La generación aumentada por recuperación (RAG) es una arquitectura que se utiliza para aumentar los modelos de lenguaje grandes (LLM) con datos adicionales para que puedan generar respuestas más precisas. Puede implementar RAG en sus aplicaciones de IA generativa combinando un LLM con un sistema de recuperación impulsado por MongoDB Vector Search.
Empezar
Para probar rápidamente RAG con MongoDB Vector Search, utilice el Constructor de demos de chatbot en el entorno de búsqueda de MongoDB. Para obtener más información, consulte Generador de demostraciones de chatbot en Search Playground.
Para implementar su propio sistema RAG con Búsqueda vectorial de MongoDB, consulte el tutorial en esta página.
¿Por qué utilizar RAG?
Al trabajar con LLM, es posible que encuentres las siguientes limitaciones:
Datos obsoletos: los LLM se entrenan con un conjunto de datos estático hasta un cierto punto en el tiempo. Esto significa que tienen una base de conocimientos limitada y podrían utilizar datos obsoletos.
Sin acceso a datos adicionales: Los LLM no tienen acceso a datos locales, personalizados o específicos del dominio. Por lo tanto, podrían carecer de conocimientos sobre áreas específicas.
Alucinaciones: cuando se basan en datos incompletos u obsoletos, los LLM pueden generar respuestas inexactas.
Puedes abordar estas limitaciones si sigues estos pasos para implementar RAG:
Ingestión: se deben almacenar los datos personalizados como incrustaciones vectoriales en una base de datos vectorial, como MongoDB. Esto permite crear una base de conocimientos con datos actualizados y personalizados.
Recuperación: recupere documentos semánticamente similares de la base de datos de acuerdo a la pregunta del usuario utilizando una solución de búsqueda, como la búsqueda vectorial de MongoDB. Estos documentos enriquecen el LLM con datos adicionales y relevantes.
Generación: pregunta a LLM. El LLM utiliza los documentos recuperados como contexto para generar una respuesta más precisa y relevante, reduciendo las alucinaciones.
RAG es una arquitectura eficaz para construir chatbots de IA, ya que permite a los sistemas de IA proporcionar respuestas personalizadas y específicas del dominio. Para crear chatbots listos para producción, configure un servidor para enrutar solicitudes y crear una interfaz de usuario sobre su implementación de la RAG.
RAG con búsqueda vectorial de MongoDB
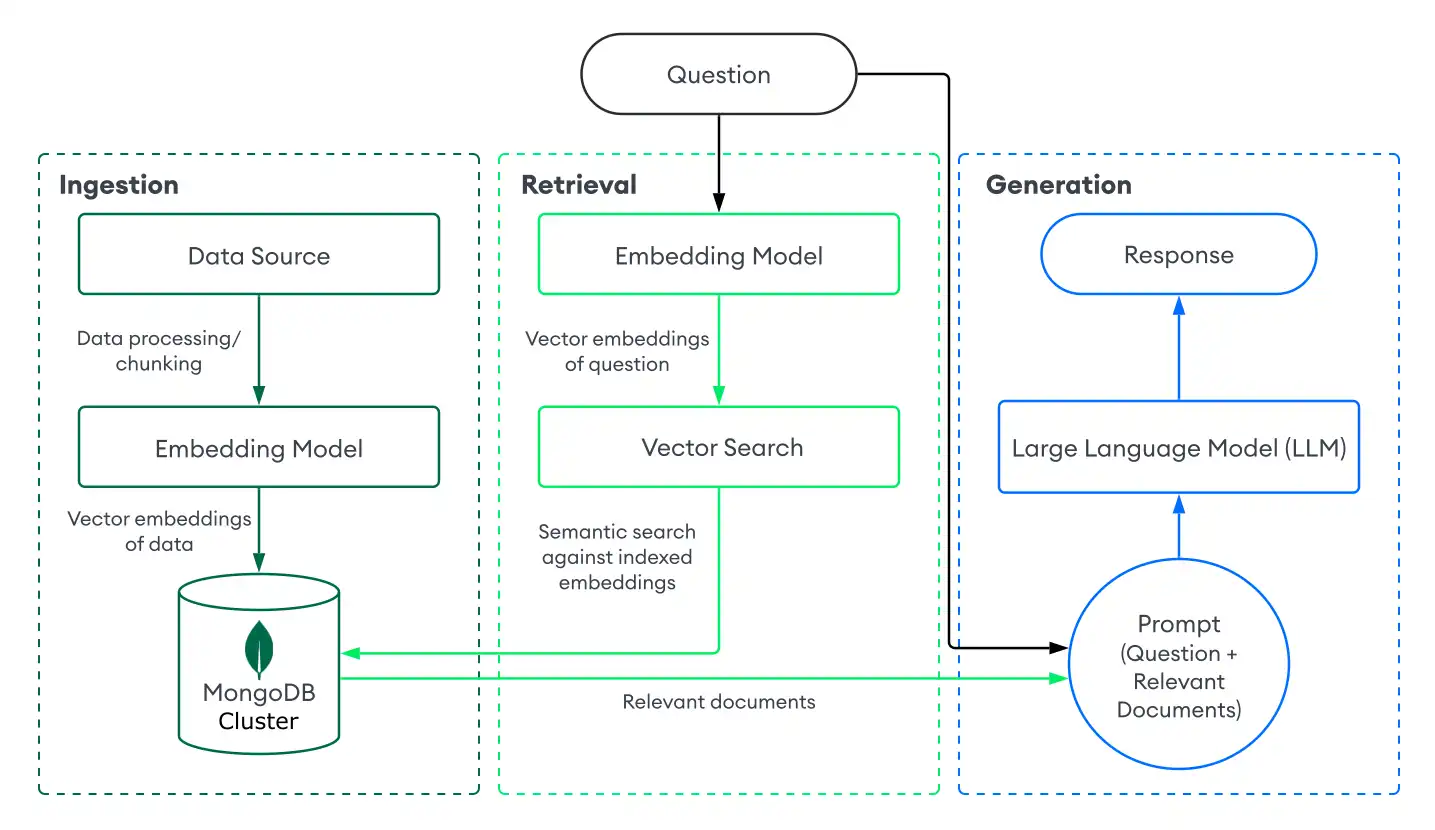
Para implementar la RAG con la búsqueda vectorial de MongoDB, debe ingerir datos en MongoDB, recuperar documentos con la búsqueda vectorial de MongoDB y generar respuestas utilizando un LLM. Esta sección describe los componentes de una implementación básica o ingenua de la RAG con la búsqueda vectorial de MongoDB. Para obtener instrucciones paso a paso, consulte el Tutorial.

