人工智能 (AI) 可以定义为机器在没有人类直接监督的情况下理性思考、解决问题和作出决策的能力。
自机器学习和深度学习技术问世以来,机器开始根据输入的数据进行“思考”和“学习”,并执行以前只能由人类完成的任务。在本文中,我们将进一步探讨 AI、生成式 AI,以及 MongoDB 如何通过简化 AI 处理、实现基于上下文的搜索和提高大型语言模型 (LLM) 的准确性来改变生成式 AI 格局。
目录
人工智能 (AI) 释义
人工智能是计算机科学的一个领域,它使机器能够进行推理、智能决策和数据分析,其智能程度被认为超过了人类的理解力和掌控力。
AI 包括数据科学、统计学、神经科学和机器学习等领域,其中还包括作为现代算法基础的深度学习。
这些算法是 AI 的基础,通过将数据理解为模式,并轻松、准确地完成艰巨的任务,作出类似人类的决策。
AI 系统的一些流行示例包括 ChatGPT、Alexa 和 Siri 等虚拟助手、自动驾驶汽车和推荐引擎。
人工智能与人类智能的相似之处
人脑的工作机制非常复杂。我们根据过去的经验和记忆来思考、行动和决策,并根据周围的环境和情况总结出相应的模式。在一段时间内,我们所认为的世界就是大脑所感知的世界。例如,如果我们总是看到红玫瑰,我们的大脑就会认为玫瑰是红色的,具有特定的形状和大小。如果我们读到或听到玫瑰也可能是黄色或粉色的,那么根据以前对红玫瑰的认知,我们就会想象黄玫瑰或粉玫瑰在某种程度上非常类似于红玫瑰。
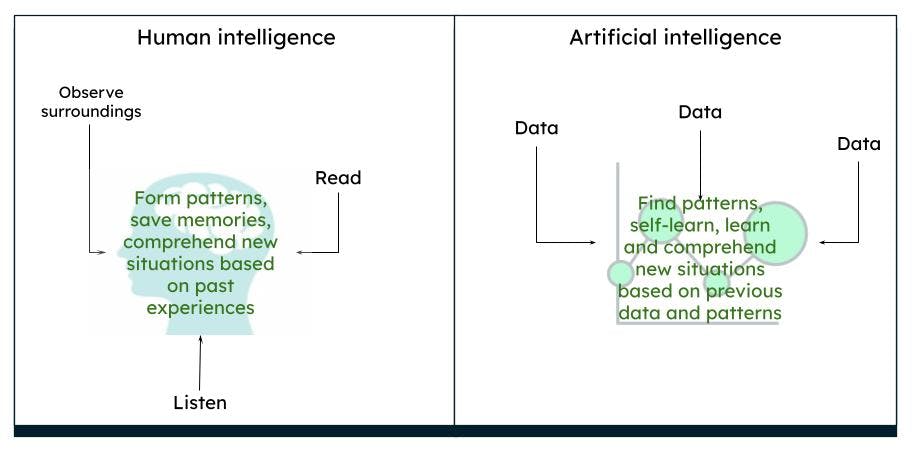 Representation of human intelligence vs artificial intelligence
Representation of human intelligence vs artificial intelligence
AI 以同样的机制运作。在获得足够多的数据时,机器就能根据数据模式,通过算法得出某些结果。例如,如果输入有关玫瑰花和颜色的数据,那么机器下次再识别到类似的物体时,就可以将其标识为特定颜色的玫瑰。
AI 与机器学习
AI 是一个更广泛的术语,包括用于执行智能任务的机器的理论和系统。机器学习 是 AI 的一个分支,侧重于分析数据,利用各种算法发现模式并推动决策,而不需要显式编程。机器学习技术包括有监督学习法、无监督学习法和强化学习法。
深度学习
深度学习是机器学习的一个子集,类似于人类智能。深度学习模型由人工深度神经网络(即相互连接的神经元或节点)组成,具有许多层,能够处理比机器学习算法更复杂的数据模式。LLM 和生成式 AI 是深度学习的子集。目前已有许多人工神经网络可用于特定任务。
所有这些神经网络都基于“感知器”,即用于二元分类的最基本的神经网络。感知器由单层神经元组成,它接收输入层传来的数据,应用权重,并馈送到输出层。
