이 페이지에서는 MongoDB Vector Search 성능 벤치마크결과를 살펴봅니다.
결과 요약
2048 차원에서
voyage-3-large임베딩을 사용하는 15.3M 벡터에서, 양자화가 구성된 MongoDB Vector Search는 쿼리 지연 시간< 50ms인 상태에서 90~95%의 정확도를 유지합니다.이진 양자화는 후보 수가 수백 개일 때 완전 정밀 벡터로 재점수화하는 추가 비용 때문에 속도가 더 느려집니다. 하지만 인덱스 제공 비용이 약 1/4 수준이라면 많은 대규모 워크로드에서 더 효과적인 선택이 될 수 있습니다.
대규모 워크로드를 양자화하여 실행할 때는 1024차원 이상을 권장합니다.
numCandidates에 선택된 값에 따라 선택적 필터가 성능을 향상시키거나 악화시킬 수 있습니다.이진 양자화를 위한 재점수화의 추가 비용은 높은 동시성 워크로드에서 처리량 감소로 나타납니다.
샤딩은 처리량을 약간 개선하지만 처리량 향상을 위해 검색 노드의 수를 늘리거나 검색 노드의 사용 가능한 코어 수를 확장할 것을 권장합니다.
다차원 벤치마크 전반에 걸친 리콜 및 지연 시간 분석
첫 번째 결과 집합은 5.5M(550만 개) 문서로 구성된 데이터셋에 대해 수행한 테스트를 보여줍니다. 이 데이터세트는 각 문서마다 voyage-3-large를 사용해 생성한 다양한 차원(256, 512, 1024, 2048)의 벡터를 포함하고 있습니다.

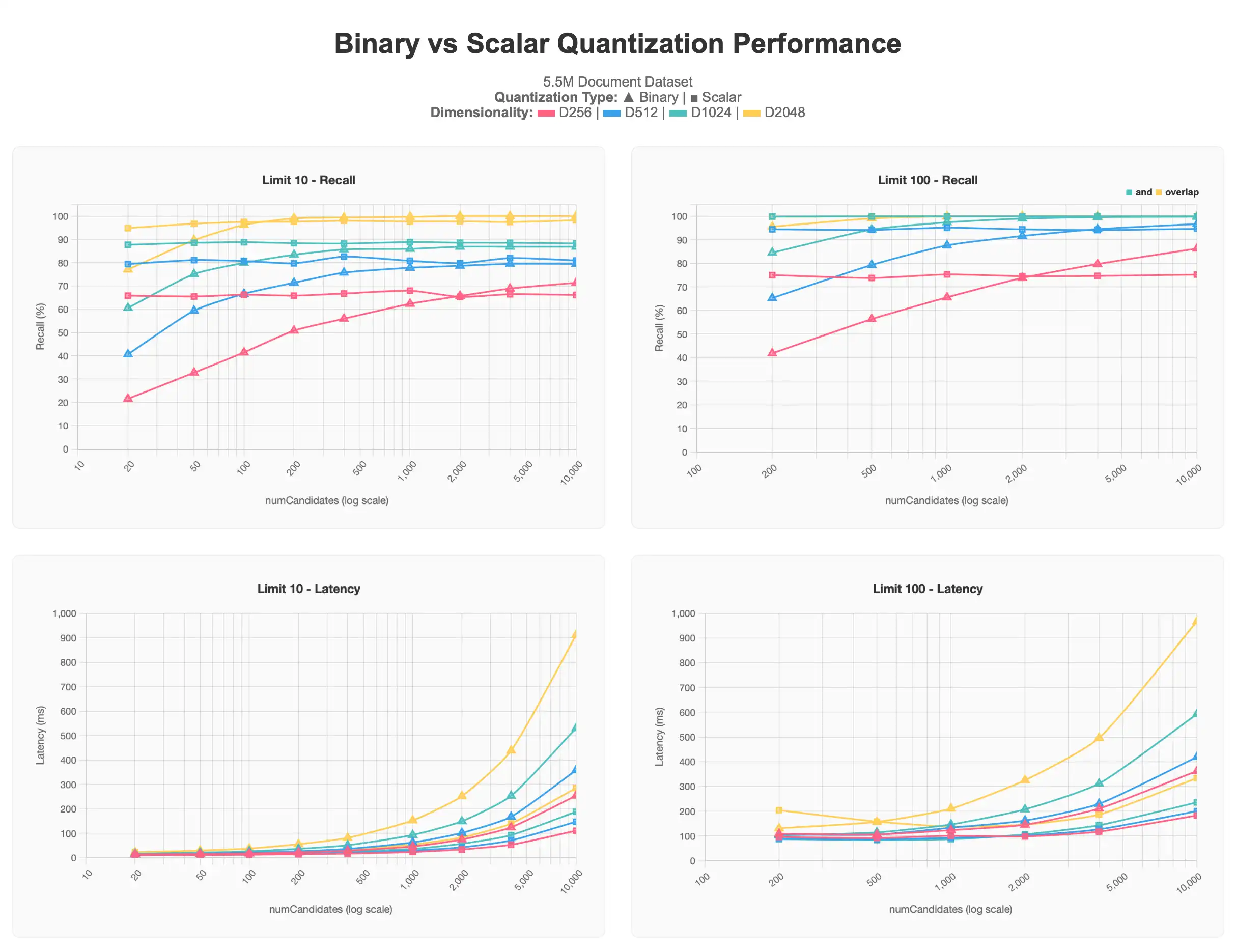
전체 차트 보려면 Claude 아티팩트를 참조하세요.
스칼라 양자화된 결과는 모두 이진 양자화된 결과보다 높은 수준에서 시작하지만 numCandidates 이 증가해도 점근 수준을 유지합니다. 반대로 이진 양자화된 쿼리는 더 많은 numCandidates 가 요청될수록 더 정확한 결과를 산출하여 스칼라 양자화의 점근선에 접근하고, 일부 경우에는 이를 전달하는데, 특히 1000의 numCandidates 이상에서는 지연 시간 비용 .
