Note
Atlas is currently available as a knowledge base in AWS regions located in the United States only.
You can use MongoDB Atlas as a knowledge base for Amazon Bedrock to build generative AI applications, implement retrieval-augmented generation (RAG), and build agents.
Overview
The Amazon Bedrock Knowledge Base integration with Atlas enables the following use cases:
Use foundation models with MongoDB Vector Search to build AI applications and implement RAG. To get started, see Get Started.
Enable hybrid search with MongoDB Vector Search and MongoDB Search for your knowledge base. To learn more, see Hybrid Search with Amazon Bedrock and Atlas.
Get Started
This tutorial demonstrates how to start using MongoDB Vector Search with Amazon Bedrock. Specifically, you perform the following actions:
Load custom data into an Amazon S3 bucket.
Optionally, configure an endpoint service using AWS PrivateLink.
Create a MongoDB Vector Search index on your data.
Create a knowledge base to store data on Atlas.
Create an agent that uses MongoDB Vector Search to implement RAG.
Background
Amazon Bedrock is a fully-managed service for building generative AI applications. It allows you to leverage foundation models (FMs) from various AI companies as a single API.
You can use MongoDB Vector Search as a knowledge base for Amazon Bedrock to store custom data in Atlas and create an agent to implement RAG and answer questions on your data. To learn more about RAG, see Retrieval-Augmented Generation (RAG) with MongoDB.
Prerequisites
To complete this tutorial, you must have the following:
Load Custom Data
If you don't already have an Amazon S3 bucket that contains text data, create a new bucket and load the following publicly accessible PDF about MongoDB best practices:
Download the PDF.
Navigate to the Best Practices Guide for MongoDB.
Click either Read Whitepaper or Email me the PDF to access the PDF.
Download and save the PDF locally.
Upload the PDF to an Amazon S3 bucket.
Follow the steps to create an S3 Bucket. Ensure that you use a descriptive Bucket Name.
Follow the steps to upload a file to your Bucket. Select the file that contains the PDF that you just downloaded.
Configure an Endpoint Service
By default, Amazon Bedrock connects to your knowledge base over the public internet. To further secure your connection, MongoDB Vector Search supports connecting to your knowledge base over a virtual network through an AWS PrivateLink endpoint service.
Optionally, complete the following steps to enable an endpoint service that connects to an AWS PrivateLink private endpoint for your Atlas cluster:
Set up a private endpoint in Atlas.
Follow the steps to set up a AWS PrivateLink private endpoint for your Atlas cluster. Ensure that you use a descriptive VPC ID to identify your private endpoint.
For more information, see Learn About Private Endpoints in Atlas.
Configure the endpoint service.
MongoDB and partners provide a Cloud Development Kit (CDK) that you can use to configure an endpoint service backed by a network load balancer that forwards traffic to your private endpoint.
Follow the steps specified in the CDK GitHub Repository to prepare and run the CDK script.
Create the MongoDB Vector Search Index
In this section, you set up Atlas as a vector database, also called a vector store, by creating a MongoDB Vector Search index on your collection.
Required Access
To create a MongoDB Vector Search index, you must have Project Data Access Admin or higher access to the Atlas project.
Procedure
In Atlas, go to the Data Explorer page for your project.
If it's not already displayed, select the organization that contains your project from the Organizations menu in the navigation bar.
If it's not already displayed, select your project from the Projects menu in the navigation bar.
In the sidebar, click Data Explorer under the Database heading.
The Data Explorer displays.
IMPORTANT: You can also click the name of a cluster to open the Cluster sidebar, and then click Data Explorer under the Shortcuts heading.
In Atlas, go to the Search & Vector Search page for your cluster.
You can go the MongoDB Search page from the Search & Vector Search option, or the Data Explorer.
If it's not already displayed, select the organization that contains your project from the Organizations menu in the navigation bar.
If it's not already displayed, select your project from the Projects menu in the navigation bar.
In the sidebar, click Search & Vector Search under the Database heading.
If you have no clusters, click Create cluster to create one. To learn more, see Create a Cluster.
If your project has multiple clusters, select the cluster you want to use from the Select cluster dropdown, then click Go to Search.
The Search & Vector Search page displays.
If it's not already displayed, select the organization that contains your project from the Organizations menu in the navigation bar.
If it's not already displayed, select your project from the Projects menu in the navigation bar.
In the sidebar, click Data Explorer under the Database heading.
Expand the database and select the collection.
Click the Indexes tab for the collection.
Click the Search and Vector Search link in the banner.
The Search & Vector Search page displays.
Start your index configuration.
Make the following selections on the page and then click Next.
Search Type | Select the Vector Search index type. |
Index Name and Data Source | Specify the following information:
|
Configuration Method | For a guided experience, select Visual Editor. |
IMPORTANT: Your |fts| index is named ``autoembed_index` by default. If you are creating multiple indexes, we recommend that you maintain a consistent, descriptive naming convention across your indexes.
Define the MongoDB Vector Search index.
This vectorSearch type index definition indexes the following fields:
embeddingfield as the vector type. Theembeddingfield contains the vector embeddings created using the embedding model that you specify when you configure the knowledge base. The index definition specifies1024vector dimensions and measures similarity usingcosine.bedrock_metadata,bedrock_text_chunk, andx-amz-bedrock-kb-document-page-numberfields as the filter type for pre-filtering your data. You will also specify these fields in Amazon Bedrock when you configure the knowledge base.
Note
If you previously created an index with the filter field page_number, you must update your index definition to use the new filter field name x-amz-bedrock-kb-document-page-number instead. Amazon Bedrock has updated the field name, and indexes using the old field name no longer work correctly with Amazon Bedrock knowledge bases.
Specify embedding as the field to index and specify 1024 dimensions.
To configure the index, do the following:
Select Cosine from the Similarity Method dropdown.
In the Filter Field section, specify the
bedrock_metadata,bedrock_text_chunk, andx-amz-bedrock-kb-document-page-numberfields to filter the data by.
Paste the following index definition in the JSON editor:
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
Check the status.
The newly created index displays on the Search & Vector Search page. While the index is building, the Status field reads Pending. When the index is finished building, the Status field reads Ready.
Note
Larger collections take longer to index. You will receive an email notification when your index is finished building.
Create a Knowledge Base
In this section, you create a knowledge base to load custom data into your vector store.
Navigate to Amazon Bedrock management console.
Log in to the AWS Console.
In the upper-left corner, click the Services dropdown menu.
Click Machine Learning, and then select Amazon Bedrock.
Manage model access.
Amazon Bedrock doesn't grant access to FMs automatically. If you haven't already, follow the steps to add model access for the Titan Embeddings G1 - Text and Anthropic Claude V2.1 models.
Create the knowledge base.
In the left navigation of the Amazon Bedrock console, click Knowledge Bases.
Click Create and then select Knowledge base with vector store.
Specify
mongodb-atlas-knowledge-baseas the Knowledge Base name.Click Next.
By default, Amazon Bedrock creates a new IAM role to access the knowledge base.
Add a data source.
Specify a name for the data source used by the knowledge base.
Enter the URI for the S3 bucket that contains your data source. Or, click Browse S3 and find the S3 bucket that contains your data source from the list.
Click Next.
Amazon Bedrock displays available embedding models that you can use to convert your data source's text data into vector embeddings.
Select the Titan Embeddings G1 - Text model.
Connect Atlas to the Knowledge Base.
In the Vector database section, select Use an existing vector store.
Select MongoDB Atlas and configure the following options:
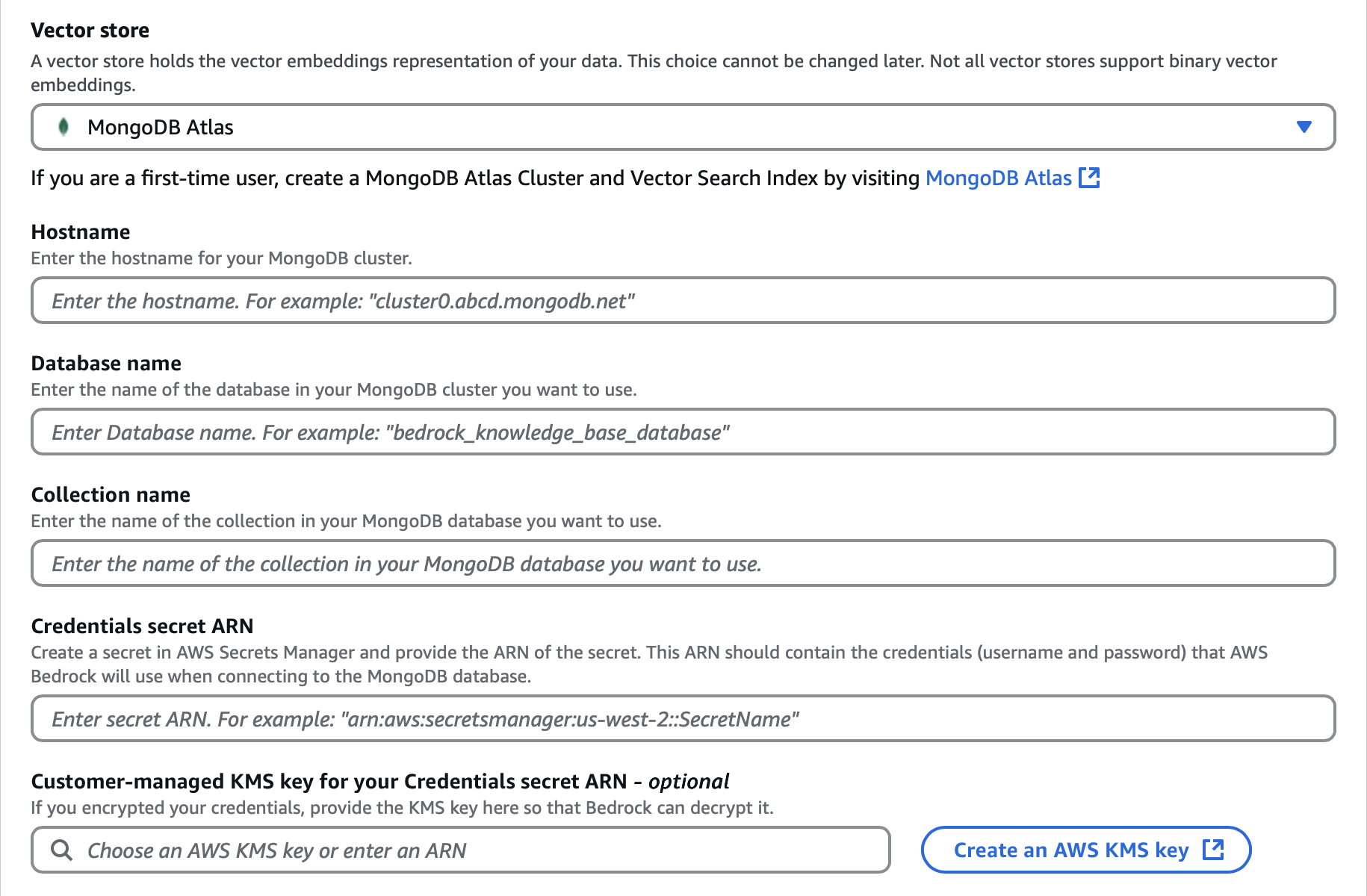 click to enlarge
click to enlargeFor the Hostname, enter the URL for your Atlas cluster located in its connection string. The hostname uses the following format:
<clusterName>.mongodb.net For the Database name, enter
bedrock_db.For the Collection name, enter
test.For the Credentials secret ARN, enter the ARN for the secret that contains your Atlas cluster credentials. To learn more, see AWS Secrets Manager concepts.
In the Metadata field mapping section, configure the following options to determine the MongoDB Vector Search index and field names that Atlas uses to embed and store your data source:
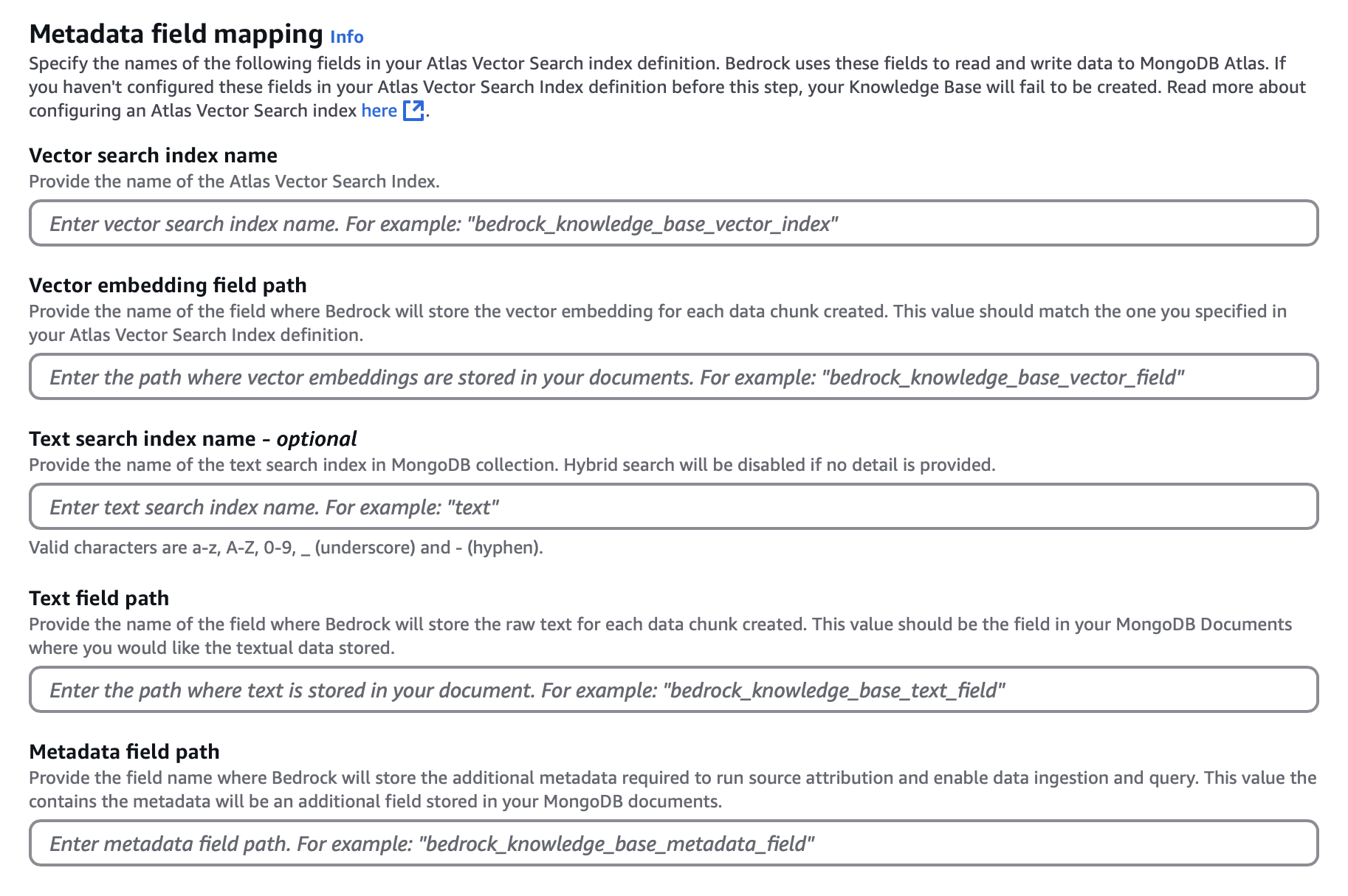 click to enlarge
click to enlargeFor the Vector search index name, enter
vector_index.For the Vector embedding field path, enter
embedding.For the Text field path, enter
bedrock_text_chunk.For the Metadata field path, enter
bedrock_metadata.
Note
Optionally, you can specify the Text search index name field to configure hybrid search. To learn more, see Hybrid Search with Amazon Bedrock and Atlas.
If you configured an endpoint service, enter your PrivateLink Service Name.
Click Next.
Sync the data source.
After Amazon Bedrock creates the knowledge base, it prompts you to sync your data. In the Data source section, select your data source and click Sync to sync the data from the S3 bucket and load it into Atlas.
When the sync completes, if you're using Atlas, you can verify your vector embeddings by navigating to the bedrock_db.test namespace in the Atlas UI.
Build an Agent
In this section, you deploy an agent that uses MongoDB Vector Search to implement RAG and answer questions on your data. When you prompt this agent, it does the following:
Connects to your knowledge base to access the custom data stored in Atlas.
Uses MongoDB Vector Search to retrieve relevant documents from your vector store based on the prompt.
Leverages an AI chat model to generate a context-aware response based on these documents.
Complete the following steps to create and test the RAG agent:
Select a model and provide a prompt.
By default, Amazon Bedrock creates a new IAM role to access the agent. In the Agent details section, specify the following:
From the dropdown menus, select Anthropic and Claude V2.1 as the provider and AI model used to answer questions on your data.
Note
Amazon Bedrock doesn't grant access to FMs automatically. If you haven't already, follow the steps to add model access for the Anthropic Claude V2.1 model.
Provide instructions for the agent so that it knows how to complete the task.
For example, if you're using the sample data, paste the following instructions:
You are a friendly AI chatbot that answers questions about working with MongoDB. Click Save.
Add the knowledge base.
To connect the agent to the knowledge base that you created:
In the Knowledge Bases section, click Add.
Select mongodb-atlas-knowledge-base from the dropdown.
Describe the knowledge base to determine how the agent should interact with the data source.
If you're using the sample data, paste the following instructions:
This knowledge base describes best practices when working with MongoDB. Click Add, and then click Save.
Test the agent.
Click the Prepare button.
Click Test. Amazon Bedrock displays a testing window to the right of your agent details if it's not already displayed.
In the testing window, enter a prompt. The agent prompts the model, uses MongoDB Vector Search to retrieve relevant documents, and then generates a response based on the documents.
If you used the sample data, enter the following prompt. The generated response might vary.
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] Tip
Click the annotation in the agent's response to view the text chunk that MongoDB Vector Search retrieved.
Other Resources
To troubleshoot issues, see Troubleshooting the Amazon Bedrock Knowledge Base Integration.