 Diversi stadi (tipi) di IA
Diversi stadi (tipi) di IA
Modelli di Foundation
I modelli Foundation sono reti neurali profonde artificiali generalizzate addestrate su enormi quantità di dati non strutturati. Sono costruiti per servire come modelli generici. Possiamo costruire modelli più specifici per l'intelligenza artificiale e l'apprendimento automatico personalizzando questi modelli di base pre-addestrati (foundation).
Ad esempio, un modello di base come il Large Language Model (LLM) addestrato sui dati di testo può essere utilizzato per una serie di compiti, come il recupero di informazioni e le risposte alle domande. I trasformatori generativi pre-addestrati o GPT (su cui si basa il famoso ChatGPT) e BERT (rappresentazioni di codificatori bidirezionali da trasformatori) sono esempi di modelli di base LLM. La ResNet (rete residua) è un modello di base molto diffuso nella computer vision per la classificazione delle immagini e per le attività di computer vision. I modelli di base sono molto adattabili e sono in grado di auto-supervisionare e migliorare attraverso suggerimenti e messe a punto.
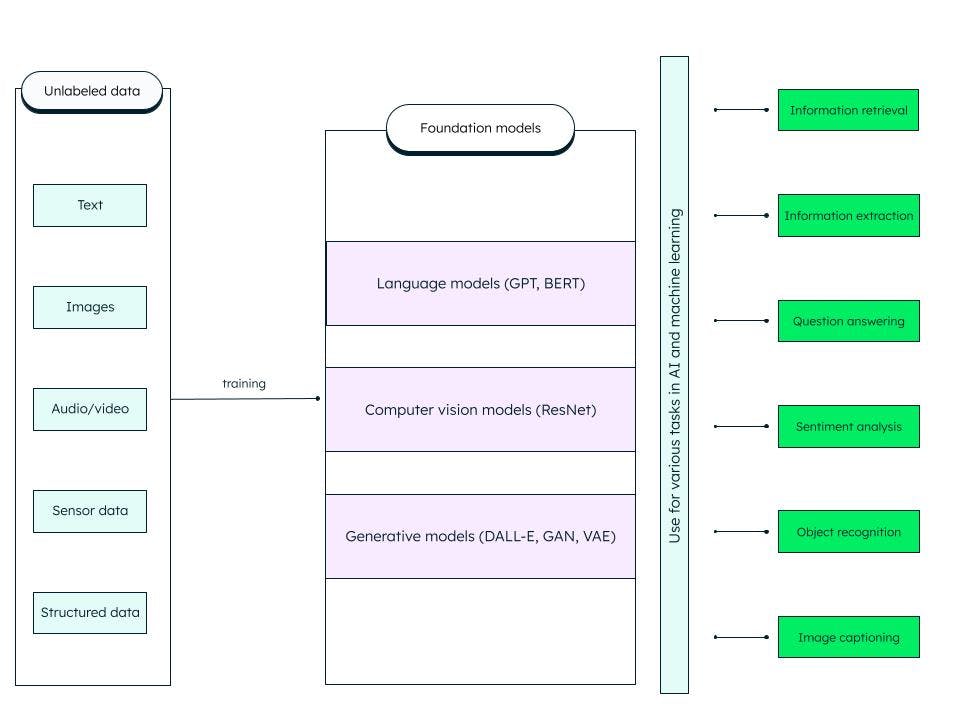
Che cosa include il modello base?
Ai generativa
Le tecnologie di IA possono produrre nuovi contenuti come immagini, video, audio, testi e qualsiasi altra cosa - un'IA in grado di generare contenuti è chiamata IA generativa!
L'IA generativa si basa su modelli di base in grado di eseguire compiti come la classificazione, il completamento di frasi, la generazione di immagini o voci e dati sintetici (generati artificialmente). I modelli di fondazione sono ottimizzati per adattarsi allo specifico compito generativo da svolgere.
Il successo di un modello di IA generativo dipende dalla qualità e dalla diversità dei dati e dalla velocità di generazione.
