多区域Atlas部署是指在多个地区设立的集群。多区域部署可能在同一地理位置(大洲或国家/地区等大片区域)内有多个区域,或者在多个地理位置内 多个区域。多区域部署:
在考虑多区域部署是否适合您时,您必须评估应用程序的关键性,以及这如何对应于不同的 RTO/RPO 要求。弹性可以从多区域部署的零停机时间到单区域部署的不同备份策略,表现为一个连续范围。这种取舍是为了更高的可用性而增加成本。
有关多区域部署是否适合您的工作负载的更多指导,请参阅“可靠性”部分。
注意
多区域部署仅适用于 M10 及更大的专用集群。
多区域部署策略
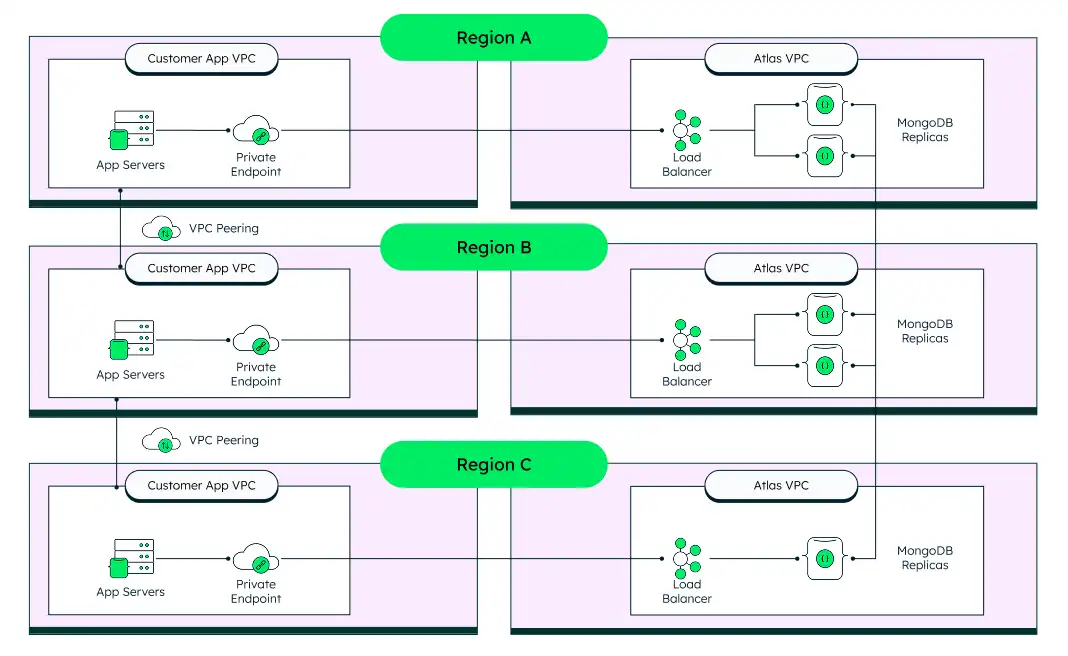
下图显示了 2+2+1拓扑结构的 2 示例,下文将详细讨论。它显示了在 3 个不同区域具有 5 个节点的单个集群:2 个节点位于 US1 中,2 个节点位于 US2 中,1 个节点位于 US3 中。


5-节点,3-区域架构 (2+2+1)
