La inteligencia artificial (IA) puede definirse como la capacidad de las máquinas para pensar racionalmente, resolver problemas y tomar decisiones sin la supervisión de una mente humana.
Con la llegada del aprendizaje automático y las tecnologías de aprendizaje profundo, las máquinas pueden “pensar“ y “aprender“ basándose en los datos que se les suministran y realizar tareas que antes solo podían realizar los humanos. En este artículo, exploraremos más sobre inteligencia artificial, IA generativa y cómo MongoDB está cambiando la fachada de la IA generativa al simplificar el procesamiento de IA, habilitar búsquedas basadas en el contexto y mejorar la precisión de los grandes modelos lingüísticos (LLM).
Índice
- Inteligencia artificial (IA) explicada
- En qué se parece la IA a la inteligencia humana
- IA vs aprendizaje automático
- Aprendizaje profundo
- Historia de la inteligencia artificial
- Tipos de IA
- Modelos de base
- IA generativa
- Modelo de lenguaje grande (LLM)
- Búsqueda vectorial
- Búsqueda vectorial en Atlas MongoDB
- ¿Cómo funciona la búsqueda vectorial en Atlas?
- Casos importantes de uso de la IA
- Uso ético de la IA, gobernanza y normativa de la IA
- Herramientas y servicios de IA
- Preguntas frecuentes
Inteligencia Artificial (IA) explicada
La inteligencia artificial es un campo de la informática que faculta a las máquinas para participar en el razonamiento, la toma de decisiones inteligentes y el análisis de datos, en una escala que se percibe que supera la comprensión y las capacidades humanas.
La IA incluye campos como ciencia de datos, estadística, neurociencia y aprendizaje automático, que incluye además el aprendizaje profundo, en el que se basan nuestros algoritmos modernos.
Estos algoritmos son la base para que la IA tome decisiones similares a las humanas al comprender los datos en los patrones y realizar tareas difíciles con facilidad y precisión.
Algunos ejemplos populares de sistemas de inteligencia artificial incluyen ChatGPT, asistentes virtuales como Alexa y Siri, autos autónomos y motores de recomendación.
Cómo es que la IA es similar a la inteligencia humana
El cerebro humano funciona de una manera compleja. Pensamos, actuamos y tomamos decisiones con base en nuestras experiencias y recuerdos pasados, que dan como resultado patrones casados en el entorno y las situaciones. A lo largo de un periodo de tiempo, lo que observamos es lo que el cerebro percibe como real. Por ejemplo, si vemos constantemente una rosa roja, nuestro cerebro procesa que una rosa es de color rojo y tiene cierta forma y tamaño. Si leemos o escuchamos que las rosas también pueden ser amarillas o rosas, basándonos en nuestro conocimiento previo de una rosa roja, imaginamos una rosa amarilla o rosa para, de cierta manera, acercarnos a lo que sería una rosa roja.
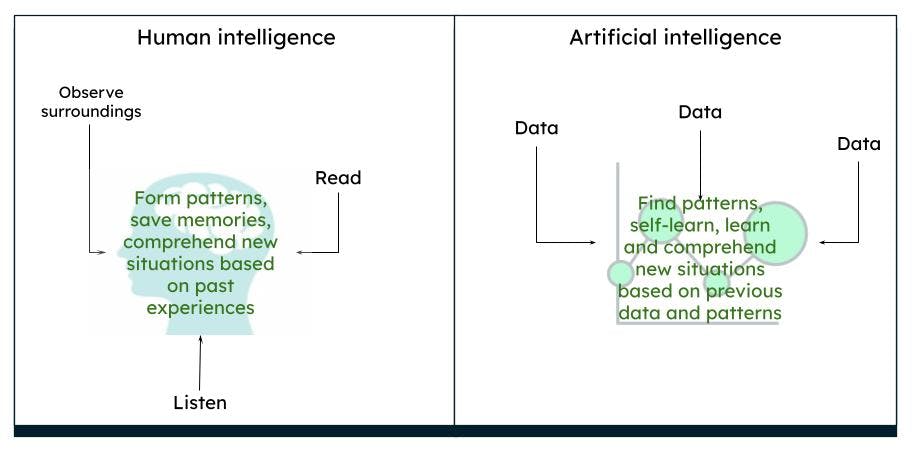 Representación de inteligencia humana vs inteligencia artificial
Representación de inteligencia humana vs inteligencia artificial
La IA funciona de la misma manera. Cuando una computadora está provista de suficientes datos, las máquinas son capaces de deducir ciertos resultados, basados en los patrones de datos, a través de algoritmos. Por ejemplo, si alimenta datos sobre rosas y colores, la próxima vez que la computadora vea un objeto similar, puede identificarlo como una rosa de un color en particular.
IA vs aprendizaje automático
La IA es un término más amplio que consiste en teorías y sistemas para construir máquinas que realicen tareas que requieran inteligencia. Aprendizaje automático es una rama de la IA que se centra en el análisis de datos, para encontrar patrones e impulsar decisiones utilizando diversos algoritmos, sin necesidad de programación explícita. Las técnicas de aprendizaje automático consisten en métodos de aprendizaje supervisado, no supervisado y de refuerzo.
Aprendizaje profundo
El aprendizaje profundo es un subconjunto del aprendizaje automático que se asemeja a la inteligencia humana. Los modelos de aprendizaje profundo consisten en redes neuronales profundas artificiales, es decir, neuronas (o nodos) interconectadas, y tienen muchas capas, lo que les permite procesar patrones de datos más complejos que los algoritmos de aprendizaje automático. Los LLM y la IA generativa son subconjuntos del aprendizaje profundo. Hay muchas redes neuronales artificiales que se pueden utilizar para tareas específicas.
Todas estas redes neuronales se basan en un “perceptrón”, que es la red neuronal más básica utilizada para la clasificación binaria. El perceptrón consiste en una sola capa de neuronas que toma una capa de entrada, aplica pesos y alimenta a la capa de salida.
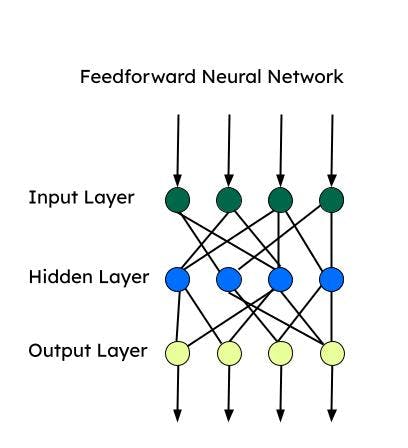
Red neuronal feedforward (FNN)
Feedforward es una de las primeras redes neuronales artificiales desarrolladas y consiste en un grupo de múltiples perceptrones en cada capa. También se la conoce como perceptrón multicapa (MLP). Sólo suministra información en una dirección, es decir, hacia adelante, y no hay bucles. Las redes neuronales feedforward tienen entrada, salida y una capa oculta que procesa la entrada. Las FNN se utilizan para el aprendizaje supervisado, cuando los datos no dependen del tiempo ni son secuenciales.
Redes neuronales convolucionales (CNN)
Las CNN son un tipo de FNN y se utilizan para tareas complejas de clasificación de imágenes, visión por computadora, análisis de imágenes y procesamiento del lenguaje natural. Una CNN mira un parche de imagen a la vez y avanza con un menor número de parámetros a la vez para aprender/extraer las características más importantes. La extracción de características se realiza mediante kernels durante una operación de convolución.
Redes neuronales recurrentes (RNN)
Los RNN son más adecuadas para datos secuenciales, donde el orden de entrada es crucial. La información secuencial se captura mediante un bucle en la capa de entrada. Las RNN son más adecuadas para Time Series y procesamiento de lenguaje natural. La memoria a largo plazo (LSTM) son tipos de RNN, que tienen celdas de memoria para almacenar dependencias de los datos secuenciales. Las LSTM son bastante buenas en reconocimiento de voz, análisis de sentimientos y traducción.
Autoencoder
Los autocodificadores consisten en un codificador y un decodificador. Los codificadores comprimen las dimensiones de los datos a un espacio dimensional inferior (espacio latente). Los decodificadores reconstruyen los datos de entrada utilizando el espacio latente. Los autocodificadores se pueden utilizar para la eliminación de emisiones, la reducción de dimensionalidad y el aprendizaje de características.
Redes de autoatención (SAN)
La arquitectura codificador-decodificador puede recordar secuencias más cortas. No obstante, puede olvidar parte de la información (particularmente la información que se recibe primero) en una secuencia larga. Con un mecanismo de atención, el decodificador puede atender a toda la secuencia y utilizar el contexto de toda la secuencia para producir la salida. La autoatención permite procesar todo el texto de entrada a la vez y crea relaciones entre todas las palabras en toda la secuencia. Debido a esta característica, la autoatención funciona más rápido que una RNN o CNN para dependencias de largo alcance.
Historia de la inteligencia artificial
Aunque las primeras imaginaciones comenzaron ya en el año 750 a.C. a través de libros e ideas basadas en la ciencia ficción y las máquinas pensantes, las primeras bases de las redes neuronales fueron sentadas en 1947 por Walter Pitts y Warren McCulloch, que crearon un modelo computacional para la arquitectura de las redes neuronales.
En 1950, Alan Turing introdujo el test de Turing, para definir la inteligencia de las máquinas.
El término inteligencia artificial se acuñó en 1956, cuando John McCarthy organizó un taller de IA y definió el término como la ciencia y la ingeniería de hacer que las máquinas sean inteligentes. A principios de la década de 1960, Frank Rosenblatt desarrolló la primera computadora, Perceptrón, que aprendería a partir de prueba y error. Más tarde, en 1963, John McCarthy fundó el laboratorio de IA.
El siguiente gran avance en la IA pasó por los sistemas expertos, sistemas informáticos basados en conocimientos que podrían emular las capacidades de toma de decisiones de un experto humano. Estos sistemas fueron formas de IA bastante exitosas y se utilizaron en atención médica, simuladores de combate y entrenamiento, y ayudas a la gestión de misiones.
En la década de 1980, la inteligencia artificial se convirtió en una industria y se invirtieron miles de millones de dólares en sistemas expertos, sistemas de visión y robótica.
En 1997, el desarrollo de Deep Blue, el ordenador ajedrecista de IBM que derrotó al entonces campeón del mundo de ajedrez, suscitó un mayor interés por la inteligencia artificial y se produjeron rápidos avances en este campo.
Alrededor de 2010, los investigadores que trabajaban en la traducción del lenguaje natural descubrieron que, en comparación con los modelos con sistemas basados en reglas, los modelos que se alimentaban con grandes cantidades de datos de texto diversos producían resultados mucho mejores.
El año 2011 vio la llegada de asistentes personales como Cortana, Siri y Alexa, que podían responder preguntas a través del procesamiento del lenguaje natural y realizar tareas.
En 2014, los modelos lingüísticos comenzaron a comprender el contexto en el que aparecía una palabra. Los trabajos posteriores dieron lugar a modelos lingüísticos generales que proporcionaban modelos de base o fundamentales que podían derivarse para un caso de uso o dominio específico.
Estos modelos básicos nos han llevado hacia la IA generativa y los grandes modelos de lenguaje (LLM) como ChatGPT.