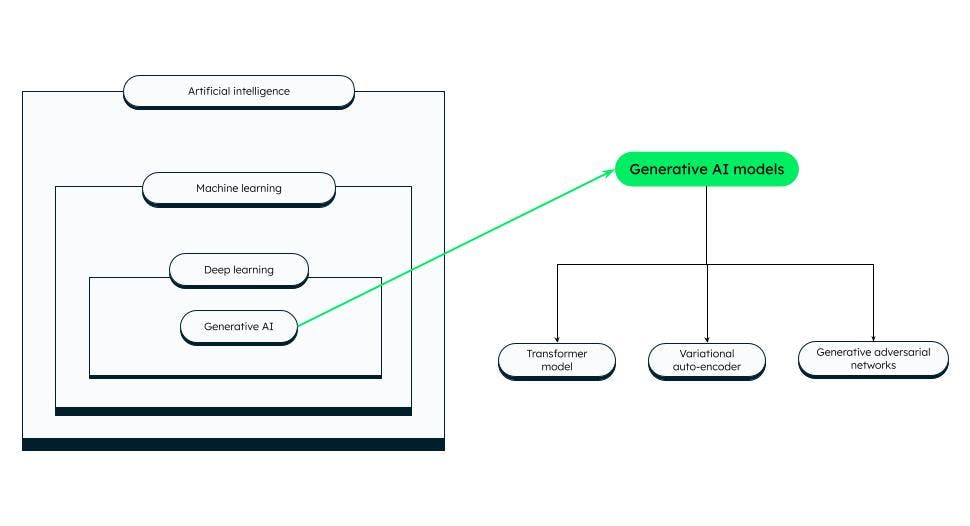 Modelli di IA generativi
Modelli di IA generativi
Esistono diverse categorie di modelli di IA generativi, tra cui:
Modello di trasformatore
Le architetture basate sui trasformatori si sono dimostrate molto precise nell'identificare le relazioni contestuali tra le parole (dati). Sono utilizzate per la generazione di testi, la traduzione automatica e la modellazione linguistica. Gli LLM, come il GPT (utilizzato in ChatGPT), sono un esempio di architettura a trasformatori.
L'attenzione è tutto ciò che serve!
Il modello di trasformatore funziona con un meccanismo di auto-attenzione, in cui l'importanza di ogni elemento di una sequenza di input viene soppesata durante l'elaborazione del testo, catturando così in modo efficace le informazioni contestuali.
Ad esempio, se vuoi tradurre il testo inglese “Mi piace scrivere di intelligenza artificiale“ in spagnolo, il modello trasformatore passerà questa sequenza di parole (token) all'encoder (rete neurale). Le parole in ingresso vengono tutte convertite parallelamente in una rappresentazione vettoriale numerica (word embeddings), composta dalla query (la trasformazione necessaria), dai vettori chiave (input) e dai vettori valore (output).
Ad esempio, per la parola “amore“ nella nostra frase, avremo i vettori q_love, k_love e v_love.
Viene creata una matrice con il punteggio di somiglianza di ogni parola con un'altra. Ad esempio, verrà generata la somiglianza della parola “amore“ con tutte le altre parole della frase: un punteggio più alto indica una maggiore somiglianza.
Il passo successivo consiste nel calcolare i pesi di attenzione che determinano l'importanza da attribuire a ogni parola della frase rispetto alla parola chiave principale (“amore“, nel nostro caso).
Quindi, aggiungiamo le codifiche posizionali alle rappresentazioni vettoriali. Le incorporazioni posizionali (somiglianza + codifica posizionale) aiutano il decodificatore (un'altra rete neurale) a decidere l'ordine in cui devono essere collocati i token (parole) in uscita.
