Industrias: Seguros, Servicios Financieros, Salud
Productos y herramientas: Serie de tiempo, MongoDB Atlas Charts, MongoDB Connector for Spark, Base de datos MongoDB Atlas, Vistas materializadas de MongoDB, Pipelines de agregación
emparejar: Databricks
Resumen de la solución
Esta solución demuestra cómo usar MongoDB, aprendizaje automático y procesamiento de datos en tiempo real para automatizar el proceso de suscripción digital de vehículos conectados. Puede usar esta solución para ofrecer a los clientes primas personalizadas basadas en el uso, que tengan en cuenta sus hábitos y comportamientos.
Para hacer esto, deberá recopilar datos, enviarlos a una plataforma de aprendizaje automático para su análisis y luego utilizar los resultados para crear primas personalizadas para sus clientes. También visualizarás los datos para identificar tendencias y obtener perspectivas. Este enfoque único y personalizado brindará a tus clientes un mayor control sobre los costos de seguro y te ayudará a ofrecer precios más precisos y justos.
El repositorio de GitHub contiene instrucciones detalladas paso a paso sobre cómo cargar los datos de muestra y compilar el pipeline de transformación en MongoDB Atlas, así como cómo generar, enviar y procesar eventos hacia y desde Databricks.
Al final de esta demostración, crearás una visualización de datos con Atlas Charts que rastrea los cambios automáticos en las primas de seguros casi en tiempo real.
Puede aplicar los conceptos de esta solución a otras industrias, incluyendo:
Servicios financieros: los bancos y las instituciones financieras deben ser capaces de interpretar las transacciones financieras con sello de tiempo para el comercio, la detección de fraudes y más.
Venta minorista: Los minoristas requieren perspectivas en tiempo real sobre los datos actuales del mercado.
Atención sanitaria: desde los modos de transporte hasta los propios paquetes, los sensores IoT permiten la optimización de la cadena de suministro tanto en tránsito como en el sitio.
Arquitecturas de Referencia
El siguiente diagrama describe la arquitectura de la siguiente manera:

Figura 1. Arquitectura de referencia con MongoDB
Primero, cargue un conjunto de datos que incluya la distancia total recorrida en coche en MongoDB y ejecute una tarea cron diaria a medianoche para resumir los viajes diarios. Luego, compile los viajes diarios en un documento almacenado en una nueva colección llamada customerTripDailyEjecute una tarea cron mensual el día 25de cada mes, agregando los documentos diarios y creando una nueva colección llamada customerTripMonthly. Cada vez que se crea un nuevo resumen mensual, una función de Atlas publica la distancia total del mes y la prima de referencia en Databricks para la predicción de aprendizaje automático. La predicción de aprendizaje automático se envía de vuelta a MongoDB y se añade a customerTripMonthly. Como paso final, visualice todos sus datos con MongoDB Charts.
Enfoque de modelo de datos
Para este caso de uso, un modelo de datos básico cubre a los clientes, los viajes que realizan, las pólizas que compran y los vehículos asegurados por esas pólizas.
Este ejemplo crea tres colecciones de MongoDB y dos vistas materializadas. Puedes encontrar el modelo de datos completo para definir objetos de MongoDB en el repositorio de GitHub.

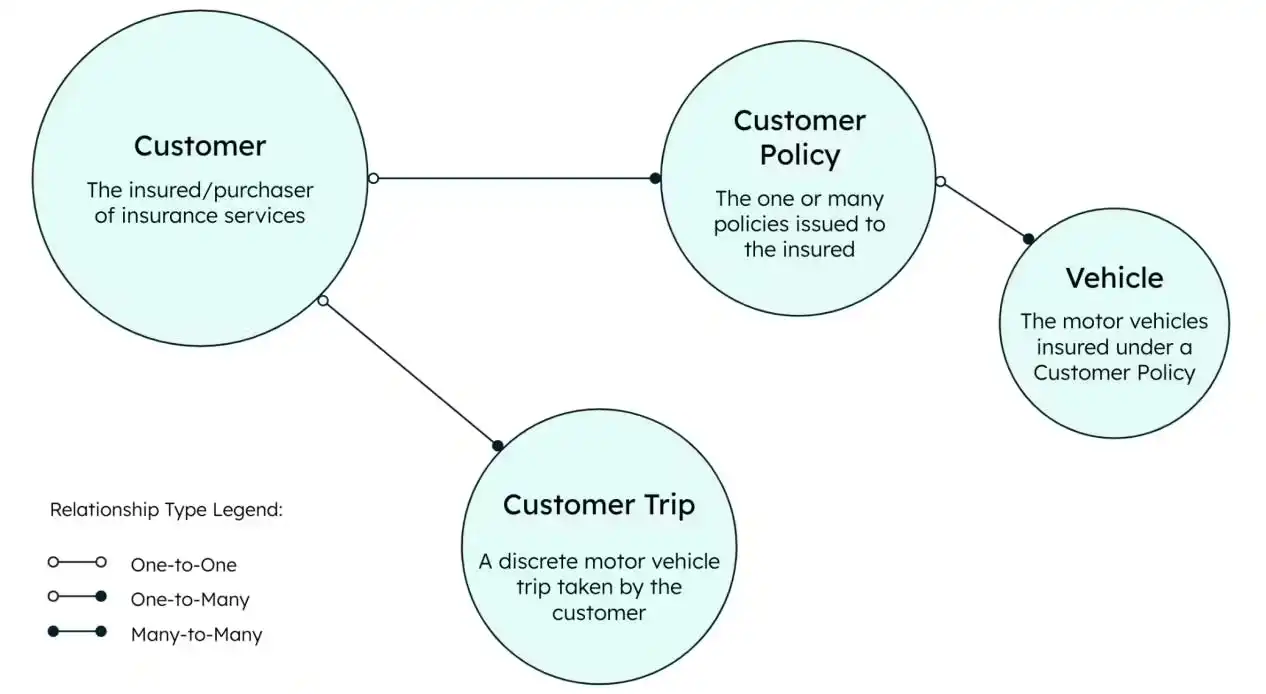
Figura 2. Enfoque del modelo de datos de MongoDB
Compilar la solución
Para replicar esta solución, consulta su repositorio de GitHub. Sigue la instrucción del repositorio,README que explica los siguientes pasos con más detalle.
Crea una pipeline de procesamiento de datos con una vista materializada
El componente del pipeline de procesamiento de datos consiste en datos de muestra, una vista materializada diaria y una vista materializada mensual. Un conjunto de datos de muestra de datos de telemetría de vehículos IoT representa los recorridos en vehículos motorizados realizados por los clientes. Se carga en la colección denominada customerTripRaw. El conjunto de datos se puede encontrar en GitHub y puede cargarse a través de mongoimport u otros métodos. Para crear una vista materializada, un activador programado ejecuta una función que ejecutar un pipeline de agregación. Esto luego genera un resumen diario de los datos IoT sin procesar y lo coloca en una colección de vista materializada llamada customerTripDaily. De manera similar, para una vista materializada mensual, un activador programado ejecuta una función que ejecuta una pipeline de agregación que resume la información en la colección customerTripDaily mensualmente y lo coloca en una colección de vistas materializadas llamada customerTripMonthly.
Consulta los siguientes repositorios de Github para crear el pipeline de procesamiento de datos:
Paso 1: Cargue los datos de muestra.
Paso 2: Configura una tarea cron diaria.

Figura 3. Crear una pipeline de procesamiento de datos
Automatice los cálculos de primas de seguros con un modelo de aprendizaje automático
El componente de procesamiento de decisiones consta de un disparador programado que recopila los datos necesarios y envía la carga útil a un punto final de la API de Databricks ML Flow. Este modelo se entrenó previamente con el conector Spark de MongoDB en Databricks. A continuación, espera a que el modelo responda con una prima calculada según los kilómetros mensuales recorridos por un cliente determinado. A continuación, el disparador programado actualiza la colección customerPolicy para añadir un nuevo cálculo de la prima mensual como un nuevo subdocumento dentro de la matriz monthlyPremium.
Consulta los siguientes repositorios de Github para crear el pipeline de procesamiento de datos:

Figura 4. Automatización de cálculos con modelo de aprendizaje automático
Visualiza cambios en las primas de seguros casi en tiempo real a lo largo del tiempo
Después de que se haya agregado la prima mensual, puedes configurar Atlas Charts para visualizar tus primas calculadas basadas en el uso. Configura diferentes gráficas para ver cómo han cambiado las primas a lo largo del tiempo y así descubrir patrones interesantes.
Lecciones clave
Aprende cómo compilar vista materializada sobre datos de series de tiempo: Consulta los pasos 1-3 en el repositorio de GitHub.
Aprovecha los pipelines de agregación para expresiones cron: consulta los pasos 2 o 3 en el Repositorio de GitHub.
Sirve modelos de aprendizaje automático con los datos de MongoDB Atlas: consulta el paso 4 en el repositorio de GitHub.
Guarde una predicción de modelo de aprendizaje automático en una base de datos Atlas: consulte los pasos 5 y 6 en el repositorio de Github.
Visualice información casi en tiempo real de los resultados del modelo en constante cambio: consulte el paso adicional en el repositorio de GitHub.
Autores
Jeff Needham, MongoDB
Ainhoa Múgica, MongoDB
Luca Napoli, MongoDB
Karolina Ruiz Rogelj, MongoDB