일반적으로 limit의 값이 낮을수록 상위 결과를 정확히 찾아내기 어려워 100%의 정확도에 도달하기가 더 어렵고, 더 나은 결과를 얻으려면 종종 numCandidates 값을 더 높여야 할 수도 있습니다. 이는 이진 양자화 플롯에서 특히 잘 관찰할 수 있습니다. 또한 256차원 및 512차원과 같은 저차원 벡터는 어떤 형태의 양자화를 적용하더라도 대규모 환경에서 특히 성능 저하를 겪는다는 것을 알 수 있습니다. 256차원 벡터는 limit 10 테스트에서 70% 이상의 리콜을 초과하지 못하고, 512차원 벡터도 80%를 초과하지 못합니다. 또한 limit 100 테스트에서 90~95% 목표 구간에 도달하려면 더 높은 numCandidates 값이 필요합니다.
이러한 정보를 바탕으로 대규모 데이터셋을 다룰 때는 1024차원 이상의 차원을 유지하고 양자화를 적용하는 것이, 낮은 차원에 양자화를 적용하지 않는 것보다 확장성 측면에서 더 좋다는 결론을 내렸습니다. 또한 요청하는 벡터의 수 역시 결과에 영향을 미칩니다.
더 큰 규모의 벤치마크 결과
더 큰 15.3M(1,530만 개) 벡터 데이터셋의 경우 차원을 2048차원으로 고정한 뒤 양자화, 필터링 및 동시성이 성능에 미치는 영향을 조사했습니다. 이전 테스트 결과에서 더 높은 차원이 리콜(재현율) 유지에 더 유리하게 작용했기 때문에 2048차원으로 설정하였으며, 사실 1024차원만으로도 90~95% 리콜 목표 달성에는 충분했을 것입니다.
리콜 및 지연 시간 분석
이진 양자화를 사용할 때, 기준선과 비교하여 90~95% 리콜 목표를 달성하려면 훨씬 더 많은 numCandidates가 필요하다는 것을 관찰했습니다. numCandidates가 높을수록 일반적으로 지연 시간이 길어지지만, 이는 상황에 따라 달라질 수 있습니다.