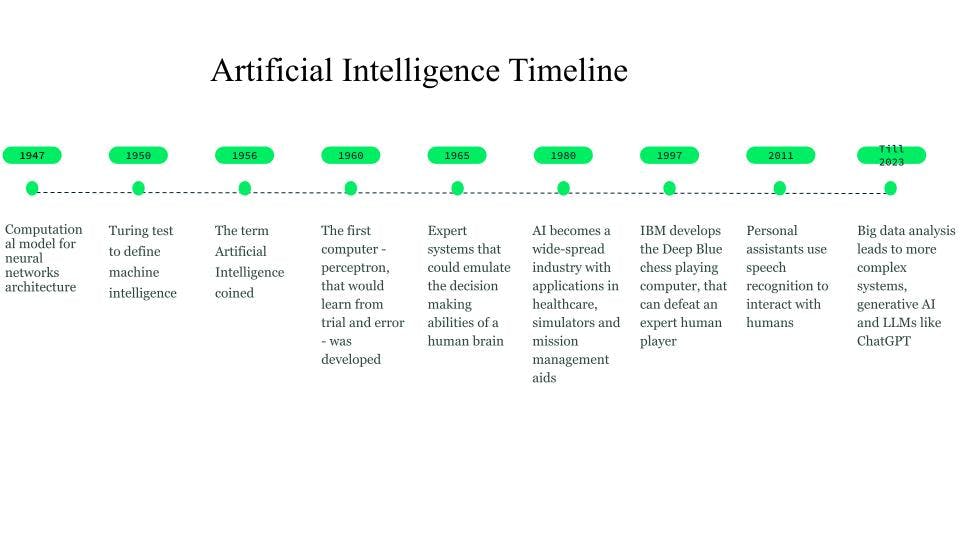 Historia y cronología de IA
Historia y cronología de IA
Tipos de la IA
Una clasificación amplia de la inteligencia artificial, basada en su capacidad, es IA estrecha (o débil) e IA fuerte. A través de la investigación y los avances en el campo del aprendizaje automático, el aprendizaje profundo y la IA, estamos pasando de la IA débil a la IA fuerte.
IA estrecha
Los sistemas de IA débil/IA estrechaI, o Inteligencia Artificial Estrecha (ANI), están entrenados para realizar tareas específicas y tienen capacidades limitadas en función de los datos con los que se entrenan. También se conocen como sistemas de AI tradicionales, en los que el sistema puede responder de forma inteligente en función de un determinado conjunto de entradas y reglas. Sin embargo, no puede crear nada nuevo.
Las IA tradicionales o débiles se clasifican a su vez en dos categorías: máquinas reactivas y memoria limitada.
Máquinas vas
La forma más antigua de inteligencia artificial eran las máquinas reactivas, que no tenían memoria. Sin embargo, pueden emular la capacidad de un humano para responder a diferentes estímulos. No pueden aprender de su experiencia (no tienen memoria) y basan su respuesta en una combinación limitada de entradas. La máquina Deep Blue de IBM es una máquina reactiva.
IA de memoria limitada
Los sistemas de memoria limitada tienen memoria y pueden aprender y tomar decisiones basadas en los datos de entrada proporcionados. La mayor parte de la IA que vemos, los autos autónomos, los chatbots, los asistentes personales como Alexa y los sistemas de recomendación como el de Netflix, son todos ejemplos de IA de memoria limitada.
IA fuerte
Con la innovación de ChatGPT y otros modelos de IA generativa similares, estamos entrando lentamente en la fase de IA fuerte. La IA generativa es una especie de IA de última generación, que puede crear algo nuevo basado en las entradas del usuario. ChatGPT es un ejemplo de IA generativa basada en el modelo de lenguaje grande (LLM). Queda mucho trabajo por hacer en la IA fuerte, que se puede clasificar de la siguiente manera:
Teoría de la mente (ToM)
La ToM es una habilidad cognitiva para comprender los diferentes estados mentales, como las creencias, los pensamientos y los sentimientos de los demás, para explicar su comportamiento y acciones. Los investigadores están trabajando en la aplicación de ToM a la IA con el objetivo de permitir que los sistemas de IA comprendan las emociones y el estado mental humano. ChatGPT, la nuevo IA que puede interactuar con humanos en lenguaje natural y producir nuevos contenidos, ha demostrado alguna forma de teoría de la mente durante las pruebas. Sin embargo, todavía no posee la capacidad de comprender deseos, creencias o emociones. Las respuestas de ChatGPT se basan en datos y patrones comunes.
Inteligencia artificial general (AGI)
La IA general es la siguiente etapa del desarrollo de la IA, en la que un sistema o agente de IA se comportará exactamente como un humano, incluida la creación independiente de múltiples competencias y funcionalidades, conexiones de formularios y generalizaciones, con poca o ninguna formación.
Autoconsciencia
La siguiente etapa es un punto de singularidad de la IA, donde las máquinas serán conscientes de sí mismas. Tendrán sus propios deseos, creencias y emociones, además de comprender las emociones, deseos y creencias de los humanos. Los agentes autoconscientes se pueden utilizar en el cuidado de la salud y la robótica, y demuestran ser más potentes y precisos en la realización de tareas en comparación con los humanos.
Superinteligencia artificial (ASI)
La IA autoconsciente puede conducir a la ASI, donde los agentes de IA pueden volverse súper inteligentes y dominar a los humanos en valores y motivos. Las AI y las ASI autoconscientes podrían plantear problemas con el empleo, así como con la ética, para lo cual los investigadores y los gobiernos deben estar alerta y formar normas y directrices. Sin embargo, estos son objetivos descabellados y pueden tardar décadas en alcanzarse.
