A inteligência artificial (IA) pode ser definida como a capacidade das máquinas de pensar de forma racional, resolver problemas e tomar decisões sem a supervisão de uma mente humana.
Com o surgimento das tecnologias de aprendizado de máquina e aprendizado profundo, as máquinas são capazes de “pensar“ e “aprender“ com base nos dados fornecidos a elas e realizar tarefas que antes só poderiam ser feitas por humanos. Neste artigo, vamos explorar mais sobre inteligência artificial, IA generativa e como o MongoDB está mudando a face da IA generativa ao simplificar o processamento de IA, possibilitar buscas baseadas em contexto e aprimorar a precisão de grandes modelos de linguagem (LLMs).
Tabela de conteúdos
- Inteligência artifical (IA) explicado
- Como a IA é semelhante à inteligência humana
- IA vs. Aprendizado de Máquina
- Deep learning
- História da inteligência artificial
- Tipos de IA
- Modelos de base
- IA Generativa
- Modelo de Linguagem Grande (LLM)
- Vector Search
- MongoDB Atlas Vector Search
- Como funciona a pesquisa Atlas Vector?
- Casos de uso importantes da inteligência artificial
- Uso ético da IA, governança da IA e regulamentações
- Ferramentas e serviços de IA
- Perguntas e Respostas
A Inteligência Artificial (IA) explicodo
A Inteligência Artificial é um campo da ciência da computação que capacita máquinas a realizar raciocínio, tomadas de decisão inteligentes e análise de dados em uma escala que se percebe ultrapassar a compreensão e capacidades humanas.
A IA inclui campos como ciência de dados, estatística, neurociência e aprendizado de máquina, que inclui ainda aprendizado profundo, no qual nossos algoritmos modernos se baseiam.
Esses algoritmos são a base para a IA tomar decisões semelhantes às humanas ao compreender dados em padrões e realizar tarefas difíceis com facilidade e precisão.
Alguns exemplos populares de sistemas de inteligência artificial incluem o ChatGPT, assistentes virtuais como Alexa e Siri, carros autônomos e motores de recomendação.
Como a IA é semelhante à inteligência humana
O cérebro humano funciona de forma complexa. Nós pensamos, agimos e tomamos decisões com base em nossas experiências passadas e memórias, derivando padrões com base em nosso entorno e situações. Em um período de tempo, o que observamos é o que o cérebro percebe como verdadeiro. Por exemplo, se sempre vemos uma rosa vermelha, nosso cérebro processa que a rosa é vermelha e tem uma determinada forma e tamanho. Se lemos ou ouvimos que rosas também podem ser amarelas ou rosas, com base em nosso conhecimento prévio de uma rosa vermelha, imaginamos que uma rosa amarela ou rosa se assemelhe, de certa forma, a uma rosa vermelha.
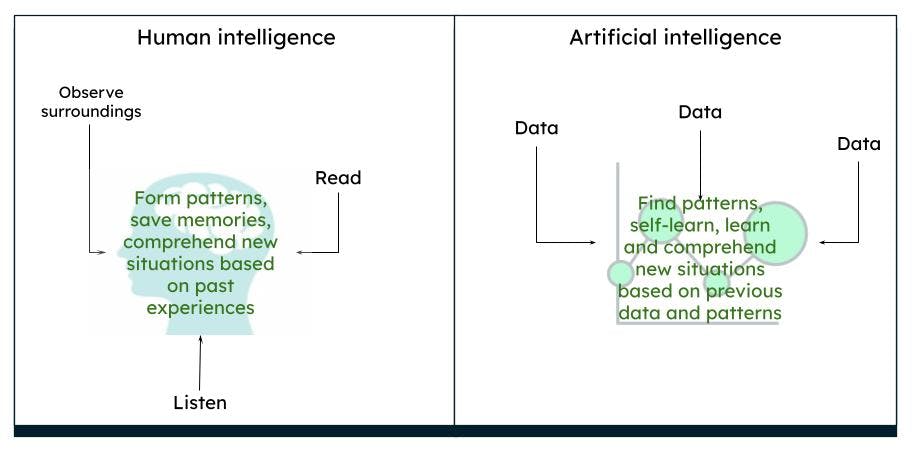 Representação da inteligência humana versus inteligência artificial
Representação da inteligência humana versus inteligência artificial
A IA funciona da mesma forma. Quando um computador é alimentado com dados suficientes, as máquinas são capazes de derivar certos resultados, com base nos padrões dos dados, por meio de algoritmos. Por exemplo, se você alimentar dados sobre rosas e cores, da próxima vez que o computador encontrar um objeto semelhante, ele pode ser identificado como uma rosa de uma cor específica.
IA vs. aprendizado de máquina
IA é um termo mais amplo que consiste em teorias e sistemas para construir máquinas que executam tarefas que requerem inteligência. Machine Learning é um ramo da IA que se concentra na análise de dados, buscando padrões e orientando decisões por meio de vários algoritmos, sem a necessidade de programação explícita. As técnicas de aprendizado de máquina consistem em métodos supervisionados, não supervisionados e de aprendizado por reforço.
Deep learning
Deep learning é um subconjunto do aprendizado de máquina que se assemelha à inteligência humana. Os modelos de deep learning consistem em redes neurais profundas artificiais, ou seja, neurônios (ou nós) interconectados e possuem muitas camadas, permitindo-lhes processar padrões de dados mais complexos do que os algoritmos de aprendizado de máquina. LLMs e IA generativa são subconjuntos de aprendizagem profunda. Existem muitas redes neurais artificiais que podem ser usadas para tarefas específicas.
