Las aplicaciones de IA a menudo pueden empezar siendo pequeñas en términos de computación, datos y costos monetarios. A medida que las aplicaciones de producción se escalan debido al aumento de la interacción de los usuarios, factores clave como el costo asociado con el almacenamiento y la recuperación de grandes volúmenes de datos se convierten en oportunidades críticas de optimización. Se pueden abordar estos desafíos centrándose en:
Algoritmos eficientes de búsqueda vectorial
Procesos automatizados de cuantización
Estrategias de integración optimizadas
Tanto el generación de recuperación aumentada (RAG) como los sistemas basados en agentes dependen de los datos vectoriales, que son representaciones numéricas de objetos de datos como imágenes, vídeos y texto, para realizar búsquedas de similitud semántica. Los sistemas que utilizan RAG o flujos de trabajo dirigidos por agentes deben gestionar de manera eficiente grandes conjuntos de datos de alta dimensión para mantener tiempos de respuesta rápidos, minimizar la latencia de recuperación y controlar los costos de infraestructura.
Acerca del Tutorial
Este tutorial le dota con las técnicas necesarias para diseñar, implementar y gestionar cargas de trabajo avanzadas de IA a escala, asegurando un rendimiento óptimo y eficiencia de costos.
Específicamente, en este tutorial, aprenderás cómo:
Genera incrustaciones usando la IA de Voyage
voyage-3-large, un modelo de incrustación multilingüe de propósito general que también tiene en cuenta la cuantificación y los incorpora a una base de datos MongoDB.Cuantificar automáticamente las incrustaciones (embeddings) a tipos de datos de menor precisión, optimizando tanto el uso de memoria como la latencia de la query.
Ejecute una consulta que compare incrustaciones float32, int8 y binarias, sopesando la precisión del tipo de datos frente a la eficiencia y la precisión de recuperación.
Mida la recuperación (también denominada retención) de las incrustaciones cuantificadas, que evalúa la eficacia con la que se cuantifican La búsqueda de ANN recupera los mismos documentos que una búsqueda de ENN de precisión completa.
Nota
La cuantificación binaria es óptima para escenarios que exigen reducir el consumo de recursos, aunque puede requerir una pasada de reajuste para corregir cualquier pérdida de precisión.
La cuantificación escalar ofrece un término medio práctico, adecuado para la mayoría de los casos de uso que necesitan equilibrar el rendimiento y la precisión.
Float32 asegura la máxima fidelidad, pero conlleva la mayor sobrecarga de rendimiento y memoria, lo que lo hace menos ideal para sistemas de gran escala o sensibles a la latencia.
Requisitos previos
Para completar este tutorial, debes tener lo siguiente:
Procedimiento
Importa las librerías necesarias y configura las variables de entorno.
Cree un cuaderno interactivo de Python guardando un archivo con la extensión
.ipynb.Instalar las bibliotecas.
Para este tutorial, debes importar las siguientes librerías:
PyMongo
Controlador Python de MongoDB para conectarse a su clúster, crear índices y ejecutar consultas.
voyageai
Cliente de Voyage IA para Python para generar los embeddings para los datos.
pandas
Herramienta de manipulación y análisis de datos para cargar los datos y prepararlos para la búsqueda vectorial.
conjuntos de datos
librería de Hugging Face que proporciona acceso a conjuntos de datos listos para usar.
matplotlib
Biblioteca de gráficosy visualización para visualizar los datos.
Para instalar las librerías, ejecuta lo siguiente:
pip install --quiet -U pymongo voyageai pandas datasets matplotlib Obtenga y establezca de forma segura variables de entorno.
La siguiente función asistente
set_env_securelyobtiene y establece variables de entorno de forma segura. Copie, pegue y ejecute el siguiente código y, cuando se le solicite, configure valores secretos como su clave de Voyage IA API y la cadena de conexión de su clúster.1 import getpass 2 import os 3 import voyageai 4 5 # Function to securely get and set environment variables 6 def set_env_securely(var_name, prompt): 7 value = getpass.getpass(prompt) 8 os.environ[var_name] = value 9 10 # Environment Variables 11 set_env_securely("VOYAGE_API_KEY", "Enter your Voyage API Key: ") 12 set_env_securely("MONGO_URI", "Enter your MongoDB URI: ") 13 MONGO_URI = os.environ.get("MONGO_URI") 14 if not MONGO_URI: 15 raise ValueError("MONGO_URI not set in environment variables.") 16 17 # Voyage Client 18 voyage_client = voyageai.Client()
Ingrese los datos en su clúster.
En este paso, debes cargar hasta 250000 documentos de los siguientes conjuntos de datos:
El conjunto de datos wikipedia-22-12-en-voyage-embed contiene fragmentos de artículos de Wikipedia con embarcamientos pre-generados en 1024punto flotante de dimensiones32 a partir del voyage-3-large modelo de Voyage IA. Esta es la colección de documentos principal con metadatos. Este conjunto de datos sirve como un compendio diverso de vectores para probar los efectos de la cuantificación de vectores en la búsqueda semántica. Cada documento de este conjunto de datos contiene los siguientes campos:
| El ObjectId ( |
| El identificador único del documento. |
| El título del documento. |
| El texto del documento. |
| La URL del documento. |
| El ID de Wikipedia del documento. |
| El número de visualizaciones del documento. |
| El ID del párrafo en el documento. |
| El número de lenguajes en el documento. |
| Los vectores de embedding con 1024 dimensiones para el documento. |
El conjunto de datos wikipedia-22-12-en-annotation contiene los datos de referencia anotados para la función de medición de recall. Estos datos se utilizan como conjunto de datos de referencia para la validación de exactitud y para evaluar el impacto de la cuantización en la calidad de recuperación. Cada documento en este conjunto de datos contiene los siguientes campos, que son la verdad fundamental utilizada para evaluar el rendimiento de la búsqueda vectorial:
| El ObjectId ( |
| El identificador único del documento. |
| El ID de Wikipedia del documento. |
| Las consultas que contienen las frases clave, preguntas, información parcial y oraciones del documento. |
| El arreglo de frases clave utilizadas para evaluar el rendimiento de la búsqueda vectorial para el documento. |
| El arreglo de información parcial que se utiliza para evaluar el rendimiento de la búsqueda vectorial del documento. |
| El arreglo de preguntas que se utilizan para evaluar el rendimiento de la búsqueda vectorial de documentos. |
| El conjunto de oraciones que se utilizan para evaluar el rendimiento de la búsqueda vectorial del documento. |
Define las funciones para cargar los datos en su clúster.
Copia, pega y ejecuta el siguiente código en tu cuaderno de apuntes. El código de muestra define las siguientes funciones :
generate_bson_vectorpara convertir las incrustaciones en el conjunto de datos en vectores binarios BSON para un almacenamiento y procesamiento eficiente de sus vectores.get_mongo_clientpara obtener la cadena de conexión de su clúster.insert_dataframe_into_collectionpara ingerir datos en el clúster.
1 import pandas as pd 2 from datasets import load_dataset 3 from bson.binary import Binary, BinaryVectorDtype 4 import pymongo 5 6 # Connect to Cluster 7 def get_mongo_client(uri): 8 """Connect to MongoDB and confirm the connection.""" 9 client = pymongo.MongoClient(uri) 10 if client.admin.command("ping").get("ok") == 1.0: 11 print("Connected to MongoDB successfully.") 12 return client 13 print("Failed to connect to MongoDB.") 14 return None 15 16 # Generate BSON Vector 17 def generate_bson_vector(array, data_type): 18 """Convert an array to BSON vector format.""" 19 array = [float(val) for val in eval(array)] 20 return Binary.from_vector(array, BinaryVectorDtype(data_type)) 21 22 # Load Datasets 23 def load_and_prepare_data(dataset_name, amount): 24 """Load and prepare streaming datasets for DataFrame.""" 25 data = load_dataset(dataset_name, streaming=True, split="train").take(amount) 26 return pd.DataFrame(data) 27 28 # Insert datasets into MongoDB Collection 29 def insert_dataframe_into_collection(df, collection): 30 """Insert Dataset records into MongoDB collection.""" 31 collection.insert_many(df.to_dict("records")) 32 print(f"Inserted {len(df)} records into '{collection.name}' collection.") Carga los datos en el clúster.
Copie, pegue y ejecute el siguiente código en su notebook para cargar el conjunto de datos en su clúster. Este código realiza las siguientes acciones:
Recupera los conjuntos de datos.
Convierte los embeddings a formato BSON.
Crea colecciones en su clúster e inserta los datos.
1 import pandas as pd 2 from bson.binary import Binary, BinaryVectorDtype 3 from pymongo.errors import CollectionInvalid 4 5 wikipedia_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-voyage-embed", amount=250000) 6 wikipedia_annotation_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-annotation", amount=250000) 7 wikipedia_annotation_data_df.drop(columns=["_id"], inplace=True) 8 9 # Convert embeddings to BSON format 10 wikipedia_data_df["embedding"] = wikipedia_data_df["embedding"].apply( 11 lambda x: generate_bson_vector(x, BinaryVectorDtype.FLOAT32) 12 ) 13 14 # MongoDB Setup 15 mongo_client = get_mongo_client(MONGO_URI) 16 DB_NAME = "testing_datasets" 17 db = mongo_client[DB_NAME] 18 19 collections = { 20 "wikipedia-22-12-en": wikipedia_data_df, 21 "wikipedia-22-12-en-annotation": wikipedia_annotation_data_df, 22 } 23 24 # Create Collections and Insert Data 25 for collection_name, df in collections.items(): 26 if collection_name not in db.list_collection_names(): 27 try: 28 db.create_collection(collection_name) 29 print(f"Collection '{collection_name}' created successfully.") 30 except CollectionInvalid: 31 print(f"Error creating collection '{collection_name}'.") 32 else: 33 print(f"Collection '{collection_name}' already exists.") 34 35 # Clear collection and insert fresh data 36 collection = db[collection_name] 37 collection.delete_many({}) 38 insert_dataframe_into_collection(df, collection) Connected to MongoDB successfully. Collection 'wikipedia-22-12-en' created successfully. Inserted 250000 records into 'wikipedia-22-12-en' collection. Collection 'wikipedia-22-12-en-annotation' created successfully. Inserted 87200 records into 'wikipedia-22-12-en-annotation' collection. IMPORTANTE: Puede llevar algún tiempo convertir las incrustaciones en vectores BSON e ingerir los conjuntos de datos en su clúster.
Verifica que los conjuntos de datos se hayan cargado correctamente iniciando sesión en tu clúster e inspeccionando visualmente las colecciones en Explorador de datos.
Crea índices de MongoDB Vector Search en la colección.
En este paso, creará los siguientes tres índices en el campo embedding:
Índice cuantizado escalar | Para utilizar el método de cuantización escalar para cuantizar los embeddings. |
Índice cuantizado binario | Utilizar el método de cuantificación binaria para cuantificar las incrustaciones. |
Float32 ANN Index | Para utilizar el método float32 ANN para cuantificar las incrustaciones. |
Define la función para crear el índice de búsqueda vectorial de MongoDB.
Copia, pega y ejecuta lo siguiente en tu notebook:
1 import time 2 from pymongo.operations import SearchIndexModel 3 4 def setup_vector_search_index(collection, index_definition, index_name="vector_index"): 5 new_vector_search_index_model = SearchIndexModel( 6 definition=index_definition, name=index_name, type="vectorSearch" 7 ) 8 9 # Create the new index 10 try: 11 result = collection.create_search_index(model=new_vector_search_index_model) 12 print(f"Creating index '{index_name}'...") 13 14 # Wait for initial sync to complete 15 print("Polling to check if the index is ready. This may take a couple of minutes.") 16 predicate=None 17 if predicate is None: 18 predicate = lambda index: index.get("queryable") is True 19 while True: 20 indices = list(collection.list_search_indexes(result)) 21 if len(indices) and predicate(indices[0]): 22 break 23 time.sleep(5) 24 print(f"Index '{index_name}' is ready for querying.") 25 return result 26 27 except Exception as e: 28 print(f"Error creating new vector search index '{index_name}': {e!s}") 29 return None Definir los índices.
Las siguientes configuraciones de índices implementan una estrategia diferente de cuantificación:
vector_index_definition_scalar_quantizedEsta configuración utiliza cuantificación escalar (int8), lo cual:
Reduce cada dimensión del vector de un número flotante de 32bits a un número entero de 8bits
Mantiene un buen equilibrio entre precisión y eficiencia de memoria
Es adecuado para la mayoría de los casos de uso en producción donde se necesita la optimización de memoria
vector_index_definition_binary_quantizedEsta configuración utiliza cuantificación binaria (int1), que:
Reduce cada dimensión del vector a un solo bit
Ofrece la máxima eficiencia de memoria
Es ideal para implementaciones a gran escala donde las limitaciones de memoria son críticas
La cuantización automática se realiza de manera transparente cuando se crean estos índices, y la Búsqueda Vectorial de MongoDB gestiona la conversión de float32 al formato cuantizado especificado durante la creación de índices y las operaciones de búsqueda.
La configuración del índice
vector_index_definition_float32_annindexa vectores de fidelidad total de1024dimensiones utilizando la función de similitudcosine.1 # Scalar Quantization 2 vector_index_definition_scalar_quantized = { 3 "fields": [ 4 { 5 "type": "vector", 6 "path": "embedding", 7 "quantization": "scalar", 8 "numDimensions": 1024, 9 "similarity": "cosine", 10 } 11 ] 12 } 13 # Binary Quantization 14 vector_index_definition_binary_quantized = { 15 "fields": [ 16 { 17 "type": "vector", 18 "path": "embedding", 19 "quantization": "binary", 20 "numDimensions": 1024, 21 "similarity": "cosine", 22 } 23 ] 24 } 25 # Float32 Embeddings 26 vector_index_definition_float32_ann = { 27 "fields": [ 28 { 29 "type": "vector", 30 "path": "embedding", 31 "numDimensions": 1024, 32 "similarity": "cosine", 33 } 34 ] 35 } Crea los índices escalar, binario y float32 utilizando la función
setup_vector_search_index.Configura los nombres de la colección y los índices.
wiki_data_collection = db["wikipedia-22-12-en"] wiki_annotation_data_collection = db["wikipedia-22-12-en-annotation"] vector_search_scalar_quantized_index_name = "vector_index_scalar_quantized" vector_search_binary_quantized_index_name = "vector_index_binary_quantized" vector_search_float32_ann_index_name = "vector_index_float32_ann" Crea los índices de MongoDB Vector Search.