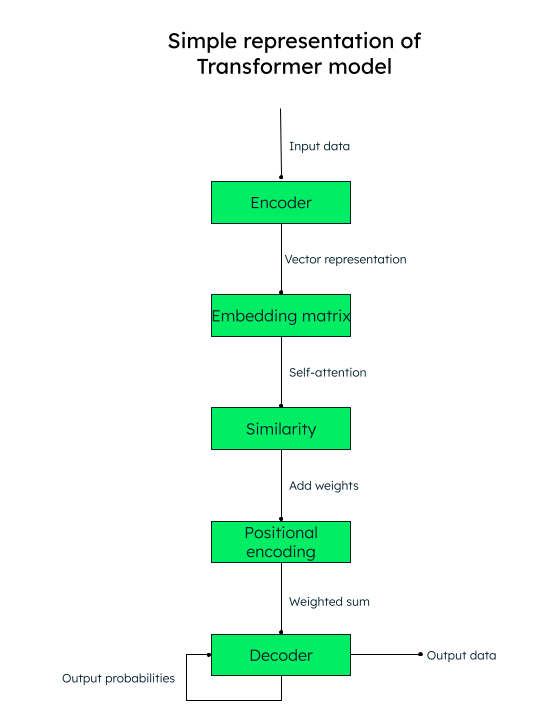
Rappresentazione del modello di trasformatore
Autocodificatori variazionali (VAE)
I VAE sono molto popolari per la generazione di immagini, la compressione dei dati e il denoising delle immagini. In un VAE, la rete neurale di codifica prende i punti dei dati in ingresso e li mappa in una rappresentazione dello spazio latente. Uno spazio latente è la rappresentazione dei dati in una dimensione inferiore, estraendo le caratteristiche più importanti dei dati e scartando le altre. La rete neurale di decodifica ricostruisce i dati in uscita sulla base della rappresentazione latente.
Reti generative avversarie (GAN)
Le GAN sono ampiamente utilizzate per creare immagini realistiche, arte, video deepfake, traduzione da immagine a immagine e immagini a super risoluzione. Una GAN consiste in un generatore (rete neurale) che prende in ingresso un rumore o un seme casuale e crea campioni di dati sintetici (come un'immagine). I campioni di dati sintetici vengono poi inviati a un'altra rete neurale, Discriminator, che utilizza una classificazione binaria per determinare se i campioni sono falsi o reali. Grazie all'addestramento avversario, il generatore e il discriminatore vengono addestrati simultaneamente fino a raggiungere un equilibrio di Nash, in cui il generatore è in grado di produrre dati realistici di alta qualità (come le immagini) e il discriminatore li classifica accuratamente come reali o falsi.
Modello linguistico di grandi dimensioni (LLM)
Gli LLM sono modelli di base che si addestrano su enormi insiemi di dati e forniscono un'esperienza quasi accurata e coinvolgente agli utenti. Per poter costruire questi modelli, è necessario acquisire enormi quantità di dati da più fonti, archiviarli correttamente, elaborarli e recuperarli in base alla rilevanza, quando necessario.
I LLM possono essere utilizzati per la risoluzione di problemi generali, come la risposta a domande, la generazione di testi, la classificazione e il riassunto di testi, e per la messa a punto tramite la messa a punto e la richiesta di addestramento su un set di dati minimo per la risoluzione di problemi specifici.
Come funziona un LLM?
I modelli Foundation imparano dai modelli di dati e producono un output flessibile e generalizzabile, che può essere applicato a diversi casi specifici. Una di queste istanze è l'LLM, che si applica agli input basati sul testo.
Gli LLM sono composti da dati, architettura e formazione. I dati sono generalmente petabyte di libri, conversazioni e contenuti testuali di grandi dimensioni. L'architettura è una rete neurale profonda e, nel caso di GPT, è il transformer. Durante l'addestramento, il modello impara a prevedere la parola successiva di una determinata frase.
Tuttavia, ci sono tre problemi con l'LLM:
Se qualche informazione è stata sviluppata o modificata dopo che il modello è stato completamente addestrato, il modello non ne è a conoscenza e potrebbe fornire risultati non aggiornati. Ad esempio, se chiedi al modello: “Dammi un elenco di buoni film comici degli ultimi 6 mesi“, il modello non sarà in grado di farlo se non è stato addestrato 6 mesi fa!
Il modello potrebbe avere informazioni errate all'interno della sua rappresentazione interna.
Il modello non può accedere ai tuoi dati privati e potrebbe presentare informazioni distorte o incomplete basate su una conoscenza limitata.
Retrieval augmentation generation (RAG)
Il framework RAG AI mira a risolvere i problemi di cui sopra e a migliorare la qualità delle risposte LLM fornendo al modello una verità di base su una base di conoscenza esterna che integra le informazioni presentate internamente nell'LLM. In questo modo si riducono le possibilità che il modello identifichi in modo errato un modello o un oggetto inesistente (allucinazioni), nonché informazioni errate, fuorvianti e non aggiornate.
L'architettura di recupero utilizza un archivio vettoriale e aumenta le capacità del LLM attraverso la ricerca vettoriale.
MongoDB Atlas, la piattaforma unificata per i dati degli sviluppatori, offre la ricerca vettoriale all'interno della piattaforma - che puoi configurare in pochi semplici passi - per migliorare l'output del tuo LLM e produrre risultati più accurati.
Ricerca vettoriale
Nella sezione precedente abbiamo imparato a conoscere il modello dei trasformatori e a capire che i vettori sono rappresentazioni numeriche di dati testuali. Ad esempio, la rappresentazione vettoriale della nostra frase precedente, “Mi piace scrivere di intelligenza artificiale“, potrebbe essere simile a: “Mi piace...“ = [0.33, 0.45, 0.72, -0.23.....]
La rappresentazione vettoriale di cui sopra include la relazione tra ogni parola, come ad esempio la relazione tra la parola “artificiale“ e la parola “intelligenza“ o la parola “scrivere“ o il contesto della parola “amore“ in questa frase.
Questi vettori vengono generati (come abbiamo visto nel modello del trasformatore) inviando i dati di input attraverso una rete neurale profonda (encoder).
In realtà, le rappresentazioni vettoriali possono avere un numero qualsiasi di dimensioni. Più parametri hanno i dati, più dimensioni ci sono. Per dare un senso a questi numeri e per capire cosa succede dopo che i vettori sono stati generati, tracciamo un grafico a due dimensioni per facilitare la comprensione.
Tutti i vettori sono rappresentati secondo la loro rappresentazione numerica. Si noti che gli embeddings di parole (vettori) che hanno un significato simile saranno tracciati uno vicino all'altro, formando così un cluster.
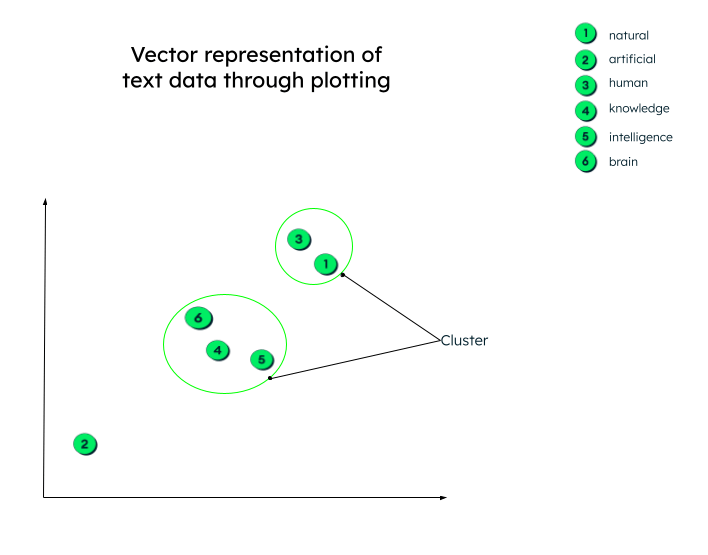 Rappresentazione grafica dei vettori
Rappresentazione grafica dei vettori
Potrebbero esserci molti contesti in cui i dati possono essere raggruppati in cluster. La relazione dipende da come l'encoder incorpora i dati di origine e da come viene calcolata la distanza tra i vettori. Nell'esempio seguente si possono stabilire due tipi di relazioni: gatto e cane sono animali domestici, mentre tigre e lupo sono animali selvatici. - Cat e tiger appartengono alla stessa famiglia, mentre dog e wolf appartengono alla stessa famiglia di animali.
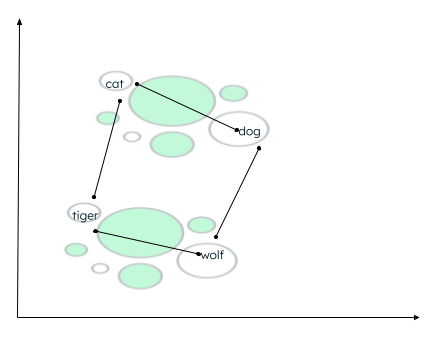 Calcolo della distanza di parole simili
Calcolo della distanza di parole simili
Una funzione di somiglianza determina le parole più vicine ed etichetta di quelle dei vicini. Questo raggruppamento/clustering viene eseguito utilizzando l'algoritmo k-nearest neighbor, dove il valore di k rappresenta il numero di vicini da identificare. Per trovare la somiglianza, la ricerca vettoriale supporta molti metodi, come la ricerca della distanza euclidea tra le estremità dei due vettori. - Cosino (angolo) tra i due vettori. - Prodotto scalare (scalare) dei vettori.
MongoDB Atlas fornisce le funzionalità di ricerca vettoriale all'interno della piattaforma Atlas stessa, attraverso framework di intelligenza artificiale, e supporta tutte le funzioni di somiglianza di cui sopra.
MongoDB Atlas Vector
Search MongoDB ha sempre supportato la ricerca vettoriale in due dimensioni. Tuttavia, la nuova ricerca vettoriale consente funzionalità potenti grazie all'incorporamento e consente dimensioni più elevate. Le applicazioni possono scrivere i dati e gli incorporamenti vettoriali nel database. I vettori di dati vengono generati utilizzando un modello di codificatore. La ricerca Atlas utilizza l'algoritmo Vicino più vicino (ANN) approssimativo tramite il grafico Hierarchical Navigable Small World (HNSW). L'ANN è una variante del vicino k-nearest, ma con una velocità di recupero superiore.
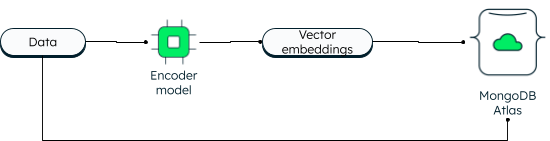 Come vengono archiviati i vettori in MongoDB Atlas
Come vengono archiviati i vettori in MongoDB Atlas
Durante la lettura, la query viene codificata e inviata nella fase di aggregazione `$search' insieme al vettore di destinazione. Se si desidera apprendere i passaggi, seguire il tutorial sulla creazione di applicazioni AI generative utilizzando MongoDB.
Il vantaggio di avere vettori insieme ai dati operativi è che è possibile accedere a tutte le informazioni all'interno di un'unica piattaforma, anche ai dati privati, che non sarebbero altrimenti accessibili.
Atlas vector search semplifica l'architettura dell'applicazione. Poiché Atlas è completamente gestito, la piattaforma MongoDB Atlas si occupa di tutto, dalla sincronizzazione dei dati alla sicurezza e alla privacy. Gli sviluppatori possono lavorare con il database e la ricerca vettoriale utilizzando l'API unificata MongoDB Query. È possibile distribuire Atlas in oltre 125 regioni tra i tre principali provider di cloud. Atlas offre un uptime continuo con automazione avanzata che assicura prestazioni elevate indipendentemente dalla scala dell'applicazione.
Alcuni casi d'uso importanti di Atlas vector search sono:- Semantic search. - Sistemi di risposta alle domande. - Estrazione feature. - Raccomandazione e punteggio di rilevanza. - Generazione sinonimo. - Ricerca immagini.
Come funziona la ricerca Atlas Vector?
L'applicazione client invia i dati non elaborati. Il modello di incorporamento vettoriale crea vettori per ogni testo nella query iniziale (dati grezzi). Framework come Llamaindex e LangChain si integrano bene con MongoDB Atlas per creare incorporamenti e inviare dati a MongoDB per aggiungere consapevolezza contestuale. La context aware query, nota come prompt, viene quindi inviata a un LLM, che genera una encoded response, per essere elaborata dal vector embedding model (decoder) e inviata al client dopo la decoding.
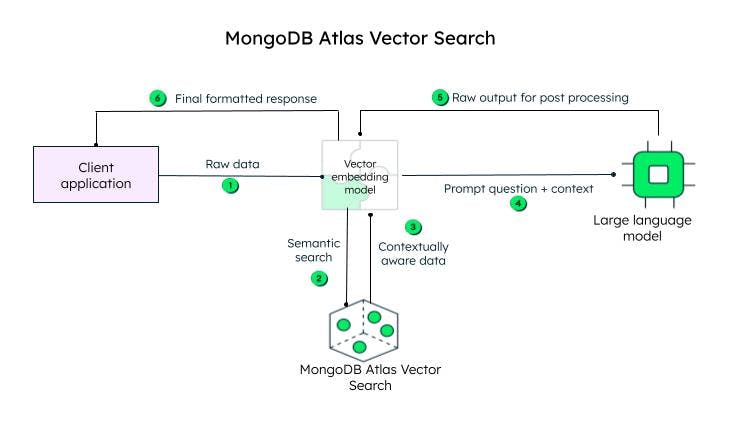 Steps to achieve vector search in MongoDB Atlas
Steps to achieve vector search in MongoDB Atlas
Vector embeddings possono essere archiviati nel documento del database MongoDB come un array di float, insieme al contenuto, nel campo content_embeddings.
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... other fields......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]Se il numero di dimensioni nei dati di input è maggiore, il numero di virgola mobile sarà maggiore.
Successivamente, si definisce la definizione dell'indice aggiungendola al generatore di definizioni:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}La definizione dell'indice include il modello che troverebbe i cluster di somiglianza, le dimensioni e la funzione di somiglianza (tra i tre metodi supportati da MongoDB) che verrebbero utilizzati dal modello.
Questo è tutto! Bastano due passaggi e il gioco è fatto.
Per poter eseguire la ricerca, è possibile utilizzare l'operatore di aggregazione '$search' specificando l'operatore 'knnBeta' e fornendo gli incorporamenti vettoriali della query nel campo 'vector'. È inoltre necessario specificare il “path“ degli incorporamenti di contenuto che devono essere esaminati per la ricerca vettoriale. MongoDB fornisce anche “filters“ aggiuntivi per restringere la ricerca e il numero di vicini più prossimi che l'algoritmo k-nearest neighbor dovrebbe restituire.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Poiché sia gli incorporamenti vettoriali che i dati risiedono nella stessa piattaforma, è possibile accedere al carico di lavoro operativo e ai vettori utilizzando un'unica API di query MongoDB unificata. Per imparare a utilizzare la funzionalità passo dopo passo, consulta il nostro tutorial su creazione di app di IA generativa utilizzando la ricerca vettoriale.
Importanti casi d'uso dell'IA
L'AI viene applicata con successo in vari settori, tra cui retail, healthcare e manufacturing. Alcuni casi d'uso popolari dell'IA sono: l'elaborazione del linguaggio naturale (NLP): l'IA viene utilizzata attivamente nell'analisi del sentiment, assistenti virtuali, chatbot, riconoscimento vocale e traduzione testuale. Come abbiamo visto sopra, sfruttando la potenza di Atlas Vector Search e della ricerca vettoriale, i sistemi di intelligenza artificiale possono produrre output nel linguaggio umano.
Computer vision: Grazie alle moderne neural networks in place, AI systems sono in grado di eseguire con precisione image classification, face and object recognition, e image generation.
Sistemi di raccomandazione e filtraggio dei contenuti: i sistemi di AI sono in grado di consigliare contenuti agli utenti utilizzando modelli di deep learning e machine learning senza alcun intervento umano.
Sanità: la tecnologia dell'intelligenza artificiale ha portato l'assistenza sanitaria a un nuovo livello, aiutando i medici nella diagnosi precoce delle malattie, nella ricerca medica e nella scoperta di farmaci, nonché nell'archiviazione sicura delle cartelle cliniche elettroniche dei pazienti.