Todas essas redes neurais são baseadas em um “perceptron“, que é a rede neural mais básica usada para classificação binária. Perceptron consiste em uma única camada de neurônios que utiliza uma camada de entrada, aplica pesos e a alimenta na camada de saída.
Feedforward neural network (FNN)
Feedforward é uma das primeiras redes neurais artificiais desenvolvidas e consiste em um grupo de vários perceptrons em cada camada. Também é conhecido como perceptron multicamadas (MLP). Ele só alimenta as informações em uma direção — ou seja, na direção para frente — e não há loops. As redes neurais diretas têm entrada, saída e uma camada oculta que processa a entrada. Os FNNNs são usadas para aprendizado supervisionado, quando os dados não são dependentes do tempo ou sequenciais.
Redes neurais convolucionais (CNN)
CNNs são um tipo de FNN e são utilizadas para tarefas complexas de classificação de imagens, visão computacional, análise de imagens e processamento de linguagem natural. Uma CNN analisa um patch de imagem por vez e avança com um menor número de parâmetros por vez para aprender/extrair as características mais importantes. A extração de recursos é feita usando kernels durante uma operação de convolução.
Redes neurais recorrentes (RNN)
RNNs são mais adequadas para dados sequenciais, onde a ordem de entrada é crucial. A informação sequencial é capturada através de um loop na camada de entrada. RNNs são mais adequados para time-series e processamento de linguagem natural. As unidades de memória de longo prazo (LSTMs) são tipos de RNN, que possuem células de memória para armazenar dependências dos dados sequenciais. LSTMs são muito bons em reconhecimento de fala, análise de sentimentos e tradução.
Autoencoder
Autoencoders consistem em um codificador e um decodificador. Os codificadores comprimem as dimensões dos dados para um espaço dimensional inferior (espaço latente). Os decodificadores reconstroem os dados de entrada usando o espaço latente. Os codificadores podem ser usados para remoção de ruído, redução de dimensionalidade e aprendizado de características.
Redes de autoatenção (SANs)
A arquitetura codificador-decodificador pode lembrar sequências mais curtas. No entanto, pode esquecer algumas informações (particularmente as informações recebidas primeiro) em uma longa sequência. Com um mecanismo de atenção, o decodificador pode atender a toda a sequência e usar o contexto da sequência inteira para produzir a saída. A autoatenção permite que todo o texto de entrada seja processado de uma vez e cria relações entre todas as palavras na sequência inteira. Devido a esse recurso, a autoatenção funciona mais rapidamente do que uma RNN ou CNN para dependências de longo alcance.
History de inteligência artificial
Embora as primeiras concepções tenham começado já em 750 a.C. através de livros e ideias baseadas em ficção científica e máquinas pensantes, os primeiros fundamentos para redes neurais foram estabelecidos em 1947 por Walter Pitts e Warren McCulloch, que criaram um modelo computacional para a arquitetura de redes neurais.
Em 1950, Alan Turing introduziu o teste de Turing, para definir a inteligência da máquina.
O termo inteligência artificial foi cunhado em 1956, quando John McCarthy organizou um workshop de IA e definiu o termo como a ciência e engenharia de tornar as máquinas inteligentes. Por volta do início da década de 1960, Frank Rosenblatt desenvolveu o primeiro computador, o Perceptron, que aprenderia por tentativa e erro. Mais tarde, em 1963, John McCarthy fundou o laboratório de IA.
O próximo grande avanço em IA veio por meio dos sistemas especialistas, sistemas computacionais baseados em conhecimento que podiam emular as capacidades de tomada de decisão de um especialista humano. Esses sistemas foram formas bastante bem-sucedidas de IA e foram utilizados em cuidados de saúde, simuladores de combate e treinamento, e auxílios à gestão de missões.
Na década de 1980, a inteligência artificial se tornou uma indústria, e bilhões de dólares foram investidos em sistemas especialistas, sistemas de visão e robótica.
Em 1997, o desenvolvimento do Deep Blue, o computador de xadrez da IBM que derrotou o então campeão mundial de xadrez, criou um interesse adicional em inteligência artificial, e foram observados desenvolvimentos rápidos no campo.
Por volta de 2010, pesquisadores trabalhando em tradução de linguagem natural descobriram que, em comparação com modelos com sistemas baseados em regras, os modelos alimentados com grandes quantidades de dados de texto diversificado produziram resultados muito melhores.
Em 2011, ocorreu o lançamento de assistentes pessoais como Cortana, Siri e Alexa, que podiam responder perguntas por meio de processamento de linguagem natural e realizar tarefas.
Em 2014, os modelos de linguagem começaram a compreender o contexto em que uma palavra aparecia. Trabalhos posteriores resultaram em modelos de linguagem gerais que forneceram modelos base ou fundamentais que poderiam ser adaptados para um caso de uso ou domínio específico.
Esses modelos de base nos levaram à IA generativa e aos modelos de linguagem grande (LLMs) como o ChatGPT.
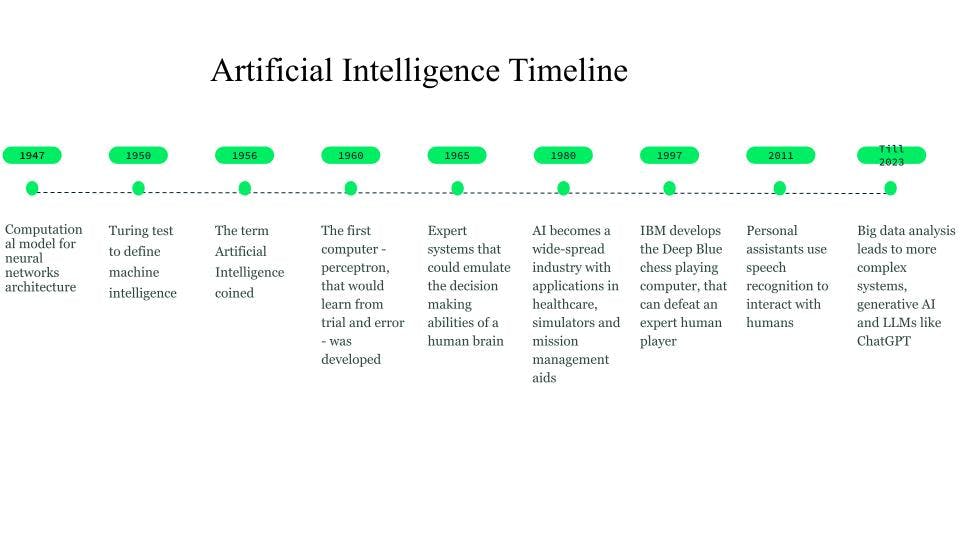 History e cronograma de AI
History e cronograma de AI
Tipos de IA
Uma classificação ampla da inteligência artificial, com base em sua capacidade, é a IA estreita (ou fraca) e a IA forte. Por meio de pesquisas e avanços no campo da aprendizagem de máquina, da aprendizagem profunda e da IA, estamos passando da IA fraca para a IA forte.
A IA estreita
IA fraca/AI estreita, ou Inteligência Artificial Estreita (IAN), são sistemas treinados para executar tarefas específicas e têm capacidades limitadas com base nos dados nos quais são treinados. Eles também são conhecidos como sistemas de IA tradicionais, nos quais o sistema pode responder de maneira inteligente com base em um determinado conjunto de entradas e regras. Entretanto, ele não pode criar nada novo.
As IAs tradicionais ou fracas são ainda classificadas em duas categorias: máquinas reativas e memória limitada.
Máquinas reativas
A forma mais antiga de inteligência artificial eram as máquinas reativas, que não tinham memória. No entanto, eles podem emular a capacidade humana de responder a diferentes estímulos. Eles não podem aprender com a experiência (sem memória), e baseiam suas respostas em uma combinação limitada de entradas. A máquina Deep Blue da IBM é uma máquina reativa.
AI de memória limitada
Os sistemas de memória limitada possuem memória e podem aprender e tomar decisões com base nos dados de entrada fornecidos. A maioria das IA que vemos, como carros autônomos, chatbots, assistentes pessoais como Alexa e sistemas de recomendação como o da Netflix, são todos exemplos de IA com memória limitada.
A IA forte
Com a inovação do ChatGPT e outros modelos de IA generativa semelhantes, estamos entrando lentamente na fase de IA forte. A IA generativa é um tipo de IA de última geração, que pode criar algo novo com base nas entradas do usuário. O ChatGPT é um exemplo de IA generativa baseada no modelo de linguagem grande (LLM). Muito mais trabalho precisa ser feito em IA forte, que pode ser categorizada da seguinte forma:
Theory of mind (ToM)
ToM é uma habilidade cognitiva para entender os diferentes estados mentais, como crenças, pensamentos e sentimentos dos outros, a fim de explicar seu comportamento e ações. Pesquisadores estão trabalhando na aplicação de ToM à IA com o objetivo de permitir que os sistemas de IA entendam as emoções humanas e o estado mental. O ChatGPT, o novo sistema de IA que pode interagir com humanos em linguagem natural e produzir novo conteúdo, demonstrou algum tipo de teoria da mente durante os testes. Entretanto, ainda não possui a capacidade de compreender desejos, crenças ou emoções. As respostas do ChatGPT são baseadas em dados e padrões comuns.
Inteligência geral artificial (AGI)
A inteligência artificial geral é a próxima etapa do desenvolvimento da IA, na qual um sistema ou agente de IA se comportará exatamente como um humano, incluindo a construção independente de várias competências e funcionalidades, formando conexões e generalizações, com pouco ou nenhum treinamento.
Self-aware
A próxima etapa é um ponto de singularidade da IA, onde as máquinas estarão conscientes de si mesmas. Elas terão seus próprios desejos, crenças e emoções, além de compreender as emoções, desejos e crenças dos humanos. Agentes autoconscientes podem ser utilizados na área da saúde e na robótica, e mostram-se mais poderosos e precisos na realização de tarefas quando comparados aos humanos.
Superinteligência artificial (ASI)
A IA autoconsciente pode levar à ASI, onde agentes de IA podem se tornar superinteligentes e superar os humanos em valores e motivações. A conscientização de IA e ASI pode levantar problemas com o emprego, bem como questões éticas, para os quais pesquisadores e governos precisam estar atentos e estabelecer regras e diretrizes. Entretanto, essas são metas rebuscadas e podem levar décadas para serem alcançadas.
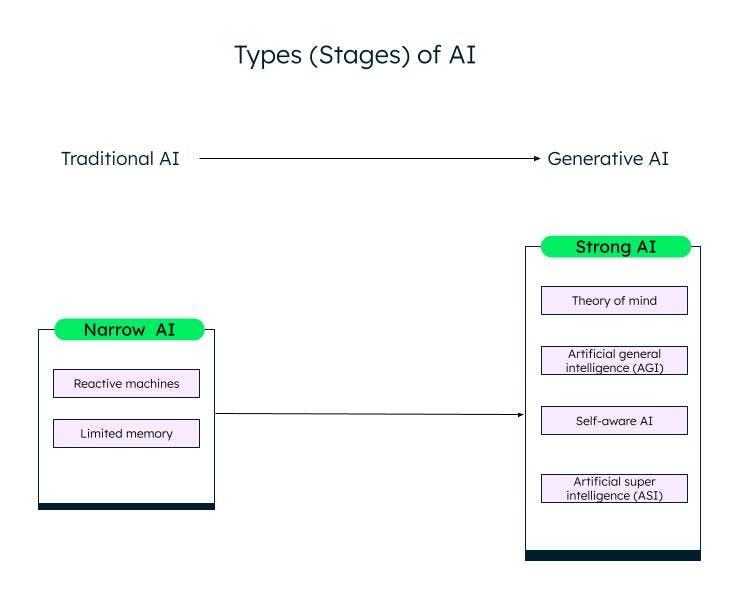 Different stages (types) of AI
Different stages (types) of AI
Os modelos de base
Os modelos de base são redes neurais profundas artificiais generalizadas treinadas com grandes quantidades de dados não estruturados. Eles são construídos para servir como modelos de finalidade geral. Podemos criar modelos mais específicos para tarefas de IA e aprendizado de máquina personalizando esses modelos de base (fundamentais) pré-treinados.
Por exemplo, um modelo de base como o modelo de linguagem grande (LLM) treinado em dados de texto pode ser utilizado para uma variedade de tarefas, como recuperação de informações e perguntas e respostas. O transformador pré-treinado generativo ou GPT (no qual o famoso ChatGPT é baseado) e o BERT (representações de codificador bidirecional de transformadores) são exemplos de modelos de base LLM. A ResNet (rede residual) é um tipo popular de modelo de base para visão computacional usado em classificação de imagens e tarefas de visão computacional. Os modelos de base são muito adaptáveis e podem ser autossupervisionados e improvisados por meio de prompts e ajustes finos.
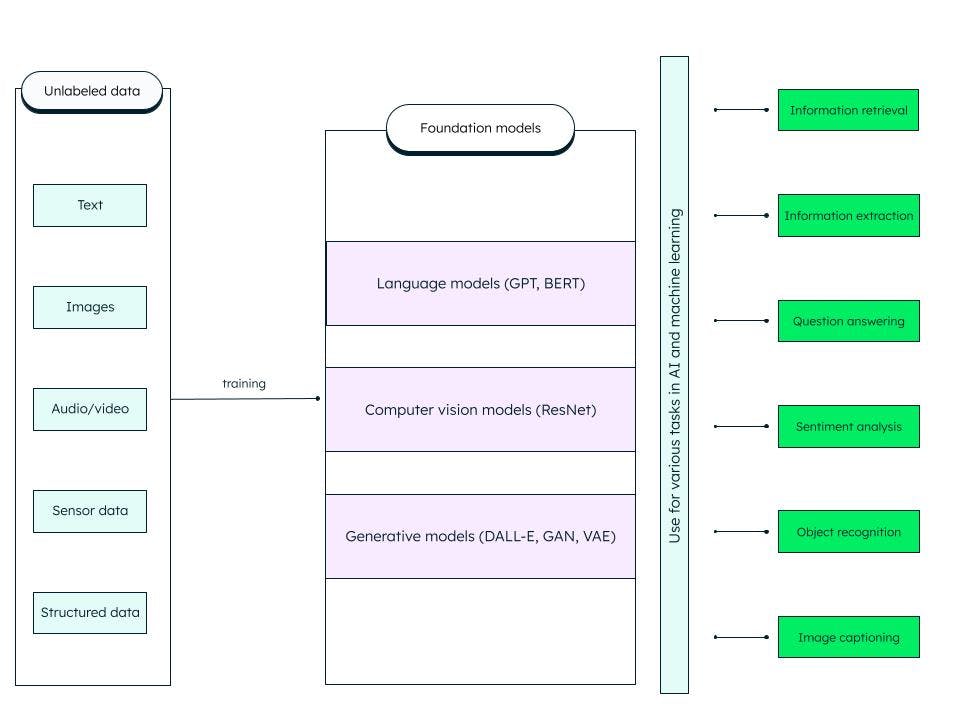 O que o modelo de fundação inclui?
O que o modelo de fundação inclui?
Generative IA
As tecnologias de IA podem produzir novos conteúdos, como imagens, vídeos, áudios, textos e praticamente qualquer outra coisa – essa IA que é capaz de gerar conteúdo é chamada de IA generativa!
A IA generativa é baseada em modelos de base que podem realizar tarefas como classificação, preenchimento de frases, geração de imagem ou voz, e dados sintéticos (gerados artificialmente). Os modelos de base são ajustados para se adequarem à tarefa geradora específica em questão.
O sucesso de um modelo de IA generativa depende da qualidade e diversidade dos dados, bem como da velocidade de geração.
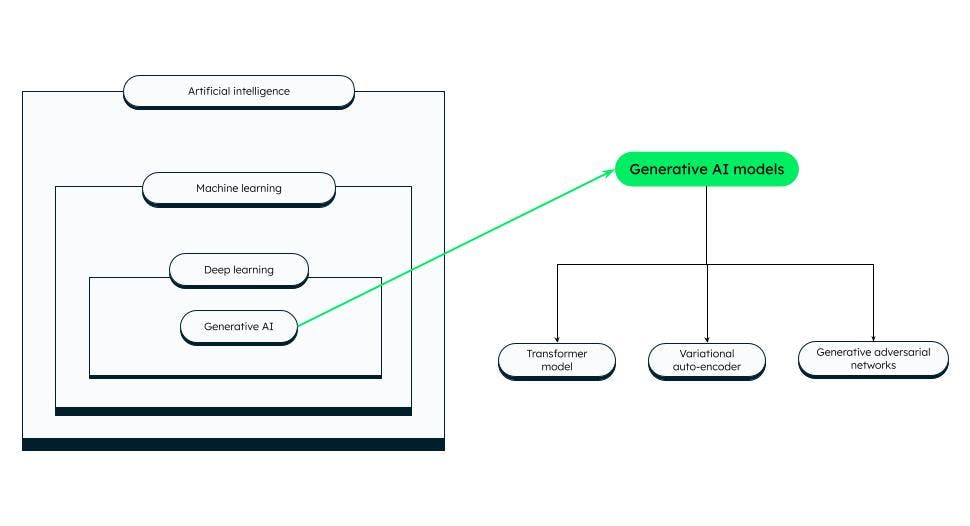 Generative models de IA
Generative models de IA
Existem diferentes categorias de modelos de IA generativa, das quais algumas proeminentes são:
Modelo Transformer
As arquiteturas baseadas em transformadores têm se mostrado bastante precisas na identificação de relações contextuais entre palavras (dados). Eles são usados para geração de texto, tradução automática e modelagem de linguagem. LLMs, como GPT (usado no ChatGPT), são um exemplo de arquitetura de transformador.
Atenção é tudo que você precisa!
O modelo de transformador opera com um mecanismo de autoatenção, no qual a importância de cada elemento em uma sequência de entrada é ponderada durante o processamento de texto, capturando assim as informações contextuais de forma eficaz.
Por exemplo, se você quiser traduzir o texto em inglês “I love to write about artificial intelligence“ para o espanhol, o modelo de transformador passaria esta sequência de palavras (tokens) para o codificador (rede neural). As palavras de entrada são todas convertidas paralelamente em uma representação vetorial numérica (embeddings de palavras), consistindo nos vetores de consulta (a transformação necessária), chave (entrada) e valor (saída).
Por exemplo, para a palavra “love“ em nossa frase, teríamos vetores qlove, klove e v_love.
Uma matriz é criada com a pontuação de similaridade de cada palavra com outra. Por exemplo, a similaridade da palavra “love“ com todas as outras palavras da frase seria gerada, onde um escore mais alto indica mais similaridade.
O próximo passo é calcular os pesos de atenção que determinam quanto importância deve ser dada a cada palavra na frase em relação à palavra-chave principal (“love“, no nosso caso).
Em seguida, adicione as codificações posicionais às representações vetoriais. Os embeddings posicionais (similaridade + codificação posicional) ajudam o decodificador (outra rede neural) a decidir a ordem na qual os tokens de saída (palavras) devem ser colocados.
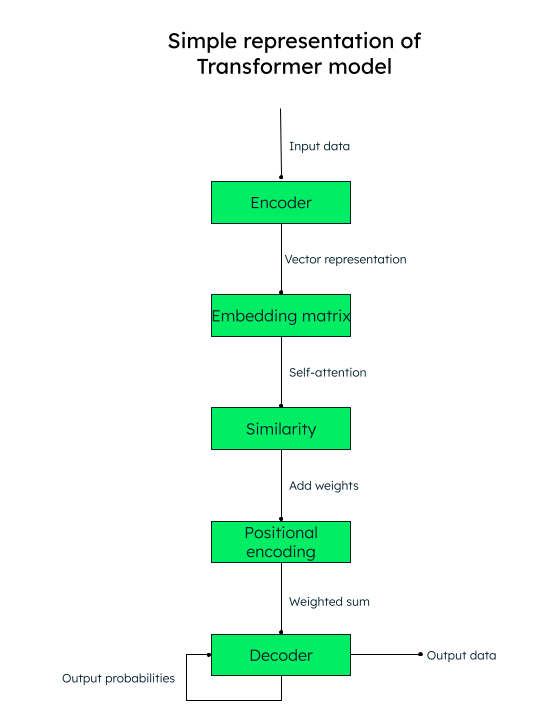
Representação do modelo do transformador
Codificadores automáticos variacionais (VAEs)
VAEs são bastante populares para geração de imagens, compactação de dados e remoção de ruído de imagens. Em um VAE, a rede neural do codificador pega os data points de entrada e os mapeia para uma representação de espaço latente. Um espaço latente é a representação de dados em uma dimensão inferior, através da extração das características mais importantes dos dados e descarte de outras características. A rede neural do decodificador reconstrói os dados de saída com base na representação latente.
Redes geradoras adversárias (GANs)
As GANs são amplamente utilizadas para criar imagens realistas, arte, vídeos deepfake, tradução de imagem para imagem e imagens de super resolução. Uma GAN consiste em um gerador (rede neural) que recebe ruído aleatório ou uma semente como entrada e cria amostras de dados sintéticas (como uma imagem). As amostras de dados sintéticos são então alimentadas em outra rede neural, o Discriminador, que utiliza classificação binária para determinar se as amostras são falsas ou reais. Através do treinamento adversário, o gerador e o discriminador são treinados simultaneamente até que um equilíbrio de Nash seja alcançado, onde o gerador é capaz de produzir dados realistas de alta qualidade (como imagens) e o discriminador categoriza com precisão se são reais ou falsos.
Modelo de linguagem grande (LLM)
LLMs são um modelo básico que treina em grandes conjuntos de dados e fornece uma experiência quase precisa e envolvente para os usuários. Para poder construir tais modelos, é necessário capturar grandes quantidades de dados de múltiplas fontes, armazená-los corretamente e processá-los e recuperá-los com base na relevância, quando necessário.
LLMs podem ser utilizados para solução de problemas em geral, como responder perguntas, geração de texto, classificação e sumarização de texto, e ajuste fino utilizando ajuste e indução para treinar em um conjunto mínimo de dados para solucionar problemas específicos.
Como funciona um LLM?
Os modelos de base aprendem a partir de padrões nos dados e produzem uma saída flexível e generalizável, que pode ser então aplicada a diferentes instâncias específicas. Um desses exemplos é o LLM, que é aplicado para entradas baseadas em texto.
LLMs consistem em dados, arquitetura e treinamento. Os dados geralmente são petabytes de grandes livros, conversas e conteúdo de texto. A arquitetura é uma rede neural profunda e, no caso do GPT, é o transformador. Durante o treinamento, o modelo aprende a prever a próxima palavra de qualquer sentença fornecida.
Porém, existem três problemas com o LLM:
Se alguma informação for desenvolvida ou alterada após o modelo estar completamente treinado, o modelo não terá conhecimento disso e poderá fornecer resultados desatualizados. Por exemplo, se você perguntar ao modelo: “Dê-me uma lista de bons filmes de comédia nos últimos 6 meses“, o modelo não será capaz de fazer isso se não tiver sido treinado há 6 meses!
O modelo pode conter informações incorretas em sua representação interna.
- O modelo não pode acessar seus dados privados e pode apresentar informações tendenciosas ou incompletas com base em conhecimento limitado.
Geração de aumento de recuperação (RAG)
O framework de IA RAG visa resolver os problemas mencionados e melhorar a qualidade das respostas do LLM, fornecendo ao modelo uma base de conhecimento externa que complementa as informações internas apresentadas no LLM. Isso reduz as chances de o modelo identificar incorretamente um padrão ou objeto inexistente (alucinações), além de informações incorretas, enganosas e desatualizadas.
A arquitetura de recuperação usa um armazenamento de vetores e aumenta a capacidade do LLM por meio de pesquisa vetorial.
Atlas MongoDB, a plataforma unificada de dados do desenvolvedor fornece vector search dentro da plataforma, que você pode configurar em alguns passos simples para aprimorar a saída do seu LLM e produzir resultados mais precisos.
Vector pesquisa
Aprendemos na seção anterior sobre o modelo de transformador e que vetores são representações numéricas de dados de texto. Por exemplo, a representação vetorial da nossa frase anterior, “Eu adoro escrever sobre inteligência artificial“, poderia ser semelhante a: “Eu adoro... “ = [0,33, 0.45, 0.72, -0.23.....]
A representação vetorial acima inclui a relação entre cada palavra, como a palavra “artificial“ se relaciona com a palavra “inteligência“ ou com a palavra “escrever“, ou qual é o contexto da palavra “amor“ nesta frase.
Esses vetores são gerados (como vimos no modelo de transformer) ao enviar os dados de entrada através de uma rede neural profunda (codificador).
Na realidade, as representações vetoriais podem ter qualquer número de dimensões. Quanto mais parâmetros os dados tiverem, mais dimensões eles terão. Para compreender esses números e entender o que acontece após a geração desses vetores, vamos visualizá-los em um gráfico bidimensional para facilitar a compreensão.
Todos os vetores são plotados de acordo com sua representação numérica. Observe que as incorporações de palavras (vetores) que têm significado semelhante serão plotadas próximas umas das outras, formando assim um cluster.
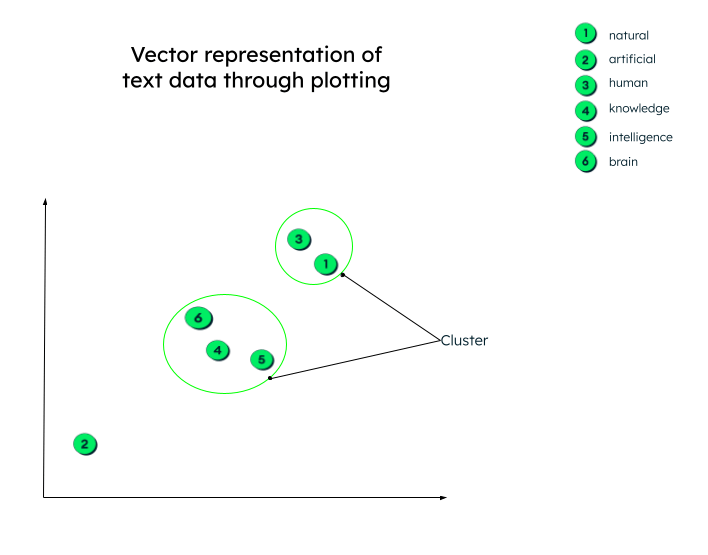 Graphical representação de vectors
Graphical representação de vectors
Pode haver muitos contextos nos quais os dados podem ser agrupados. A relação depende de como o codificador incorpora os dados de origem e de como a distância entre os vetores é calculada. No exemplo abaixo, dois tipos de relacionamentos podem ser estabelecidos:
- Tanto cat quanto dog são animais domésticos, enquanto tiger e wolf são animais selvagens.
- Cat e tiger pertencem à mesma família, enquanto dog e wolf pertencem à mesma família de animais.
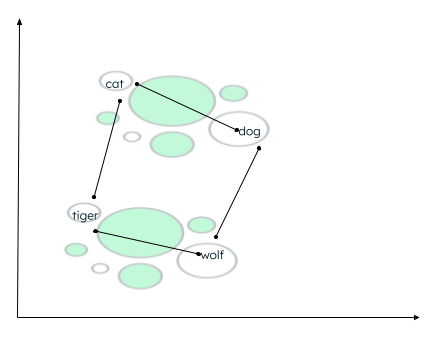
Calculation of distance of similar words
Uma função de similaridade define quais palavras estão mais próximas umas das outras e rotula as palavras próximas como vizinhas. Esse agrupamento/clustering é feito usando o algoritmo dos k-vizinhos mais próximos, onde o valor de k representa o número de vizinhos a serem identificados. Para encontrar a semelhança, a pesquisa vetorial suporta muitos métodos, como encontrar a:
- Distância euclidiana entre as extremidades dos dois vetores.
- Cosseno (ângulo) entre os dois vetores.
- Produto escalar dos vetores.
O MongoDB Atlas oferece recursos de busca de vetores dentro da própria plataforma Atlas, por meio de frameworks de IA, e suporta todas as funções de similaridade mencionadas anteriormente.
MongoDB Atlas Vector Search
O MongoDB sempre foi compatível com a pesquisa vetorial em duas dimensões. No entanto, a nova pesquisa vetorial possibilita recursos avançados devido à incorporação e permite dimensões maiores. Os aplicativos podem gravar os dados, bem como as incorporações de vetores no banco de dados. Os vetores de dados são gerados usando um modelo de codificador. A pesquisa do Atlas usa o algoritmo ANN (Approximate Nearest Neighbor) por meio do gráfico HNSW (Hierarchical Navigable Small World). ANN é uma variação do algoritmo dos k-vizinhos mais próximos, porém com uma velocidade de recuperação mais alta.
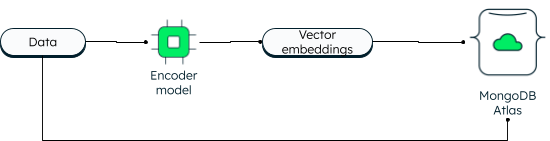
Como os vetores são armazenados no MongoDB Atlas
Ao realizar a leitura, a consulta é codificada e enviada na etapa de agregação $search, juntamente com o vetor alvo. Se você quiser conhecer as etapas, siga o tutorial sobre criação de aplicativos de IA generativa usando o MongoDB.
A vantagem de ter vetores junto com os dados operacionais é que você pode acessar todas as informações em uma única plataforma, até mesmo seus dados privados, que não seriam acessíveis de outra forma.
A pesquisa vetorial do Atlas simplifica a arquitetura de seu aplicativo. Como o MongoDB Atlas é totalmente gerenciado, a plataforma MongoDB Atlas cuida de tudo, desde a sincronização de dados, a segurança e a privacidade. Os desenvolvedores podem trabalhar com o database e a vector search usando a MongoDB Query API. Você pode implementar o Atlas em mais de 100 regiões em três grandes provedores de cloud. O Atlas oferece tempo de atividade contínuo com automação avançada que garante alto desempenho, independentemente da escala do aplicativo.
Alguns casos de uso proeminentes da pesquisa vetorial do Atlas incluem:
- Semantic search.
- Sistemas de perguntas e respostas.
- Extração de recursos.
- Pontuação de recomendação e relevância.
- Geração de sinônimos.
- Pesquisa de imagens.
Como funciona a pesquisa de Atlas Vector?
O aplicativo cliente envia os dados brutos. O modelo vector embedding cria vetores para cada texto na consulta inicial (dados brutos). Estruturas como Llamaindex e LangChain se integram bem ao MongoDB Atlas para criar incorporações e enviar dados ao MongoDB para adicionar consciência contextual. A consulta consciente do contexto, conhecida como prompt, é então enviada a um LLM, que gera uma resposta codificada, a ser processada pelo modelo de incorporação vetorial (decodificador) e enviada ao cliente após decodificação.
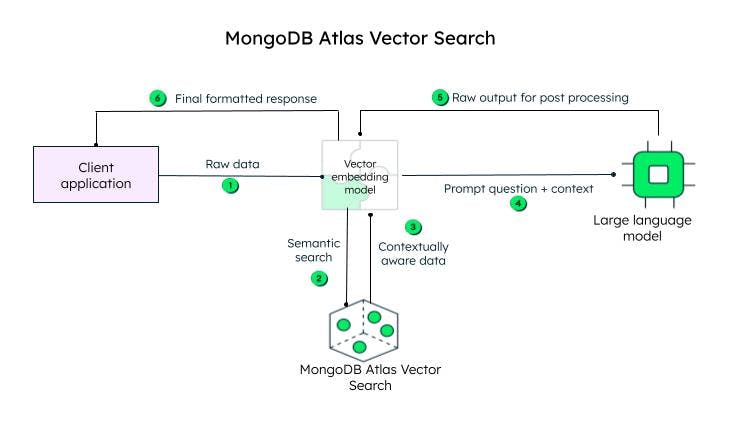 Steps obter pesquisa vetorial no MongoDB Atlas
Steps obter pesquisa vetorial no MongoDB Atlas
As incorporações vetoriais podem ser armazenadas no documento do banco de dados MongoDB como um array de floats, juntamente com o conteúdo, no campo content_embeddings.
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... other fields......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]Se o número de dimensões nos dados de entrada for maior, o número de pontos flutuantes será maior.
Em seguida, defina a definição de índice adicionando-a ao construtor de definições:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}A definição do índice inclui o modelo que encontraria os clusters de similaridade, as dimensões e a função de similaridade (de entre os três métodos suportados pelo MongoDB) que seria usada pelo modelo.
Para poder pesquisar, você pode usar o operador de agregação '$search' especificando o operador 'knnBeta' e fornecendo as {vector embeddings} da consulta no campo '{vector}'. Você também deve especificar o '{path}' das {vector embeddings} de {content} que devem ser examinadas para a {vector search}. O {MongoDB} também fornece '{filters}' adicionais para restringir a pesquisa e o número de {nearest neighbors} que o algoritmo do vizinho k-mais próximo deve retornar.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Como as {vector embeddings} e os dados residem na mesma plataforma, você pode acessar sua carga de trabalho operacional e {vector embeddings} usando uma única {MongoDB Query API} unificada. Para aprender a usar a funcionalidade passo a passo, consulte nosso tutorial sobre building generative AI apps usando vector search.
Important Casos de uso de IA
A IA está sendo aplicada com sucesso em diversos domínios, incluindo varejo, saúde e manufatura. Alguns casos de uso populares de IA são:
Processamento de linguagem natural (PLN): A inteligência artificial é amplamente utilizada em análise de sentimentos, assistentes virtuais, chatbots, reconhecimento de fala e tradução de texto. Como vimos acima, usando o poder do LLM e da busca vetorial, os sistemas de IA podem produzir resultados em linguagem humana.
Visão computacional: com redes neurais modernas, os sistemas de IA são capazes de realizar com precisão classificação de imagens, reconhecimento facial e de objetos, e geração de imagens.
Sistemas de recomendação e filtragem de conteúdo: os sistemas de IA podem recomendar conteúdo aos usuários usando modelos de aprendizado profundo e aprendizado de máquina sem intervenção humana.
Saúde: a tecnologia de inteligência artificial levou a saúde a um novo nível ao auxiliar os médicos no diagnóstico precoce de doenças, na pesquisa médica e descoberta de medicamentos, e no armazenamento seguro dos prontuários eletrônicos de saúde dos pacientes.
Carros autônomos: os carros autônomos são alimentados por algoritmos de IA, dados de sensores e visão computacional.
Robótica: os robôs industriais estão aumentando a produtividade ao realizar tarefas complexas com precisão. Da mesma forma, robôs de serviço são capazes de desempenhar suas tarefas de forma eficiente nos setores de saúde e hospitalidade.
Uso ético de IA, governança de IA e regulamentações
Com os rápidos avanços ocorrendo no campo da IA, é importante estabelecer regras e regulamentações e abordar as considerações éticas para que os sistemas de IA sejam usados de forma justa, transparente e para o propósito correto. A ética da IA concentra-se nas implicações morais e éticas das ferramentas e tecnologias de IA, ou seja, justiça, privacidade, transparência e responsabilidade.
As estruturas, estrutura e regras de conformidade são definidas pelo governo para garantir o uso responsável da IA.
O governo também estabelece regulamentações de IA, ou seja, estruturas legais para garantir a segurança dos dados, proteção ao consumidor e padrões de segurança.
AI ferramentas e serviços
Os dados são o núcleo de todas as operações de IA, e o MongoDB é uma plataforma na qual você pode confiar para criar aplicativos de IA poderosos. Como um banco de dados com um esquema flexível, a MongoDB oferece uma solução de armazenamento centralizada, com capacidades integradas de gerenciamento de dados, processamento avançado de dados, análises em tempo real, escalabilidade e muito mais. Algumas outras ferramentas e serviços populares são: - ChatGPT: o ChatGPT praticamente se tornou parte do cotidiano, desde fazer perguntas simples até planejar férias, programar, escrever poesia, resumir textos e muito mais.
Dall-E 2: Dall-E 2 é um projeto da OpenAI, assim como o ChatGPT, e gera gráficos de computador, como imagens, pinturas e desenhos, a partir de prompts de texto.
Difusão estável 2: esta é uma ferramenta de IA de texto para imagem para aplicativos generativos de IA. Ao contrário das ferramentas da OpenAI, que são acessadas por meio de portais de navegador, o Stable Diffusion 2 está disponível para download e instalação, e os usuários podem acessar publicamente o código-fonte e os algoritmos.
Perguntas frequentes
O que é inteligência artificial (IA)?
A capacidade das máquinas de pensar, aprender e tomar decisões, como um ser humano, diante de diferentes cenários, é conhecida como inteligência artificial.
Como a IA funciona?
Inteligência artificial (IA) engloba aprendizado de máquina e aprendizado profundo, ambos os quais contêm diversos algoritmos para atender aos diferentes casos de uso. Esses algoritmos operam em enormes volumes de dados coletados de diversas fontes, que são classificados, transformados e pré-processados antes de serem alimentados nos algoritmos. Os algoritmos utilizam dados para treinar, obter feedback e aprimorar-se, até que um resultado desejável seja alcançado.
Por que a inteligência artificial é importante?
A IA é importante, pois pode permitir a automação de tarefas rotineiras e repetitivas, melhorar a eficiência, reduzir erros humanos, fornecer análises preditivas para tomadas de decisão mais rápidas e precisas, oferecer recomendações personalizadas para usuários, auxiliar no diagnóstico de doenças, acelerar pesquisas em medicina e ciência, e promover inovação.
Quando a IA foi inventada?
Quais são os tipos de IA?
Qual é um exemplo de inteligência artificial?
O exemplo mais recente e popular de IA é o ChatGPT, que pode responder a perguntas feitas por humanos por meio da digitação, com uma resposta semelhante à humana. Ele também pode lembrar o contexto da conversa. O ChatGPT é treinado em um [modelo de linguagem grande] (#modelo-de-linguagem-grande-llm) e ainda mais enriquecido pelo aumento. MongoDB Atlas fornece uma ótima plataforma para [build powerful generative AI apps] (https://www.youtube.com/watch?v=BQc_pHaolsk) usando qualquer grande cloud provider.