注意
Vertex AI 扩展程序目前处于预览阶段,可能会有所变动。请联系您的 Google Cloud 代表,了解如何访问此功能。
除了结合使用 Vertex AI和MongoDB Vector Search 来实现 RAG 之外,您还可以使用 Vertex AI扩展 来进一步自定义使用 Vertex AI模型与Atlas交互的方式。在本教程中,您将创建一个 Vertex AI扩展,该扩展允许您使用自然语言实时查询Atlas中的数据。
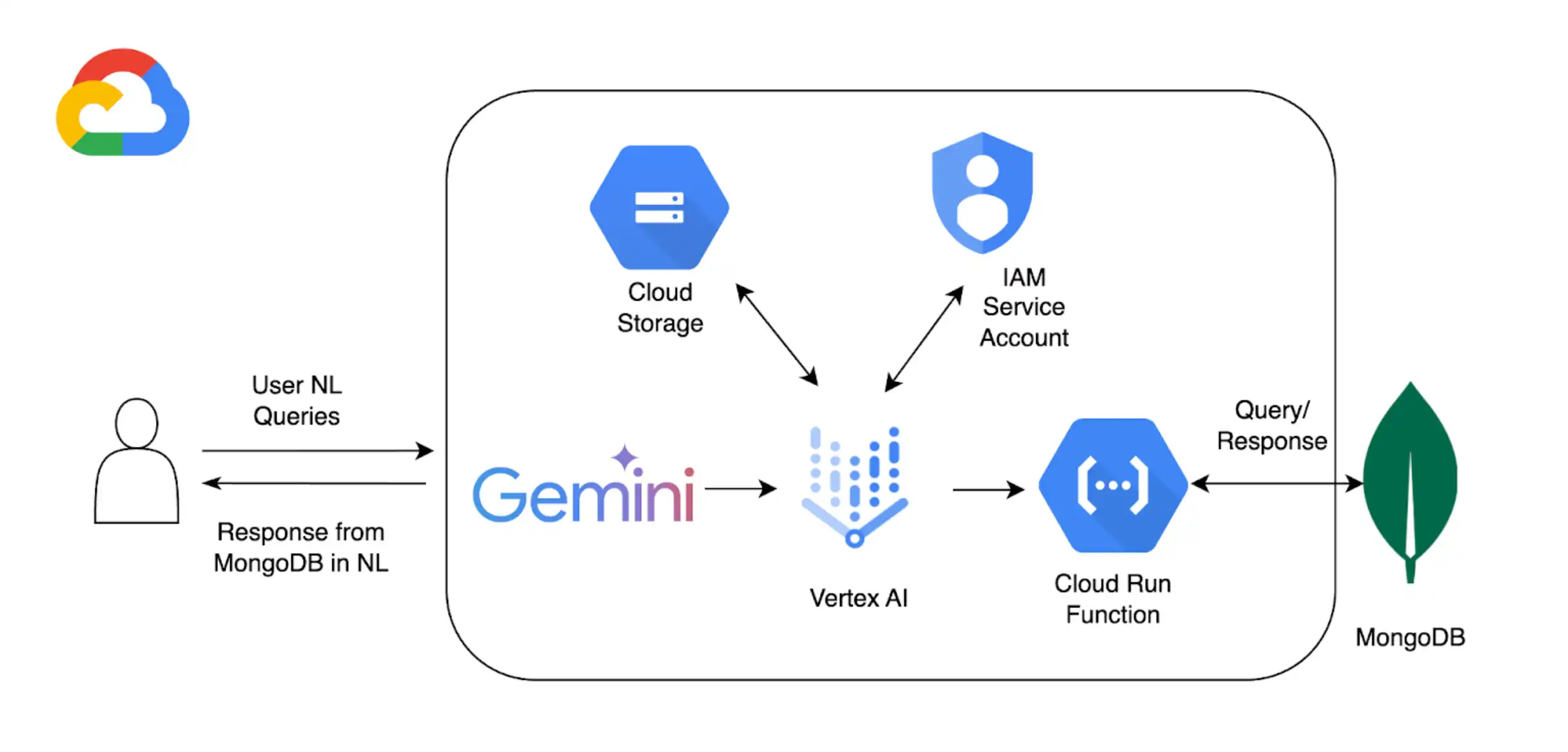
背景
本教程使用以下组件使 Atlas 能够进行自然语言查询:
Google Cloud Platform Vertex AI SDK,用于管理AI模型并为 Vertex AI启用自定义扩展。本教程使用 Gemini 1.5Pro 模型。
Google Cloud Run 用于部署在 Vertex AI 和 Atlas 之间作为 API 终结点的函数。
MongoDB API的 OpenAPI 3 规范,用于定义自然语言查询如何映射到MongoDB操作。要学习;了解更多信息,请参阅OpenAPI 规范。
Vertex AI扩展,可启用Vertex AI与Atlas的实时交互,并配置自然语言查询的处理方式。
Google Cloud Secrets Manager 用于存储您的 MongoDB API 密钥。
注意
有关详细的代码和设置说明,请参阅此示例的 GitHub 存储库。
先决条件
开始之前,您必须具备以下条件:
MongoDB Atlas 账户。要注册,请使用 Google Cloud Marketplace 或 注册新账户。
用于存储 OpenAPI 规范的 Google Cloud Storage 存储桶。
已为您的项目启用以下 API:
Cloud Build API
Cloud Functions API
Cloud Logging API
Cloud Pub/Sub API
Colab Enterprise 环境。
创建 Google Cloud Run 函数
在本节中,您将创建一个 Google Cloud Run 函数,作为 Vertex AI 扩展和 Atlas 集群之间的 API 终结点。该函数处理身份验证,连接到 Atlas 集群,并根据来自 Vertex AI 的请求执行数据库操作。
创建一个新函数。
在Google Cloud Platform控制台中,打开 Cloud Run 页面并单击 Write a function。
配置该功能。
指定函数名称和要部署函数的Google Cloud Platform地区。
选择最新可用的 Python 版本作为 Runtime。
在 Authentication section 中,选择 Allow unauthenticated invocations。
对其余设置使用默认值,然后单击 Next。
有关详细配置步骤,请参阅 Cloud Run 文档。
定义函数代码。
将以下代码粘贴到各自的文件中:
粘贴以下代码后,将 <connection-string> 替换为您的Atlas连接字符串。
将 <connection-string> 替换为您的 Atlas 集群或本地部署的连接字符串。
连接字符串应使用以下格式:
mongodb+srv://<db_username>:<db_password>@<clusterName>.<hostname>.mongodb.net
要学习;了解更多信息,请参阅通过客户端库连接到集群。
