使用大型语言模型 (LLM) 和语义搜索来构建 YouTube 转录和摘要服务。
使用案例: Gen AI
行业: 媒体
产品: MongoDB Atlas,MongoDB Atlas Vector Search
合作伙伴: LangChain
解决方案概述
由于 YouTube 等平台上的信息内容数量巨大且各不相同,因此能够快速找到相关视频并对其进行转录和总结对于知识收集非常重要。
该解决方案构建了一个由AI驱动的生成式视频摘要应用,用于转录和摘要 YouTube 视频。该应用程序使用LLM和向量嵌入以及Atlas Vector Search进行视频到文本生成和语义搜索。这种方法可以为软件开发等行业提供帮助,专业人员可以通过 Gen AI视频摘要更快地学习;了解技术。
参考架构
如果没有MongoDB,视频摘要工具将使用以下工作流程:

图 1. 非基于 MongoDB 的参考架构
此解决方案将以下架构与MongoDB结合使用:

图 1. 基于 MongoDB 的参考架构
首先,该解决方案使用 YouTubeLoader进程YouTube 链接并获取视频元数据和文字记录。然后, Python脚本使用 LLM 获取并汇总视频文字记录。
然后,Voyage AI嵌入模型将汇总的记录转换为嵌入,存储在MongoDB Atlas中。此外,光学字符识别 (OCR) 和AI直接从视频帧执行实时代码分析,生成可搜索的基于文本的视频信息版本,以及AI驱动的解释。
该解决方案将处理后的数据存储在MongoDB Atlas中的文档中,其中包括视频元数据、其文字记录和AI生成的摘要。然后,用户可以使用MongoDB Atlas Vector Search搜索这些文档。
数据模型方法
以下代码区块是此解决方案生成的文档的示例:
{ "videoURL": "https://youtu.be/exampleID", "metadata":{ "title": "How to use GO with MongoDB", "author": "MongoDB", "publishDate": "2023-01-24", "viewCount": 1449, "length": "1533s", "thumbnail": "https://exmpl.com/thumb.jpg" }, "transcript": "Full transcript…", "summary": "Tutorial on using Go with MongoDB.", "codeAnalysis": [ "Main function in Go initializes the MongoDB client.", "Imports AWS Lambda package for serverless architecture." ] }
从每个 YouTube 视频中提取的数据包括以下内容:
videoURL:指向 YouTube 视频的直接链接。metadata:视频详细信息,如标题、上传者和日期。transcript:视频中语音内容的文本表示。summary: AI生成的简明文字记录版本。codeAnalysis: AI分析的代码示例列表。
构建解决方案
GitHub存储库中提供了此解决方案的代码。按照 README 获取更具体的说明,这些说明将引导您完成以下过程:
创建MongoDB Atlas Vector Search索引
将汇总的成绩单转换为用于 Vector Search 的嵌入,并将其存储在MongoDB Atlas中。
要学习如何使用Atlas Vector Search和创建索引,请参阅MongoDB Vector Search 快速入门。
下图显示了创建向量搜索索引时可以使用的参数值。

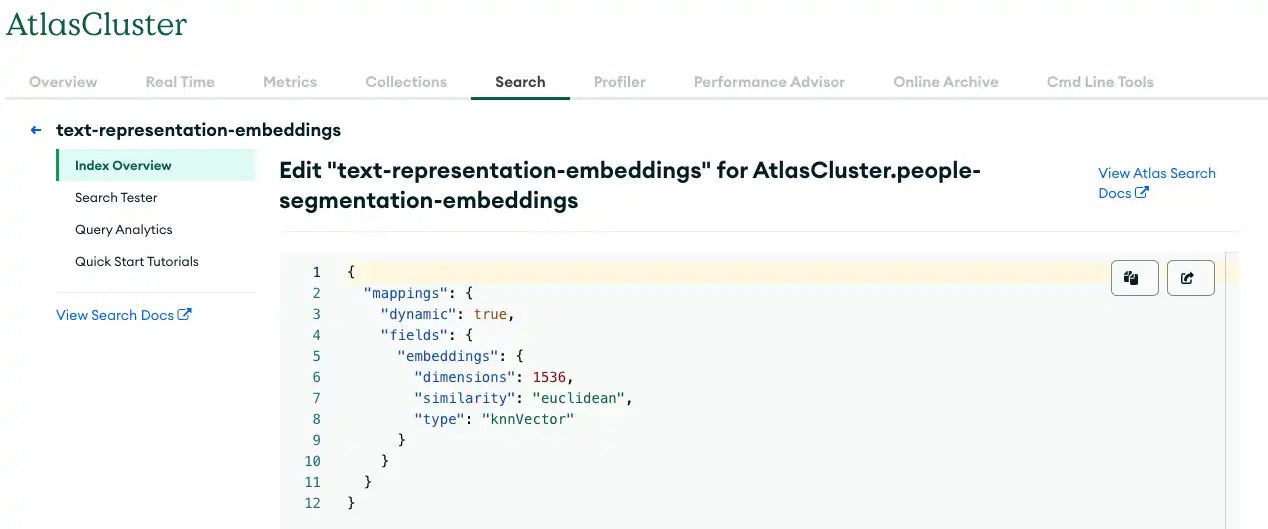
图3.在 MongoDB Atlas 中使用 Vector Search 存储数据
创建编排层
该解决方案使用编排层来协调解决方案的各种服务并管理复杂的工作流程。编排层由以下类组成,您可以在解决方案的GitHub存储库中找到这些类:
VideoServiceFacade:充当VideoService、SearchService和VideoProcessResult类的协调器。该系统处理用户提示和请求,以生成和摘要文本。VideoService:执行文本摘要。VideoProcessResult:封装处理后的视频结果,包括元数据、可能的操作和最佳搜索查询术语。SearchService:在MongoDB Atlas中执行搜索。
关键要点
Atlas Vector Search支持自然语言搜索:该解决方案在Atlas Vector Search中创建和存储向量索引,并将 LLM 生成的嵌入和输出存储在MongoDB Atlas中。这使用户能够在一个平台上搜索相关的、以前非结构化的信息,这些信息可能没有精确的关键字匹配。
LangChain 促进 Gen AI驱动的应用程序:LangChain 与MongoDB无缝集成,创建强大的AI驱动平台。
作者
Fabio Falavinha, MongoDB
David Macias, MongoDB