Este guia descreve como realizar pesquisas semânticas com modelos de IA Voyage. Esta página inclui exemplos de casos de uso de pesquisa semântica básica e avançada, incluindo pesquisa com reclassificação, bem como recuperação multilíngue, multimodal, contextualizada parte e de grande corpus.
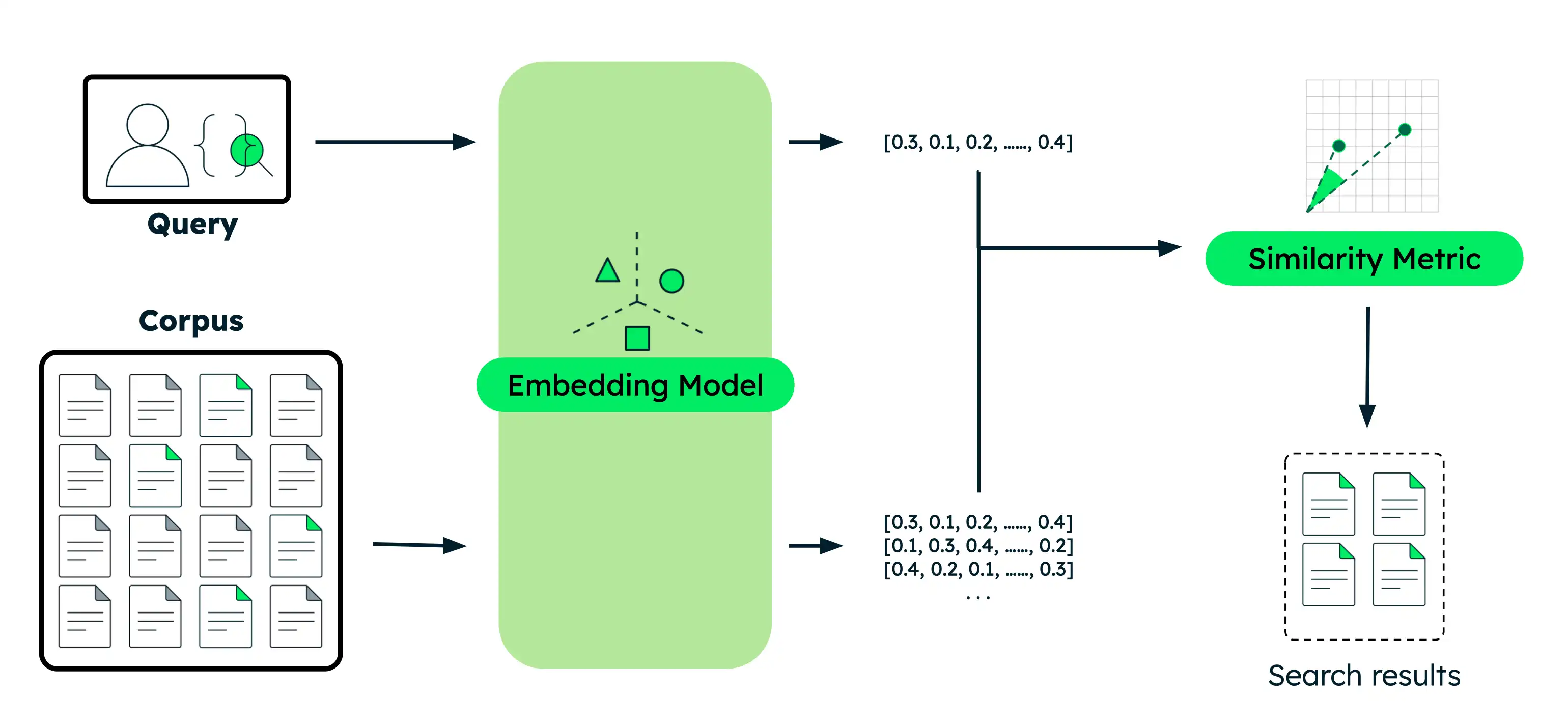
Executar pesquisa semântica
Esta seção fornece exemplos de código para vários casos de uso de pesquisa semântica com diferentes modelos de IA Voyage. Para cada exemplo, você executa as mesmas etapas básicas:
Incorpore os documentos: converta seus dados em incorporações vetoriais que capturam seu significado. Esses dados podem ser texto, imagens, partes de documento ou um grande corpus de texto.
Incorpore a query: Transforme sua query de pesquisa na mesma representação vetorial dos seus documentos.
Encontrar documentos semelhantes: compare o vetor de query com os vetores de documento para identificar os resultados mais semanticamente semelhantes.
Trabalhe com uma versão executável deste tutorial como um bloco de anotações Python.
Configure seu ambiente.
Antes de começar, crie um diretório de projeto , instale bibliotecas e defina a chave de API do modelo.
Execute os seguintes comandos no seu terminal para criar um novo diretório para este tutorial e instalar as bibliotecas necessárias:
mkdir voyage-semantic-search cd voyage-semantic-search pip install --upgrade voyageai numpy datasets Siga as etapas para criar uma chave de API de modelo e, em seguida, execute o seguinte comando em seu terminal para exportá-la como uma variável de ambiente:
export VOYAGE_API_KEY="your-model-api-key"
Execute queries de pesquisa semântica.
Expanda cada seção para obter exemplos de código para cada tipo de pesquisa semântica.
Crie um arquivo denominado
semantic_search_basic.pyno seu projeto e cole o seguinte código nele:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort documents by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices, 1): print(f"{rank}. {documents[idx]}") print(f" Similarity: {similarities[idx]:.4f}\n")
Execute o seguinte comando no seu terminal:
python semantic_search_basic.py
Query: 'When is Apple's conference call scheduled?' 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity: 0.2335 4. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Similarity: 0.1955 5. Photosynthesis in plants converts light energy into glucose and produces essential oxygen. Similarity: 0.1881 6. Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems. Similarity: 0.1601
Crie um arquivo denominado
semantic_search_reranker.pyem seu projeto e cole o seguinte código nele:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results before reranking print(f"Query: '{query}'\n") print("Before reranker (embedding similarity only):") for rank, idx in enumerate(ranked_indices[:3], 1): print(f"{rank}. {documents[idx]}") print(f" Similarity Score: {similarities[idx]:.4f}\n") # Rerank documents for improved accuracy rerank_results = vo.rerank( query=query, documents=documents, model="rerank-2.5" ) # Display results after reranking print("\nAfter reranker:") for rank, result in enumerate(rerank_results.results[:3], 1): print(f"{rank}. {documents[result.index]}") print(f" Relevance Score: {result.relevance_score:.4f}\n")
Execute o seguinte comando no seu terminal:
python semantic_search_reranker.py
Query: 'When is Apple's conference call scheduled?' Before reranker (embedding similarity only): 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity Score: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity Score: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity Score: 0.2335 After reranker: 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Relevance Score: 0.9453 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Relevance Score: 0.2832 3. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Relevance Score: 0.2637
Crie um arquivo denominado
semantic_search_multilingual.pyem seu projeto e cole o seguinte código nele:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # English documents about technology companies english_docs = [ "Apple announced record-breaking revenue in its latest quarterly earnings report.", "The Mediterranean diet emphasizes fish, olive oil, and vegetables.", "Microsoft is investing heavily in artificial intelligence and cloud computing.", "Shakespeare's plays continue to influence modern literature and theater." ] # Spanish documents about technology companies spanish_docs = [ "Apple anunció ingresos récord en su último informe trimestral de ganancias.", "La dieta mediterránea enfatiza el pescado, el aceite de oliva y las verduras.", "Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube.", "Las obras de Shakespeare continúan influenciando la literatura y el teatro modernos." ] # Chinese documents about technology companies chinese_docs = [ "苹果公司在最新季度财报中宣布创纪录的收入。", "地中海饮食强调鱼类、橄榄油和蔬菜。", "微软正在大力投资人工智能和云计算。", "莎士比亚的作品继续影响现代文学和戏剧。" ] # Perform semantic search in English english_query = "tech company earnings" # Generate embeddings for English documents english_embeddings = vo.embed( texts=english_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for English query english_query_embedding = vo.embed( texts=[english_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product english_similarities = np.dot(english_embeddings, english_query_embedding) # Sort by similarity (highest to lowest) english_ranked = np.argsort(-english_similarities) print(f"English Query: '{english_query}'\n") for rank, idx in enumerate(english_ranked[:2], 1): print(f"{rank}. {english_docs[idx]}") print(f" Similarity: {english_similarities[idx]:.4f}\n") # Perform semantic search in Spanish spanish_query = "ganancias de empresas tecnológicas" # Generate embeddings for Spanish documents spanish_embeddings = vo.embed( texts=spanish_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Spanish query spanish_query_embedding = vo.embed( texts=[spanish_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product spanish_similarities = np.dot(spanish_embeddings, spanish_query_embedding) # Sort by similarity (highest to lowest) spanish_ranked = np.argsort(-spanish_similarities) print(f"Spanish Query: '{spanish_query}'\n") for rank, idx in enumerate(spanish_ranked[:2], 1): print(f"{rank}. {spanish_docs[idx]}") print(f" Similarity: {spanish_similarities[idx]:.4f}\n") # Perform semantic search in Chinese chinese_query = "科技公司收益" # Generate embeddings for Chinese documents chinese_embeddings = vo.embed( texts=chinese_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Chinese query chinese_query_embedding = vo.embed( texts=[chinese_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product chinese_similarities = np.dot(chinese_embeddings, chinese_query_embedding) # Sort by similarity (highest to lowest) chinese_ranked = np.argsort(-chinese_similarities) print(f"Chinese Query: '{chinese_query}'\n") for rank, idx in enumerate(chinese_ranked[:2], 1): print(f"{rank}. {chinese_docs[idx]}") print(f" Similarity: {chinese_similarities[idx]:.4f}\n")
Execute o seguinte comando no seu terminal:
python semantic_search_multilingual.py
English Query: 'tech company earnings' 1. Apple announced record-breaking revenue in its latest quarterly earnings report. Similarity: 0.5172 2. Microsoft is investing heavily in artificial intelligence and cloud computing. Similarity: 0.4745 Spanish Query: 'ganancias de empresas tecnológicas' 1. Apple anunció ingresos récord en su último informe trimestral de ganancias. Similarity: 0.5232 2. Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube. Similarity: 0.4871 Chinese Query: '科技公司收益' 1. 苹果公司在最新季度财报中宣布创纪录的收入。 Similarity: 0.4725 2. 微软正在大力投资人工智能和云计算。 Similarity: 0.4426
Pesquise por imagens de amostra e salve-as em seu diretório de projeto. O exemplo de código a seguir pressupõe que você tenha imagens de um cão, um cão e umabanana.