1 setup_vector_search_index( 2 wiki_data_collection, 3 vector_index_definition_scalar_quantized, 4 vector_search_scalar_quantized_index_name, 5 ) 6 setup_vector_search_index( 7 wiki_data_collection, 8 vector_index_definition_binary_quantized, 9 vector_search_binary_quantized_index_name, 10 ) 11 setup_vector_search_index( 12 wiki_data_collection, 13 vector_index_definition_float32_ann, 14 vector_search_float32_ann_index_name, 15 ) Creating index 'vector_index_scalar_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_scalar_quantized' is ready for querying. Creating index 'vector_index_binary_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_binary_quantized' is ready for querying. Creating index 'vector_index_float32_ann'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_float32_ann' is ready for querying. vector_index_float32_ann' IMPORTANTE: La operación podría tardar unos minutos en completarse. Los índices deben estar en estado Ready para usarlos en consultas.
Verifique que la creación del índice haya tenido éxito iniciando sesión en su clúster e inspeccionando visualmente los índices en MongoDB Search.
Defina las funciones para generar embeddings y consultar una colección usando los índices de MongoDB Vector Search.
Este código define las siguientes funciones:
La función
get_embedding()genera incrustaciones de dimensión 1024 para el texto dado utilizando el modelo de incrustaciónvoyage-3-largede Voyage AI.La función
custom_vector_searchtoma los siguientes parámetros de entrada y devuelve los resultados de la operación de búsqueda vectorial.user_querystring de texto de query para la que se desea generar incrustaciones.
collectionColección MongoDB para buscar.
embedding_pathCampo de la colección que contiene las incrustaciones.
vector_search_index_nameNombre del índice a utilizar en la query.
top_kNúmero de documentos principales en los resultados a devolver.
num_candidatesNúmero de candidatos a considerar.
use_full_precisionMarcar para realizar ANN, si
False, o PEN, siTrue, búsqueda.El valor de
use_full_precisionse establece enFalsepor defecto para una búsqueda ANN. Establece el valor deuse_full_precisionaTruepara realizar una búsqueda ENN.En concreto, esta función realiza las siguientes acciones:
Genera las incrustaciones para el texto de la consulta.
Construye la etapa
$vectorSearchConfigura el tipo de búsqueda
Especifica los campos de la colección que se devolverán
Ejecuta la pipeline después de reunir estadísticas de rendimiento
Devuelve los resultados
1 def get_embedding(text, task_prefix="document"): 2 """Fetch embedding for a given text using Voyage AI.""" 3 if not text.strip(): 4 print("Empty text provided for embedding.") 5 return [] 6 result = voyage_client.embed([text], model="voyage-3-large", input_type=task_prefix) 7 return result.embeddings[0] 8 9 def custom_vector_search( 10 user_query, 11 collection, 12 embedding_path, 13 vector_search_index_name="vector_index", 14 top_k=5, 15 num_candidates=25, 16 use_full_precision=False, 17 ): 18 19 # Generate embedding for the user query 20 query_embedding = get_embedding(user_query, task_prefix="query") 21 22 if query_embedding is None: 23 return "Invalid query or embedding generation failed." 24 25 # Define the vector search stage 26 vector_search_stage = { 27 "$vectorSearch": { 28 "index": vector_search_index_name, 29 "queryVector": query_embedding, 30 "path": embedding_path, 31 "limit": top_k, 32 } 33 } 34 35 # Add numCandidates only for approximate search 36 if not use_full_precision: 37 vector_search_stage["$vectorSearch"]["numCandidates"] = num_candidates 38 else: 39 # Set exact to true for exact search using full precision float32 vectors and running exact search 40 vector_search_stage["$vectorSearch"]["exact"] = True 41 42 project_stage = { 43 "$project": { 44 "_id": 0, 45 "title": 1, 46 "text": 1, 47 "wiki_id": 1, 48 "url": 1, 49 "score": { 50 "$meta": "vectorSearchScore" 51 }, 52 } 53 } 54 55 # Define the aggregate pipeline with the vector search stage and additional stages 56 pipeline = [vector_search_stage, project_stage] 57 58 # Execute the explain command 59 explain_result = collection.database.command( 60 "explain", 61 {"aggregate": collection.name, "pipeline": pipeline, "cursor": {}}, 62 verbosity="executionStats", 63 ) 64 65 # Extract the execution time 66 vector_search_explain = explain_result["stages"][0]["$vectorSearch"] 67 execution_time_ms = vector_search_explain["explain"]["query"]["stats"]["context"][ 68 "millisElapsed" 69 ] 70 71 # Execute the actual query 72 results = list(collection.aggregate(pipeline)) 73 74 return {"results": results, "execution_time_ms": execution_time_ms}
Ejecute una consulta de búsqueda vectorial de MongoDB para evaluar el rendimiento de la búsqueda.
La siguiente consulta realiza búsquedas vectoriales con diferentes estrategias de cuantificación, midiendo métricas de rendimiento para vectores de cuantificación escalar, cuantificación binaria y precisión completa (float32), a la vez que captura mediciones de latencia en cada nivel de precisión y estandariza el formato de los resultados para su comparación analítica. Utiliza incrustaciones generadas con Voyage AI para la cadena de consulta "¿Cómo puedo aumentar mi productividad para obtener el máximo rendimiento?".
La consulta almacena indicadores de rendimiento esenciales clave en la variable results, incluido el nivel de precisión (escalar, binario, flotante32), el tamaño del conjunto de resultados (top_k), la latencia de la consulta en milisegundos y el contenido del documento recuperado, lo que proporciona métricas integrales para evaluar el rendimiento de la búsqueda en diferentes estrategias de cuantificación.
1 vector_search_indices = [ 2 vector_search_float32_ann_index_name, 3 vector_search_scalar_quantized_index_name, 4 vector_search_binary_quantized_index_name, 5 ] 6 7 # Random query 8 user_query = "How do I increase my productivity for maximum output" 9 test_top_k = 5 10 test_num_candidates = 25 11 12 # Result is a list of dictionaries with the following headings: precision, top_k, latency_ms, results 13 results = [] 14 15 for vector_search_index in vector_search_indices: 16 # Conduct a vector search operation using scalar quantized 17 vector_search_results = custom_vector_search( 18 user_query, 19 wiki_data_collection, 20 embedding_path="embedding", 21 vector_search_index_name=vector_search_index, 22 top_k=test_top_k, 23 num_candidates=test_num_candidates, 24 use_full_precision=False, 25 ) 26 # Include the precision in the results 27 precision = vector_search_index.split("vector_index")[1] 28 precision = precision.replace("quantized", "").capitalize() 29 30 results.append( 31 { 32 "precision": precision, 33 "top_k": test_top_k, 34 "num_candidates": test_num_candidates, 35 "latency_ms": vector_search_results["execution_time_ms"], 36 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 37 } 38 ) 39 40 # Conduct a vector search operation using full precision 41 precision = "Float32_ENN" 42 vector_search_results = custom_vector_search( 43 user_query, 44 wiki_data_collection, 45 embedding_path="embedding", 46 vector_search_index_name="vector_index_scalar_quantized", 47 top_k=test_top_k, 48 num_candidates=test_num_candidates, 49 use_full_precision=True, 50 ) 51 52 results.append( 53 { 54 "precision": precision, 55 "top_k": test_top_k, 56 "num_candidates": test_num_candidates, 57 "latency_ms": vector_search_results["execution_time_ms"], 58 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 59 } 60 ) 61 62 # Convert the results to a pandas DataFrame with the headings: precision, top_k, latency_ms 63 results_df = pd.DataFrame(results) 64 results_df.columns = ["precision", "top_k", "num_candidates", "latency_ms", "results"] 65 66 # To display the results: 67 results_df.head()
precision top_k num_candidates latency_ms results 0 _float32_ann 5 25 1659.498601 {'title': 'Henry Ford', 'text': 'Ford had deci... 1 _scalar_ 5 25 951.537687 {'title': 'Gross domestic product', 'text': 'F... 2 _binary_ 5 25 344.585193 {'title': 'Great Depression', 'text': 'The fir... 3 Float32_ENN 5 25 0.231693 {'title': 'Great Depression', 'text': 'The fir...