Duración: 5 minutos
Ingestión
La ingesta de datos para RAG implica el procesamiento de tus datos personalizados y almacenarlos en una base de datos vectorial para prepararlos para la recuperación. Para crear un pipeline de ingestión básico con MongoDB como base de datos vectorial, haz lo siguiente:
Prepare sus datos.
Se debe cargar, procesar y dividir en fragmentos los datos para prepararlos para la aplicación RAG. La fragmentación implica dividir los datos en partes más pequeñas para una recuperación óptima.
Convierte los datos en incrustaciones vectoriales.
Convierte tus datos en embeddings vectoriales utilizando un modelo de embebimiento. Para obtener más información, consulte Cómo crear embebimientos vectoriales manualmente.
Almacena los datos y las incrustaciones en MongoDB.
Se deben almacenar estas incrustaciones en el clúster. Se deben almacenar las incrustaciones como un campo junto a otros datos en la colección.
Retrieval
Construir un sistema de recuperación implica buscar y devolver los documentos más relevantes de su base de datos vectorial para aumentar el LLM con. Para recuperar documentos relevantes con la búsqueda vectorial de MongoDB, convierta la pregunta del usuario en incrustaciones vectoriales y ejecute un query de búsqueda vectorial sobre los datos de su colección de MongoDB para identificar los documentos con las incrustaciones más similares.
Para realizar una recuperación básica con la búsqueda vectorial de MongoDB, realice lo siguiente:
Defina un índice de búsqueda vectorial de MongoDB en la colección que contiene sus incrustaciones vectoriales.
Elija uno de los siguientes métodos para recuperar documentos según la pregunta del usuario:
Utilice una integración de búsqueda vectorial de MongoDB con un marco o servicio popular. Estas integraciones incluyen librerías y herramientas con funcionalidad incorporada que le permiten desarrollar fácilmente sistemas de recuperación con la búsqueda vectorial de MongoDB.
Desarrolle su propio sistema de recuperación. Puede definir sus propias funciones y pipelines para ejecutar consultas de búsqueda vectorial de MongoDB específicas para su caso de uso.
Para aprender a desarrollar un sistema de recuperación básico con la búsqueda vectorial de MongoDB, consulte Tutorial.
Generación
Para generar respuestas, se deben combinar los sistema de recuperación con un LLM. Después de realizar una búsqueda vectorial para recuperar documentos relevantes, se debe proporcionar la pregunta del usuario junto con los documentos relevantes como contexto al LLM para que pueda generar una respuesta más precisa.
Elija uno de los siguientes métodos para conectarse a un LLM:
Utilice una integración de búsqueda vectorial de MongoDB con un marco o servicio popular. Estas integraciones incluyen librerías y herramientas con funcionalidad incorporada para ayudarle a conectarse a LLMs con una configuración mínima.
Llama a la API del LLM. La mayoría de los proveedores de IA ofrecen API a sus modelos generativos que puedes usar para generar respuestas.
Cargue un LLM de código abierto. Si no dispone de claves ni créditos de API, puede utilizar un LLM de código abierto cargándolo localmente desde su aplicación. Para ver una implementación de ejemplo, consulte el tutorial Crear una implementación local de RAG con búsqueda vectorial de MongoDB.
Tutorial
El siguiente ejemplo demuestra cómo implementar la RAG con un sistema de recuperación impulsado por la búsqueda vectorial de MongoDB. Seleccione su modelo de incrustación preferido, LLM y lenguaje de programación para empezar:
Próximos pasos
Para tutoriales adicionales de RAG, consulta los siguientes recursos:
Para aprender a implementar la RAG con marcos de trabajo LLM y servicios de IA populares, consulte Integraciones de IA de MongoDB.
Para aprender cómo implementar la RAG usando una implementación local de Atlas y modelos locales, consulte Crear una implementación local de RAG con búsqueda vectorial de MongoDB.
Para tutoriales basados en casos de uso y cuadernos interactivos de Python,consulte el Repositorio de cuadernos de documentación.y repositorio de casos de uso de IA generativa.
Para crear agentes de IA e implementar RAG agéntico, consulta Compilar agentes de IA con MongoDB.
Mejore sus resultados
Para optimizar sus aplicaciones RAG, asegúrese de utilizar un potente modelo de incrustación como Voyage IA para generar incrustaciones vectoriales de alta calidad.
Además, la búsqueda vectorial de MongoDB brinda soporte a sistemas de recuperación avanzados. Puede crear un índice para los datos vectoriales junto con los demás datos de su clúster sin problemas. Esto le permite mejorar sus resultados mediante el prefiltro en otros campos de su colección o realizar una búsqueda híbrida que combina la búsqueda semántica con los resultados de la búsqueda de texto completo.
También puede utilizar los siguientes recursos: