Casos de uso: Personalização, IA generativa
Setores: mídia, telecomunicações
Produtos e ferramentas: MongoDB Atlas, MongoDB Vector Search, MongoDB Atlas Stream Processing
Parceiros: Voyage AI, Azure OpenAI
Visão Geral da Solução
Quando um novo usuário chega em seu site de notícias, você tem segundos para entender o que ele está procurando antes que ele possa perder o interesse e sair. Isso introduz o problema da inicialização a frio: como você recomenda conteúdo aos usuários sem dados anteriores sobre eles?
Considere um usuário anônimo que acessa seu site e clica em três artigos:
"VIDIA cria novo processador de IA"
"TSMC expande produção no Arizona"
"Ações da Intel cai em meio a atrasos"
Uma simples pesquisa por palavra-chave só recomenda outros artigos sobre Intel ou Arizona. No entanto, um sistema inteligente reconhece que todos os três cliques estão relacionados a cadeias de suprimentos de semicondutores. Isso permite que ele recomande artigos relevantes como "O futuro do vale do silício", mesmo quando eles não compartilham palavras-chave com o histórico de navegação do usuário.
A solução deste artigo cria um sistema inteligente de personalização de mídia que ingere e processa dados de cliques para gerar um resumo em linguagem natural dos interesses do usuário e recomenda artigos relevantes com os quais o usuário tem maior probabilidade de se envolver.
Esta solução combina:
Atlas Stream Processing para ingestão de dados em tempo real, enriquecimento e integração LLM para resumir a intenção do usuário a partir de dados de fluxo de cliques
Atlas Vector Search com incorporações automatizadas de IA Voyage para recuperação semântica e recomendações
Arquitetura de referência
Essa arquitetura mostra como criar um mecanismo de recomendações de mídia orientado por IA que ingere, processa e reage ao comportamento do usuário em tempo real usando o MongoDB Atlas.

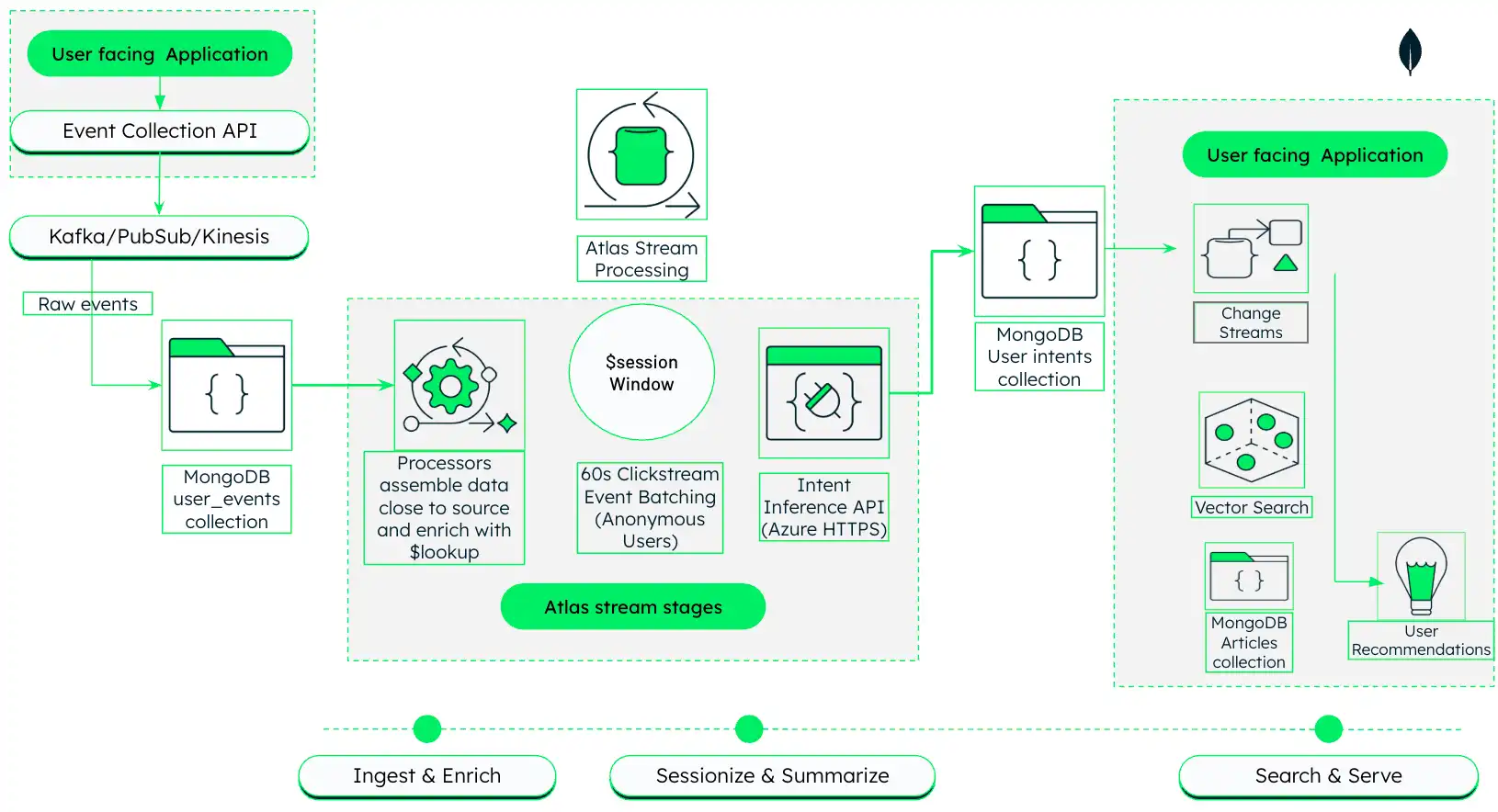
figura 1. Arquitetura de personalização de mídia orientada por IA com Atlas Stream Processing e MongoDB Vector Search
Essa arquitetura opera em três fases, que são descritas em detalhes nas próximas seções:
Ingestão e enriquecimento: capture eventos de fluxo de cliques brutos do aplicação voltado para o usuário e una-os com metadados de artigo em tempo real usando o Atlas Stream Processing.
Sessão e resumo: Agrupe cliques relacionados em sessões e use um LLM para gerar resumos em linguagem natural dos interesses do usuário.
Pesquisar e servir: Use resumos gerados para direcionar a pesquisa de vetor semântica e retornar recomendações personalizadas.
Fase 1: ingestão e enriquecimento de dados do fluxo de cliques
Na primeira fase, essa arquitetura de solução usa o Atlas Stream Processing para consumir dados brutos de cliques de sua plataforma de mídia e enriquecê-los com metadados dos artigos em seu banco de dados.
Configure suas fontes de dados.
Esta solução utiliza as seguintes duas collections no banco de dados news do mesmo cluster MongoDB :
A coleção articles contém metadados sobre os artigos do seu catálogo. Neste exemplo, a coleção está no banco de dados news do cluster ClickstreamCluster.
Cada documento na coleção representa um artigo e contém metadados relevantes. Por exemplo:
{ "_id": { "$oid": "696493bfbc1084032ac0adfe" }, "title": "Ukraine updates, Day 6: ‘We are sacrificing our lives for freedom,’ Zelenskyy gets standing ovation after speech to European parliament", "link": "https://nationalpost.com/news/world/ukraine-updates-day-6-russia-kyiv", "keywords": null, "creator": [ "National Post Wire Services" ], "video_url": null, "description": "Russia escalated shelling overnight of key cities in Ukraine as its troops on the ground move slowly in a large convoy toward the capital, Kyiv", "content": "8:20 a.m. EST — Ukraine's Zelenskyy tells EU: 'Prove that you are with us\" Read More", "pubDate": "2022-03-01 13:45:04", "expire_at": "Wed, 07 Sep 2022 13:45:04 GMT", "image_url": null, "source_id": "nationalpost", "country": [ "canada" ], "category": [ "top" ], "language": "english" }
A coleção user_events contém eventos de fluxo de cliques brutos ingeridos de seu aplicação voltado para o usuário. Neste exemplo, a coleção está no banco de dados news do cluster ClickstreamCluster.
Você pode configurar uma fonte de dados de cliques usando seu sistema de coleção de evento preferido. Para recriar o método mostrado no diagrama de arquitetura de referência, implemente uma API de collection de evento em seu aplicação voltado ao usuário para enviar eventos de clique para um tópico do Apache Kafka. Em seguida, use o conector do coletor MongoDB Kafka para ler a partir do tópico do fluxo de cliques e gravar na user_events coleção do cluster MongoDB .
Cada clique em artigo gera um documento de evento com campos como session_id, article_id e timestamp. Por exemplo:
{ "_id": { "$oid": "696a1ecd66a51be18fffb8fa" }, "user_id": "user-2", "session_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "timestamp": { "$date": "2026-01-16T16:49:41.208Z" }, "event_type": "read", "article_id": { "$oid": "696493e6bc1084032ac116ed" }, "device": "desktop", "metadata": { "time_on_page": 54, "referral": "https://guzman.com/main/search/listmain.jsp" } }
Crie um espaço de trabalho do Stream Processing.
No Atlas, Go para a página Stream Processing do seu projeto.
Se ainda não tiver sido exibido, selecione a organização que contém seu projeto no menu Organizations na barra de navegação.
Se ainda não estiver exibido, selecione seu projeto no menu Projects na barra de navegação.
Na barra lateral, clique em Stream Processing sob o título Streaming Data.
A página Processamento de fluxo é exibida.
Clique em Create a workspace.
Na página Create a stream processing workspace, configure seu espaço de trabalho da seguinte maneira:
Tier:
SP30Provider:
AWSRegion:
us-east-1Workspace Name:
article-personalization
Adicione uma conexão para seu fluxo de cliques e dados de artigos.
O processador de stream precisa de conexões com os dados de stream de cliques e com os metadados de artigo para realizar o enriquecimento. Ambas as fontes de dados devem estar no mesmo Atlas cluster.
No painel da sua área de trabalho do processamento de fluxos, clique em Manage.
Na aba Connection Registry , clique em + Add Connection no canto superior direito.
Na página Edit Connection, configure sua conexão da seguinte maneira:
Tipo de conexão:
Atlas DatabaseNome da conexão:
usereventsAtlas Cluster: o nome do cluster onde seu fluxo de cliques e dados de artigo residem (por
ClickstreamClusterexemplo,)Executar como:
Read and write to any database
Clique em Save changes para criar a conexão.
Crie um processador de fluxo persistente.
Crie um processador de fluxo denominado userIntentSummarizer com estágios que leem eventos de cliques brutos da coleção user_events e enriqueçam os eventos com metadados de artigo.
Na página Processamento de Stream do seu projeto Atlas , clique Manage em no painel do seu espaço de trabalho de processamento de stream.
JSON editorNo, copie e cole a seguinte definição deJSON do na caixa de texto do editor de JSON para definir um processador de fluxo denominado
userIntentSummarizercom estes estágios:$source: lê eventos de fluxo de cliques brutos dauser_eventscoleção nonewsbanco de dados do cluster de fluxo de cliques conectadouserevents(conexão).$lookup: Une os eventos de fluxo de cliques brutos com aarticlescoleção com base noarticle_idcampo , levando metadados de artigos relevantes dos campos,descriptionkeywordstitlee.$addFields: projeta osdescriptioncampos,keywordsetitledo campoarticle_detailsno nível superior do fluxo de evento para torná-los facilmente acessíveis para os estágios downstream.$project: Projeta campos relevantes para processamento downstream.
{ "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, Clique em Update stream processor para salvar suas alterações.
Fase 2: Sessão e resumo do comportamento do usuário
Nesta fase, estendemos o pipeline do processador de fluxo para agrupar cliques relacionados em sessões e usamos um LLM para gerar um resumo em linguagem natural de cada sessão que descreve os interesses do usuário.
Conecte seu provedor de LLM ao seu espaço de trabalho de processamento de fluxo.
Adicione uma conexão HTTPS externa ao seu provedor de LLM (por exemplo, Azure OpenAI) para permitir que o processador de fluxo chame o LLM diretamente do pipeline para enriquecer seus dados:
No painel da sua área de trabalho do processamento de fluxos, clique em Manage.
Na aba Connection Registry , clique em + Add Connection no canto superior direito.
Configure a conexão da seguinte maneira:
Tipo de conexão:
HTTPSNome da conexão:
azureopenaiURL: a URL do ponto de conexão para sua instância do Azure OpenAI
Cabeçalhos: adicione estes pares de valores-chave aos cabeçalhos:
Chave:
Content-Type, Valor:application/jsonChave:
api-key, Valor: Sua chave de API do Azure OpenAI
Sessionize os dados do fluxo de cliques usando o $sessionWindow estágio .
Adicione um estágio ao pipeline do processador de fluxo para agrupar eventos relacionados em sessões com base em uma lacuna de sessão especificada. Esta solução define uma sessão como uma sequência de eventos do $sessionWindow mesmo session_id sem intervalo de inatividade superior a 60 segundos.
Adicione este estágio ao seu pipeline userIntentSummarizer após os estágios de enriquecimento:
{ "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }
Resuma as sessões de usuários usando o $https estágio.
Adicione um estágio para chamar seu provedor de LLM diretamente de seu pipeline de processamento de fluxo. Essa solução chama o Azure OpenAI para gerar um resumo em linguagem natural de cada sessão que descreve os interesses do usuário com base nos títulos dos artigos da $https sessão.
Adicione este estágio ao seu pipeline após o estágio $sessionWindow:
{ "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions the create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }
Observação
O processador de fluxo em si é "inteligente". Ele transforma uma lista de títulos em um resumo semântica (por exemplo, "O usuário está pesquisando lógica de produção de semicondutores") antes que os dados cheguem ao disco. Isso difere fundamentalmente dos pipelines tradicionais de processamento em lote , que normalmente gravam dados brutos de sessão em um banco de dados e, em seguida, chamam uma API externa de um servidor de aplicação .
Escreva resumos de sessão para uma nova coleção.
Adicione os seguintes estágios ao pipeline para extrair o resumo da saída do LLM e escrevê-lo em uma nova collection:
$match: Filtra todas as sessões em que a chamada LLM falhou e retornou um erro para evitar a gravação de dados incompletos no banco de dados.$addFields: Extrai osummarycampo da saída do LLM e o adiciona ao nível superior do documento.$project: remove a saída LLM bruta do documento para reduzir o ruído e os custos de armazenamento.$merge: Grava os documentos resultantes em uma nova coleção chamadauser_intentnonewsbanco de dados do seu cluster de cliquesuserevents(conexão). Cada documento nesta coleção representa uma sessão de usuário e contém um resumo dos interesses do usuário.
{ "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } }
Inicie o processador de fluxo.
Quando estiver pronto para começar a resumir seus dados de fluxo de cliques, clique no ícone Start do processador userIntentSummarizer na lista de processadores de fluxo para seu espaço de trabalho de processamento de fluxo.
Esse pipeline deve escrever documentos na coleção user_intent que contenham resumos de sessão que capturem os interesses do usuário. Por exemplo:
{ "_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "summary": "The user seems interested in geopolitical developments, especially in the Middle East, US political strategies involving Trump, and legal aspects of government operations.", "titles": [ "Israel and Hamas agree to part of Trump's Gaza peace plan, will free hostages and prisoners", "Top officials from US and Qatar join talks aimed at brokering peace in Gaza", "How Trump secured a Gaza breakthrough", "Ontario's anti-tariff ad is clever, effective and legally sound, experts say", "Shutdown? Trump's been dismantling the government all year", "AP News Summary at 7:58 p.m. EDT" ] }
A seguir está a definição JSON completa para o userIntentSummarizer processador de fluxo que executa todas as operações descritas nas Fases 1 2e, incluindo a ingestão de dados de fluxo de cliques, enriquecimento-os com metadados de artigo, sessão do comportamento do usuário, chamada de um LLM para resumir intenção do usuário e escrever os resumos em uma nova collection.