为了在区域服务中断时实现近乎即时的恢复,我们建议采用的架构至少由分布在 3 个区域的 5 个节点组成。这种架构确保在不强制故障转移到第二个区域的情况下进行定期维护操作,同时在整个区域性服务中断事件中提供自动故障转移和数据丢失保护。
下图显示了此架构的详细信息:

注释和注意事项
5-节点,2-区域架构 (2+3)
如果您的公司仅限于 2 个区域,您可以使用 5 节点、3 区域架构的变体,其中 5 个节点分布在两个区域之间。主区域有 2 个可选举节点,次区域有 1 个可选举节点和 2 个只读(无投票权)节点。
如果可以使用 3 区域,通常不建议这样做,因为如果多数地区发生故障,操作符必须手动干预才能进行故障转移。但是,对于仅拥有 2 批准地区的客户,这是一个选项。

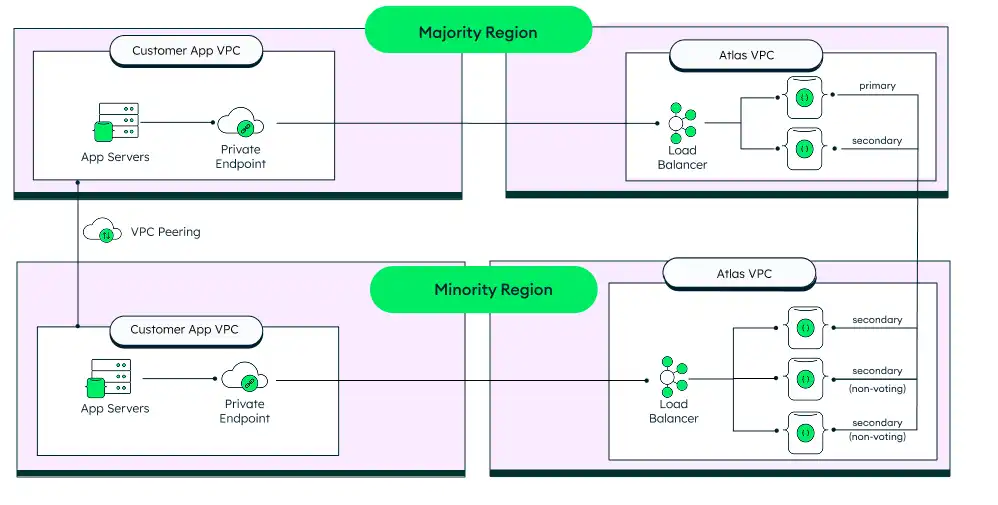
注释和注意事项
这种架构提供了增强的数据丢失保护。如果少数区域丢失,则无需用户操作,因为大多数区域仍然是一个功能齐全的集群。如果大多数区域丢失,系统仍将保持只读模式,直到大多数节点被恢复到可选举状态。然而,如果在发生故障后某些数据尚未复制到从节点,它可能无法提供完整的数据丢失保护。在这种情况下,直到主区域恢复,该数据才可用。