Las métricas de rendimiento de los resultados muestran diferencias de latencia entre los distintos niveles de precisión. Esto demuestra que, si bien la cuantificación proporciona mejoras sustanciales en el rendimiento, existe una clara compensación entre la precisión y la velocidad de recuperación, ya que las operaciones float32 de precisión completa requieren un tiempo de cálculo considerablemente mayor que sus contrapartes cuantificadas.
Mide la latencia con diferentes valores de top-k y num_candidates.
La siguiente query introduce un marco de medición de la latencia sistemático que evalúa el rendimiento de la búsqueda vectorial en diferentes niveles de precisión y escalas de recuperación. El parámetro top-k no solo determina el número de resultados a devolver, sino que también establece el parámetro numCandidates en la búsqueda del grafo HNSW de MongoDB.
El valor numCandidates influye en cuántos nodos en el grafo HNSW explora MongoDB Vector Search durante la búsqueda ANN. Aquí, un valor más alto aumenta la probabilidad de encontrar los verdaderos vecinos más cercanos, pero requiere más tiempo de computación.
Define la función para formatear el
latency_msen un formato legible por humanos.1 from datetime import timedelta 2 3 def format_time(ms): 4 """Convert milliseconds to a human-readable format""" 5 delta = timedelta(milliseconds=ms) 6 7 # Extract minutes, seconds, and milliseconds with more precision 8 minutes = delta.seconds // 60 9 seconds = delta.seconds % 60 10 milliseconds = round(ms % 1000, 3) # Keep 3 decimal places for milliseconds 11 12 # Format based on duration 13 if minutes > 0: 14 return f"{minutes}m {seconds}.{milliseconds:03.0f}s" 15 elif seconds > 0: 16 return f"{seconds}.{milliseconds:03.0f}s" 17 else: 18 return f"{milliseconds:.3f}ms" Define la función para medir la latencia de la query de búsqueda vectorial.
La siguiente función recibe como entrada un
user_query, uncollection, unvector_search_index_name, un valoruse_full_precision, un valortop_k_valuesy un valornum_candidates_values, y devuelve los resultados de la búsqueda vectorial. Aquí, toma nota de lo siguiente:La latencia aumenta a medida que aumentan los valores de
top_kynum_candidatesporque la operación de búsqueda vectorial utiliza un mayor número de documentos, lo que hace que la búsqueda tarde más.La latencia es mayor en la búsqueda de fidelidad completa (
use_full_precision=True) que en la búsqueda aproximada (use_full_precision=False), porque la búsqueda de fidelidad completa se demora más que la búsqueda aproximada, ya que busca en todo el conjunto de datos utilizando los vectores de coma flotante de máxima precisión32.La latencia de la búsqueda cuantificada es menor que la de la búsqueda de fidelidad completa porque la búsqueda cuantificada utiliza la búsqueda aproximada y los vectores cuantizados.
1 def measure_latency_with_varying_topk( 2 user_query, 3 collection, 4 vector_search_index_name="vector_index_scalar_quantized", 5 use_full_precision=False, 6 top_k_values=[5, 10, 100], 7 num_candidates_values=[25, 50, 100, 200, 500, 1000, 2000, 5000, 10000], 8 ): 9 results_data = [] 10 11 # Conduct vector search operation for each (top_k, num_candidates) combination 12 for top_k in top_k_values: 13 for num_candidates in num_candidates_values: 14 # Skip scenarios where num_candidates < top_k 15 if num_candidates < top_k: 16 continue 17 18 # Construct the precision name 19 precision_name = vector_search_index_name.split("vector_index")[1] 20 precision_name = precision_name.replace("quantized", "").capitalize() 21 22 # If use_full_precision is true, then the precision name is "_float32_" 23 if use_full_precision: 24 precision_name = "_float32_ENN" 25 26 # Perform the vector search 27 vector_search_results = custom_vector_search( 28 user_query=user_query, 29 collection=collection, 30 embedding_path="embedding", 31 vector_search_index_name=vector_search_index_name, 32 top_k=top_k, 33 num_candidates=num_candidates, 34 use_full_precision=use_full_precision, 35 ) 36 37 # Extract the execution time (latency) 38 latency_ms = vector_search_results["execution_time_ms"] 39 40 # Store results 41 results_data.append( 42 { 43 "precision": precision_name, 44 "top_k": top_k, 45 "num_candidates": num_candidates, 46 "latency_ms": latency_ms, 47 } 48 ) 49 50 return results_data Ejecuta la consulta de búsqueda vectorial de MongoDB para medir la latencia.
La operación de evaluación de latencia realiza un análisis integral del rendimiento ejecutando búsquedas a través de todas las estrategias de cuantización, probando múltiples tamaños de conjuntos de resultados, capturando métricas de rendimiento estandarizadas y agregando los resultados para un análisis comparativo, lo que permite una evaluación detallada del comportamiento de búsqueda vectorial bajo diferentes configuraciones y cargas de recuperación.
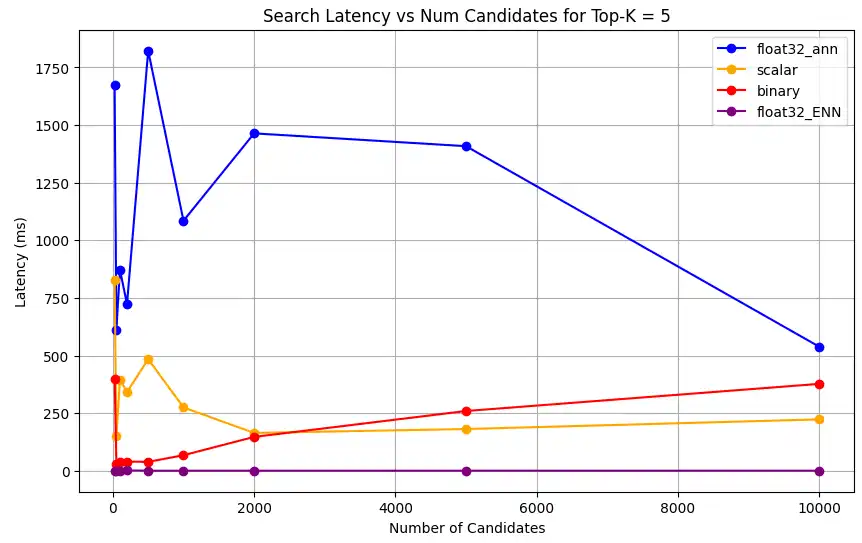
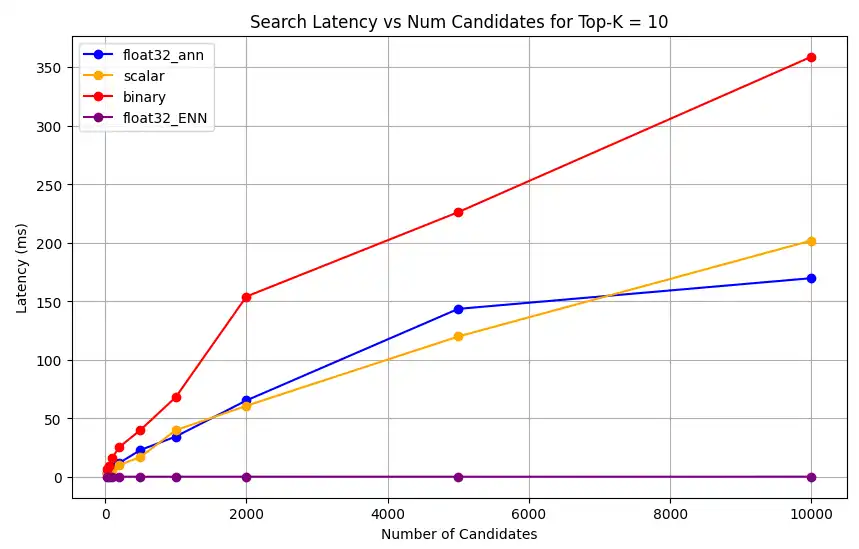
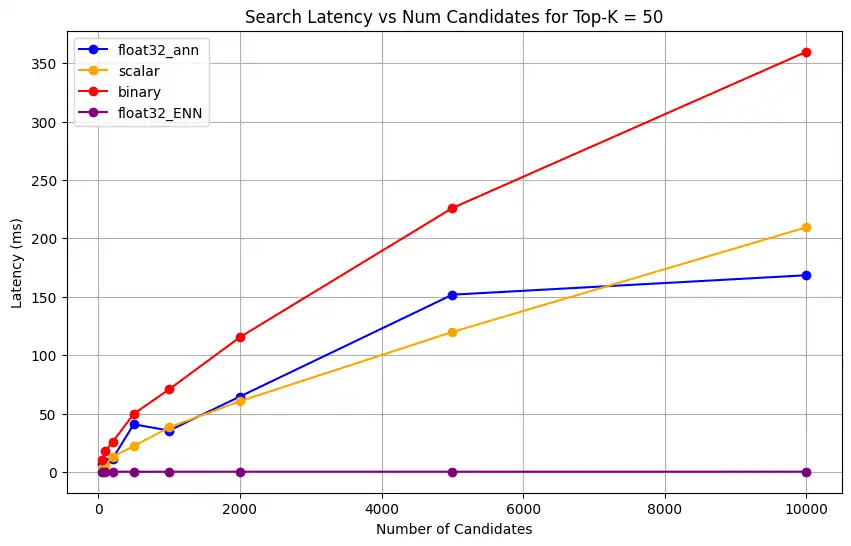
1 # Run the measurements 2 user_query = "How do I increase my productivity for maximum output" 3 top_k_values = [5, 10, 50, 100] 4 num_candidates_values = [25, 50, 100, 200, 500, 1000, 2000, 5000, 10000] 5 6 latency_results = [] 7 8 for vector_search_index in vector_search_indices: 9 latency_results.append( 10 measure_latency_with_varying_topk( 11 user_query, 12 wiki_data_collection, 13 vector_search_index_name=vector_search_index, 14 use_full_precision=False, 15 top_k_values=top_k_values, 16 num_candidates_values=num_candidates_values, 17 ) 18 ) 19 20 # Conduct vector search operation using full precision 21 latency_results.append( 22 measure_latency_with_varying_topk( 23 user_query, 24 wiki_data_collection, 25 vector_search_index_name="vector_index_scalar_quantized", 26 use_full_precision=True, 27 top_k_values=top_k_values, 28 num_candidates_values=num_candidates_values, 29 ) 30 ) 31 32 # Combine all results into a single DataFrame 33 all_latency_results = pd.concat([pd.DataFrame(latency_results)]) Top-K: 5, NumCandidates: 25, Latency: 1672.855906 ms, Precision: _float32_ann ... Top-K: 100, NumCandidates: 10000, Latency: 184.905389 ms, Precision: _float32_ann Top-K: 5, NumCandidates: 25, Latency: 828.45855 ms, Precision: _scalar_ ... Top-K: 100, NumCandidates: 10000, Latency: 214.199836 ms, Precision: _scalar_ Top-K: 5, NumCandidates: 25, Latency: 400.160243 ms, Precision: _binary_ ... Top-K: 100, NumCandidates: 10000, Latency: 360.908558 ms, Precision: _binary_ Top-K: 5, NumCandidates: 25, Latency: 0.239107 ms, Precision: _float32_ENN ... Top-K: 100, NumCandidates: 10000, Latency: 0.179203 ms, Precision: _float32_ENN Las mediciones de latencia revelan una clara jerarquía de rendimiento entre los tipos de precisión, donde la cuantificación binaria presenta los tiempos de recuperación más rápidos, seguida de la cuantificación escalar. Las operaciones de32 ANN float de precisión completa muestran latencias significativamente mayores. La diferencia de rendimiento entre las búsquedas cuantificadas y las de precisión completa se acentúa a medida que aumentan los valores Top-K. Las32 operaciones de ENN float son las más lentas, pero ofrecen los resultados de mayor precisión.
Representa la latencia de búsqueda frente a varios valores superiores k.
1 import matplotlib.pyplot as plt 2 3 # Map your precision field to the labels and colors you want in the legend 4 precision_label_map = { 5 "_scalar_": "scalar", 6 "_binary_": "binary", 7 "_float32_ann": "float32_ann", 8 "_float32_ENN": "float32_ENN", 9 } 10 11 precision_color_map = { 12 "_scalar_": "orange", 13 "_binary_": "red", 14 "_float32_ann": "blue", 15 "_float32_ENN": "purple", 16 } 17 18 # Flatten all measurements and find the unique top_k values 19 all_measurements = [m for precision_list in latency_results for m in precision_list] 20 unique_topk = sorted(set(m["top_k"] for m in all_measurements)) 21 22 # For each top_k, create a separate plot 23 for k in unique_topk: 24 plt.figure(figsize=(10, 6)) 25 26 # For each precision type, filter out measurements for the current top_k value 27 for measurements in latency_results: 28 # Filter measurements with top_k equal to the current k 29 filtered = [m for m in measurements if m["top_k"] == k] 30 if not filtered: 31 continue 32 33 # Extract x (num_candidates) and y (latency) values 34 x = [m["num_candidates"] for m in filtered] 35 y = [m["latency_ms"] for m in filtered] 36 37 # Determine the precision, label, and color from the first measurement in this filtered list 38 precision = filtered[0]["precision"] 39 label = precision_label_map.get(precision, precision) 40 color = precision_color_map.get(precision, "blue") 41 42 # Plot the line for this precision type 43 plt.plot(x, y, marker="o", color=color, label=label) 44 45 # Label axes and add title including the top_k value 46 plt.xlabel("Number of Candidates") 47 plt.ylabel("Latency (ms)") 48 plt.title(f"Search Latency vs Num Candidates for Top-K = {k}") 49 50 # Add a legend and grid, then show the plot 51 plt.legend() 52 plt.grid(True) 53 plt.show() El código devuelve los siguientes gráficos de latencia, que ilustran cómo funciona la recuperación de documentos de búsqueda vectorial con diferentes tipos de precisión de embedding, binario, escalar y float32, a medida que aumenta el
top-k(el número de resultados recuperados):![Captura de pantalla de la gráfica que muestra la latencia de búsqueda frente al número de candidatos para Top-K = 5]() haga clic para ampliar
haga clic para ampliar![Captura de pantalla de la gráfica que muestra la latencia de búsqueda frente al número de candidatos para Top-K = 10]() haga clic para ampliar
haga clic para ampliar![Captura de pantalla de la gráfica que muestra la latencia de búsqueda frente al número de candidatos para Top-K = 50]() haga clic para ampliar
haga clic para ampliar



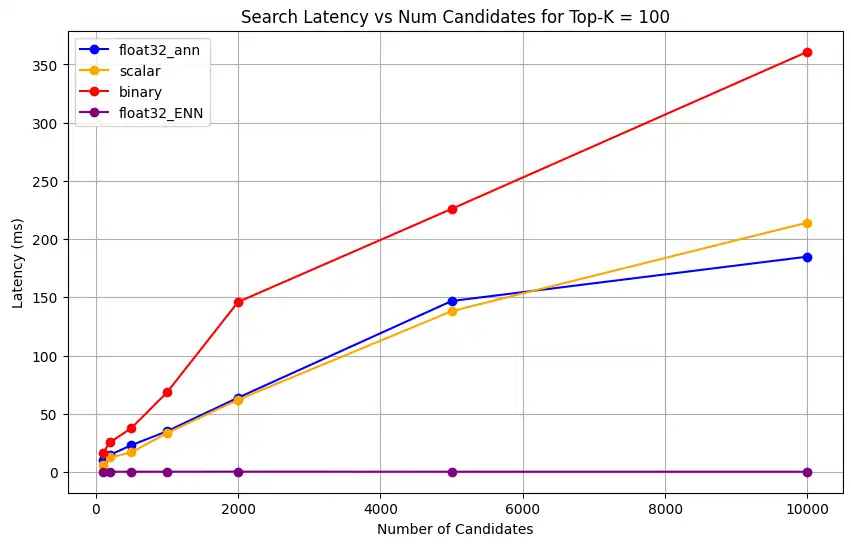
Mide la capacidad de representación y retención.
La siguiente query mide cuán eficazmente MongoDB Vector Search recupera documentos relevantes del conjunto de datos de referencia. Se calcula como la proporción de documentos relevantes encontrados correctamente con respecto al número total de documentos relevantes en la verdad básica (Encontrados/Total). Por ejemplo, si una query tiene 5 documentos relevantes en el ground truth y MongoDB Vector Search encuentra 4 de ellos, el recall sería 0.8 o 80% .
Define una función para medir la capacidad de representación y retención de la operación de búsqueda vectorial. Esta función realiza lo siguiente:
Crea la búsqueda de línea base utilizando32 vectores float de precisión completa y búsqueda ENN.
Crea la búsqueda cuantificada utilizando los vectores cuantificados y la búsqueda ANN.
Calcula la retención de la búsqueda cuantificada en comparación con la búsqueda de referencia.
La retención debe mantenerse dentro de un rango razonable para la búsqueda cuantificada. Si la capacidad de representación es baja, significa que la búsqueda vectorial no puede capturar el significado semántico de la consulta y que los resultados podrían no ser precisos. Esto indica que la cuantificación no es efectiva y que el modelo de incrustación inicial utilizado no es eficaz para el proceso de cuantificación. Recomendamos utilizar modelos de incrustación que tengan en cuenta la cuantificación, es decir, que durante el proceso de entrenamiento, el modelo se optimice específicamente para producir incrustaciones que mantengan sus propiedades semánticas incluso después de la cuantificación.
1 def measure_representational_capacity_retention_against_float_enn( 2 ground_truth_collection, 3 collection, 4 quantized_index_name, # This is used for both the quantized search and (with use_full_precision=True) for the baseline. 5 top_k_values, # List/array of top-k values to test. 6 num_candidates_values, # List/array of num_candidates values to test. 7 num_queries_to_test=1, 8 ): 9 retention_results = {"per_query_retention": {}} 10 overall_retention = {} # overall_retention[top_k][num_candidates] = [list of retention values] 11 12 # Initialize overall retention structure 13 for top_k in top_k_values: 14 overall_retention[top_k] = {} 15 for num_candidates in num_candidates_values: 16 if num_candidates < top_k: 17 continue 18 overall_retention[top_k][num_candidates] = [] 19 20 # Extract and store the precision name from the quantized index name. 21 precision_name = quantized_index_name.split("vector_index")[1] 22 precision_name = precision_name.replace("quantized", "").capitalize() 23 retention_results["precision_name"] = precision_name 24 retention_results["top_k_values"] = top_k_values 25 retention_results["num_candidates_values"] = num_candidates_values 26 27 # Load ground truth annotations 28 ground_truth_annotations = list( 29 ground_truth_collection.find().limit(num_queries_to_test) 30 ) 31 print(f"Loaded {len(ground_truth_annotations)} ground truth annotations") 32 33 # Process each ground truth annotation 34 for annotation in ground_truth_annotations: 35 # Use the ground truth wiki_id from the annotation. 36 ground_truth_wiki_id = annotation["wiki_id"] 37 38 # Process only queries that are questions. 39 for query_type, queries in annotation["queries"].items(): 40 if query_type.lower() not in ["question", "questions"]: 41 continue 42 43 for query in queries: 44 # Prepare nested dict for this query 45 if query not in retention_results["per_query_retention"]: 46 retention_results["per_query_retention"][query] = {} 47 48 # For each valid combination of top_k and num_candidates 49 for top_k in top_k_values: 50 if top_k not in retention_results["per_query_retention"][query]: 51 retention_results["per_query_retention"][query][top_k] = {} 52 for num_candidates in num_candidates_values: 53 if num_candidates < top_k: 54 continue 55 56 # Baseline search: full precision using ENN (Float32) 57 baseline_result = custom_vector_search( 58 user_query=query, 59 collection=collection, 60 embedding_path="embedding", 61 vector_search_index_name=quantized_index_name, 62 top_k=top_k, 63 num_candidates=num_candidates, 64 use_full_precision=True, 65 ) 66 baseline_ids = { 67 res["wiki_id"] for res in baseline_result["results"] 68 } 69 70 # Quantized search: 71 quantized_result = custom_vector_search( 72 user_query=query, 73 collection=collection, 74 embedding_path="embedding", 75 vector_search_index_name=quantized_index_name, 76 top_k=top_k, 77 num_candidates=num_candidates, 78 use_full_precision=False, 79 ) 80 quantized_ids = { 81 res["wiki_id"] for res in quantized_result["results"] 82 } 83 84 # Compute retention for this combination 85 if baseline_ids: 86 retention = len( 87 baseline_ids.intersection(quantized_ids) 88 ) / len(baseline_ids) 89 else: 90 retention = 0 91 92 # Store the results per query 93 retention_results["per_query_retention"][query].setdefault( 94 top_k, {} 95 )[num_candidates] = { 96 "ground_truth_wiki_id": ground_truth_wiki_id, 97 "baseline_ids": sorted(baseline_ids), 98 "quantized_ids": sorted(quantized_ids), 99 "retention": retention, 100 } 101 overall_retention[top_k][num_candidates].append(retention) 102 103 print( 104 f"Query: '{query}' | top_k: {top_k}, num_candidates: {num_candidates}" 105 ) 106 print(f" Ground Truth wiki_id: {ground_truth_wiki_id}") 107 print(f" Baseline IDs (Float32): {sorted(baseline_ids)}") 108 print( 109 f" Quantized IDs: {precision_name}: {sorted(quantized_ids)}" 110 ) 111 print(f" Retention: {retention:.4f}\n") 112 113 # Compute overall average retention per combination 114 avg_overall_retention = {} 115 for top_k, cand_dict in overall_retention.items(): 116 avg_overall_retention[top_k] = {} 117 for num_candidates, retentions in cand_dict.items(): 118 if retentions: 119 avg = sum(retentions) / len(retentions) 120 else: 121 avg = 0 122 avg_overall_retention[top_k][num_candidates] = avg 123 print( 124 f"Overall Average Retention for top_k {top_k}, num_candidates {num_candidates}: {avg:.4f}" 125 ) 126 127 retention_results["average_retention"] = avg_overall_retention 128 return retention_results Evalúe y compare el rendimiento de sus índices de búsqueda vectorial de MongoDB.
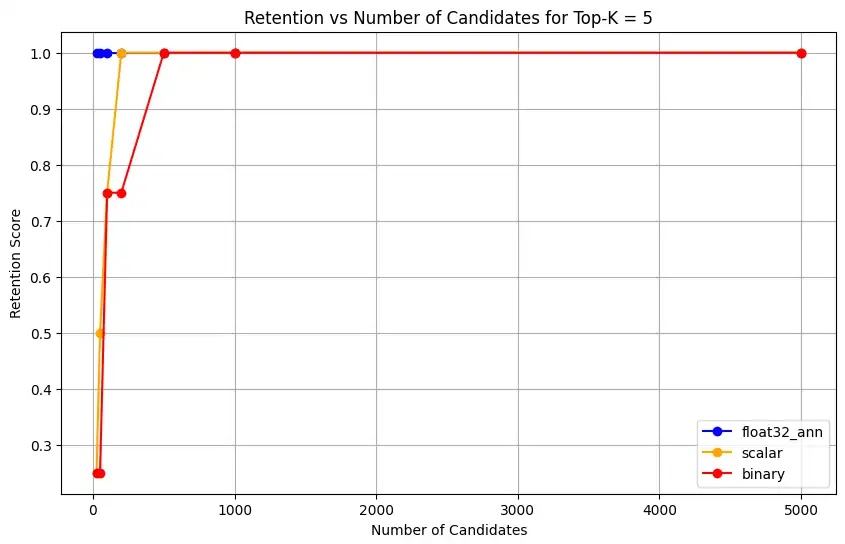
1 overall_recall_results = [] 2 top_k_values = [5, 10, 50, 100] 3 num_candidates_values = [25, 50, 100, 200, 500, 1000, 5000] 4 num_queries_to_test = 1 5 6 for vector_search_index in vector_search_indices: 7 overall_recall_results.append( 8 measure_representational_capacity_retention_against_float_enn( 9 ground_truth_collection=wiki_annotation_data_collection, 10 collection=wiki_data_collection, 11 quantized_index_name=vector_search_index, 12 top_k_values=top_k_values, 13 num_candidates_values=num_candidates_values, 14 num_queries_to_test=num_queries_to_test, 15 ) 16 ) Loaded 1 ground truth annotations Query: 'What happened in 2022?' | top_k: 5, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [60254944, 64483771, 69094871] Retention: 0.7500 ... Query: 'What happened in 2022?' | top_k: 5, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 10, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [60254944, 64483771, 65225795, 69094871, 70149799] Retention: 1.0000 ... Query: 'What happened in 2022?' | top_k: 10, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871, 69265870] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 50, num_candidates: 50 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 8351234, 29868391, 40365067, 52241897, 52251217, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.8125 ... Query: 'What happened in 2022?' | top_k: 50, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 100, num_candidates: 100 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [22576, 25391, 243401, 547384, 751099, 8351234, 17742072, 18426568, 29868391, 40365067, 47747350, 52241897, 52251217, 52851695, 53992315, 57798792, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.7586 ... Query: 'What happened in 2022?' | top_k: 100, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Overall Average Retention for top_k 5, num_candidates 25: 0.7500 ... La salida muestra los resultados de retención para cada consulta en el conjunto de datos de datos de campo. La retención se expresa como un decimal entre 0 y 1, donde 1.0 significa que se conservan los ID de datos de campo y 0.25 que solo se conserva el 25% de los mismos.
Grafique la capacidad de retención de los diferentes tipos de precisión.
1 import matplotlib.pyplot as plt 2 3 # Define colors and labels for each precision type 4 precision_colors = {"_scalar_": "orange", "_binary_": "red", "_float32_": "green"} 5 6 if overall_recall_results: 7 # Determine unique top_k values from the first result's average_retention keys 8 unique_topk = sorted(list(overall_recall_results[0]["average_retention"].keys())) 9 10 for k in unique_topk: 11 plt.figure(figsize=(10, 6)) 12 # For each precision type, plot retention vs. number of candidates at this top_k 13 for result in overall_recall_results: 14 precision_name = result.get("precision_name", "unknown") 15 color = precision_colors.get(precision_name, "blue") 16 # Get candidate values from the average_retention dictionary for top_k k 17 candidate_values = sorted(result["average_retention"][k].keys()) 18 retention_values = [ 19 result["average_retention"][k][nc] for nc in candidate_values 20 ] 21 22 plt.plot( 23 candidate_values, 24 retention_values, 25 marker="o", 26 label=precision_name.strip("_"), 27 color=color, 28 ) 29 30 plt.xlabel("Number of Candidates") 31 plt.ylabel("Retention Score") 32 plt.title(f"Retention vs Number of Candidates for Top-K = {k}") 33 plt.legend() 34 plt.grid(True) 35 plt.show() 36 37 # Print detailed average retention results 38 print("\nDetailed Average Retention Results:") 39 for result in overall_recall_results: 40 precision_name = result.get("precision_name", "unknown") 41 print(f"\n{precision_name} Embedding:") 42 for k in sorted(result["average_retention"].keys()): 43 print(f"\nTop-K: {k}") 44 for nc in sorted(result["average_retention"][k].keys()): 45 ret = result["average_retention"][k][nc] 46 print(f" NumCandidates: {nc}, Retention: {ret:.4f}") El código devuelve las gráficas de retención para lo siguiente:
![Captura de pantalla de la gráfica que muestra Retención vs Núm. de candidatos para Top-K = 5]() haga clic para ampliar
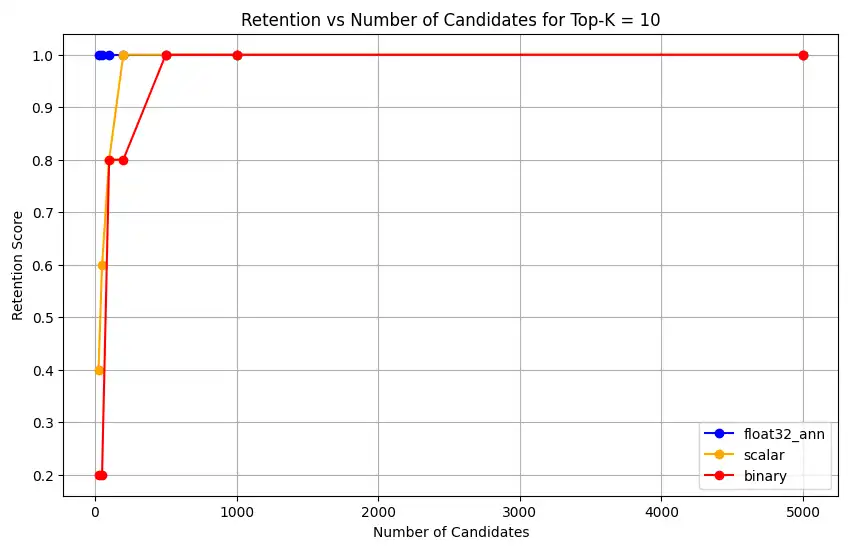
haga clic para ampliar![Captura de pantalla de la gráfica que muestra Retención vs Núm. de candidatos para Top-K = 10]() haga clic para ampliar
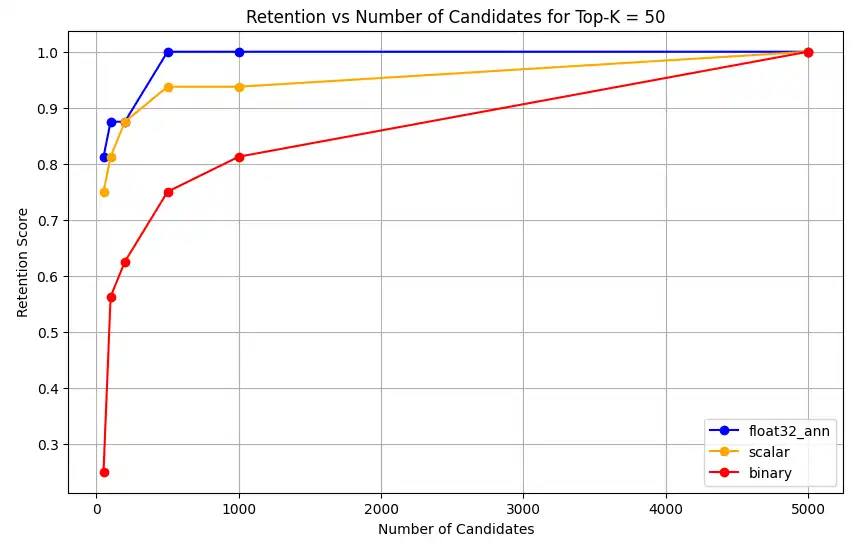
haga clic para ampliar![Captura de pantalla de la gráfica que muestra Retención vs Núm. de candidatos para Top-K = 50]() haga clic para ampliar
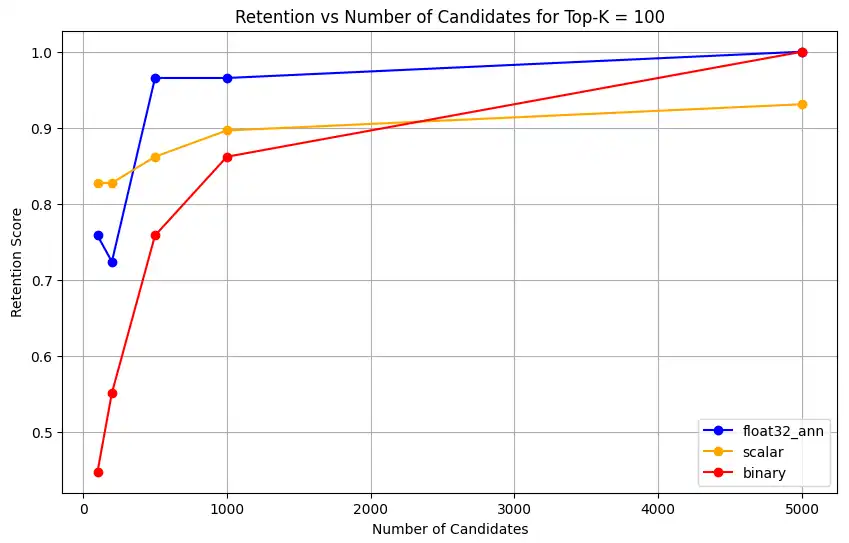
haga clic para ampliar![Captura de pantalla de la gráfica que muestra Retención vs Núm. de candidatos para Top-K = 100]() haga clic para ampliar
haga clic para ampliarPara las incrustaciones
float32_ann,scalarybinary, el código también devuelve resultados de retención promedio detallados similares a los siguientes:Detailed Average Retention Results: _float32_ann Embedding: Top-K: 5 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.8125 NumCandidates: 100, Retention: 0.8750 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.7586 NumCandidates: 200, Retention: 0.7241 NumCandidates: 500, Retention: 0.9655 NumCandidates: 1000, Retention: 0.9655 NumCandidates: 5000, Retention: 1.0000 _scalar_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.5000 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.4000 NumCandidates: 50, Retention: 0.6000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.7500 NumCandidates: 100, Retention: 0.8125 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 0.9375 NumCandidates: 1000, Retention: 0.9375 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.8276 NumCandidates: 200, Retention: 0.8276 NumCandidates: 500, Retention: 0.8621 NumCandidates: 1000, Retention: 0.8966 NumCandidates: 5000, Retention: 0.9310 _binary_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 0.7500 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.2000 NumCandidates: 50, Retention: 0.2000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 0.8000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.5625 NumCandidates: 200, Retention: 0.6250 NumCandidates: 500, Retention: 0.7500 NumCandidates: 1000, Retention: 0.8125 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.4483 NumCandidates: 200, Retention: 0.5517 NumCandidates: 500, Retention: 0.7586 NumCandidates: 1000, Retention: 0.8621 NumCandidates: 5000, Retention: 1.0000 Los resultados de recall demuestran patrones de rendimiento distintos entre los tres tipos de embeddings.
La cuantificación escalar muestra una mejora constante, lo que indica una fuerte precisión de recuperación en valores más altos de K. La cuantificación binaria, aunque comienza más bajo, mejora en Top-K 50 y 100, sugiriendo una compensación entre eficiencia computacional y rendimiento de recuperación. Las incrustaciones Float32 demuestran el rendimiento inicial más sólido y alcanzan el mismo recall máximo que la cuantificación escalar en Top-K 50 y 100.
Esto sugiere que mientras float32 proporciona una mejor memoria en valores Top-K más bajos, la cuantificación escalar puede lograr un rendimiento equivalente en valores Top-K más altos, ofreciendo al mismo tiempo una mayor eficiencia computacional. La cuantización binaria, a pesar de su menor umbral de recuperación, podría seguir siendo valiosa en escenarios donde las limitaciones de memoria y computación sean más importantes que la necesidad de la máxima precisión en la recuperación.