Crie um arquivo denominado
semantic_search_multimodal.pyem seu projeto e cole o seguinte código nele:
import voyageai import numpy as np from PIL import Image # Initialize Voyage AI client vo = voyageai.Client() # Prepare interleaved text + image inputs interleaved_inputs = [ ["An orange cat", Image.open('cat.jpg')], ["A golden retriever", Image.open('dog.jpg')], ["A banana", Image.open('banana.jpg')], ] # Prepare image-only inputs image_only_inputs = [ [Image.open('cat.jpg')], [Image.open('dog.jpg')], [Image.open('banana.jpg')], ] # Labels for display labels = ["cat.jpg", "dog.jpg", "banana.jpg"] # Search query query = "a cute pet" # Generate embeddings for interleaved text + image inputs interleaved_embeddings = vo.multimodal_embed( inputs=interleaved_inputs, model="voyage-multimodal-3.5" ).embeddings # Generate embedding for query query_embedding = vo.multimodal_embed( inputs=[[query]], model="voyage-multimodal-3.5" ).embeddings[0] # Calculate similarity scores using dot product interleaved_similarities = np.dot(interleaved_embeddings, query_embedding) # Sort by similarity (highest to lowest) interleaved_ranked = np.argsort(-interleaved_similarities) print(f"Query: '{query}'\n") print("Search with interleaved text + image:") for rank, idx in enumerate(interleaved_ranked, 1): print(f"{rank}. {interleaved_inputs[idx][0]}") print(f" Similarity: {interleaved_similarities[idx]:.4f}\n") # Generate embeddings for image-only inputs image_only_embeddings = vo.multimodal_embed( inputs=image_only_inputs, model="voyage-multimodal-3.5" ).embeddings # Calculate similarity scores using dot product image_only_similarities = np.dot(image_only_embeddings, query_embedding) # Sort by similarity (highest to lowest) image_only_ranked = np.argsort(-image_only_similarities) print("\nSearch with image-only:") for rank, idx in enumerate(image_only_ranked, 1): print(f"{rank}. {labels[idx]}") print(f" Similarity: {image_only_similarities[idx]:.4f}\n")
Execute o seguinte comando no seu terminal:
python semantic_search_multimodal.py
Query: 'a cute pet' Search with interleaved text + image: 1. An orange cat Similarity: 0.2685 2. A golden retriever Similarity: 0.2325 3. A banana Similarity: 0.1564 Search with image-only: 1. dog.jpg Similarity: 0.2485 2. cat.jpg Similarity: 0.2438 3. banana.jpg Similarity: 0.1210
Crie um arquivo denominado
semantic_search_contextualized.pyem seu projeto e cole o seguinte código nele:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents (each document is a list of chunks that share context) documents = [ [ "This is the SEC filing on Greenery Corp.'s Q2 2024 performance.", "The company's revenue increased by 7% compared to the previous quarter." ], [ "This is the SEC filing on Leafy Inc.'s Q2 2024 performance.", "The company's revenue increased by 15% compared to the previous quarter." ], [ "This is the SEC filing on Elephant Ltd.'s Q2 2024 performance.", "The company's revenue decreased by 2% compared to the previous quarter." ] ] # Search query query = "What was the revenue growth for Leafy Inc. in Q2 2024?" # Generate contextualized embeddings (preserves relationships between chunks) contextualized_result = vo.contextualized_embed( inputs=documents, model="voyage-context-3", input_type="document" ) # Flatten the embeddings and chunks for semantic search contextualized_embeddings = [] all_chunks = [] chunk_to_doc = [] # Maps chunk index to document index for doc_idx, result in enumerate(contextualized_result.results): for emb, chunk in zip(result.embeddings, documents[doc_idx]): contextualized_embeddings.append(emb) all_chunks.append(chunk) chunk_to_doc.append(doc_idx) # Generate contextualized query embedding query_embedding_ctx = vo.contextualized_embed( inputs=[[query]], model="voyage-context-3", input_type="query" ).results[0].embeddings[0] # Calculate similarity scores using dot product similarities_ctx = np.dot(contextualized_embeddings, query_embedding_ctx) # Sort by similarity (highest to lowest) ranked_indices_ctx = np.argsort(-similarities_ctx) # Display top 3 results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices_ctx[:3], 1): doc_idx = chunk_to_doc[idx] print(f"{rank}. {all_chunks[idx]}") print(f" (From document: {documents[doc_idx][0]})") print(f" Similarity: {similarities_ctx[idx]:.4f}\n")