这种架构有一些注意事项:
如果多数地区丢失,则少数地区就不是功能齐全的集群;它没有主节点 (primary node in the replica set),只能接受读取,不能接受写入。
由于没有多数投票节点,因此它没有主节点 (primary node in the replica set),只能接受读取(而不是写入)。
要恢复功能集群,管理员需要将 2 个只读节点重新配置为可选举节点。然而,数据丢失是可能的。在服务中断期间,任何对从节点的新写入都会被放入一个特殊的集合中,以便手动恢复。然而,在主节点故障之前,未复制到至少一个从节点的所有写入都会丢失。要学习更多信息,请参阅在区域服务中断期间重新配置副本集或使用acceptDataRisksAndForceReplicaSetReconfig API 参数。
在分片集群中,如果您的 MongoDB 进程没有复制数据块迁移,数据不一致可能会导致孤立文档。
成本更低的变体
为了进一步节省费用,您可以设计没有 2 只读节点的架构。除了上面列出的注意事项之外,数据大小对决策也有重大影响,因为每当向集群添加新节点时,都需要将数据同步到从节点。示例,1 TB 的数据平均需要 1 小时的恢复和同步时间。我们建议在少数群体地区中设置 2 个只读节点,因为它们已经完全同步,并且恢复到功能齐全的集群只需几秒钟到几分钟的时间。
3-节点,3-区域架构 (1+1+1)
对于可以容忍中断的不太关键的工作负载,您可以通过在每个 3 区域中使用 1节点来利用成本较低的架构。每个区域都有一个可选举节点,这意味着如果主节点 (primary node in the replica set)节点不可用,您的集群将故障转移到新地区以确保持续可用性。但是,如果原始主节点 (primary node in the replica set)地区中的应用层级仍在为用户请求提供服务,则当请求跨多个区域路由时,延迟就会增加。此外,在重建节点的情况下,将能力执行优化的初始同步。
注意
我们一般不建议使用此配置,因为对Atlas节点进行定期、有计划的维护会导致暂时的延迟峰值。
多区域部署的建议
要学习如何配置多区域部署以及可以添加的不同类型的节点,请参阅 Atlas 文档中的配置高可用性和工作负载隔离。
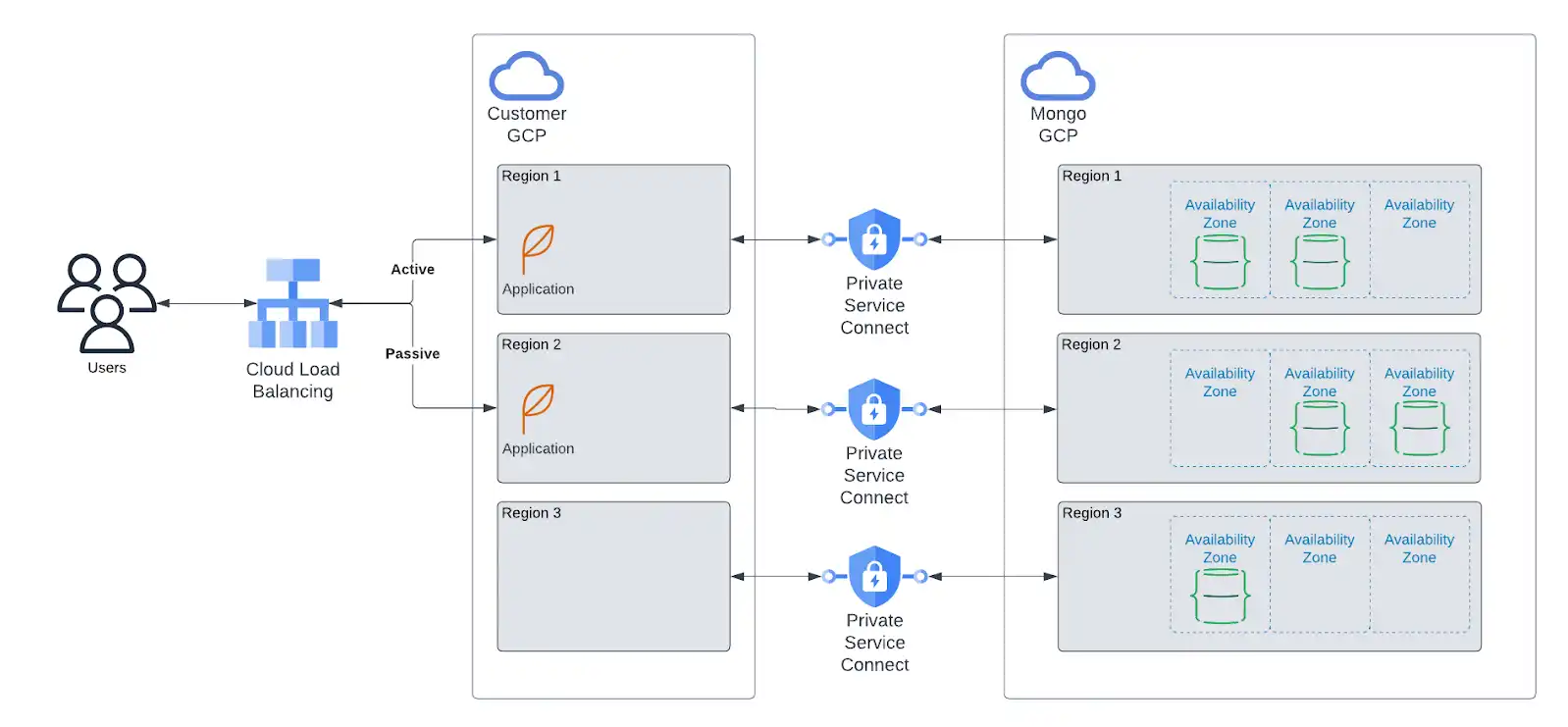
如果您的应用程序部署在以下云提供商之一, MongoDB强烈建议您将Atlas资源部署到相同的提供商和地区。此外,我们建议您将跨区域的应用程序资源部署映射到Atlas资源的部署,如下所示。
将应用程序资源与Atlas资源一起部署:
减少应用程序执行数据库操作的延迟。
通过将自管理的云资源与Atlas资源连接起来的私有端点,可增强安全性。私有端点提供最高级别的网络安全,确保流量只能从您的帐户启动。
允许您更精细地控制特定于地区的数据存储。
允许您在其他地方发生中断时将流量重新路由到健康区域。
要学习;了解有关应用程序和Atlas部署建议的更多信息,请参阅:

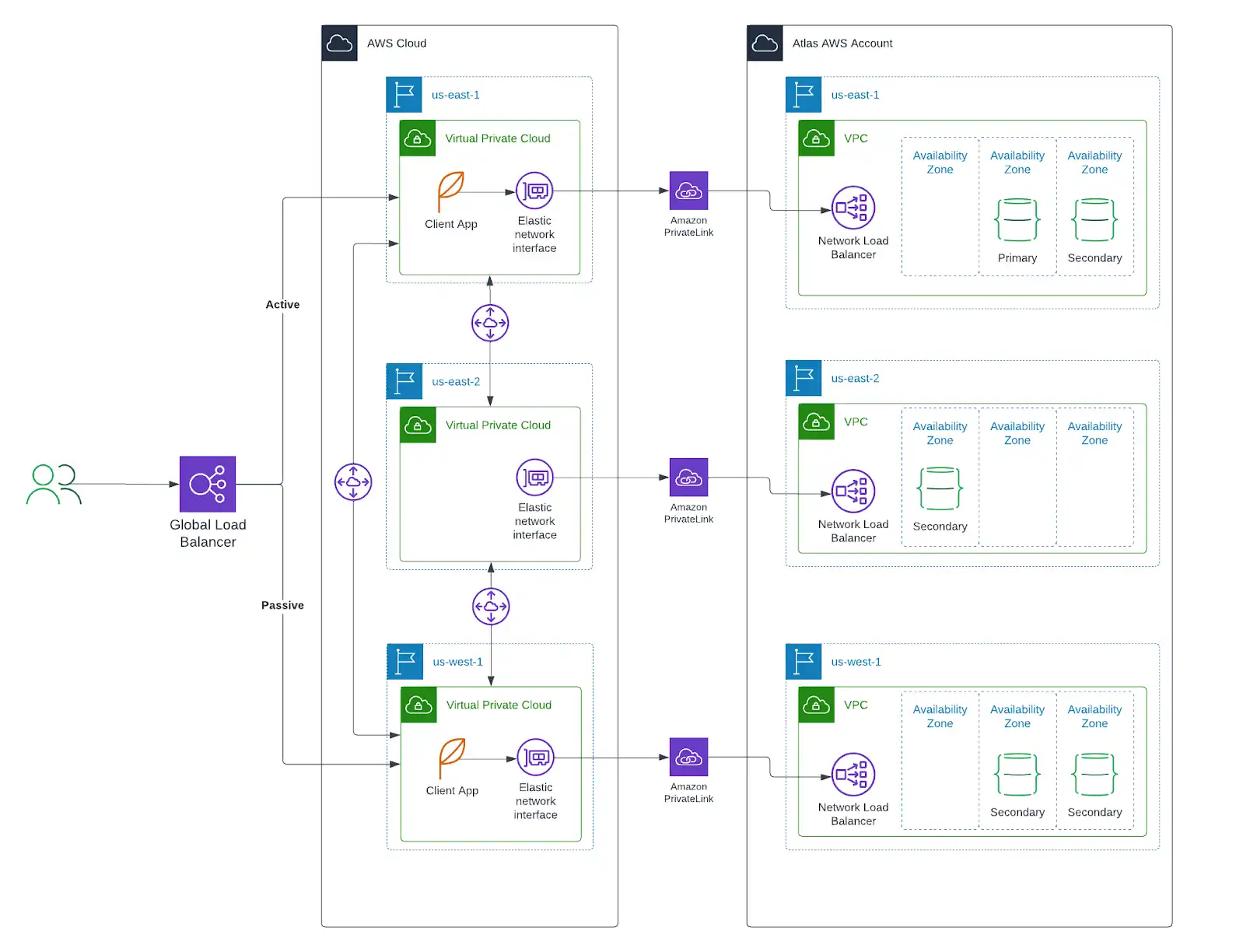
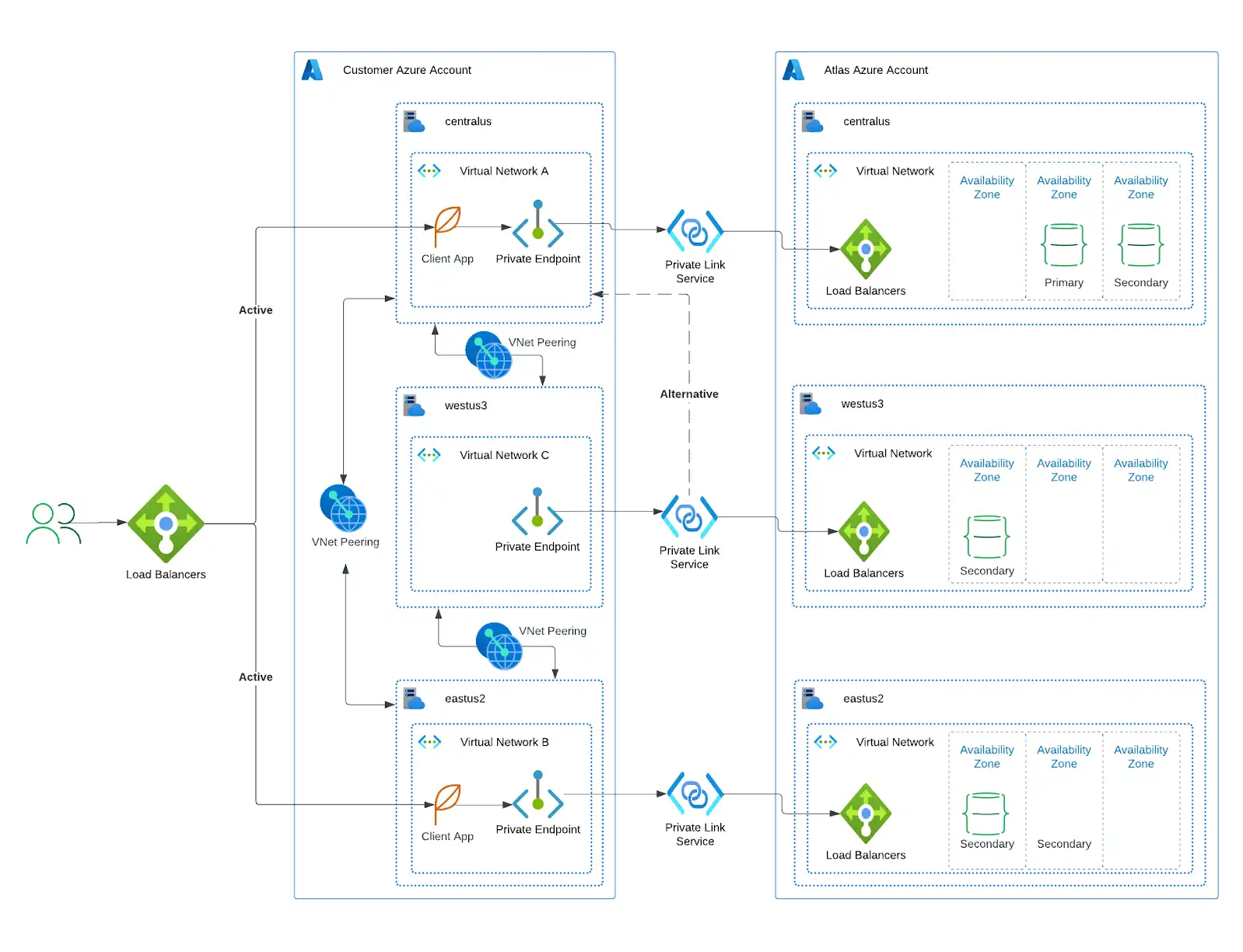

要查找有关 Atlas 云部署的建议,请参考以下资源: