Atlas admite la distribución global de tus datos, para garantizar una alta disponibilidad, baja latencia y cumplimiento normativo. La planificación cuidadosa de la distribución de sus datos puede garantizar que cumpla con los requisitos de cumplimiento para soberanía de los datos, como la Ley General de Protección de Datos (GDPR) de la UE. Puedes configurar uno o más clústeres en las regiones donde necesites garantizar la soberanía de los datos y configurar tu arquitectura para guardar esos datos específicos en los clústeres o nodos correctos con una clave de partición geográfica o de zona apropiada.
El siguiente diagrama muestra una topología distribuida globalmente. Posee 3 clústeres, uno en cada una de las 3 geografías. Cada clúster tiene la misma distribución regional de 5 nodos repartidos en 3 regiones.
Esta topología permite que la aplicación envíe datos específicos de la región únicamente al clúster correspondiente. Por lo tanto, los datos de la UE cubiertos por el RGPD se escriben en el clúster 2, cuyos nodos se encuentran en la UE. De igual forma, los datos específicos de Asia-Pacífico solo se escriben en el clúster 3, donde todos los nodos se encuentran en ubicaciones de Asia-Pacífico. Los datos globales, o aquellos que no son específicos de una región, se escriben en todos los clústeres 3. Esto garantiza que la interrupción de un clúster no pueda afectar a otras partes de la aplicación.
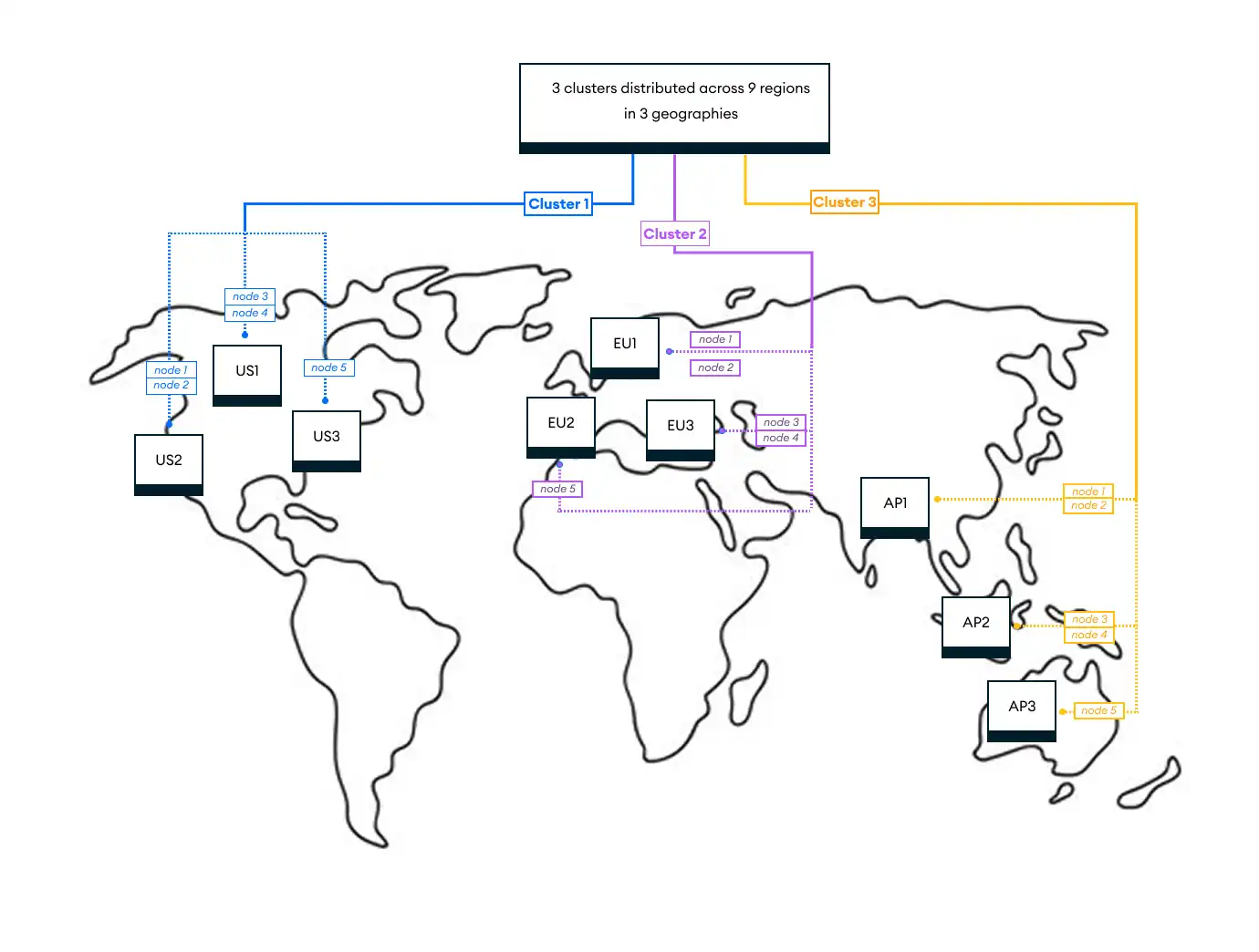
Con una gran empresa global o una aplicación global, los arquitectos pueden querer implementar clústeres en varias geografías o continentes. En general, la mejor práctica es implementar clústeres multi-región separados en cada geografía. Esto otorga a la aplicación una alta disponibilidad en una sola región y mantiene los requisitos de soberanía de datos sencillos. Una capa de proxy o redirección debe identificar de dónde proviene la solicitud y asignarla a la geografía correcta.
Aunque los clientes pueden aprovechar las implementaciones multirregión de Atlas para implementar en múltiples geografías, tienden a no evitar la complejidad que implica cumplir con los requisitos de la soberanía de los datos. Un set de réplicas replicará nativamente todos los datos a todos los nodos secundario. Para datos centrados en el usuario que deben cumplir con requisitos de soberanía, como el GDPR, esto no funcionará, y esta arquitectura solo debe considerarse para datos de referencia pública que sean los mismos a nivel global sin requisitos de soberanía. Los clústeres pueden particionarse con una clave de partición que contiene la información de la región donde los datos deben almacenarse para cumplir con los requisitos de soberanía y Atlas tiene una funcionalidad llamada Clústeres Globales, que agiliza la configuración de la clave de partición correspondiente a la zona geográfica. Sin embargo, en la práctica, las empresas optan por implementar clústeres separados en diferentes regiones para la misma aplicación a fin de no tener que lidiar con la complejidad de asegurar que el código de la aplicación esté configurando correctamente la clave de partición adecuada según la zona geográfica.
Clústeres globales
Clústeres Global Atlas se utilizan en las implementaciones más complejas y, por lo tanto, requieren un planeamiento muy cuidadoso. En casi todos los casos, un paradigma de implementación multiregión puede cubrir tus necesidades.
Podría considerar una estrategia de implementación global si:
Necesita una única cadena de conexión global.
Es necesario realizar agregaciones globales en todos los clústeres/particiones.
Necesitas la capacidad de leer/escribir para todos los clústeres/particiones desde cualquier lugar en un solo clúster lógico, y al mismo tiempo realizar lecturas/escrituras regionales.
Importante
La complejidad de los clústeres globales y las necesidades y ofertas únicas de regiones geográficas específicas, hacen que documentar unas únicas mejores prácticas sea difícil. Ponte en contacto con el equipo de Professional Services de MongoDB para discutir tus requisitos específicos.