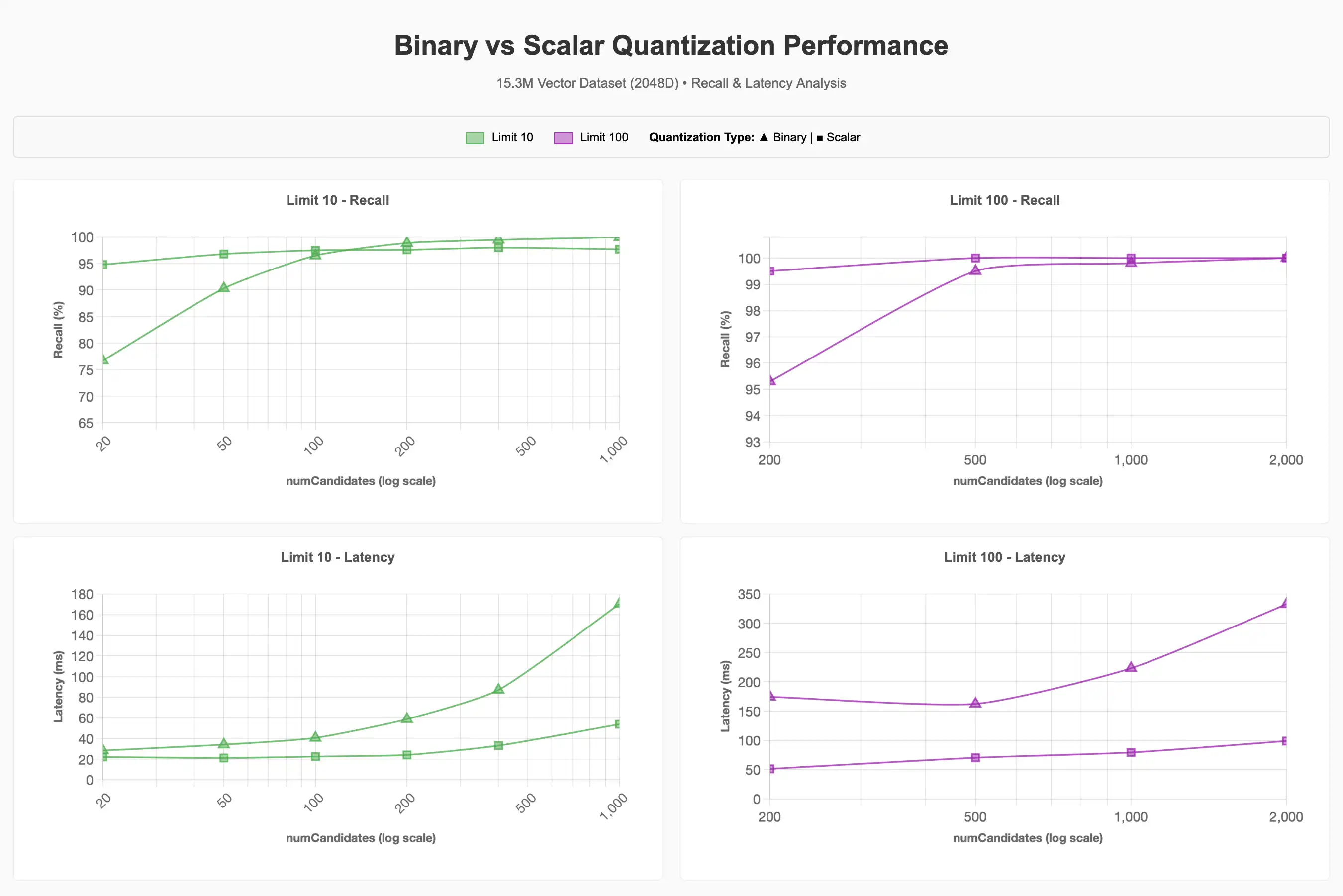
전체 차트를 보려면 Claude 아티팩트를 참조하세요.
