整合用户上下文与领域特定的排序因素,在您的应用程序中添加快速且相关的智能输入建议。
行业: 零售
产品: MongoDB Atlas,MongoDB Atlas Vector Search
解决方案概述
键入时功能(也称为自动完成、自动建议或预测搜索)通常指低级字符匹配,而不是专门构建的综合解决方案。此功能可帮助您快速导航到所需的相关内容。通过在搜索栏中键入“matr”来查找电影“黑客帝国”,就是“键入时”功能的一个示例。
当存在完整查询或非常接近的单词匹配时,向量搜索和全文搜索非常适合从语义上匹配内容。但是,集成的“键入时”功能可以返回相关结果,其中包含的字符更少,并且文本输入与目标关键字之间的距离更大。这种基于词法的解决方案有利于部分匹配,并提供相关的上下文相关结果。
参考架构
键入时建议解决方案在架构上非常简单。在您键入时,请求将发送到Atlas Search,后者会返回相关结果。该架构围绕专门的 entities集合和相应的查询构建。


图1.输入即搜解决方案架构
数据模型方法
提供给用户的每个建议都代表域中的一个唯一实体。实体必须建模为专门集合中的单个文档,该集合针对键入时的建议性进行了调整。
主集合通常将一种类型的实体表示为文档,并将其他领域实体表示为元数据字段或嵌入式文档。示例,考虑使用Atlas中提供的示例电影数据。键入时,搜索会建议电影名称。不过,您也可以搜索演职人员姓名。示例,您只需键入“kea”即可查找由基努·里维斯 (Keanu Reeves) 主演的电影。
数据模型具有以下模式:
_id:此集合的唯一 ID,格式为<type>-<natural id>。type:实体/对象类型,例如电影、品牌、产品和类别。name:实体的名称或标题,通常每种类型都是唯一的。
实体文档具有稳定、唯一的标识符非常重要,因为实体会定期从主集合中刷新。为每个实体分配 type 可以支持筛选(仅在特定于演员的查找中建议演员)、分组(按类型组织建议)或按类型提升(电影的权重高于演员姓名)。
将实体直接建模为独立文档,可使每个文档携带可选元数据字段,用于辅助排序、展示、过滤或分组操作。
文档模型通过复杂的索引配置为 name字段提供数据,索引以多种适合多种方式查询的方式划分值。 该解决方案的强大之处在于结合了多种索引和查询策略。
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
构建解决方案
首先,识别数据中可建议的实体。在电影场景中,这些信息将包括电影标题、演员姓名,也许还包括类型和导演姓名。
这种键入建议系统的基础如下:
创建一个
entities集合,并使用上面建模的模式进行填充。只要有保证,请经常刷新entities集合。使用索引配置创建Atlas Search
entities_index,如下所述。在使用
$search的聚合管道中制作一设立强大的查询子句以及任何相关的提升因子。
导入实体
虽然填充 entities集合的方法有多种,但一种直接的填充方法是在主集合上运行聚合管道,以引入所有电影的唯一标题:
[ { $group: { _id: "$title", }, }, { $project: { _id: {$concat: [ "title", "-", "$_id" ]}, type: "title", name: "$_id" } }, { $merge: { into: "entities" } } ]
$project 阶段将每个唯一的电影标题转换为必要的 entities模式。由于该集合对每个文档进行类型化,因此 type 被编码为生成的 _id 的前缀,并附加实际的电影标题,为每个唯一标题创建了可重复的标识符。在实体标识符中包含 type 允许具有相同名称的不同类型的 entities 彼此独立(可能有名为“冒险”的电影以及“冒险”类型)。
最后,$merge 阶段会添加所有新标题并保持现有标题不变。
“The Matrix”的最终标题类型文档如下所示:
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
每种实体类型都可能需要自己的技术来合并到 entities集合中,例如“流派”和“演员”实体,需要使用 $unwind 从其嵌套数组中展开。
此演员特定的实体导入将“Keanu Reeves”作为:
{ "_id":"cast-Keanu Reeves", "name":"Keanu Reeves", "type":"cast", "weight": 6.637 }
索引实体
name 字段以多种方式进行索引,这将有助于在查询时进行部分匹配和排名。

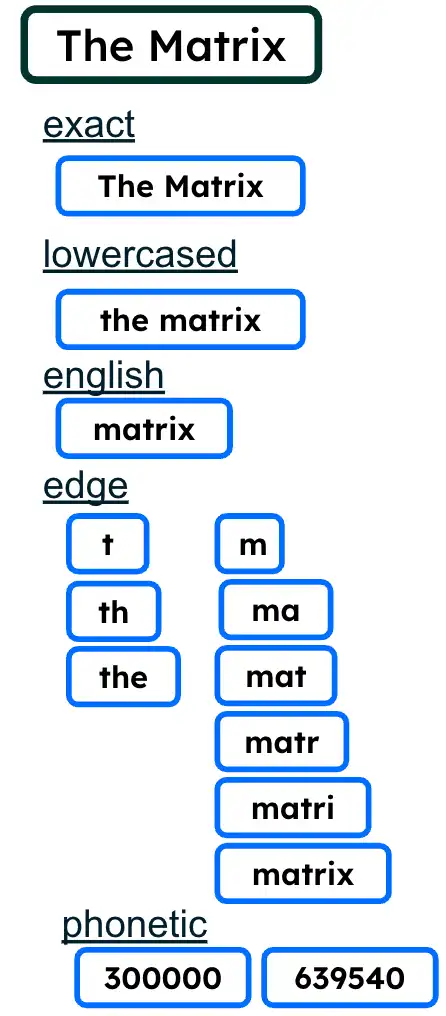
图2.多种索引策略
多分析器功能使用Atlas Search索引配置,启用单个文档字段能够以多种方式进行索引。
type 字段被索引为 token 字段,用于 equals 或 in 过滤,并且被索引为 stringFacet 字段,以便在每个实体类型的结果中获取计数。
索引定义可通过动态映射或您提供的静态定义来处理 _id、type 和 name 之外添加的任何其他字段。在此示例中,weight 是自定义类型,可作为数字类型进行动态处理。
搜索建议
生成的专业搜索索引为键入查询奠定了基础。name字段以多种方式建立索引,并与使用各种可调查询运算符输入的用户进行匹配。其想法是将查询运算符与以不同方式分析的映射进行比较,看看哪些内容匹配。找到的匹配项越多,建议的排名就越高。每个查询子句都可以独立增加和求和,从而为匹配实体提供相关性分数。这些分数可以通过其他因素进一步提高,例如可选的实体 weight字段。


图3.查询示例和相关性分数计算
通常,用户选择建议后,会对所选项目执行有针对性的传统搜索。然后,搜索会返回所有匹配的项目。
访问此解决方案的Github存储库。
关键要点
使用专门的索引配置将建议实体建模为文档:按照上述步骤创建一个单独的集合,其中包含任何来源的所有实体。
使用这些配置创建索引:当主集合将所有建议实体建模为顶级文档时,请使用这些索引设置。
使用索引结构精心设计查询:使用索引来匹配实体并根据需要对建议进行排名。
作者
Erik Hatcher, MongoDB