{ "name": "userIntentSummarizer", "pipeline": [ { "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, { "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }, { "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions then create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }, { "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } } ] }
Fase 3: pesquisa semântica e recomendações personalizadas de serviço
Por fim, usamos o MongoDB Vector Search para realizar a pesquisa semântica no catálogo de artigos usando os resumos de sessão gerados na fase anterior para gerar recomendações de conteúdo personalizadas.
Prepare os dados do artigo para recuperação semântica.
Antes de realizar a pesquisa semântica, você precisa gerar incorporações vetoriais para os dados do artigo. Para fazer isso, crie um índice do MongoDB Vector Search chamado vector_index que indexe o description campo da sua articles coleção como o autoEmbed tipo . Isso instrui o MongoDB Vector Search a usar a incorporação automatizada para gerar automaticamente incorporações vetoriais para o description campo sempre que os documentos forem inseridos ou atualizados na coleção.
Importante
A incorporação automatizada está disponível como um recurso de visualização somente para o MongoDB Community Edition v8.2 e versões mais recentes. O recurso e a documentação correspondente podem mudar a qualquer momento durante o período de Pré-visualização. Para aprender mais, consulte Visualizar recursos.
O Atlas suporta incorporação manual em todas as edições do MongoDB.
Utilize esta definição JSON para criar um índice de vetor nestes campos:
O campo
descriptioncomo o tipoautoEmbedpara instruir o MongoDB Vector Search a gerar automaticamente incorporações vetoriais para o campodescriptionusando o modelo de incorporaçãovoyage-4-largesempre que documentos forem inseridos ou atualizados na coleção.O campo
titlecomo o tipofilterpara pré-filtrar os dados para a pesquisa semântica usando o valor da string no campo. Isso permite excluir artigos que o usuário já leu dos resultados da pesquisa.
{ "fields": [ { "type": "autoEmbed", "modalitytype": "text", "path": "description", "model": "voyage-4-large" }, { "type": "filter", "path": "title" } ] }
Execute consultas de pesquisa semântica para fornecer recomendações personalizadas.
Quando um usuário visitar seu site, pegue o resumo da sessão atual e use-o como query para uma pesquisa vetorial em seu catálogo de artigos. Desde que você ativou a incorporação automatizada no índice, a Vector Search do MongoDB gera automaticamente a incorporação para o resumo no momento da query e a usa como o vetor de query efetivo.
Este exemplo mostra uma query de pesquisa vetorial simplificada que usa a sessão summary como o vetor de query e exclui artigos que o usuário já leu com base no campo titles :
[{ "$vectorSearch": { "index": "vector_index", // Vector index with autoEmbed on article descriptions "path": "description", "query": { "text": "<session-summary>" // Session summary from user_intent document }, "numCandidates": 100, "filter": { "title": { "$nin": [<read-titles>] } // Exclude articles the array of titles in the user_intent document } } }]
Principais Aprendizados
Essa arquitetura demonstra vários progressos importantes na criação de produtos de dados modernos:
Latência reduzida: a incorporação de chamadas LLM diretamente no processador de fluxo elimina vários saltos de rede e camadas de persistência intermediária. O sistema transforma cliques brutos em intenção aplicável quase em tempo real.
Experiência aprimorada do desenvolvedor: defina pipelines com MQL baseado em JSON , permitindo que equipes que já conhecem queries do MongoDB criem streaming avançado e cargas de trabalho alimentadas por IA sem aprender novos DSLs ou provisionar infraestrutura adicional.
Personalização semântica: vá além da correspondência de palavras-chave e dos trabalhos em lote da noite para o dia para criar sistemas que escutam, refletem e respondem instantaneamente ao comportamento do usuário.
Autores
Vinod Krsnaan, arquitetura de soluções, MongoDB
Saiba mais
Para entender como o Atlas Vector Search aprimora a pesquisa semântica e habilita a análise em tempo real, visite a página do Atlas Vector Search.
Para saber como o MongoDB está transformando as operações de mídia, leia o artigo Personalização de mídia alimentada por IA: MongoDB e Vector Search.
Para descobrir como o MongoDB oferece suporte a fluxos de trabalho de mídia modernos, visite a página MongoDB para mídia e entretenimento.
Para saber mais sobre o Atlas Stream Processing, acesse a documentação de Atlas Stream Processing .