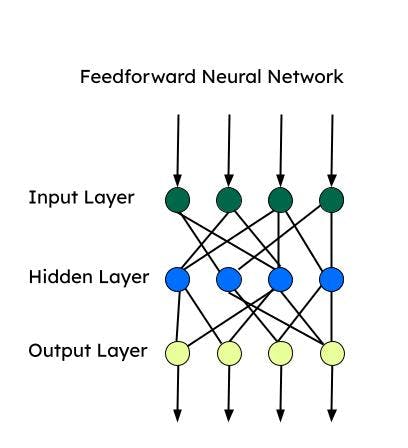
前馈神经网络 (FNN)
前馈神经网络是最早发明的人工神经网络之一,每层由多个感知器组成。前馈神经网络也称为多层感知器 (MLP)。它只向一个方向(即前进方向)提供信息,并且没有循环。前馈神经网络有输入层、输出层和处理输入数据的隐藏层。当数据不随时间变化或不连续时,FNN 可用于监督学习。
卷积神经网络 (CNN)
CNN 是 FNN 的类型之一,可用于复杂的图像分类任务、计算机视觉、图像分析和自然语言处理。CNN 一次只处理一个图像片段,并一次使用较少的参数来学习/提取最重要的特征。特征提取是在卷积运算过程中使用内核完成的。
循环神经网络 (RNN)
RNN 更适合处理输入顺序至关重要的顺序数据。顺序信息是通过输入层的循环所获取的信息。RNN 更适合时间序列数据和自然语言处理。长短时记忆 (LSTM) 是 RNN 的一种,它具有存储单元,用于存储顺序数据的依赖关系。LSTM 在语音识别、情感分析和翻译方面表现出色。
自编码器
自编码器由编码器和解码器组成。编码器将数据的维度压缩到低维空间(隐空间)。解码器利用隐空间重建输入数据。自编码器可用于去噪、降维和特征学习。
自注意力机制 (SANs)
编码器-解码器结构可以记忆较短的序列。不过,该结构可能会忘记长序列中的某些信息(尤其是首先接收的信息)。通过注意力机制,解码器就能关注整个序列,并利用整个序列的上下文来产生输出。自注意力允许一次性处理所有输入文本,并在整个序列中的所有词之间建立关系。得益于这一功能,在处理长程依赖时,自注意力机制的工作速度比 RNN 或 CNN 更快。
AI 的历史
虽然早在公元前 750 年,人们就开始创作科幻小说,提出了思维机器的构想,但直到 1947 年,Walter Pitts 和 Warren McCulloch 才为神经网络奠定基础,创建神经网络架构的计算模型。
1950 年,Alan Turing 提出图灵测试,作为衡量机器智能的准则。
AI 一词诞生于 1956 年,当时 John McCarthy 组织了一次 AI 研讨会,并将其定义为有关机器智能化的科学和工程。大约在 20 世纪 60 年代初,Frank Rosenblatt 首次引入感知器这一概念,即让机器从试错中学习。1963 年,John McCarthy 成立了 AI 实验室。
随后,AI 的重大突破来自专家系统,这是一种基于知识的计算机系统,可以模拟人类专家的决策能力。这些系统是相当成功的 AI 形式,被用于医疗保健、战斗、训练模拟器以及任务管理辅助工具。
20 世纪 80 年代,AI 发展成为一项产业,人们在专家系统、视觉系统和机器人技术上投入了数十亿美元。
1997 年,IBM 研制出会下国际象棋的计算机“深蓝”,它一举击败当时的国际象棋世界冠军,这一消息进一步激发了人们对 AI 的兴趣,推动了该领域快速发展。
2010 年左右,自然语言翻译的研究人员发现,与基于规则的系统所建立的模型相比,通过大量不同文本数据所训练的模型会产生更好的结果。
2011 年,Cortana、Siri 和 Alexa 等个人助理相继问世,它们可以通过自然语言处理技术,回答问题和执行任务。
到 2014 年,语言模型开始理解词的语境。通用语言模型是进一步的研究成果,这些模型提供了基础或基础模型,可对特定的用例或领域进行下游处理。
这些基础模型引导我们开发出生成式 AI 和 ChatGPT 等大型语言模型 (LLM)。
 History and timeline of AI
History and timeline of AI
AI 的类型
根据能力高低,AI 大致可分为窄 AI(或弱 AI)和强 AI。通过机器学习、深度学习和 AI 领域的研究和进步,我们正在从弱 AI 迈向强 AI。
Narrow AI
弱 AI/窄 AI,或称狭义人工智能 (ANI),系统经过训练,可以执行特定的任务,并根据训练数据而拥有有限的能力。它们也被称为传统 AI 系统,可以根据特定的输入和规则作出智能响应。但是,此类 AI 系统不能创造任何新的内容。
传统 AI 或弱 AI 又分为两类:响应式机器和有限内存。
响应式机器
最古老的 AI 形式是响应式机器,并没有记忆。不过,此类机器可以模拟人类对不同刺激作出响应的能力。它们无法从经验中学习(没有记忆),只能根据有限的输入组合作出响应。IBM 的“深蓝”就属于响应式机器。
有限记忆 AI
有限记忆系统具有记忆力,可以根据输入的数据进行学习和作出决策。我们看到的大多数 AI 用例,比如自动驾驶汽车、聊天机器人、Alexa 等个人助理以及 Netflix 等推荐系统,都是有限记忆 AI。
强 AI
随着 ChatGPT 和其他类似生成式 AI 模型的创新,我们正逐渐步入强 AI 阶段。生成式 AI 是下一代 AI,可以根据用户的输入创造新的内容。ChatGPT 是基于大型语言模型 (LLM) 的生成式 AI 的一个例子。强 AI 方面还有很多工作要做,具体可分为以下几类:
心智理论 (ToM)
心智理论是一种认知技能,用于理解他人的信念、思想和情感等不同心理状态,从而解释他人的行为和行动。研究人员正致力于将 ToM 应用于 AI,目标是让 AI 系统能够理解人类的情绪和心理状态。ChatGPT 是一种新的 AI 系统,可以用自然语言与人类交互并生成新的内容,其测试过程展示了某种形式的心智理论。然而,ChatGPT 仍然无法理解人类的欲望、信念或情感。ChatGPT 的响应基于数据和常见模式。
通用人工智能 (AGI)