import functions_framework import os import json from pymongo import MongoClient from bson import ObjectId import traceback from datetime import datetime def connect_to_mongodb(): client = MongoClient("<connection-string>") return client def success_response(body): return { 'statusCode': '200', 'body': json.dumps(body, cls=DateTimeEncoder), 'headers': { 'Content-Type': 'application/json', }, } def error_response(err): error_message = str(err) return { 'statusCode': '400', 'body': error_message, 'headers': { 'Content-Type': 'application/json', }, } # Used to convert datetime object(s) to string class DateTimeEncoder(json.JSONEncoder): def default(self, o): if isinstance(o, datetime): return o.isoformat() return super().default(o) def mongodb_crud(request): client = connect_to_mongodb() payload = request.get_json(silent=True) db, coll = payload['database'], payload['collection'] request_args = request.args op = request.path try: if op == "/findOne": filter_op = payload['filter'] if 'filter' in payload else {} projection = payload['projection'] if 'projection' in payload else {} result = {"document": client[db][coll].find_one(filter_op, projection)} if result['document'] is not None: if isinstance(result['document']['_id'], ObjectId): result['document']['_id'] = str(result['document']['_id']) elif op == "/find": agg_query = [] if 'filter' in payload and payload['filter'] != {}: agg_query.append({"$match": payload['filter']}) if "sort" in payload and payload['sort'] != {}: agg_query.append({"$sort": payload['sort']}) if "skip" in payload: agg_query.append({"$skip": payload['skip']}) if 'limit' in payload: agg_query.append({"$limit": payload['limit']}) if "projection" in payload and payload['projection'] != {}: agg_query.append({"$project": payload['projection']}) result = {"documents": list(client[db][coll].aggregate(agg_query))} for obj in result['documents']: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) elif op == "/insertOne": if "document" not in payload or payload['document'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_one(payload['document']) result = {"insertedId": str(insert_op.inserted_id)} elif op == "/insertMany": if "documents" not in payload or payload['documents'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_many(payload['documents']) result = {"insertedIds": [str(_id) for _id in insert_op.inserted_ids]} elif op in ["/updateOne", "/updateMany"]: payload['upsert'] = payload['upsert'] if 'upsert' in payload else False if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/updateOne": update_op = client[db][coll].update_one(payload['filter'], payload['update'], upsert=payload['upsert']) else: update_op = client[db][coll].update_many(payload['filter'], payload['update'], upsert=payload['upsert']) result = {"matchedCount": update_op.matched_count, "modifiedCount": update_op.modified_count} elif op in ["/deleteOne", "/deleteMany"]: payload['filter'] = payload['filter'] if 'filter' in payload else {} if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/deleteOne": result = {"deletedCount": client[db][coll].delete_one(payload['filter']).deleted_count} else: result = {"deletedCount": client[db][coll].delete_many(payload['filter']).deleted_count} elif op == "/aggregate": if "pipeline" not in payload or payload['pipeline'] == []: return error_response("Send a pipeline") docs = list(client[db][coll].aggregate(payload['pipeline'])) for obj in docs: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) result = {"documents": docs} else: return error_response("Not a valid operation") return success_response(result) except Exception as e: print(traceback.format_exc()) return error_response(e) finally: if client: client.close()
创建 Vertex AI 扩展
在本节中,您将创建一个 Vertex AI 扩展,该扩展允许使用 Gemini 1.5 Pro 模型在 Atlas 中对您的数据进行自然语言查询。此扩展使用 OpenAPI 规范和您创建的 Cloud Run函数,将自然语言映射到数据库操作,并在 Atlas 中查询您的数据。
要实现此扩展,您可以使用交互式 Python 笔记本,它允许您单独运行 Python 代码片段。在本教程中,您将在 Colab 企业环境中创建名为 mongodb-vertex-ai-extension.ipynb 的笔记本。
设置环境。
对您的 Google Cloud 账号进行身份验证并设置群组 ID。
from google.colab import auth auth.authenticate_user("GCP project id") !gcloud config set project {"GCP project id"} 安装所需的依赖项。
!pip install --force-reinstall --quiet google_cloud_aiplatform !pip install --force-reinstall --quiet langchain==0.0.298 !pip install --upgrade google-auth !pip install bigframes==0.26.0 重新启动内核。
import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) 设置环境变量。
将示例值替换为与您的项目相对应的正确值。
import os # These are sample values; replace them with the correct values that correspond to your project os.environ['PROJECT_ID'] = 'gcp project id' # GCP Project ID os.environ['REGION'] = "us-central1" # Project Region os.environ['STAGING_BUCKET'] = "gs://vertexai_extensions" # GCS Bucket location os.environ['EXTENSION_DISPLAY_HOME'] = "MongoDb Vertex API Interpreter" # Extension Config Display Name os.environ['EXTENSION_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # Extension Config Description os.environ['MANIFEST_NAME'] = "mdb_crud_interpreter" # OPEN API Spec Config Name os.environ['MANIFEST_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # OPEN API Spec Config Description os.environ['OPENAPI_GCS_URI'] = "gs://vertexai_extensions/mongodbopenapispec.yaml" # OPEN API GCS URI os.environ['API_SECRET_LOCATION'] = "projects/787220387490/secrets/mdbapikey/versions/1" # API KEY secret location os.environ['LLM_MODEL'] = "gemini-1.5-pro" # LLM Config
下载 Open API 规范。
从 GitHub 下载 Open API 规范,并将 YAML 文件上传到 Google Cloud Storage 存储桶。
from google.cloud import aiplatform from google.cloud.aiplatform.private_preview import llm_extension PROJECT_ID = os.environ['PROJECT_ID'] REGION = os.environ['REGION'] STAGING_BUCKET = os.environ['STAGING_BUCKET'] aiplatform.init( project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET, )
创建 Vertex AI扩展。
以下清单是一个结构化JSON对象,用于配置扩展的关键组件。将 <service-account> 替换为 Cloud Run function 使用的服务帐号名称。
from google.cloud import aiplatform from vertexai.preview import extensions mdb_crud = extensions.Extension.create( display_name = os.environ['EXTENSION_DISPLAY_HOME'], # Optional. description = os.environ['EXTENSION_DESCRIPTION'], manifest = { "name": os.environ['MANIFEST_NAME'], "description": os.environ['MANIFEST_DESCRIPTION'], "api_spec": { "open_api_gcs_uri": ( os.environ['OPENAPI_GCS_URI'] ), }, "authConfig": { "authType": "OAUTH", "oauthConfig": {"service_account": "<service-account>"} }, }, ) mdb_crud
运行自然语言查询
在 Vertex AI 中,单击左侧导航菜单中的 Extensions。您的新扩展名为 MongoDB Vertex API Interpreter,显示在扩展列表中。
以下示例演示了您可以在 Atlas 中用于查询数据的两种不同的自然语言查询:
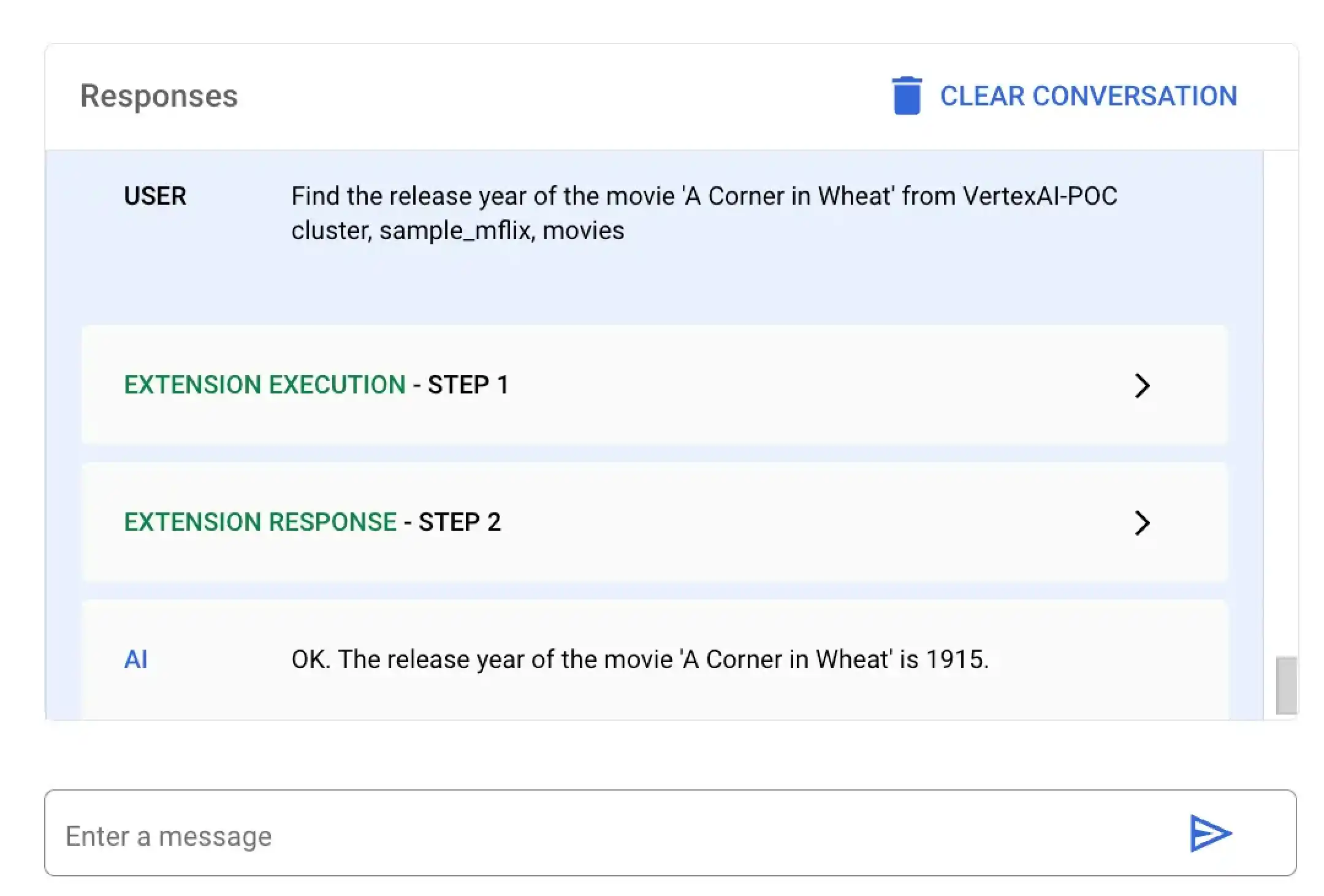
在此示例中,您要求 Vertex AI查找一部名为 A Corner in Wheat 的特定电影的发布年份。您可以使用 Vertex AI平台或 Colab 笔记本运行此自然语言查询:
选择名为 MongoDB Vertex API Interpreter 的扩展并输入以下自然语言查询:
Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies

在 mongodb-vertex-ai-extension.ipynb 中粘贴并运行以下代码,以查找特定电影的发布日期:
## Please replace accordingly to your project ## Operation Ids os.environ['FIND_ONE_OP_ID'] = "findone_mdb" ## NL Queries os.environ['FIND_ONE_NL_QUERY'] = "Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" ### Test data setup os.environ['TITLE_FILTER_CLAUSE'] = "A Corner in Wheat" from vertexai.preview.generative_models import GenerativeModel, Tool fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findOneResponse = fc_chat.send_message(os.environ['FIND_ONE_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findOneResponse)
response = mdb_crud.execute( operation_id = findOneResponse.candidates[0].content.parts[0].function_call.name, operation_params = findOneResponse.candidates[0].content.parts[0].function_call.args ) print(response)
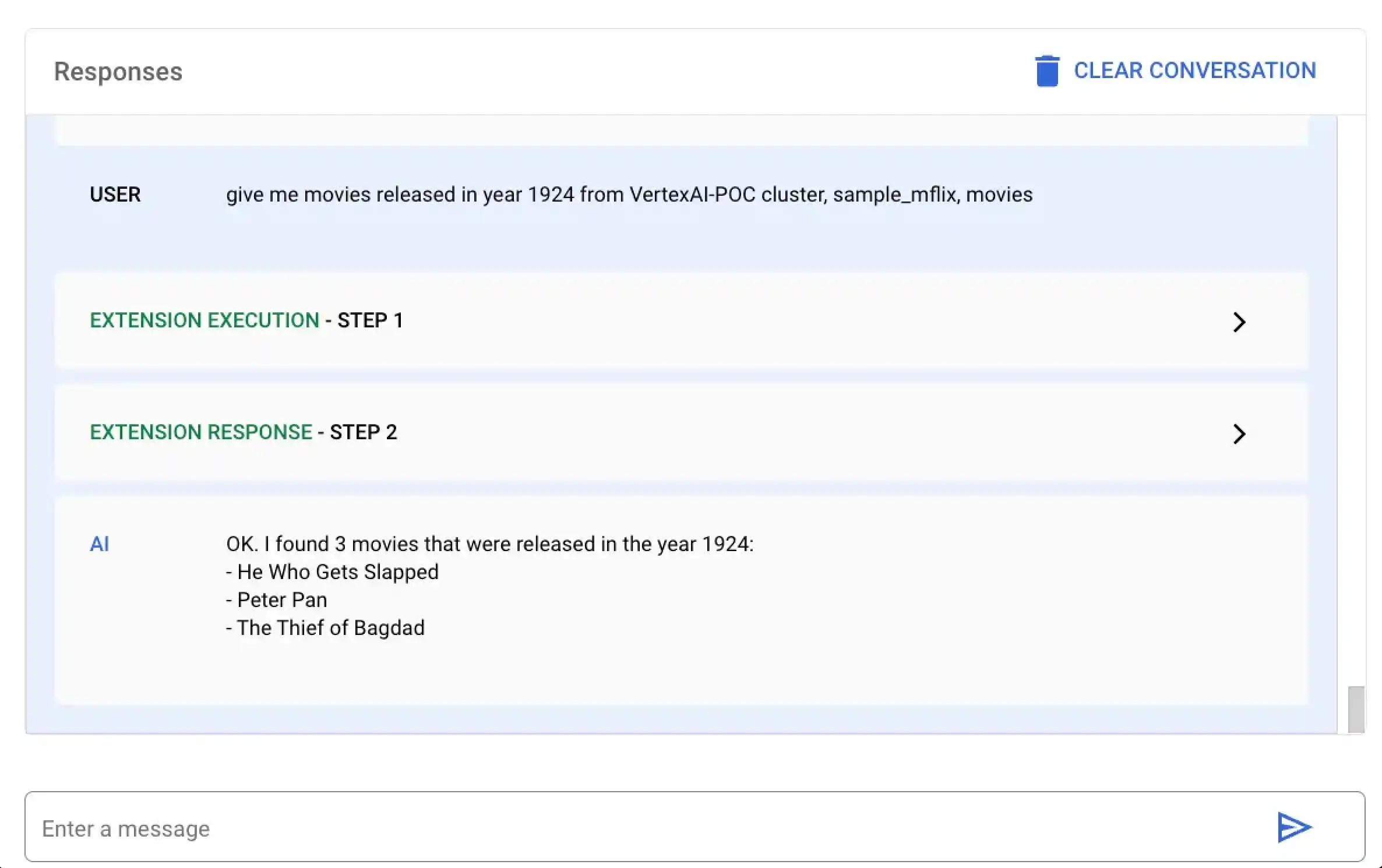
在此示例中,您要求 Vertex AI查找 1924 年上映的所有电影。您可以使用 Vertex AI平台或 Colab 笔记本运行此自然语言查询:
选择名为 MongoDB Vertex API Interpreter 的扩展并输入以下自然语言查询:
give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies

在 mongodb-vertex-ai-extension.ipynb 中粘贴并运行以下代码,以查找特定年份上映的所有电影:
## This is just a sample values please replace accordingly to your project ## Operation Ids os.environ['FIND_MANY_OP_ID'] = "findmany_mdb" ## NL Queries os.environ['FIND_MANY_NL_QUERY'] = "give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" os.environ['YEAR'] = 1924 fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findmanyResponse = fc_chat.send_message(os.environ['FIND_MANY_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findmanyResponse)
response = mdb_crud.execute( operation_id = findmanyResponse.candidates[0].content.parts[0].function_call.name, operation_params = findmanyResponse.candidates[0].content.parts[0].function_call.args ) print(response)