필터링
15.3M(1,530만 개) 항목 중 약 500k(전체의 약 3%에 해당하는 약 50만 개)가 반려동물 용품 카테고리에 속하는 데이터셋에 선택적 필터를 적용할 때 리콜과 지연 시간이 어떻게 변하는지 관찰했습니다.

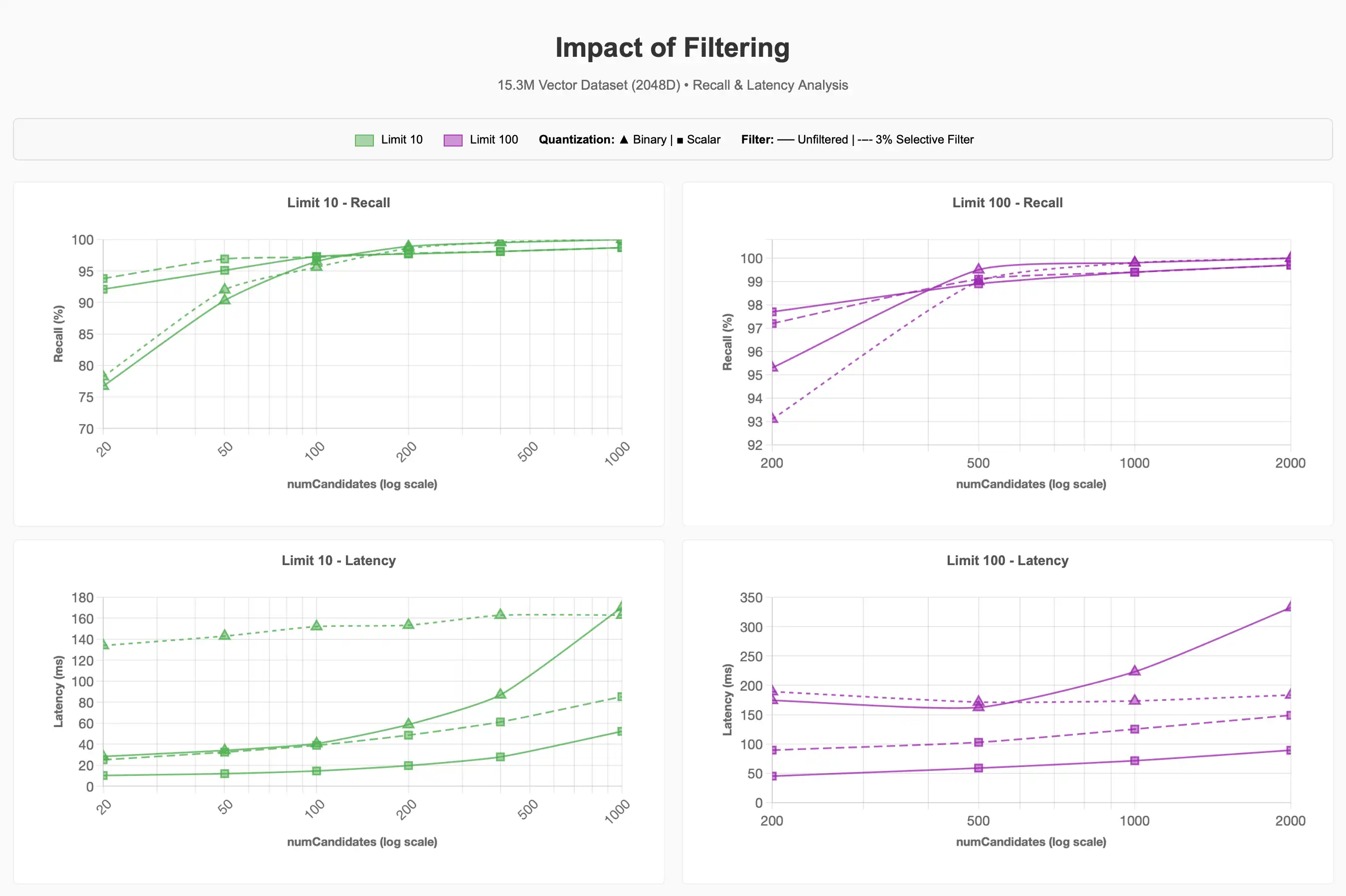
전체 차트를 보려면 Claude 아티팩트를 참조하세요.
3% 선택적 필터가 쿼리의 비용을 상당히 증가시킬 수 있음을 알 수 있습니다. 더 낮은 limit 값에서 이진 양자화를 사용할 경우, 필터를 적용하지 않은 쿼리보다 90~95% 재현율을 달성하는 데 약 4배 높은 비용이 소요되었습니다.
Lucene 10의 향후 개선사항에서 계층적 네비게이션 스몰월드를 위한 Acorn-1 검색 전략이 지원되면 이 프로세스가 개선될 가능성이 있습니다 그러나 세그먼트 내 메타데이터 필터와 일치하는 벡터 수보다 더 많은 후보를 요청해 등가 최근접 이웃을 수행하면, 양자화 방식과 무관하게 필터 선택성이 쿼리 성능에 크게 작용함을 보여줍니다.
동시성
이 테스트는 스칼라 및 이진 양자화를 사용할 때 다양한 limit 값에서 동시 요청 수를 1, 10 및 100으로 확장하여 테스트했습니다. numCandidates 값은 90~95%의 리콜을 달성할 수 있도록 선택되었습니다.

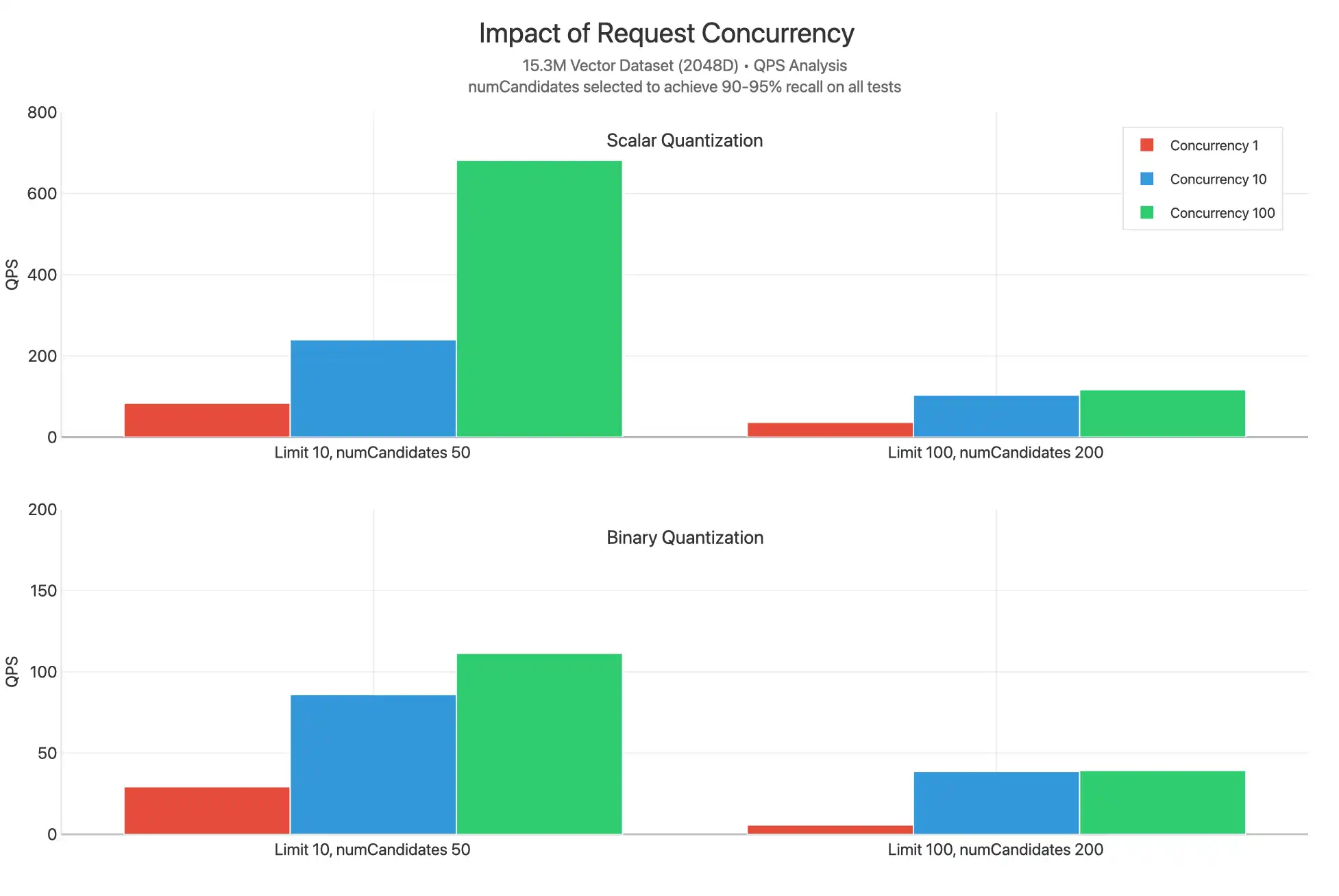
전체 차트를 보려면 Claude 아티팩트를 참조하세요.
스칼라 양자화는 모든 limit 값에서 훨씬 더 높은 QPS를 달성하는 것으로 나타나는데 이는 numCandidates 값이 낮아 쿼리별로 수행되는 작업이 적고, 재점수화가 필요하지 않기 때문인 것으로 보입니다. 동시성 10과 동시성 100 조건의 플롯이 매우 근접하게 나타나는 것으로 볼 때, 상당한 CPU 병목 현상이 발생하고 있으며, 이로 인해 더 높은 지연 시간이 나타날 수 있음을 알 수 있습니다.
예외적으로, 스칼라 양자화에서 limit 10, 동시성 100 조건에서는 QPS가 현저히 더 높게 나타나는 데이터 포인트가 있습니다. 이는 재점수화를 하지 않고 limit 값이 낮을수록 쿼리별 비교 작업이 적어지기 때문에, 각 요청의 반환이 더 빨라지고 코어가 다른 쿼리 처리에 더 효과적으로 사용될 수 있기 때문입니다.
요청 처리를 위한 사용 가능한 vCPU 수를 확장하려면 검색 노드 계층을 확장하거나 검색 노드 수를 최소 2에서 최대 32 노드로 확장하는 방식이 동시성 병목 현상을 해소하고, 수천 건의 QPS 수준까지 무리 없이 확장할 수 있도록 도와줄 수 있습니다.
샤딩
클러스터와 컬렉션이 _id에서 샤딩되고, 바이너리 양자화 인덱스에 대해 필터링되지 않은 쿼리가 실행될 경우 어떤 일이 발생하는지도 관찰했습니다.