Execute o seguinte comando no seu terminal:
python semantic_search_contextualized.py
Query: 'What was the revenue growth for Leafy Inc. in Q2 2024?' 1. The company's revenue increased by 15% compared to the previous quarter. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.7138 2. This is the SEC filing on Leafy Inc.'s Q2 2024 performance. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.6630 3. The company's revenue increased by 7% compared to the previous quarter. (From document: This is the SEC filing on Greenery Corp.'s Q2 2024 performance.) Similarity: 0.5531
Crie um arquivo denominado
semantic_search_large_corpus.pyem seu projeto e cole o seguinte código nele:
import voyageai import numpy as np from datasets import load_dataset from collections import defaultdict # Initialize Voyage AI client vo = voyageai.Client() # Load legal benchmark dataset corpus_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "corpus")["corpus"] queries_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "queries")["queries"] qrels_ds = load_dataset("mteb/legalbench_consumer_contracts_qa")["test"] # Extract corpus and query data corpus_ids = [row["_id"] for row in corpus_ds] corpus_texts = [row["text"] for row in corpus_ds] query_ids = [row["_id"] for row in queries_ds] query_texts = [row["text"] for row in queries_ds] # Build relevance mapping (defaultdict creates sets for missing keys) qrels = defaultdict(set) for row in qrels_ds: if row["score"] > 0: qrels[row["query-id"]].add(row["corpus-id"]) # Generate embeddings for the entire corpus print(f"Generating embeddings for {len(corpus_texts)} documents...") corpus_embeddings = vo.embed( texts=corpus_texts, model="voyage-4-large", input_type="document" ).embeddings # Select a sample query query_idx = 1 query = query_texts[query_idx] query_id = query_ids[query_idx] # Generate embedding for the query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(corpus_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display top 5 results print(f"Query: {query}\n") print("Top 5 Results:") for rank, idx in enumerate(ranked_indices[:5], 1): doc_id = corpus_ids[idx] is_relevant = "✓" if doc_id in qrels[query_id] else "✗" print(f"{rank}. [{is_relevant}] Document ID: {doc_id}") print(f" Similarity: {similarities[idx]:.4f}") print(f" Text: {corpus_texts[idx][:100]}...\n") # Show the ground truth most relevant document most_relevant_id = list(qrels[query_id])[0] most_relevant_idx = corpus_ids.index(most_relevant_id) print(f"Ground truth most relevant document:") print(f"Document ID: {most_relevant_id}") print(f"Rank in results: {np.where(ranked_indices == most_relevant_idx)[0][0] + 1}") print(f"Similarity: {similarities[most_relevant_idx]:.4f}")
Execute o seguinte comando no seu terminal:
python semantic_search_large_corpus.py
Generating embeddings for 154 documents... Query: Will Google come to a users assistance in the event of an alleged violation of such users IP rights? Top 5 Results: 1. [✓] Document ID: 9NIQ0Wobtq Similarity: 0.6047 Text: Your content Some of our services give you the opportunity to make your content publicly available ... 2. [✗] Document ID: gAk7Gdp0CX Similarity: 0.5515 Text: Taking action in case of problems Before taking action as described below, well provide you with adv... 3. [✗] Document ID: S87XwXaHCP Similarity: 0.5178 Text: Privacy and Data Protection Our Privacy Center explains how we treat your personal data. By using th... 4. [✗] Document ID: 8IRh1E2JDB Similarity: 0.5134 Text: OUR PROPERTY The Service is protected by copyright, trademark, and other US and foreign laws. These ... 5. [✗] Document ID: 50OXirZRiR Similarity: 0.5098 Text: Uploading Content If you have a YouTube channel, you may be able to upload Content to the Service. Y... Ground truth most relevant document: Document ID: 9NIQ0Wobtq Rank in results: 1 Similarity: 0.6047
Sobre os exemplos
A tabela a seguir resume os exemplos nesta página:
Exemplo | Modelo usado | Noções básicas sobre os resultados |
|---|---|---|
Pesquisa semântica básica |
| O documento da chamada em conferência da Apple está em primeiro lugar, significativamente mais alto do que documentos não relacionados, demonstrando correspondência semântica precisa. |
Pesquisa semântica com reranker |
| A reclassificação melhora a precisão da pesquisa analisando todo o relacionamento query-documento . Enquanto a incorporação da similaridade por si só classifica o documento correto primeiro com uma pontuação moderada, o reclassificador aumenta significativamente sua pontuação de relevância, o que o separa melhor dos resultados irrelevantes. |
Pesquisa semântica multilingue |
| Os modelos de Voyage executam pesquisa semântica de forma eficaz em diferentes idiomas. O exemplo demonstra três pesquisas separadas em inglês, espanhol e chinês, cada uma identificando corretamente os documentos mais relevantes sobre os resultados de empresas de tecnologia em seus respectivos idiomas. |
Pesquisa semântica multimodal |
| O modelo oferece suporte a texto, imagem e vídeo intercalados, bem como pesquisa somente de imagem e somente vídeo. Em ambos os casos, as imagens de cães e gatos têm uma classificação significativamente mais alta do que a imagem não relacionada da bananeira, demonstrando recuperação precisa do conteúdo visual. Entradas intercaladas com texto descritivo produzem pontuações de similaridade ligeiramente mais altas do que entradas somente de imagem. |
Embeddings de partes contextualizadas |
| A parte de 15% de crescimento da receita está em primeiro lugar porque está vinculado ao documento da Leafy Inc. . As pontuações semelhantes de crescimento de parte de 7% da Geophyllum} são mais baixas, mostrando como o modelo considera com precisão o contexto do documento para distinguir entre partes semelhantes. |
Pesquisa semântica com corpus grande |
| O documento de verdade sobre o conteúdo do usuário ocupa o primeiro lugar entre 154 documentos, demonstrando recuperação eficaz em escala, apesar da complexidade semântica. |
- Acessando incorporações
Os exemplos usam o cliente Python,
voyageai.Client(), que lê automaticamente sua chave API da variável de ambienteVOYAGE_API_KEY. A API retorna um objeto de resposta. Use o atributo.embeddingspara acessar os vetores de incorporação reais:result = vo.embed(texts=["example"], model="voyage-4-large", input_type="document") embeddings = result.embeddings # List of embedding vectors - Calculando similaridade
Os exemplos calculam pontuações de similaridade entre query e incorporações de documento usando a função de produto pontual do Numpy:
np.dot(). Como as incorporações do Voyage IA são normalizadas para o comprimento 1, o produto pontual é matematicamente equivalente à similaridade do cosseno.Para classificar os resultados por similaridade, os exemplos usam a função
argsort()do Numpy para exibir os principais N resultados. O sinal negativo é classificado em ordem decrescente, de modo que as pontuações de similaridade mais altas apareçam primeiro.- Parâmetro do tipo de entrada
- O parâmetro
input_typeé definido comoqueryoudocumentpara otimizar a forma como os modelos do Voyage IA criam os vetores. Não omita este parâmetro. Para aprender mais, consulte Especificando o tipo de entrada.
Para aprender mais, consulte Como acessar os modelos de IA do Voyage ou explore a especificação completa da API.
O que é a pesquisa semântica?
A pesquisa semântica é um método de pesquisa que retorna resultados com base no significado semântica ou subjacente dos seus dados. Ao contrário da pesquisa tradicional de texto completo, que encontra correspondências de texto, a pesquisa semântica encontra vetores próximos à sua query de pesquisa no espaço multidimensional. Quanto mais próximos os vetores estiverem da sua query, mais semelhantes eles serão em significado.
Exemplo
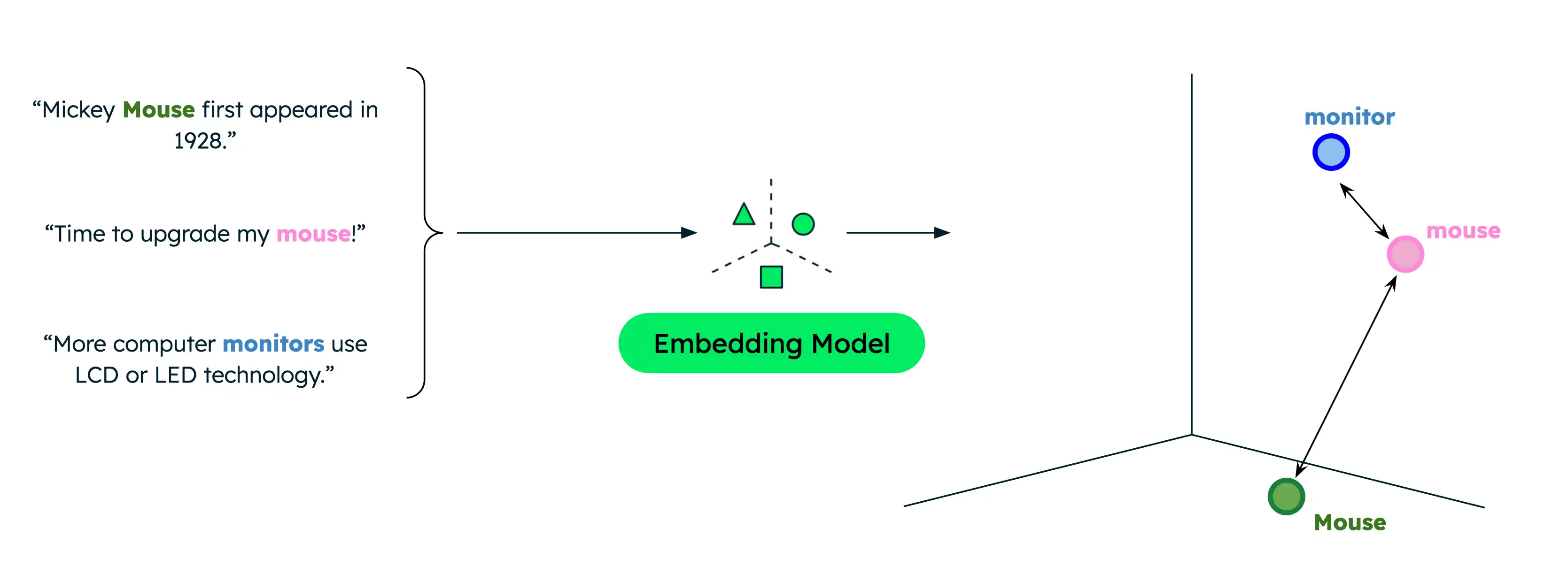
A pesquisa de texto tradicional retorna apenas correspondências exatas, limitando os resultados quando os usuários pesquisam com termos diferentes dos que estão em seus dados. Por exemplo, se seus dados contiverem documentos sobre mouse de computador e mouse animal, procurar "mouse" quando você pretende encontrar informações sobre mouse de computador resultará em correspondências incorretas.
A pesquisa semântica, no entanto, captura o relacionamento subjacente entre palavras ou frases, mesmo quando não há sobreposição lexical. Pesquisar "mouse" ao indicar que você está procurando produtos de computador resulta em resultados mais relevantes. Isso ocorre porque a pesquisa semântica compara o significado semântica da query de pesquisa com seus dados para retornar somente os resultados mais relevantes, independentemente dos termos exatos da pesquisa.

As funções de similaridade medem o quão próximos dois vetores estão um do outro e, portanto, o quão semelhantes eles são. Funções comuns incluem produto pontual, similaridade de cosseno e distância euclidiano. As incorporações da Voyage IA são normalizadas para o comprimento 1, o que significa que:
A similaridade do cosseno é equivalente à similaridade do produto pontual, enquanto esta pode ser calculada mais rapidamente.
A similaridade do cosseno e a distância euclideana resultam em classificações idênticas.
Pesquisa semântica em produção
Embora o armazenamento de seus vetores na memória e a implementação de seus próprios pipelines de pesquisa seja adequado para a criação de protótipos e experimentação, use um banco de dados vetorial e uma solução de pesquisa corporativa para aplicativos de produção, para que você possa realizar a recuperação eficiente a partir de um corpus maior.
O MongoDB tem suporte nativo para armazenamento e recuperação de vetores, sendo uma opção conveniente para armazenar e pesquisar incorporações de vetor junto com seus outros dados. Para concluir um tutorial sobre como executar a pesquisa semântica com o MongoDB Vector Search, consulte Como executar a pesquisa semântica em dados em seu cluster do Atlas.
Próximos passos
Combine a pesquisa semântica com um LLM para implementar um aplicativo RAG.