通用人工智能是 AI 发展的下一阶段,在这一阶段,AI 系统或代理的行为将与人类完全一样,仅需很少训练甚至无需训练,即可独立构建多种能力和功能、形成联系和概括总结。
自我意识
下一阶段是 AI 的奇点,即机器将拥有自我意识。除了理解人类的情感、欲望和信念之外,机器也会拥有自己的情感、欲望和信念。有自我意识的 AI 可用于医疗保健和机器人领域,与人类相比,它们拥有更强大、更准确的任务执行能力。
超人工智能 (ASI)
有自我意识的 AI 可能会催生 ASI,AI 或许会变得超级智能,并在价值观和理念上超越人类。有自我意识的 AI 和 ASI 可能会引发就业和道德问题,研究人员和政府需要对此保持警惕,并制定相关规则和准则。然而,这些目标都很遥远,可能需要几十年才能成为现实。
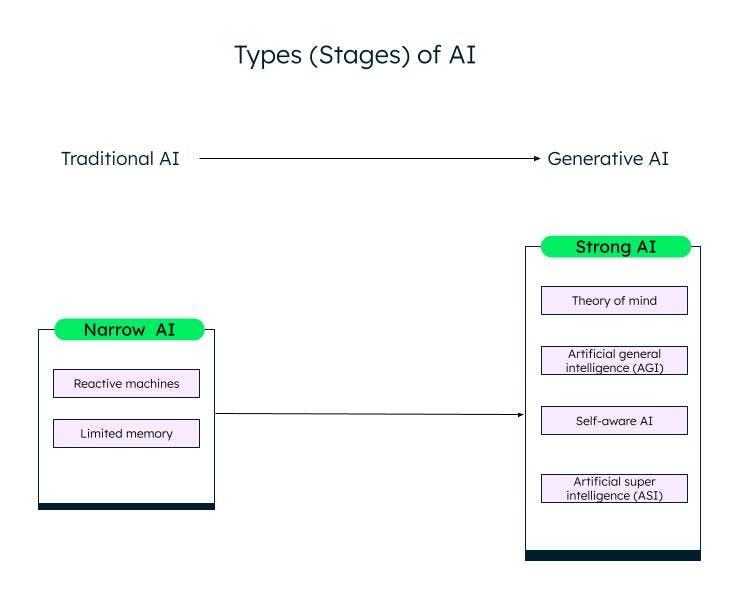 Different stages (types) of AI
Different stages (types) of AI
基础模型
基础模型是广义的人工深度神经网络,在海量非结构化数据基础上训练而成。它们被用于构建通用模型。我们可以通过定制此类预先训练的基本(基础)模型,为 AI 和机器学习任务构建更具体的模型。
例如,在文本数据上训练的大型语言模型 (LLM) 等基础模型可用于信息检索和问答等多种任务。生成式预训练转换器模型或 GPT(著名的 ChatGPT 正是基于此模型)和 BERT(来自转换器的双向编码器表征)是 LLM 基础模型的例子。ResNet(残差网络)是一种流行的计算机视觉基础模型,用于图像分类和计算机视觉任务。基础模型具有很强的适应性,可以通过提示和微调进行自我监督和随机应变。
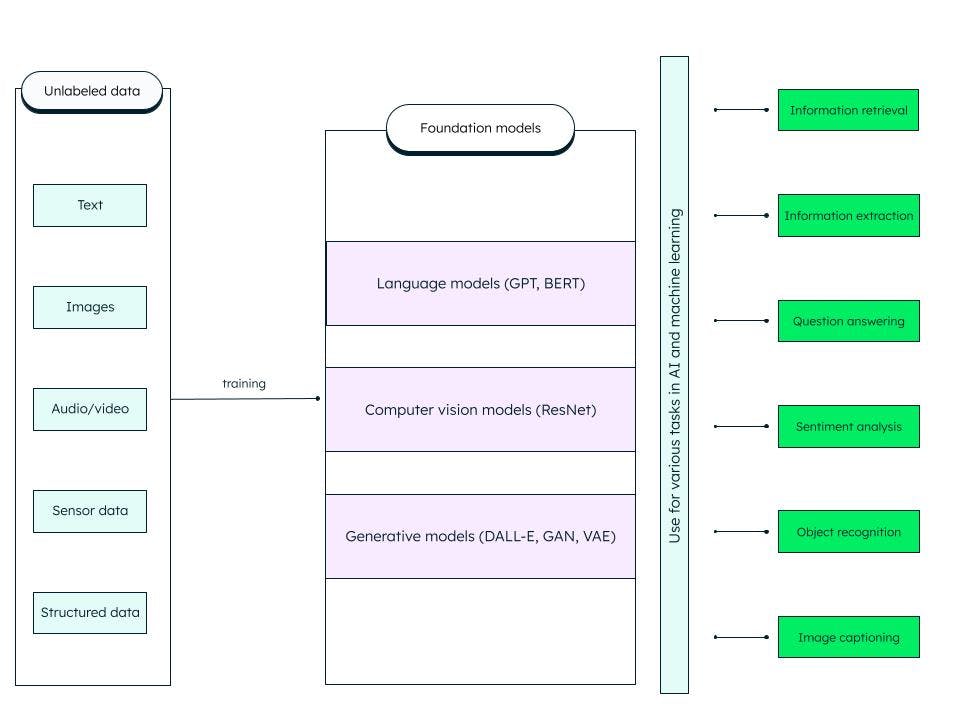
What does the foundation model include?
生成式 AI
AI 技术可以生成新的内容,如图像、视频、音频、文本以及其他任何内容;这种能够生成内容的 AI 被称为生成式 AI!
生成式 AI 基于基础模型,可以执行分类、完成句子、生成图像或语音以及合成(人工生成)数据等任务。基础模型经过微调,用于适应当前特定的生成式任务。
生成式 AI 模型的成功取决于数据的质量、多样性以及生成速度。
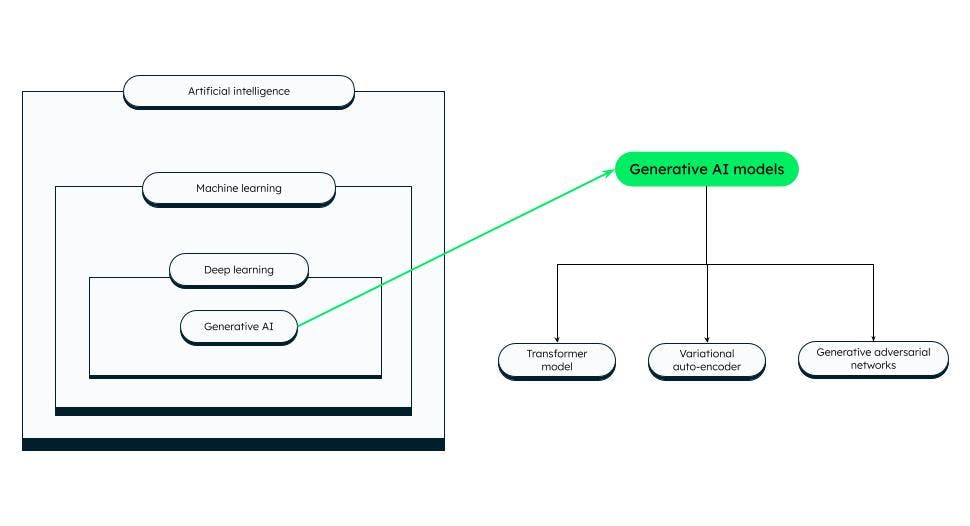 Generative AI models
Generative AI models
生成式 AI 模型有不同的类别,其中一些比较知名的模型如下:
转换器模型
事实证明,转换器架构在识别词(数据)之间的上下文关系方面相当准确。此类模型可用于文本生成、机器翻译和语言建模。LLM 和 GPT(ChatGPT 所使用的模型)一样,都是转换器架构的例子。
您只需要集中注意力!
转换器模型采用自注意力机制,在处理文本的过程中,对输入序列中每个元素进行加权,从而有效获取上下文信息。
例如,如果要将英文文本“I love to write about artificial intelligence”翻译成西班牙文,转换器模型会将这些词(标记)序列传递给编码器(神经网络)。所有输入的词都并行地转换为 numericvector 表征(词嵌入),具体由查询(所需转换)、键(输入)和值(输出)向量组成。
例如,对于句子中的“love”一词,我们将获得 q_love、k_love 和 v_love 向量。
我们再根据每个词与另一个词的相似度分数创建一个矩阵。例如,“love”一词与句子中所有其他词的相似度分数将被生成,分数越高,表示相似度越高。
下一步是计算注意力权重,这决定句子中每个词相对于主关键词(本例中为“love”)的重要程度。
然后,将位置编码添加到向量表征中。位置嵌入(相似度 + 位置编码)有助于解码器(另一个神经网络)决定输出标记(词)的排列顺序。
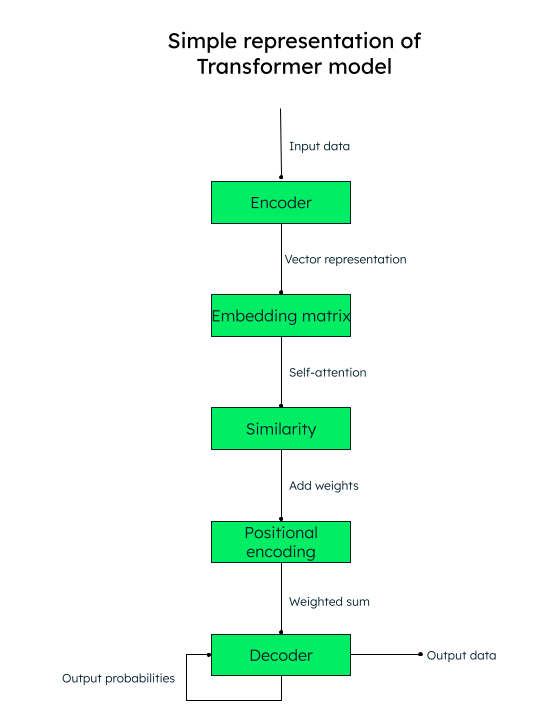
Representation of transformer model
变分自编码器 (VAE)
变分自编码器在图像生成、数据压缩和图像去噪方面非常流行。在 VAE 中,编码器神经网络接收输入数据点,并将其映射到隐空间表征。隐空间通过提取数据中最重要的特征并丢弃其他特征,以较低维度表征数据。解码器神经网络根据隐表征重建输出数据。
生成式对抗网络 (GANs)
生成式对抗网络被广泛用于创建逼真的图像、艺术品、深度伪造视频、图像到图像的转换以及超分辨率图像。GAN 由生成器(神经网络)组成,它将随机噪音或种子作为输入,并创建合成数据样本(如图像)。然后,合成数据样本被输入另一个神经网络,即鉴别器,它使用二元分类法来判断样本的真假。通过对抗训练,生成器和鉴别器同时接受训练,直到达到 纳什均衡,即生成器能够生成高质量的真实数据(如图像),而鉴别器则能准确区分真假。
大型语言模型 (LLM)
大型语言模型是一种基础模型,可在海量数据集上进行训练,并为用户提供近乎准确的交互式体验。为了能够建立此类模型,您需要从多个来源获取大量数据,然后正确存储,并在需要时根据相关性处理和获取这些数据。
LLM 可用于解决一般问题,如回答问题、文本生成、文本分类和摘要,以及使用调整和提示功能进行微调,通过最小数据集训练解决特定问题。
LLM如何工作?
基础模型从数据模式中学习,生成灵活、可通用的输出,然后应用于不同的特定实例。基于文本输入的 LLM 就是其中的一个例子。
LLM 由数据、架构和训练组成。这些数据一般都是大部头书籍、对话和文本,通常以拍字节为单位。此架构是一个深度神经网络,在 GPT 中,它就是 [转换器] (#transformer-model)。在训练过程中,模型学习预测任何给定句子的下一个词。
不过,LLM 存在三个问题:
如果在模型完全训练完成后,产生或更改任何信息,则模型将无法获知此类信息,并可能给出过时的结果。例如,如果要求模型“提供前六个月精彩喜剧电影的清单”,而模型没有接受过这方面的训练,则无法提供清单!
模型的内部表征可能存在错误的信息。
模型无法访问您的私人数据,可能会根据有限的知识提供有偏见或不完整的信息。
检索增强生成 (RAG)
检索增强生成 AI 框架旨在解决上述问题,并通过为模型提供外部知识库的基础事实,补充 LLM 内部信息,从而提高 LLM 响应质量。这就减少了模型错误识别不存在的模式或对象(幻觉)以及提供错误、误导和过时信息的概率。
检索架构使用向量存储,并通过向量搜索增强 LLM 的能力。
MongoDB Atlas,统一的开发人员数据平台在平台内提供矢量搜索,您只需简单几步即可设置来提高您的 LLM 输出,产生更准确的结果。
矢量搜索
在上一节中,我们了解了变换器模型,以及向量是文本数据的数字表示。例如,前一句话“I love to write about artificial intelligence”的向量表示可以类似于 “I love to…”= [0.33,0.45, 0.72, -0.23.....]
上述向量表示包括每个词之间的关系,例如“artificial”一词与“intelligence”一词或“write”一词之间的关系,或者在这个句子中“love”一词的上下文是什么。
这些向量是通过深度神经网络(编码器)发送输入数据生成的(正如我们在变换器模型中看到的那样)。
实际上,向量表示可以有任意数量的维度。数据的参数越多,维度就越多。为了能够理解这些数字,了解这些矢量生成后的情况,我们来绘制二维图形,以便于理解。
所有矢量均按其数字表示绘制。请注意,具有相似含义的词嵌入(向量)将被绘制在彼此靠近的位置,从而形成集群。
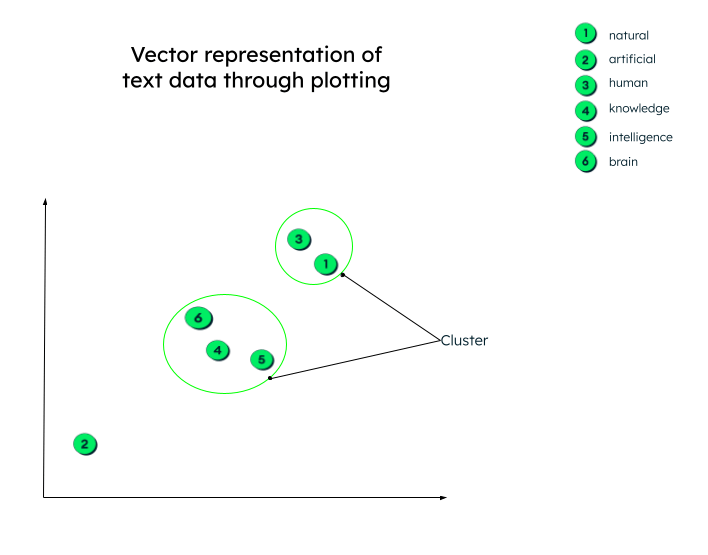 矢量的图形表示
矢量的图形表示
数据可能存在多种聚类上下文。这种关系取决于编码器如何嵌入源数据,以及如何计算向量之间的距离。在以下示例中,可以建立两种类型的关系:
- 猫 和 狗 都是家养动物,而 老虎 和 狼 则是野生动物。
- 猫 和 老虎 属于同一科,而 狗 和 狼 属于同一科。
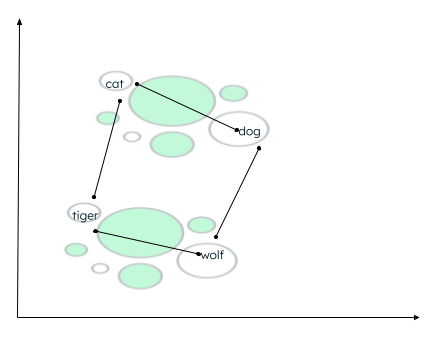
计算同类词的距离
相似度函数可确定哪些词更接近,然后将位置接近的词标记为邻近词。这种分组/聚类是通过 k 近邻算法完成的,其中 k 的值代表要识别的邻近词数量。为了找到相似度,矢量搜索支持多种方法,比如查找:
- 两个向量端点之间的欧氏距离。
- 两个向量之间的余弦(夹角)。
- 向量的点(标量)积。
MongoDB Atlas 通过 AI 框架在 Atlas 平台内部提供矢量搜索功能,并支持上述所有相似性函数。
MongoDB Atlas Vector Search
MongoDB 一直支持二维向量搜索。但是新的矢量搜索由于采用了嵌入技术,因此具有强大的功能,并允许更高的维度。 应用程序可以将数据和向量嵌入写入数据库。数据向量使用编码器模型生成。Atlas 搜索通过分层可导航小世界 (HNSW) 图使用近似最近邻 (ANN) 算法。ANN 是 K 近邻算法的变体,但检索速度更快。
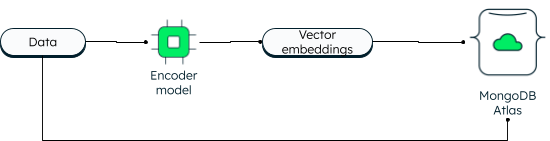
如何在 MongoDB Atlas 中存储向量
读取时,查询会被编码,并与目标向量一起提交到 $search 聚合阶段。如果您想了解具体步骤,请参阅使用 MongoDB 构建生成式 AI 应用程序]教程。
将矢量与运行数据放在一起的优势在于,您可以在一个平台内访问所有信息,甚至是您的私人数据,否则这些信息将无法访问。
Atlas 矢量搜索简化了应用架构。由于 Atlas 是完全托管型的,因此从数据同步、安全性到隐私保护,全部都由 MongoDB Atlas 平台负责。开发人员可使用统一的 MongoDB 查询 API 处理数据库和矢量搜索。您可以通过三大云提供商将 Atlas 部署到 125 多个地区。Atlas 通过先进的自动化技术为您提供持续的正常运行时间,无论应用程序规模大小,都能确保高性能。
Atlas 矢量搜索的一些重要用例包括:
- 语义搜索。
- 问答系统。
- 特征提取。
- 建议和相关性评分。
- 同义词生成。
- 图像搜索。
Atlas Vector search 如何工作?
? 客户端应用程序发送原始数据。向量嵌入模型为初始查询(原始数据)中的每个文本创建向量。Llamaindex 和 LangChain 等框架可与 MongoDB Atlas 很好地集成,以创建嵌入并将数据发送到 MongoDB,从而增加上下文感知。然后将上下文感知的查询,即提示,发送到 LLM,由其生成编码响应,然后由矢量嵌入模型(解码器)处理,并在解码后发送到客户端。
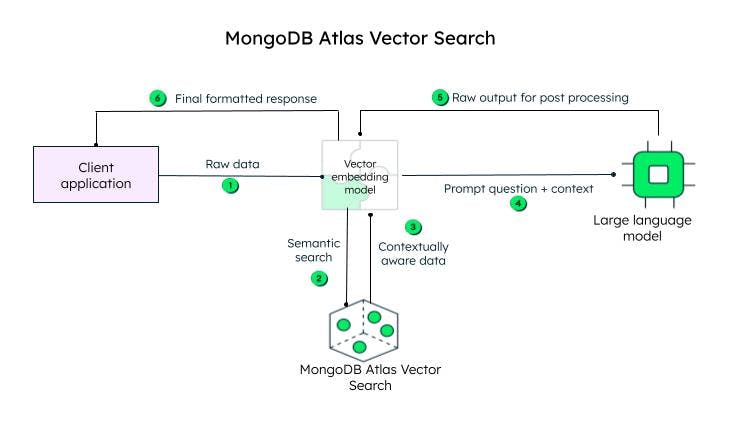 在 MongoDB Atlas 中实现矢量搜索的步骤
在 MongoDB Atlas 中实现矢量搜索的步骤
矢量嵌入可以作为浮点数组与内容一起存储在 MongoDB 数据库文档的 content_embeddings 字段中。
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... 其他字段......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]如果输入数据的维数更多,浮点数也会更多。
然后将索引定义添加到定义生成器来定义索引定义:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}索引定义包括查找相似性集群的模型、维度以及模型将使用的相似性函数(MongoDB 支持的三种方法之一)。
就是这样!只需两步就可搞定。
为了能够搜索,可以使用 $search 聚合操作符,指定 knnBeta 操作符,并在 vector 字段中给出查询的矢量嵌入。您还应指定矢量搜索中应查看的内容嵌入的“路径”。MongoDB 还提供了额外的“筛选器”以缩小搜索范围,并提供了 k 近邻算法应返回的邻近词数量。
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]由于向量嵌入和数据位于同一平台,因此您可以使用统一的 MongoDB 查询 API 访问操作工作负载和向量。如需逐步学习使用该功能,请参阅我们的教程使用向量搜索构建生成式 AI 应用程序。
重要的AI 使用案例
AI 已成功应用于零售、医疗保健和制造等多个领域。AI 的部分常见用例包括:
自然语言处理 (NLP):AI 在情感分析、虚拟助手、聊天机器人、语音识别和文本翻译中得到了广泛应用。如上所述,利用 LLM 和向量搜索的强大功能,AI 系统可以用人类语言生成输出。
计算机视觉:有了现代神经网络,AI 系统就能准确地执行图像分类、人脸和物体识别以及图像生成。
推荐系统和内容筛选:AI 系统能够利用深度学习和机器学习模型向用户推荐内容,无需人工干预。
医疗保健:人工智能技术将医疗保健提升到了新的水平,可以帮助医生开展疾病早期诊断、医学研究和药物研发,安全存储患者的电子健康记录等。
自动驾驶汽车:自动驾驶汽车由 AI 算法、传感器数据和计算机视觉驱动。
机器人技术:工业机器人能准确执行复杂的任务,从而提高生产效率。同样,服务机器人也能在医疗保健和酒店服务领域高效地执行任务。
AI 的伦理使用、AI 治理和法规
随着 AI 领域快速发展,必须制定规则和条例并解决伦理问题,这样才能公平透明地使用 AI 系统,并用于正确的目的。 AI 伦理侧重于 AI 工具和技术的道德和伦理影响,即公平、隐私、透明度和问责制。
政府制定了框架、结构和合规规则,以确保负责任地使用 AI。
政府还制定了 AI 法规,即法律框架,以确保数据安全、消费者保护和安全标准。
AI 工具和服务
数据是所有 AI 操作的核心,而 MongoDB 是您可以依赖的平台构建强大的 AI 应用程序。作为具有灵活模式的数据库,MongoDB 提供了集中存储解决方案,并具有内置数据管理功能、高级数据处理、实时分析、可扩展性等等。其他一些流行的工具和服务包括:
ChatGPT:ChatGPT 几乎已成为日常生活的一部分,从简单提问到计划假期、编码、写诗、总结文本等等。
Dall-E 2:与 ChatGPT 一样,Dall-E 2 也是 OpenAI 推出的项目,能根据文本提示生成图像、绘画和绘图等计算机图形。
Stable Diffusion 2:这是一款根据文本生成图像的 AI 工具,适用于生成式 AI 应用。与通过浏览器门户访问的 OpenAI 工具不同,Stable Diffusion 2 可供下载和安装,用户可以公开访问源代码和算法。
常见问题解答
什么是人工智能 (AI)?
机器在面对不同场景时,能够像人类一样思考、学习和做出决定,这种能力被称为人工智能。
AI 如何工作?
人工智能 (AI) 包括机器学习和深度学习,两者都由多种算法组成,以满足不同的使用情况。这些算法处理从各种来源收集的海量数据,经过分类、转换和预处理,然后输入到算法中。算法利用数据进行训练、获得反馈并自我改进,直到达到理想的结果。
人工智能为何重要?
AI 非常重要,因其可以实现自动化处理普通的重复性任务,提高效率,减少人为错误,提供预测分析,以更快更准确地做出决策,为用户提供个性化建议,协助疾病诊断,加快医学和科学研究进度,促进创新。
AI 是什么时候发明的?
AI 有哪些类型?
人工智能例子有哪些?
最近最流行的 AI 例子是 ChatGPT,其可以通过打字对人类提出的问题做出类似人类的回答。ChatGPT 还能记住对话的上下文。ChatGPT 是在大型语言模型 上训练的,并通过增强进一步丰富。MongoDB Atlas 提供了绝佳的平台,可以使用任何主要云提供商构建功能强大的生成式 AI 应用程序。