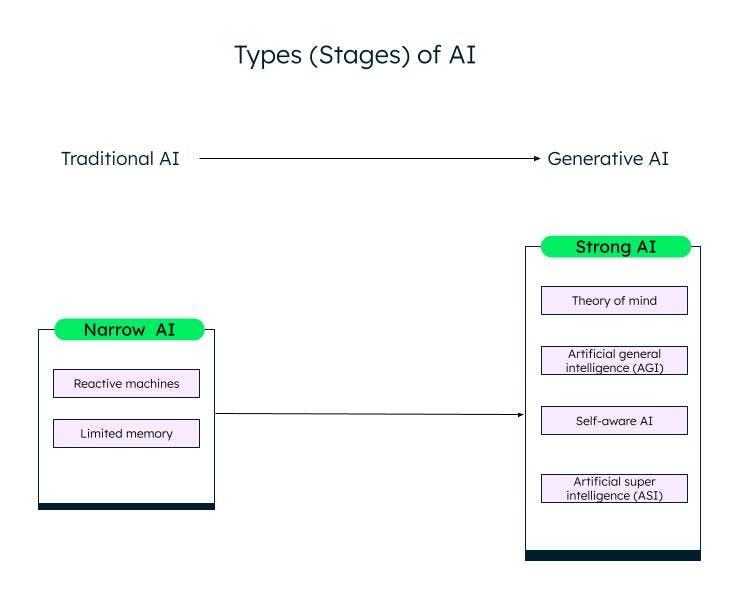 Diferentes etapas (tipos) de IA
Diferentes etapas (tipos) de IA
Modelos de base
Los modelos de base son redes neuronales profundas artificiales generalizadas capacitadas en grandes cantidades de datos no estructurados. Están diseñados para servir como modelos de uso general. Podemos construir modelos más específicos para tareas de IA y aprendizaje automático personalizando estos modelos de base preentrenados.
Por ejemplo, un modelo básico como el gran modelo lingüístico (LLM) entrenado en datos de texto puede utilizarse para diversas tareas, como la recuperación de información y las preguntas y respuestas. El transformador preentrenado generativo o GPT (en el que se basa el famoso ChatGPT) y BERT (representaciones codificadoras bidireccionales a partir de transformadores) son ejemplos de modelos de base LLM. ResNet (red residual) es un modelo básico popular de visión artificial para tareas de clasificación de imágenes y visión artificial. Los modelos de base son muy adaptables y pueden autosupervisarse e improvisar a través de indicaciones y ajustes.
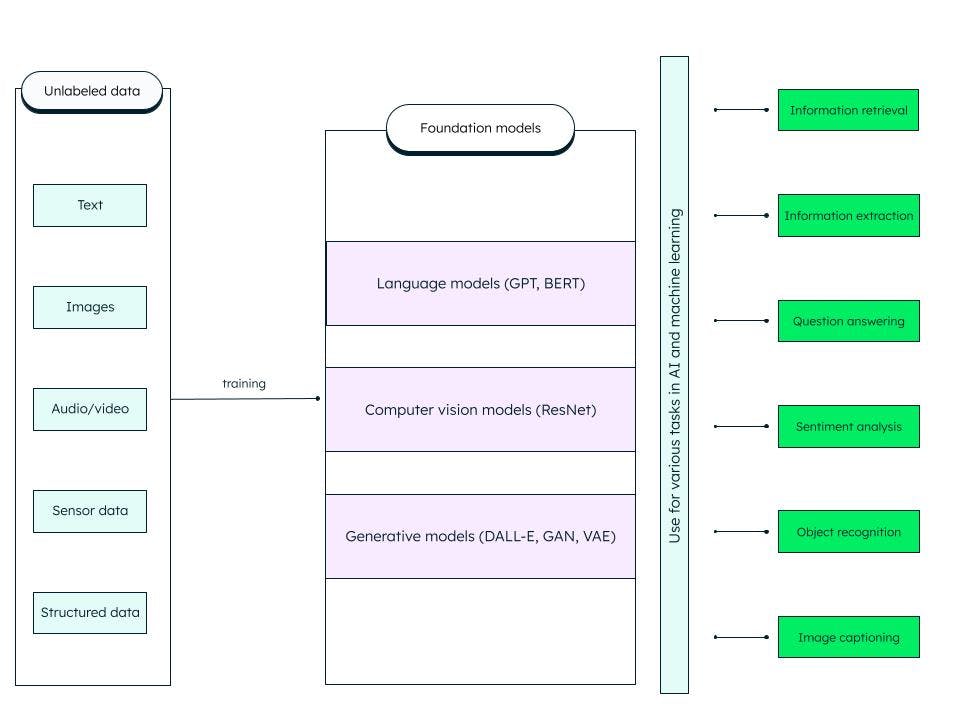
¿Qué incluye el modelo de base?
IA generativa
Las tecnologías de IA pueden producir nuevos contenidos como imágenes, vídeos, audios, texto y casi cualquier otra cosa, por lo que una IA capaz de generar contenidos se denomina IA generativa.
La IA generativa se basa en modelos básicos que pueden realizar tareas como la clasificación, la finalización de oraciones, la generación de imágenes o voz y datos sintéticos (generados artificialmente). Los modelos de base se ajustan para adaptarse a la tarea generativa específica en cuestión.
El éxito de un modelo de IA generativa depende de la calidad y diversidad de los datos, así como de la velocidad de generación.
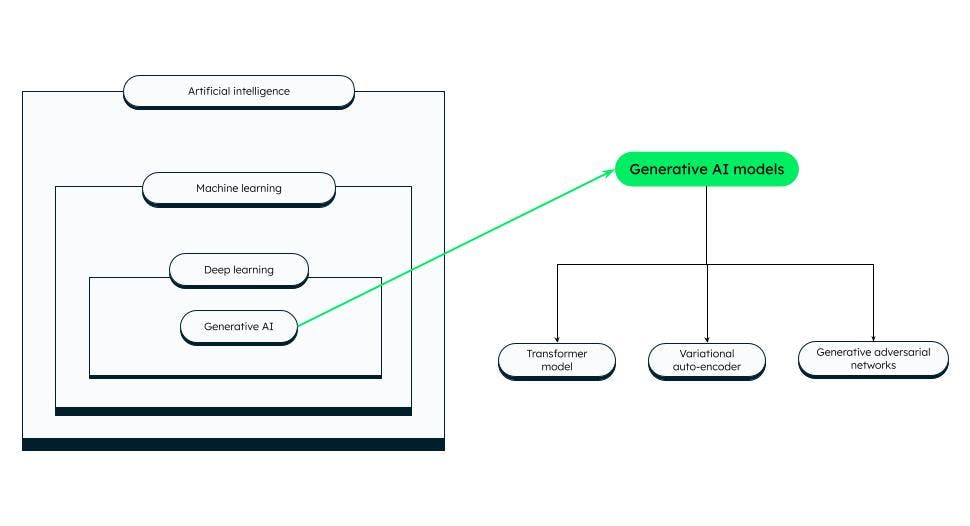 Modelos de IA generativa
Modelos de IA generativa
Existen diferentes categorías de modelos de IA generativa, y algunas de las destacadas son:
Modelo de transformador
Las arquitecturas basadas en transformadores han demostrado ser bastante precisas en la identificación de relaciones contextuales entre palabras (datos). Se utilizan para la generación de texto, la traducción automática y el modelado del lenguaje. Los LLM, como GPT (utilizado en ChatGPT), son un ejemplo de arquitectura de transformadores.
¡Todo lo que necesita es atención!
El modelo transformador trabaja sobre un mecanismo de autoatención, en donde se pesa la importancia de cada elemento en una secuencia de entrada durante el procesamiento del texto, capturando así la información contextual de manera efectiva.
Por ejemplo, si quieres traducir el texto en inglés “Me encanta escribir sobre inteligencia artificial” al español, el modelo transformador pasaría esta secuencia de palabras (tokens) al codificador (red neuronal). Todas las palabras de entrada se convierten paralelamente en una representación vectorial numérica (incrustaciones de palabras), que consiste en los vectores de consulta (la transformación necesaria), la clave (entrada) y el valor (salida).
Por ejemplo, para la palabra “amor” en nuestra oración, tendríamos vectores q_amor, k_amor, y v_amor.
Se crea una matriz con la puntuación de similitud de cada palabra con otra. Por ejemplo, se generaría la similitud de la palabra “amor” con todas las demás palabras de la oración, una puntuación más alta indica más similitud.
El siguiente paso es calcular los pesos de atención que determinan cuánta importancia se le debe dar a cada palabra de la oración en relación a la palabra clave principal (“amor”, en nuestro caso).
Luego, agregue las codificaciones posicionales a las representaciones vectoriales. Las incrustaciones posicionales (similitud + codificación posicional) ayudan al decodificador (otra red neuronal) a decidir el orden en el que deben colocarse los tokens de salida (palabras).
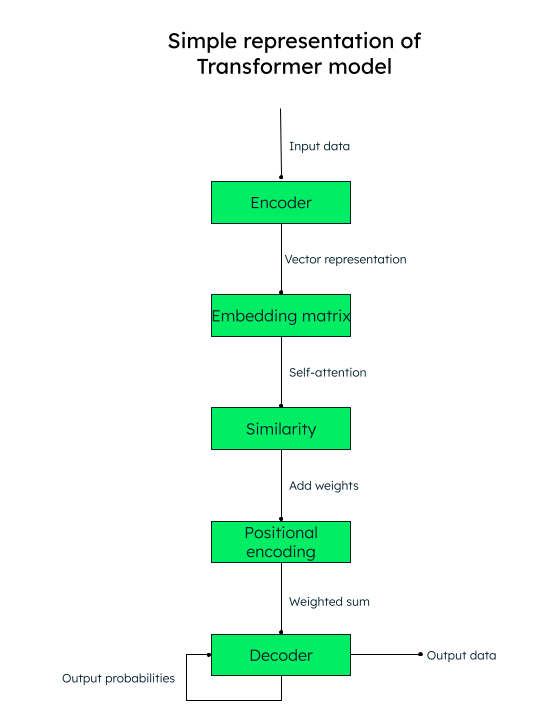
Representación del modelo de transformado
Variational autocodificadores (VAeS)
Los VAE son muy populares para la generación de imágenes, la compresión de datos y la eliminación de emisiones de imágenes. En un VAE, la red neuronal del codificador toma los puntos de datos de entrada y los mapea a una representación espacial latente. Un espacio latente es la representación de datos en una dimensión inferior mediante la extracción de las características más importantes de los datos y el descarte de otras características. La red neuronal decodificador reconstruye los datos de salida basándose en la representación latente.
Redes adversariales generativas (GAN)
Las GAN se utilizan ampliamente para crear imágenes realistas, arte, videos deepfake, traducción de imagen a imagen e imágenes de súper resolución. Una GAN consiste en un generador (red neuronal) que toma ruido aleatorio o semilla como su entrada y crea muestras de datos sintéticos (como una imagen). Las muestras de datos sintéticos son entonces alimentadas a otra red neuronal, Discriminator, que utiliza la clasificación binaria para determinar si las muestras son falsas o reales. A través del entrenamiento adversarial, el generador y el discriminador son entrenados simultáneamente hasta que se alcanza un equilibrio de Nash, donde el generador es capaz de producir datos realistas de alta calidad (como imágenes) y el discriminador los categoriza con precisión como reales o falsos.
Modelo de lenguaje grande (LLM)
Los LLM son un modelo básico que se entrenan con grandes conjuntos de datos y proporcionan una experiencia casi precisa y atractiva para los usuarios. Para poder crear estos modelos, es necesario capturar grandes cantidades de datos de múltiples fuentes, almacenarlos correctamente y procesarlos y recuperarlos en función de la relevancia, cuando sea necesario.
Los LLM se pueden utilizar para la resolución de problemas generales, como responder preguntas, generar texto, clasificar y resumir textos, y ajustar mediante el ajuste y la incitación a entrenar con un conjunto mínimo de datos para resolver problemas específicos.
¿Cómo funciona un LLM?
Los modelos básicos aprenden de los patrones de datos y producen un resultado flexible y generalizable, que luego se puede aplicar a diferentes instancias específicas. Uno de estos casos es el LLM, que se aplica a las entradas basadas en texto.
Los LLM constan de datos, arquitectura y entrenamiento. Por lo general, los datos son petabytes de libros grandes, conversaciones y contenido de texto. La arquitectura es una red neuronal profunda y, en el caso de GPT, es el transformador. Durante el entrenamiento, el modelo aprende a predecir la siguiente palabra de cualquier oración dada.
Sin embargo, hay tres problemas con el LLM:
Si se ha desarrollado o cambiado alguna información después de que el modelo esté completamente entrenado, el modelo no lo sabrá y podría dar resultados obsoletos. Por ejemplo, si le pide al modelo: “Dame una lista de buenas películas de comedia en los últimos 6 meses“, ¡el modelo no podría hacerlo si no se entrenara hace 6 meses!
Es posible que el modelo tenga información incorrecta dentro de su representación interna.
El modelo no puede acceder a sus datos privados y podría presentar información sesgada o incompleta basada en conocimientos limitados.
RAG (Generación aumentada de recuperación)
El marco de IA de RAG tiene como objetivo resolver los problemas anteriores y mejorar la calidad de las respuestas de LLM al proporcionar al modelo una verdad fundamentada en una base de conocimiento externa que complementa la información presentada internamente en el LLM. Esto reduce las posibilidades de que el modelo identifique incorrectamente un patrón u objeto inexistente (alucinaciones) y la información incorrecta, engañosa y desactualizada.
La arquitectura de recuperación utiliza un almacén de vectores y aumenta la capacidad de LLM a través de la búsqueda de vectores.
MongoDB Atlas, la plataforma unificada de datos para desarrolladores, proporciona búsqueda vectorial dentro de la plataforma, que puede configurar en unos sencillos pasos, para mejorar la salida de su LLM y producir resultados más precisos.
Búsqueda de vectores
Aprendimos en la sección anterior sobre el modelo de transformador y que los vectores son representaciones numéricas de datos de texto. Por ejemplo, la representación vectorial de nuestra oración anterior, “Me encanta escribir sobre inteligencia artificial”, podría ser similar a: “Me encanta...” = [0.33, 0.45, 0.72, -0.23,..]
La representación vectorial anterior incluye la relación entre cada palabra, como ser de qué manera la palabra “artificial“ se relaciona con la palabra “inteligencia“ o con la palabra “escribir“, o con qué contexto de la palabra “amor“ es en esta oración.
Estos vectores se generan (como vimos en el modelo de transformador) enviando los datos de entrada a través de una red neural profunda (codificador).
En realidad, las representaciones vectoriales pueden tener cualquier cantidad de dimensiones. Cuantos más parámetros tengan los datos, más dimensiones tendrán. Para poder dar sentido a estos números y entender lo que ocurre después de que se generen estos vectores, tracemos un gráfico en dos dimensiones para facilitar la comprensión.
Todos los vectores se trazan según su representación numérica. Tenga en cuenta que las incrustaciones de palabras (vectores) que tienen un significado similar se trazarán cerca unas de otras, formando así un clúster.
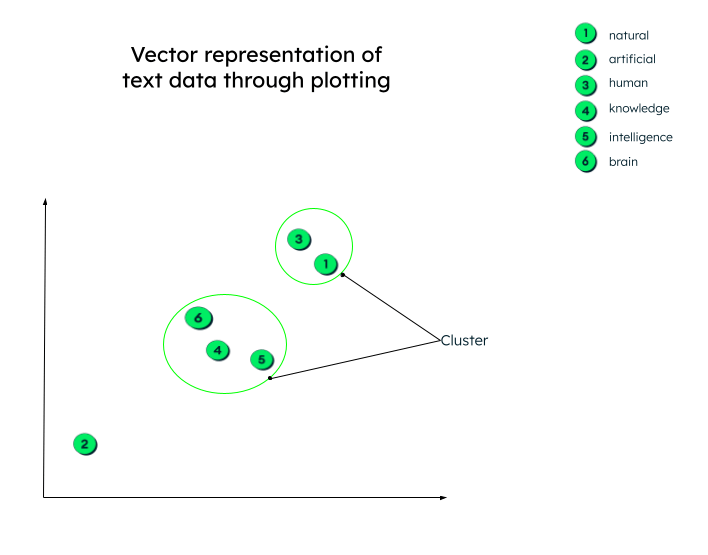 Representación gráfica de vectores
Representación gráfica de vectores
Puede haber muchos contextos en los que se pueden agrupar los datos. La relación depende de cómo el codificador incrusta los datos de origen y de cómo se calcula la distancia entre los vectores. En el siguiente ejemplo, se pueden establecer dos tipos de relaciones:
- Tanto el gato como el perro son animales domésticos, mientras que el tigre y el lobo son animales salvajes.
- Gato y tigre pertenecen a la misma familia, mientras que perro y lobo pertenecen a la misma familia de animales.
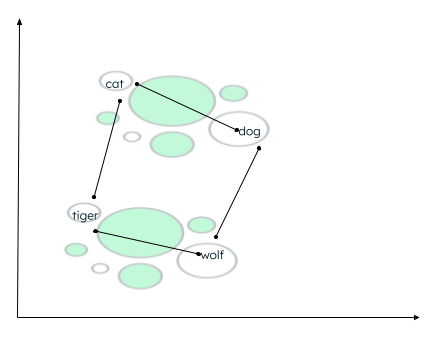
Cálculo de distancia de palabras similares
Una función de similitud determina qué palabras están más cerca y etiqueta las palabras colocadas cerca como vecinas. Esta agrupación/clúster se realiza utilizando el algoritmo de k-vecino más cercano, donde el valor de k representa el número de vecinos que se identificarán. Para encontrar la similitud, la búsqueda vectorial admite muchos métodos, como encontrar lo siguiente:
- Distancia euclidiana entre los extremos de los dos vectores.
- Coseno (ángulo) entre los dos vectores.
- Punto (escalar) producto de los vectores.
MongoDB Atlas proporciona las funciones de búsqueda vectorial dentro de la propia plataforma Atlas, a través de marcos de IA, y admite todas las funciones de similitud anteriores.
MongoDB Atlas Vector Search
MongoDB siempre ha admitido la búsqueda vectorial en dos dimensiones. Sin embargo, la nueva búsqueda de vectores permite capacidades poderosas debido a la integración y permite dimensiones más altas. Las aplicaciones pueden escribir los datos, así como las incrustaciones vectoriales en la base de datos. Los vectores de datos se generan utilizando un modelo de codificador. La búsqueda en Atlas utiliza el algoritmo de vecino más cercano (ANN) aproximado a través del gráfico de Pequeño mundo navegable jerárquico (HNSW). ANN es una variación del k-vecino más cercano, pero con una mayor velocidad de recuperación.
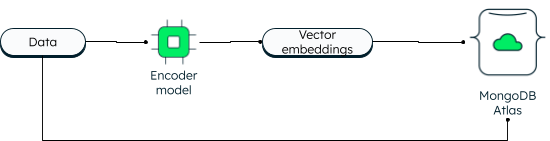
Cómo se almacenan los vectores en MongoDB Atlas
Durante la lectura, la consulta se codifica y se envía en la etapa de agregación '$search' junto con el vector de destino. Si desea aprender los pasos, siga el tutorial sobre creación de aplicaciones de IA generativa con MongoDB.
La ventaja de tener vectores junto a los datos operativos es que puede acceder a toda la información dentro de una única plataforma, incluso a sus datos privados, a los que no se podría acceder de otra manera.
La búsqueda vectorial de Atlas simplifica la arquitectura de su aplicación. Como Atlas está totalmente administrado, la plataforma MongoDB Atlas se encarga de todo, desde la sincronización de datos hasta la seguridad y la privacidad. Los desarrolladores pueden trabajar con la base de datos y la búsqueda vectorial utilizando la API de consulta de MongoDB unificada. Puede implementar Atlas en más de 125 regiones en tres importantes proveedores de cloud. Atlas le proporciona un tiempo de actividad continuo con una automatización avanzada que garantiza un alto rendimiento independientemente de la escala de la aplicación.
Algunos casos de uso destacados de la búsqueda vectorial en Atlas son:
- Búsqueda semántica.
- Sistemas de preguntas y respuestas.
- Extracción de características.
- Recomendación y puntuación de relevancia.
- Generación de sinónimos.
- Búsqueda de imágenes.
¿Cómo funciona la búsqueda de vectores Atlas?
La aplicación del cliente envía los datos sin procesar. El modelo de incrustación vectorial crea vectores para cada texto de la consulta inicial (datos sin procesar). Frameworks como Llamaindex y LangChain se integran bien con MongoDB Atlas para crear incrustaciones y enviar datos a MongoDB para agregar conciencia contextual. La consulta consciente del contexto, conocida como mensaje, se envía entonces a un LLM, que genera una respuesta codificada, para ser procesada por el modelo de incrustación vectorial (decodificador) y enviada al cliente tras la decodificación.
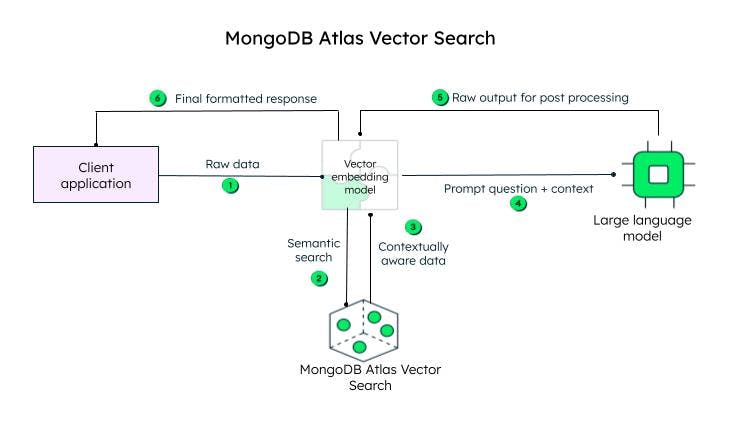 Pasos para lograr la búsqueda vectorial en MongoDB Atlas
Pasos para lograr la búsqueda vectorial en MongoDB Atlas
Las incrustaciones vectoriales pueden almacenarse en el documento de base de datos MongoDB como una selección de matrices, junto con el contenido, en el campo content_embeddings.
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... other fields......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]Si el número de dimensiones de los datos de entrada es mayor, el número de puntos flotantes será mayor.
A continuación, defina la definición de índice agregándola al generador de definiciones:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}La definición del índice incluye el modelo que encontraría los clústeres de similitud, las dimensiones y la función de similitud (de los tres métodos admitidos por MongoDB) que utilizaría el modelo.
¡Eso es todo! Solo dos pasos y listo.
Para poder buscar, puede utilizar el operador de agregación '$search' especificando el operador 'knnBeta' y dando las incrustaciones vectoriales de la consulta en el campo 'vector'. También debe especificar la “ruta“ de las incrustaciones de contenido que se deben tener en cuenta para la búsqueda vectorial. MongoDB también proporciona “filtros“ adicionales para reducir la búsqueda y el número de vecinos más cercanos que debe devolver el algoritmo de k-vecino más cercano.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Dado que tanto las incrustaciones de vectores como los datos residen en la misma plataforma, puede acceder a la carga de trabajo operativa y a los vectores mediante una única API de consulta de MongoDB unificada. Para aprender a usar la funcionalidad paso a paso, consulte nuestro tutorial sobre cómo crear aplicaciones de IA generativa usando la búsqueda de vectores.
Casos de uso de IA importantes
La IA se está aplicando con éxito en diversos ámbitos, como el comercio minorista, la salud y la industria de fabricación. Algunos casos de uso populares de la IA son:
Procesamiento del lenguaje natural (PLN): la IA se utiliza activamente en el análisis de sentimientos, los asistentes virtuales, los chatbots, el reconocimiento de voz y la traducción de textos. Como hemos visto anteriormente, utilizando el poder de LLM y la búsqueda vectorial, los sistemas de IA pueden producir resultados en lenguaje humano.
Visión artificial: con las redes neuronales modernas, los sistemas de IA son capaces de realizar con precisión la clasificación de imágenes, el reconocimiento de rostros y objetos, y la generación de imágenes.
Sistemas de recomendación y filtrado de contenidos: los sistemas de IA son capaces de recomendar contenidos a los usuarios utilizando modelos de aprendizaje profundo y aprendizaje automático sin ninguna intervención humana.
Cuidado de la salud: la tecnología de inteligencia artificial ha llevado la atención médica a un nuevo nivel al ayudar a los médicos en el diagnóstico temprano de enfermedades, la investigación médica y el descubrimiento de fármacos, y al almacenamiento seguro de los registros médicos electrónicos de los pacientes.
Autos autónomos: los autos autónomos funcionan con algoritmos de IA, datos de sensores y visión artificial.
Robótica: los robots industriales aumentan la productividad y realizan tareas complejas con precisión. De manera similar, los robots de servicios pueden realizar sus tareas de manera eficiente en los ámbitos de la salud y y la industria hotelera.
Uso ético de la IA, gobernanza de la IA y regulaciones
Con los rápidos desarrollos que se están produciendo en el campo de la IA, es importante establecer normas y reglamentos y abordar las consideraciones éticas para que los sistemas de IA se utilicen de forma justa, transparente y para el fin adecuado. La ética de la IA se centra en las implicaciones morales y éticas de las herramientas y tecnologías de IA, es decir, la equidad, la privacidad, la transparencia y la rendición de cuentas.
El gobierno establece los marcos, la estructura y las reglas de cumplimiento para garantizar el uso responsable de la IA.
El gobierno también crea regulaciones de IA, es decir, marcos legales, para garantizar que se cumplan la seguridad de los datos, la protección del consumidor y los estándares de seguridad.
Herramientas y servicios de IA
Los datos son el núcleo de todas las operaciones de IA, y MongoDB es una plataforma en la que puede confiar para crear sólidas aplicaciones de IA. Como base de datos con un esquema flexible, MongoDB proporciona una solución de almacenamiento centralizada, con capacidades de administración de datos integradas, procesamiento de datos avanzado, análisis en tiempo real, escalabilidad y mucho más. Algunas otras herramientas y servicios populares son: ChatGPT: ChatGPT casi se ha convertido en parte de la vida cotidiana para hacer preguntas simples con el fin de planificar vacaciones, programar, escribir poesía, resumir textos y mucho más.
Dall-E 2: Dall-E 2 es un proyecto de OpenAI, al igual que ChatGPT, y genera gráficos por computadora como imágenes, pinturas y dibujos a partir de indicaciones de texto.
Stable Diffusion 2: se trata de una herramienta de IA de texto a imagen para aplicaciones de IA generativa. A diferencia de las herramientas de OpenAI, a las que se accede a través de portales de navegadores, Stable Diffusion 2 está disponible para su descarga e instalación, y los usuarios pueden acceder al código fuente y a los algoritmos públicamente.
Preguntas frecuentes
¿Qué es la inteligencia artificial (IA)?
La capacidad de las máquinas para pensar, aprender y tomar decisiones, como un ser humano, cuando se enfrentan a diferentes escenarios, se conoce como inteligencia artificial.
¿Cómo funciona la IA?
La inteligencia artificial (IA) incluye el aprendizaje automático y el aprendizaje profundo, los cuales consisten en varios algoritmos para atender los diferentes casos de uso. Estos algoritmos trabajan con grandes cantidades de datos recopilados de diversas fuentes, clasificados, transformados y preprocesados para alimentar los algoritmos. Los algoritmos utilizan datos para entrenar, obtener retroalimentación y optimizarse hasta lograr un resultado deseable.
¿Por qué es importante la inteligencia artificial?
[La IA es importante] (#casos-de-uso-de-ia-importantes), ya que puede permitir la automatización de tareas mundanas y repetitivas, mejorar la eficiencia, reducir los errores humanos, proporcionar análisis predictivos para una toma de decisiones más rápida y precisa, proporcionar recomendaciones personalizadas para los usuarios, ayudar en el diagnóstico de enfermedades, acelerar la investigación en medicina y ciencia, y promover la innovación.
¿Cuándo se inventó la IA?
¿Cuáles son los tipos de IA?
¿Cuál sería un ejemplo de inteligencia artificial?
El ejemplo más reciente y popular de la IA es ChatGPT, que puede responder a las preguntas que hacen los humanos ya que escribe con una respuesta similar a la humana. También puede recordar el contexto de la conversación. ChatGPT está entrenado en un modelo de lenguaje grande y enriquecido aún más por la ampliación. MongoDB Atlas ofrece una gran plataforma para crear poderosas aplicaciones generativas de IA utilizando cualquier proveedor de cloud importante.