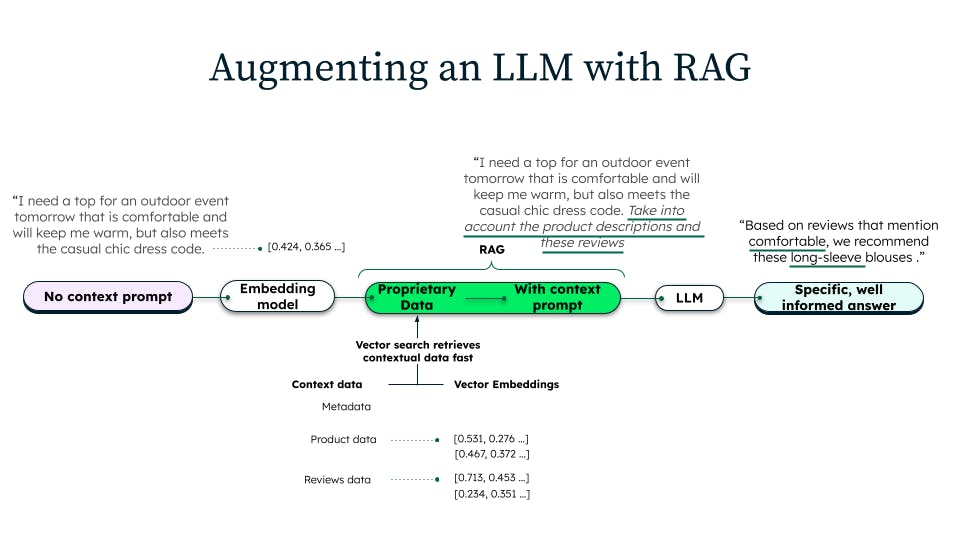
Pour pallier ce manque de contexte spécifique au domaine, la génération augmentée de récupération est effectuée comme suit :
- nous récupérons les descriptions de produits les plus pertinentes dans une base de données (souvent une base de données dotée de la recherche vectorielle) qui contient le dernier catalogue de produits ;
- ensuite, nous insérons (augmentons) ces descriptions dans l'invite du LLM ;
- enfin, nous demandons au LLM de « référencer » ces informations de produits à jour en répondant à la question.
Trois éléments à prendre en compte à partir de ce qui précède :
- la génération augmentée de récupération est une technique purement basée sur le temps d'inférence (le recyclage n'est pas nécessaire). Les étapes 1 à 3 ci-dessus se déroulent toutes dans le temps de l'inférence. Aucune modification du modèle n'est nécessaire (par exemple, la modification des poids du modèle) ;
- la génération augmentée de récupération est particulièrement adaptée aux personnalisations en temps réel des générations LLM. Comme il n'y a pas de réentraînement et que tout se fait par apprentissage en contexte, l'inférence basée sur la RAG est rapide (latence inférieure à 100 ms) et particulièrement adaptée à une utilisation dans des applications opérationnelles en temps réel ;
- la génération augmentée de récupération rend les générations LLM plus précises et plus utiles. Chaque fois que le contexte change, le LLM génère une réponse différente. Ainsi, la RAG fait en sorte que les LLM dépendent du contexte récupéré.
Simplifier la RAG mais faire en sorte qu'elle soit suffisamment élaborée pour fonctionner de manière fiable à grande échelle
Pour obtenir une architecture RAG performante et peu complexe, il faut d'abord choisir les bons systèmes. Lorsque vous choisissez des systèmes ou des technologies pour la mise en œuvre d'un système RAG, vous devez choisir un système ou des systèmes qui répondent aux objectifs suivants :
- la prise en charge de nouvelles exigences en matière de données vectorielles sans augmenter considérablement l'étendue, le coût et la complexité de vos activités informatiques ;
- s'assurer que les expériences d'IA générative développées ont accès à des données en direct avec une latence minimale ;
- avoir la flexibilité nécessaire pour répondre aux nouvelles exigences en matière de données et d'applications et permettre aux équipes de développement de rester agiles ;
- doter les équipes de développement des outils nécessaires pour qu’elles puissent intégrer l’ensemble de l’écosystème de l’IA à leurs données, et non l’inverse.
