Añada sugerencias rápidas y relevantes mientras escribe en su aplicación, incorporando el contexto del usuario y los factores de clasificación específicos del dominio.
caso de uso: Gestión de contenidos, Catálogo
Industrias: Comercio minorista
Productos: MongoDB Atlas, Búsqueda Vectorial en MongoDB Atlas
Descripción general de la solución
La funcionalidad as-you-type, también conocida como autocompletar, autocompletar o búsqueda predictiva, a menudo se refiere a la coincidencia de caracteres de bajo nivel, en lugar de una solución integral diseñada para un propósito específico. Esta funcionalidad le ayuda a navegar rápidamente hacia el contenido deseado y relevante. Buscar la película "The Matrix" escribiendo "matr" en la barra de búsqueda es un ejemplo de funcionalidad mientras se escribe.
La búsqueda vectorial y la búsqueda de texto completo son muy buenas para hacer coincidir contenido semánticamente cuando hay una query completa o coincidencias de palabras muy cercanas. Sin embargo, una funcionalidad integrada de autocompletado puede devolver resultados relevantes con incluso menos caracteres y mayor distancia entre la entrada de texto y la palabra clave objetivo. Esta solución basada en léxico facilita la coincidencia parcial y proporciona resultados pertinentes sensibles al contexto.
Arquitecturas de Referencia
La solución de sugerencia mientras escribes es arquitectónicamente sencilla. Mientras escribe, las solicitudes se envían a Atlas Search, que devuelve resultados relevantes. La arquitectura está estructurada en torno a una colección entities especializada y las correspondientes consultas.
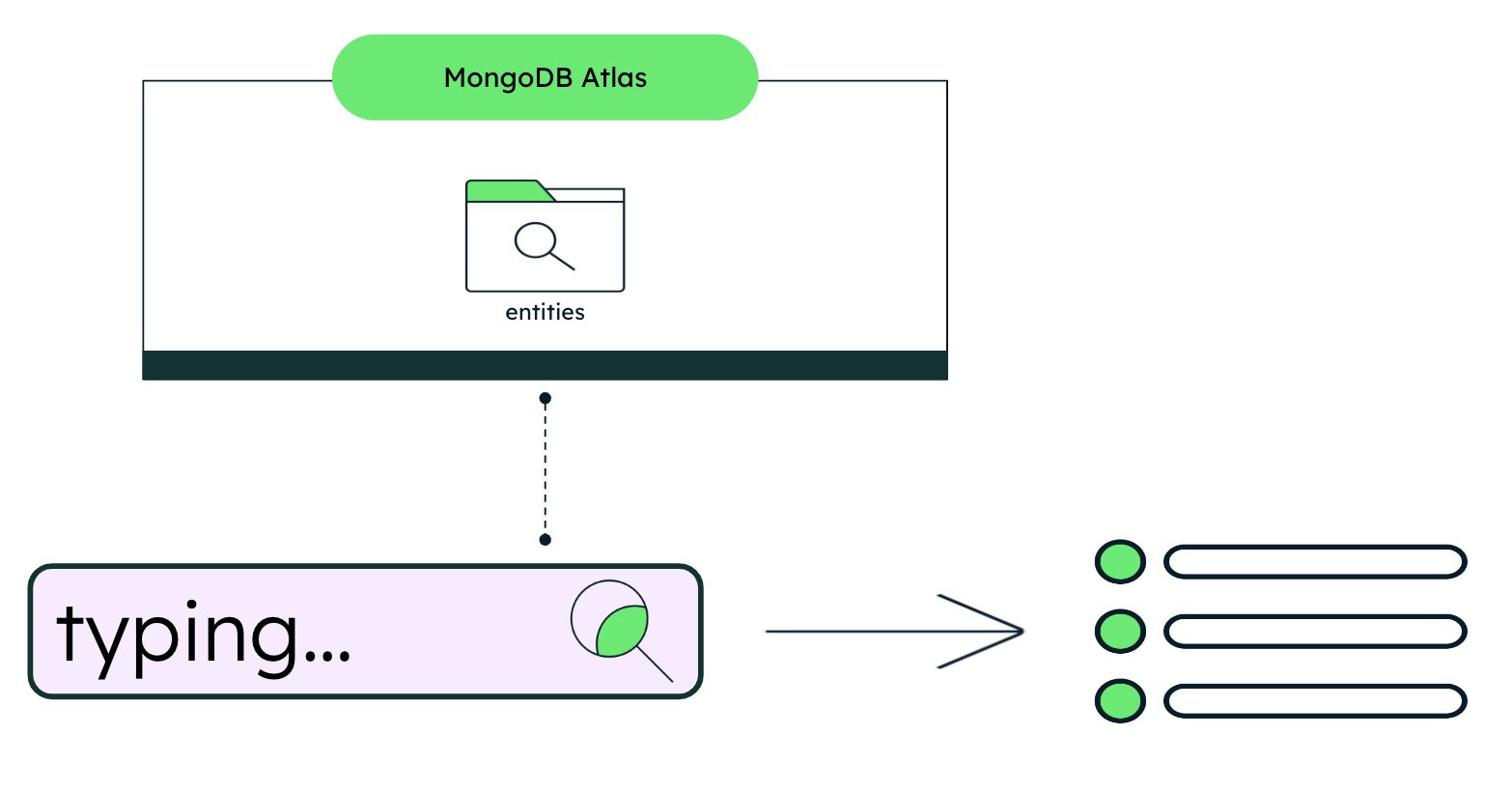
Figura 1. Arquitectura de solución justo cuando escribes
Enfoque de modelo de datos
Cada sugerencia que se presenta al usuario representa una entidad única del dominio. Las entidades deben modelarse como documentos individuales en una colección especializada optimizada para sugerencias a medida que se escribe.
La colección principal suele representar un tipo de entidad como documentos, y otras entidades de dominio como campos de metadatos o documentos incrustados. Por ejemplo, considera usar los datos de películas de muestra disponibles en Atlas. Mientras escribes, la búsqueda sugiere nombres de películas. Sin embargo, también puedes buscar nombres de miembros del reparto. Por ejemplo, puedes encontrar películas protagonizadas por Keanu Reeves con solo escribir "kea".
El modelo de datos tiene el siguiente esquema:
_idID único para esta colección en la forma<type>-<natural id>.type: tipo de entidad/tipo de objeto Realm, p. ej. película, marca, persona, producto y categoría.nameel nombre o título de la entidad, que generalmente sería único por tipo.
Es importante que los documentos de entidad tengan identificadores únicos y estables, ya que las entidades se actualizan regularmente a partir de la colección principal. Asignar un type a cada entidad permite filtrar (solo sugerir miembros del elenco en una búsqueda específica de actores), agrupar (organizar las sugerencias por tipo) o potenciar por tipo (dar mayor peso a las películas que a los nombres de los miembros del elenco).
Modelar entidades directamente como documentos individuales permite que cada una tenga campos de metadatos opcionales para ayudar en la clasificación, visualización, filtrado o agrupación de los mismos.
El modelo orientado a documentos envía el campo name a través de una configuración de índice sofisticada, que divide los valores de varias formas adecuadas para su consulta en distintas maneras. El poder de esta solución proviene de la unión de múltiples estrategias de indexación y consulta.
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
Compilar la solución
En primer lugar, identifica las entidades sugeribles en tus datos. En el escenario de las películas, estos incluirían títulos de películas, nombres de miembros del elenco y, quizás, también géneros y nombres de directores.
La base de este sistema de sugerencias a medida que se escribe es la siguiente:
Crea una colección
entitiesy rellénala con el esquema modelado anteriormente. Siempre que sea necesario, actualiza la colección deentities.Crear un Atlas Search
entities_indexusando una configuración de índice como se describe a continuación.Crea un sólido conjunto de cláusulas de consulta, junto con cualquier factor de impulso pertinente, dentro de una pipeline de agregación que utilice
$search.
Entidades importadoras
Aunque hay muchas formas de completar la entities colección, una forma sencilla de hacerlo es ejecutar una pipeline de agregación en la colección principal para obtener los títulos únicos de todas las películas:
[ { $group: { _id: "$title", }, }, { $project: { _id: {$concat: [ "title", "-", "$_id" ]}, type: "title", name: "$_id" } }, { $merge: { into: "entities" } } ]
La etapa $project convierte cada título de película único en el esquema entities necesario. Como esta colección tipifica cada documento, el type se codifica como un prefijo del _id generado y se agrega con el título real de la película, creando un identificador reproducible para cada título único. Incluir type en los identificadores de la entidad permite que diferentes tipos de entities con el mismo nombre sean independientes unos de otros (podría haber una película llamada “Aventura” así como el género “Aventura”).
Por último, la etapa $merge añade todos los títulos nuevos y deja los existentes intactos.
El documento resultante con las tipografías del título para “The Matrix” queda simplemente así:
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
Cada tipo de entidad potencialmente necesita su propia técnica para fusionarse en la colección entities, como en el caso de las entidades "género" y "reparto", que necesitan ser desenvueltas de sus arreglos anidados utilizando $unwind.
La importación de entidades específicas de este reparto incluye a “Keanu Reeves” como:
{ "_id":"cast-Keanu Reeves", "name":"Keanu Reeves", "type":"cast", "weight": 6.637 }
Indexación de Entidades
El campo name se indexa de diversas maneras, lo que facilitará la coincidencia parcial y la clasificación al momento de la query.
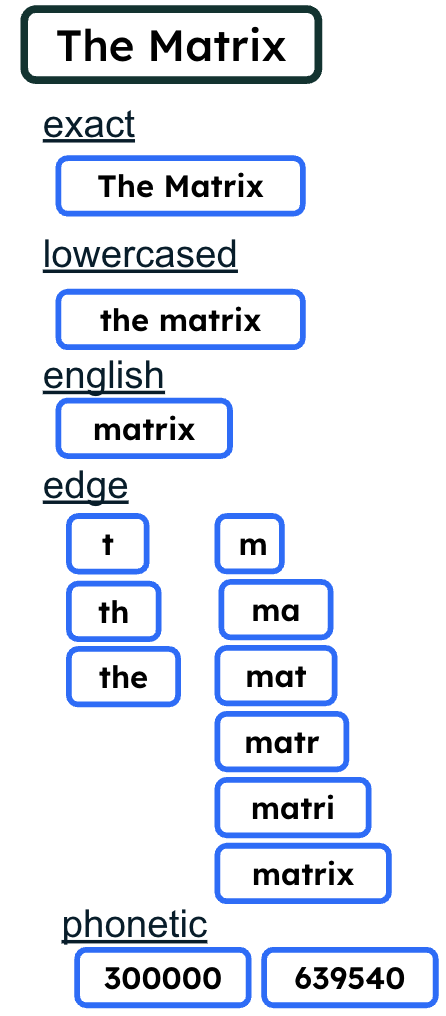
Figura 2. Estrategias de indexación múltiples
La funcionalidad multianalizadores utiliza la configuración de índice de búsqueda de Atlas para permitir que un único campo de documento se indexe de múltiples formas.
El campo type está indexado tanto como campo token, para el filtrado de equals o in, como campo stringFacet para proporcionar un medio de obtener recuentos en los resultados de cada tipo de entidad.
La definición del índice gestiona cualquier otro campo añadido además de _id, type y name, ya sea mediante mapeo dinámico o con las definiciones estáticas que proporciones. En este ejemplo, weight es personalizado y manejado dinámicamente como un tipo numérico.
Buscando sugerencias
El índice de búsqueda especializado resultante proporciona la base para consultas en tiempo real. El campo name se indexa de varias formas y se compara con los usuarios que escriben utilizando varios operadores del query ajustables. La idea es comparar los operadores del query con las asignaciones analizadas de manera diferente y ver qué coincide. Cuantos más resultados de búsqueda se encuentren, mayor será la clasificación de las sugerencias. Cada una de las cláusulas de las query puede aumentarse y sumarse de forma independiente, lo que da lugar a una puntuación de relevancia para la entidad que corresponde. Estos puntajes podrían incrementarse aún más por otros factores como un campo opcional de entidad weight.
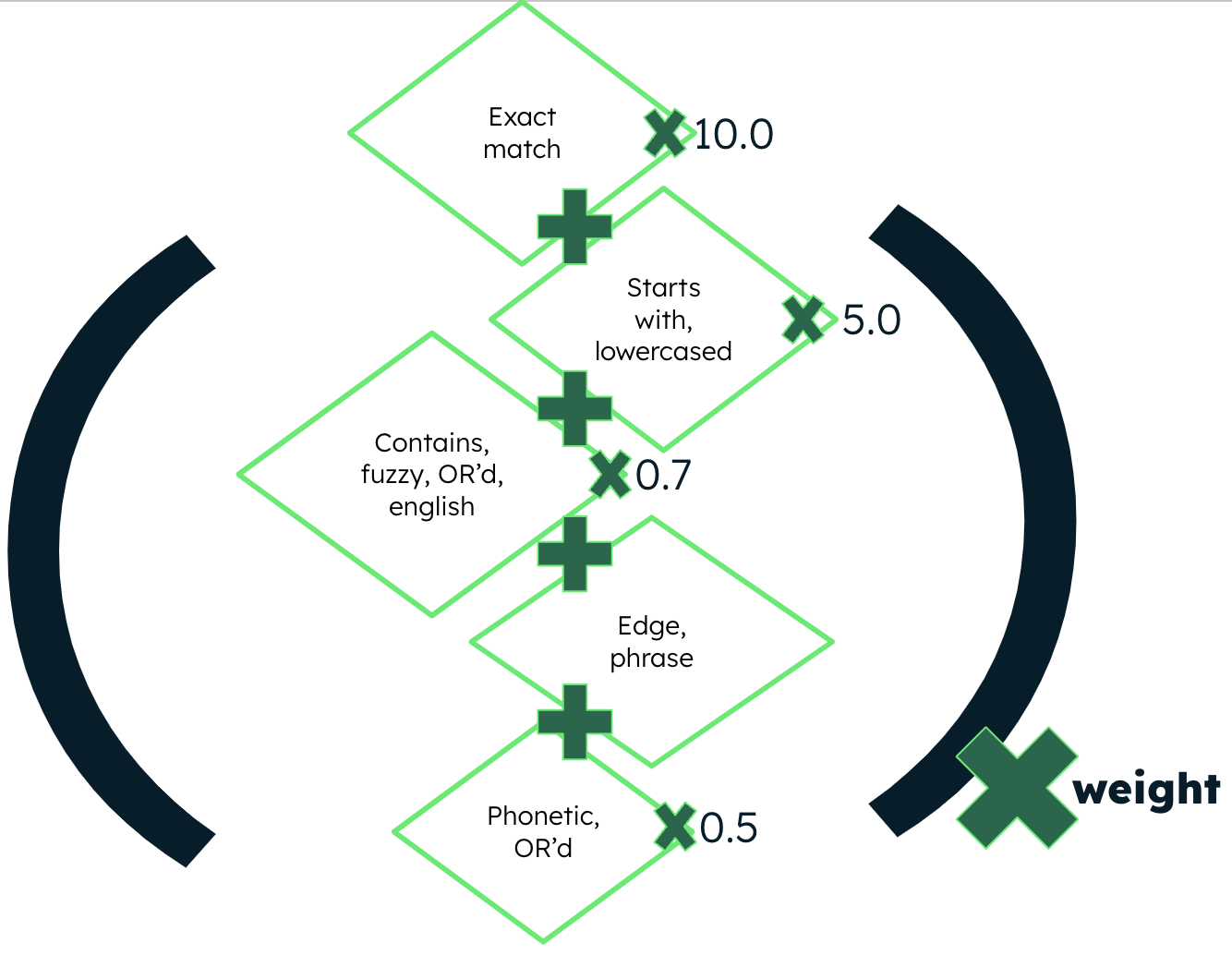
Figura 3. Ejemplo de query y cálculo de puntuación de relevancia
En general, un usuario que selecciona una sugerencia realiza a continuación una búsqueda tradicional específica para el artículo seleccionado. La búsqueda devuelve entonces todos los elementos coincidentes.
Visita el repositorio de GitHub para obtener esta solución.
Lecciones clave
Utiliza una configuración de índice especializada para modelar entidades sugestionables como documentos: Sigue los pasos anteriores para crear una colección independiente que contenga todas las entidades de cualquier fuente.
Crear un índice con estas configuraciones: Utiliza estos ajustes de índice en tu colección principal cuando todos los modelos sugieran entidades sugeribles como documentos de primer nivel.
Utiliza la estructura del índice para crear consultas ingeniosas: Utiliza tu índice para hacer coincidir entidades y clasificar sugerencias como desees.
Autores
- Erik Hatcher, MongoDB