En este tutorial, aprenderás cómo evaluar una aplicación RAG. La evaluación te ayuda a elegir el modelo correcto, garantiza que el rendimiento de tu modelo se traslade del prototipo a la producción y detecta regresiones de rendimiento.
En concreto, realizas las siguientes acciones:
Configura el entorno.
Descarga un conjunto de datos para su evaluación.
Crea fragmentos y vectores de documentos.
Incorpora los embeddings en Atlas.
Compara modelos de embedding para recuperación.
Compara modelos de finalización para generación.
Medir el rendimiento general de RAG.
Rastree el rendimiento a lo largo del tiempo con MongoDB Charts.
Nota
Este tutorial se centra en evaluar aplicaciones de LLM, no modelos de LLM. La evaluación de modelos LLM implica medir el desempeño de un modelo dado en diferentes tareas. La evaluación de la aplicación LLM consiste en evaluar diferentes componentes de una aplicación LLM, como prompts y recuperadores, así como el sistema en su conjunto.
Trabaja con una versión ejecutable de este tutorial como un cuaderno interactivo de Python.
Segundo plano
Este tutorial utiliza el marco de evaluación RAGAS de código abierto para medir el rendimiento de RAG con las siguientes métricas:
Métricas de recuperación: La precisión de contexto y el recall de contexto miden cuán bien tu recuperador encuentra información relevante.
Métricas de generación: La fidelidad y la relevancia de las respuestas miden cuán bien tu LLM genera respuestas precisas y relevantes.
Métricas generales: La similitud y corrección de las respuestas se utiliza para comparar las respuestas generadas con la verdad fundamental.
Para obtener más información sobre estas métricas, consulte Métricas RAGAS en la documentación de RAGAS.
Este tutorial utiliza el conjunto de datos ragas-wikiqa de Hugging Face, que contiene aproximadamente 230 preguntas de conocimientos generales con sus respuestas correctas.
Requisitos previos
Para completar este tutorial, debes tener lo siguiente:
Un clúster de MongoDB Atlas ejecutando MongoDB versión 6.0.11 o posterior. Asegúrate de que tu dirección IP esté en tu lista de accesodel proyecto.
Una clave API de OpenAI para utilizar los modelos de incrustaciones y chat de OpenAI.
Un terminal configurado con lo siguiente:
Python 3.10 o posterior.
Un entorno para ejecutar notebooks interactivos de Python, como VS Code o Jupyter Notebook.
Configurar el entorno
Configura tus credenciales
Ejecuta el siguiente código en tu cuaderno para configurar tu cadena de conexión MongoDB y la clave API de OpenAI:
import getpass import os from openai import OpenAI MONGODB_URI = getpass.getpass("Enter your MongoDB connection string:") os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API Key:") openai_client = OpenAI()
Descargar el conjunto de datos de evaluación
Descarga el ragas-wikiqa conjunto de datos de Hugging Face y conviértelo a un DataFrame de pandas:
from datasets import load_dataset import pandas as pd data = load_dataset("explodinggradients/ragas-wikiqa", split="train") df = pd.DataFrame(data)
El conjunto de datos contiene las siguientes columnas:
questionPregunta del usuariocorrect_answer: Respuestas del terrenocontext: Lista de textos de referencia para responder a las preguntas
Crear fragmentos de documentos
Divide los textos de referencia en fragmentos más pequeños antes de la integración:
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text by tokens using the tiktoken tokenizer text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( encoding_name="cl100k_base", keep_separator=False, chunk_size=200, chunk_overlap=30 ) def split_texts(texts): chunked_texts = [] for text in texts: chunks = text_splitter.create_documents([text]) chunked_texts.extend([chunk.page_content for chunk in chunks]) return chunked_texts # Split the context field into chunks df["chunks"] = df["context"].apply(lambda x: split_texts(x)) # Aggregate list of all chunks all_chunks = df["chunks"].tolist() docs = [item for chunk in all_chunks for item in chunk]
Tip
Experimenta con diferentes estrategias de fragmentación al evaluar la recuperación. Este tutorial se centra en la evaluación de modelos de incrustación.
Crea incrustaciones e ingléstelas en MongoDB Charts
Incorporar los documentos fragmentados e integrarlos en Atlas. Crea colecciones separadas para cada modelo de embedding que quieras comparar:
Definir una función de incorporación
Cree una función para generar incrustaciones utilizando la API de OpenAI:
from typing import List def get_embeddings(docs: List[str], model: str) -> List[List[float]]: """Generate embeddings using the OpenAI API.""" docs = [doc.replace("\n", " ") for doc in docs] response = openai_client.embeddings.create(input=docs, model=model) return [r.embedding for r in response.data]
Ingestar incrustaciones en Atlas
Incrusta e ingiere los documentos particionados en colecciones de Atlas:
from pymongo import MongoClient from tqdm.auto import tqdm client = MongoClient(MONGODB_URI) DB_NAME = "ragas_evals" db = client[DB_NAME] batch_size = 128 EVAL_EMBEDDING_MODELS = ["text-embedding-ada-002", "text-embedding-3-small"] for model in EVAL_EMBEDDING_MODELS: embedded_docs = [] print(f"Getting embeddings for the {model} model") for i in tqdm(range(0, len(docs), batch_size)): end = min(len(docs), i + batch_size) batch = docs[i:end] batch_embeddings = get_embeddings(batch, model) batch_embedded_docs = [ {"text": batch[i], "embedding": batch_embeddings[i]} for i in range(len(batch)) ] embedded_docs.extend(batch_embedded_docs) collection = db[model] collection.delete_many({}) collection.insert_many(embedded_docs) print(f"Finished inserting embeddings for the {model} model")
Crear índices de búsqueda vectorial
Cree un índice de búsqueda vectorial de MongoDB para cada colección. Utilice la siguiente definición de índice con el nombre del índice vector_index:
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
Para aprender a crear el índice, consulta Crear un índice de búsqueda vectorial de MongoDB.
Tip
Tanto text-embedding-ada-002 como text-embedding-3-small tienen 1536 dimensiones, por lo que la misma definición de índice funciona para ambas colecciones.
Comparar modelos de incrustación
Para asegurarte de recuperar el contexto adecuado para el LLM, compara diferentes modelos de embedido. Este tutorial compara text-embedding-ada-002 y text-embedding-3-small.
Crear una función de recuperador
Crea una función para obtener un recuperador del almacén vectorial usando LangChain y MongoDB Atlas:
from langchain_openai import OpenAIEmbeddings from langchain_mongodb import MongoDBAtlasVectorSearch from langchain_core.vectorstores import VectorStoreRetriever def get_retriever(model: str, k: int) -> VectorStoreRetriever: """ Get a vector store retriever for a given embedding model. Args: model (str): Embedding model to use k (int): Number of results to retrieve Returns: VectorStoreRetriever: A vector store retriever object """ embeddings = OpenAIEmbeddings(model=model) vector_store = MongoDBAtlasVectorSearch.from_connection_string( connection_string=MONGODB_URI, namespace=f"{DB_NAME}.{model}", embedding=embeddings, index_name="vector_index", text_key="text", ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": k} ) return retriever
Evalúa al recuperador
Use las métricas context_precision y context_recall de la librería RAGAS para evaluar cada modelo de embedding:
from datasets import Dataset from ragas import evaluate, RunConfig from ragas.metrics import context_precision, context_recall import nest_asyncio # Allow nested use of asyncio (used by RAGAS) nest_asyncio.apply() for model in EVAL_EMBEDDING_MODELS: data = {"question": [], "ground_truth": [], "contexts": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH retriever = get_retriever(model, 2) # Get relevant documents for the evaluation dataset for i in tqdm(range(0, len(QUESTIONS))): data["contexts"].append( [doc.page_content for doc in retriever.invoke(QUESTIONS[i])] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[context_precision, context_recall], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
Los resultados de la evaluación de los modelos de embedding en el conjunto de datos de muestra son los siguientes:
Modelo | Precisión contextual | Recuperación de contexto |
|---|---|---|
text-embedding-ada-002 | 0.9310 | 0.8561 |
text-embedding-3-pequeño | 0.9116 | 0.8826 |
En base a estos resultados, text-embedding-ada-002 clasifica los resultados más relevantes en una posición más alta, pero text-embedding-3-small recupera contextos que están más alineados con las respuestas de referencia. Para este tutorial, utiliza text-embedding-3-small como el modelo de incrustación.
Comparar modelos de finalización
Ahora que ha seleccionado el mejor modelo de embedding, compare los modelos de completado para el componente de generación de su aplicación RAG.
Crear una cadena RAG
Crea una función que compile una cadena RAG usando LangChain:
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.runnables.base import RunnableSequence from langchain_core.output_parsers import StrOutputParser def get_rag_chain(retriever: VectorStoreRetriever, model: str) -> RunnableSequence: """ Create a basic RAG chain. Args: retriever (VectorStoreRetriever): Vector store retriever object model (str): Chat completion model to use Returns: RunnableSequence: A RAG chain """ # Generate context using the retriever, and pass the user question through retrieve = { "context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough(), } template = """Answer the question based only on the following context: \ {context} Question: {question} """ # Define the chat prompt prompt = ChatPromptTemplate.from_template(template) # Define the model for chat completion llm = ChatOpenAI(temperature=0, model=model) # Parse output as a string parse_output = StrOutputParser() # RAG chain rag_chain = retrieve | prompt | llm | parse_output return rag_chain
Evalúe los modelos de finalización
Utiliza las métricas faithfulness y answer_relevancy para evaluar diferentes modelos de finalización:
from ragas.metrics import faithfulness, answer_relevancy for model in ["gpt-3.5-turbo-1106", "gpt-3.5-turbo"]: data = {"question": [], "ground_truth": [], "contexts": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) rag_chain = get_rag_chain(retriever, model) for i in tqdm(range(0, len(QUESTIONS))): question = QUESTIONS[i] data["answer"].append(rag_chain.invoke(question)) data["contexts"].append( [doc.page_content for doc in retriever.invoke(question)] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
Los resultados de la evaluación de los modelos de finalización en el conjunto de datos de muestra son los siguientes:
Modelo | Fidelidad | Relevancia de la respuesta |
|---|---|---|
gpt-3.5-turbo | 0.9714 | 0.9087 |
gpt-3.5-turbo-1106 | 0.9671 | 0.9105 |
Según estos resultados, la versión más reciente de gpt-3.5-turbo genera resultados más coherentes a nivel fáctico, mientras que la versión anterior proporciona respuestas más pertinentes al prompt dado. Para este tutorial, utilice gpt-3.5-turbo como el modelo de finalización.
Tip
Si no desea elegir entre métricas, considere crear métricas consolidadas utilizando una suma ponderada, o personalizar las indicaciones utilizadas para la evaluación.
Medir el rendimiento general
Evalúa el rendimiento general de tu aplicación de RAG utilizando los modelos con mejor rendimiento:
from ragas.metrics import answer_similarity, answer_correctness data = {"question": [], "ground_truth": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) # Use the best completion model from the generator evaluation rag_chain = get_rag_chain(retriever, "gpt-3.5-turbo") for question in tqdm(QUESTIONS): data["answer"].append(rag_chain.invoke(question)) dataset = Dataset.from_dict(data) run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[answer_similarity, answer_correctness], run_config=run_config, raise_exceptions=False, ) print(f"Overall metrics: {result}")
Esta evaluación demuestra que la cadena RAG produce una similitud de respuesta de 0.8873 y una corrección de respuesta de 0.5922 en el conjunto de muestra.
Analizar Resultados
Para investigar más a fondo los resultados, conviértalos en un dataframe de pandas y aplique un filtro a las respuestas con baja puntuación:
result_df = result.to_pandas() result_df[result_df["answer_correctness"] < 0.7]
Para un análisis visual, genera un mapa de calor de preguntas frente a métricas:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) sns.heatmap( result_df[1:10].set_index("question")[["answer_similarity", "answer_correctness"]], annot=True, cmap="flare", ) plt.show()
El código anterior produce el siguiente mapa de calor:
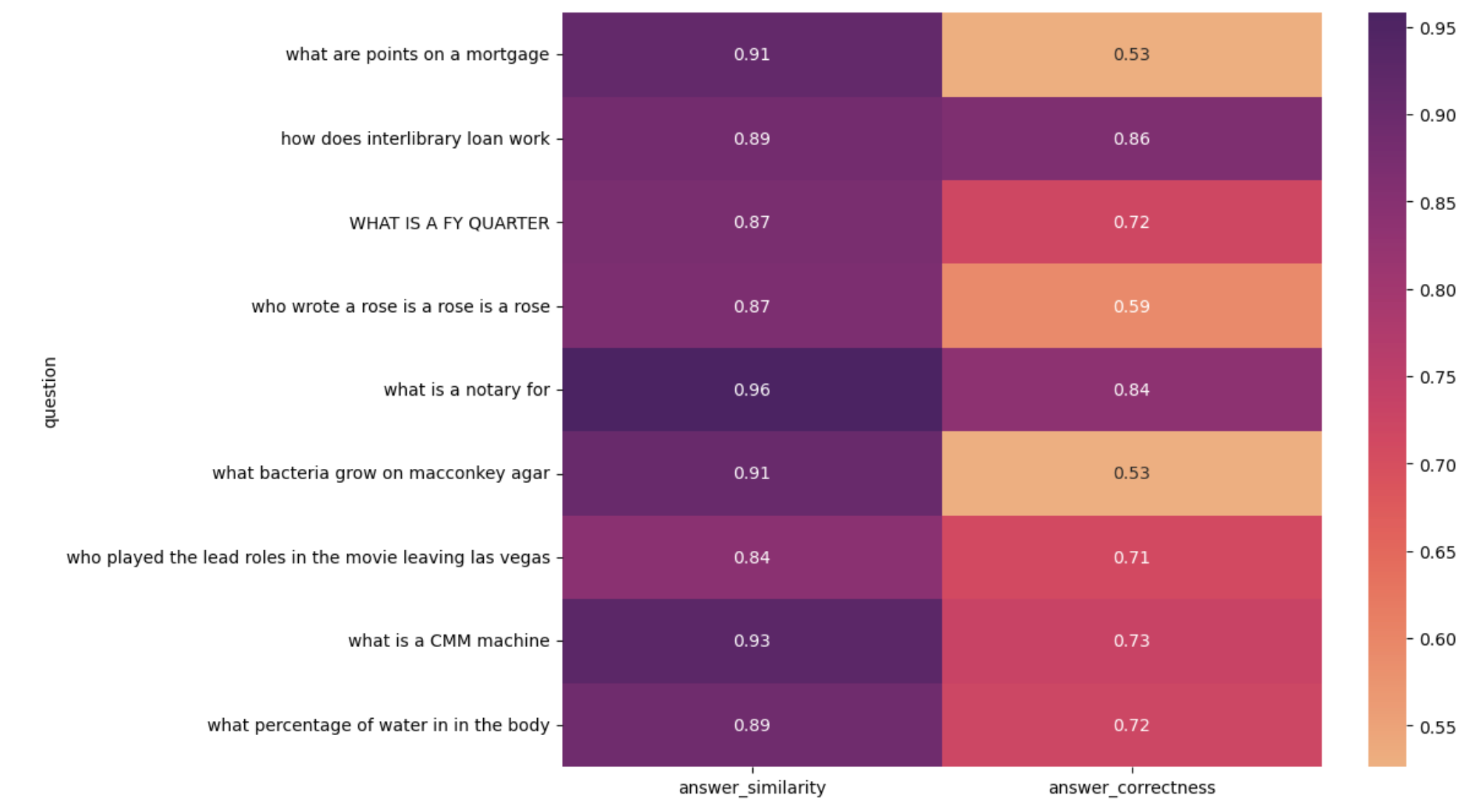
Mapa de calor que visualiza el rendimiento de la aplicación RAG (Recuperación-Generación Aumentada)
Al investigar los resultados de baja puntuación, podría encontrar:
Algunas respuestas de verdad factual en el conjunto de datos de evaluación son incorrectas. Aunque la respuesta generada por el LLMes correcta, no coincide con la verdad fundamental, lo que resulta en una puntuación baja.
Algunas respuestas verídicas son oraciones completas, mientras que la respuesta generada por LLMes una sola palabra o número.
Estos hallazgos enfatizan la importancia de la verificación aleatoria de las evaluaciones de LLM y la elaboración de conjuntos de datos de evaluación precisos.
Rastrea el rendimiento a lo largo del tiempo
La evaluación no debe ser un evento de una sola vez. Cada vez que cambies un componente en tu sistema, evalúa los cambios para determinar cómo tienen un impacto en el rendimiento. Una vez que su aplicación se encuentre en producción, supervise el rendimiento en tiempo real y detecte cambios.
Use Charts para supervisar el rendimiento de tu aplicación LLM. Escribe los resultados de la evaluación y cualquier métrica de retroalimentación que quieras rastrear en una colección de Atlas:
from datetime import datetime result["timestamp"] = datetime.now() collection = db["metrics"] collection.insert_one(result)
Este código añade un campo timestamp al resultado de la evaluación y lo escribe en una colección metrics en la base de datos ragas_evals. El documento en Atlas se ve así:
{ "answer_similarity": 0.8873, "answer_correctness": 0.5922, "timestamp": "2024-04-07T23:27:30.655+00:00" }
Crea un tablero en MongoDB Charts para visualizar tus métricas a lo largo del tiempo. Para aprender a compilar gráficas y tableros, consulta Compila gráficas.
Resumen
En este tutorial, aprendiste a evaluar una aplicación RAG usando el framework RAGAS y MongoDB Atlas. Comparaste modelos de incrustación para recuperación, modelos de finalización para generación y mediste el rendimiento general de tu aplicación. También aprendiste a rastrear el rendimiento a lo largo del tiempo utilizando MongoDB Charts.
Para obtener más información sobre cómo crear aplicaciones RAG con MongoDB, consulta Comenzar con la integración de MongoDB LangChain.