Il peut s'agir de bases de données vectorielles à usage unique ou de bases de données documentaires et relationnelles dotées de capacités vectorielles natives, en passant par les entrepôts de données et les lakehouses. Toutefois, les bases de données vectorielles à usage unique entraîneront immédiatement une prolifération et une complexité accrues. Les entrepôts de données et les lakehouses sont intrinsèquement conçus pour des requêtes analytiques de longue durée sur des données historiques, par opposition aux exigences élevées en matière de volume, de faible latence et de données récentes des applications d'IA générative alimentées par la RAG. En outre, les relational databases comportent des schémas rigides qui limitent la possibilité d'ajouter de nouvelles données et des exigences concernant l'application. Il ne reste plus que les bases de données documentaires dotées de capacités vectorielles natives ou intégrées. À ce titre, MongoDB repose sur un modèle documentaire flexible et dispose de fonctionnalités de recherche vectorielle natives. C'est donc une base de données vectorielles pour la RAG en plus d'être la base de données leader du secteur pour toute application moderne.
Faire passer les LLM au niveau supérieur avec des capacités supplémentaires dans votre mise en œuvre de la RAG
Outre les composants de base, il existe un certain nombre de fonctionnalités supplémentaires qui peuvent être ajoutées à un projet de mise en œuvre de la RAG pour améliorer la puissance des LLM. En voici quelques-unes :
- la multimodalité : les modèles RAG multimodaux peuvent générer des textes basés sur des données textuelles et non textuelles, telles que des images, des vidéos et des sons. Le fait que ces données multimodales soient stockées avec les données opérationnelles en temps réel facilite la conception et la gestion de la mise en œuvre de la RAG ;
- la définition de filtres supplémentaires dans la requête de recherche vectorielle : la possibilité d'ajouter des filtres de recherche par mot-clé, de recherche géospatiale, de point et d'intervalle sur la même requête vectorielle peut renforcer la précision et la rapidité du contexte fourni au LLM ;
- la spécificité du domaine : les modèles RAG propres à un domaine peuvent être entraînés sur des données provenant d'un domaine particulier, comme les soins de santé ou la finance. Cela permet au modèle RAG de générer un texte plus précis et plus pertinent pour ce domaine.
Il y a un certain nombre de choses à faire pour s'assurer qu'une application alimentée par l'IA générative qui repose sur la RAG est sûre, performante, fiable et évolutive lorsqu'elle est lancée à l'échelle mondiale. Voici quelques exemples :
- utiliser une plateforme sécurisée dotée de capacités de gouvernance des données adéquates : la gouvernance des données est un terme générique qui englobe toutes vos initiatives visant à garantir la sécurité, la confidentialité, l'exactitude, la disponibilité et l'utilisation des données. Elle comprend les processus, les politiques, les mesures, la technologie, les outils et les contrôles relatifs au cycle de vie des données. La plateforme doit donc être sécurisée par défaut, disposer d'un chiffrement de bout en bout et avoir atteint les niveaux de conformité les plus élevés ;
- utiliser une plateforme basée sur le cloud : outre les caractéristiques de sécurité et d'évolutivité qu'offrent les plateformes basées sur le cloud, les principaux fournisseurs de ce secteur sont ceux qui innovent le plus en matière d'infrastructure d'IA. Le choix d'une plateforme agnostique permet aux équipes de tirer parti des innovations en matière d'IA, où elles se trouvent ;
- utiliser une plateforme capable d'isoler l'infrastructure des charges de travail vectorielles de l'infrastructure des autres bases de données : les charges de travail OLTP ordinaires et les charges de travail vectorielles ne doivent pas partager l'infrastructure afin que les deux charges de travail puissent s'exécuter sur du matériel optimisé pour chacune d'entre elles, et qu'elles ne soient pas en concurrence pour les resources tout en étant en mesure d'utiliser les mêmes données ;
- utiliser une plateforme qui a fait ses preuves à grande échelle : c'est une chose pour un fournisseur de dire qu'il peut s'adapter, mais peut-il témoigner de ses réussites à l'échelle internationale ? A-t-il une tolérance aux pannes critiques et une capacité à évoluer horizontalement, et peut-il le prouver avec des témoignages de clients ?
En suivant ces conseils, il est possible de créer des applications alimentées par l'IA générative avec des architectures RAG sécurisées, performantes, fiables et évolutives.
Avec l'introduction d'Atlas Vector Search, la developer data platform de MongoDB fournit aux équipes une base de données vectorielles qui permet de construire des architectures RAG sophistiquées et performantes qui peuvent fonctionner à grande échelle. Tout cela en maintenant les plus hauts niveaux de sécurité et d'agnosticisme dans le cloud, et surtout, sans rendre les processus plus complexes et ajouter de frais inutiles.