Auto a guida autonoma: le auto a guida autonoma sono alimentate da algoritmi di intelligenza artificiale, dati dei sensori e visione artificiale.
Robotica: i robot industriali aumentano la produttività eseguendo attività complesse con precisione. Allo stesso modo, i robot di servizio sono in grado di svolgere i propri compiti in modo efficiente nei settori sanitario e alberghiero.
Uso etico dell'AI, governance dell'AI e regolamenti
Con i rapidi sviluppi nel campo dell'AI, è importante stabilire regole e regolamenti e affrontare le considerazioni etiche in modo che i sistemi di AI siano usati in modo equo, trasparente e per lo scopo giusto. L’etica dell’AI si concentra sulle implicazioni morali ed etiche degli strumenti e delle tecnologie dell’AI, ovvero equità, privacy, trasparenza e responsabilità.
I framework, la struttura e le regole di conformità sono stabiliti dal governo per garantire un uso responsabile dell’AI.
Il governo crea anche regolamenti sull'IA, ovvero quadri giuridici, per garantire la sicurezza dei dati, la protezione dei consumatori e gli standard di sicurezza.
Strumenti e servizi per l'IA
I dati sono il fulcro di tutte le operazioni di AI e MongoDB è una piattaforma su cui puoi contare per costruire potenti app di AI. Essendo un database con uno schema flessibile, MongoDB offre una soluzione di archiviazione centralizzata, con funzionalità di gestione dei dati integrate, elaborazione avanzata dei dati, analisi in tempo reale, scalabilità e molto altro ancora. Altri strumenti e servizi popolari sono:
ChatGPT: ChatGPT è quasi entrato a far parte della vita di tutti i giorni per porre semplici domande, pianificare vacanze, fare coding, scrivere poesie, riassumere testi e molto altro ancora.
Dall-E 2: Dall-E 2 è un progetto OpenAI, proprio come ChatGPT, e genera grafica computerizzata come immagini, dipinti e disegni a partire da messaggi di testo.
Stable Diffusion 2: si tratta di uno strumento di AI da testo a immagine per applicazioni di AI generativa. A differenza degli strumenti OpenAI, a cui si accede tramite portali browser, Stable Diffusion 2 è disponibile per il download e l'installazione e gli utenti possono accedere pubblicamente al codice sorgente e agli algoritmi.
Domande frequenti
Cos'è l'intelligenza artificiale (IA)?
La capacità delle macchine di pensare, imparare e prendere decisioni, come un essere umano, di fronte a diversi scenari, è nota come intelligenza artificiale.
Come funziona l'IA?
L'intelligenza artificiale (AI) comprende l'apprendimento automatico e il deep learning, entrambi composti da diversi algoritmi per soddisfare i diversi casi d'uso. Questi algoritmi funzionano su enormi quantità di dati raccolti da varie fonti, ordinati, trasformati e preelaborati per essere inseriti negli algoritmi. Gli algoritmi utilizzano i dati per addestrarsi, ottenere feedback e migliorarsi, fino a ottenere un risultato desiderabile.
Perché l’intelligenza artificiale è importante?
[L'intelligenza artificiale è importante] (#importanti-casi-duso-dellia) in quanto può consentire l'automazione di attività banali e ripetitive, migliorare l'efficienza, ridurre gli errori umani, fornire analisi predittive per un processo decisionale più rapido e accurato, fornire consigli personalizzati per gli utenti, assistere nella diagnosi delle malattie, accelerare la ricerca in medicina e scienza e promuovere l'innovazione.
Quando è stata inventata l'IA?
Quali sono i tipi di IA?
Un esempio di intelligenza artificiale?
L'esempio più recente e popolare di AI è ChatGPT, che può rispondere alle domande poste dagli umani attraverso la digitazione, con una risposta simile a quella umana. Può anche ricordare il contesto della conversazione. ChatGPT è addestrato su un modello linguistico di grandi dimensioni e ulteriormente arricchito dall'incremento. MongoDB Atlas offre un'ottima piattaforma per costruire potenti app di intelligenza artificiale generativa utilizzando qualsiasi provider cloud.