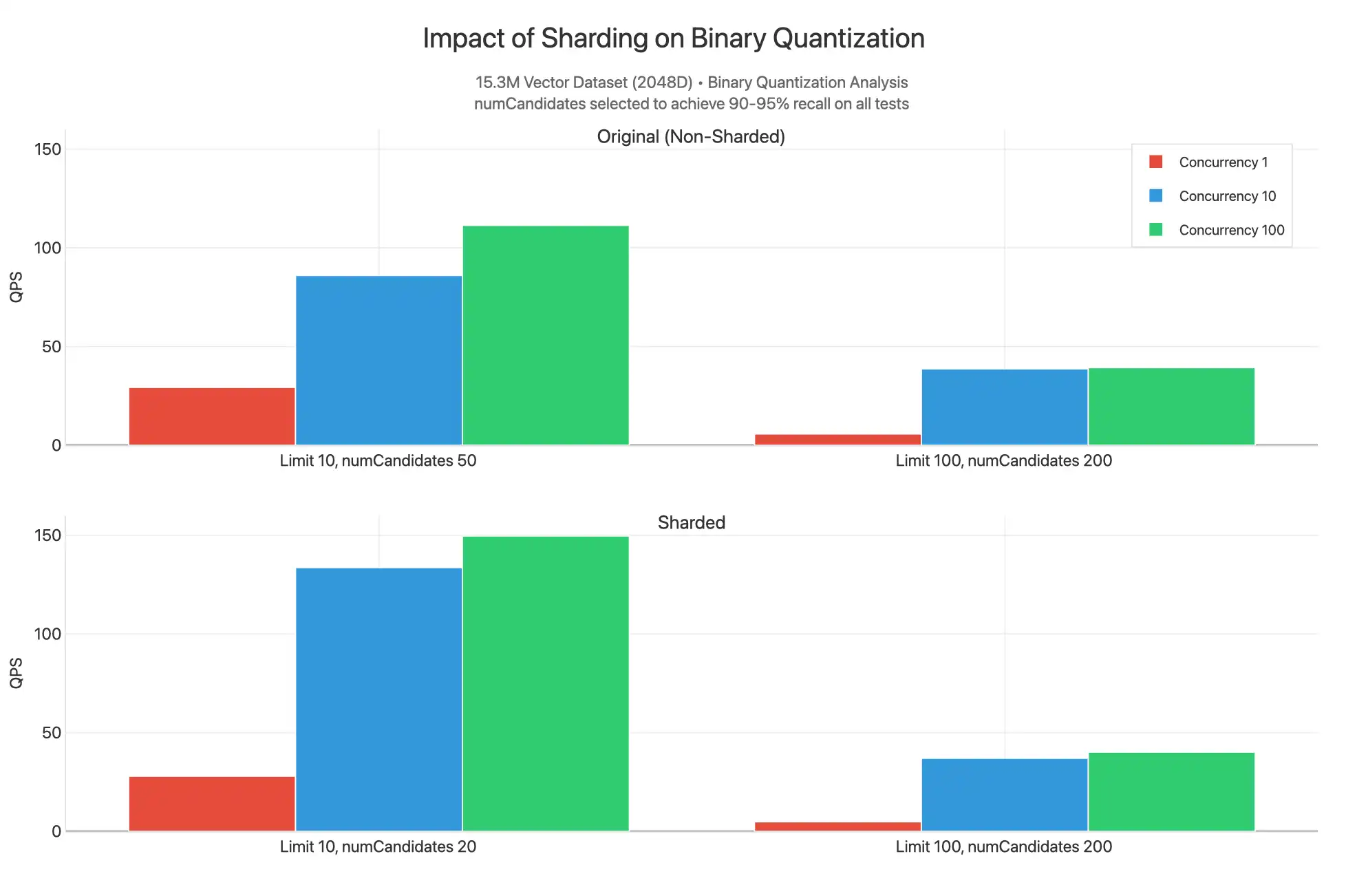
전체 차트를 보려면 Claude 아티팩트를 참조하세요.
여기에서 numCandidates 의 더 낮은 값을 제공하여 90~95% 재현율 범위 에서 결과를 생성할 수 있으므로 샤딩된 결과가 limit 10 에서 더 높은 QPS를 갖는 것을 볼 수 있습니다. 이는 15.3M 개의 데이터 세트가 세 개의 샤드로 분할 있고, 각 샤드에는 HNSW 그래프가 포함된 세그먼트에 분산된 5.1M 개의 벡터로 채워진 자체 인덱스가 있기 때문입니다. 우리는 3 샤드에 동시에 수집된 각 쿼리 분산형이 가장 가까운 n 벡터를 찾을 가능성이 더 높은 덜 고급 검색 기능적으로 수행하고 있습니다. 이러한 이유로 numCandidates 를 줄이고 쿼리를 제공 데 사용할 수 있는 코어를 더 많이 가질 수 있으므로 샤딩 할 때 QPS가 약간 더 높지만, 클러스터 샤딩 비용 증가를 정당화할 만큼 그 차이는 크지 않습니다. 대부분의 경우 벡터 검색 위한 처리량 확장하다 해야 하기 때문이 아니라 운영 워크로드 와 관련된 이유로 클러스터 샤드 해야 합니다.
참고
limit 100, numCandidates 200의 경우에도 값은 유사합니다. 지능형 샤드 키 매칭이 필터로 사용되는 필터 쿼리에서는 더 나은 성능을 기대할 수 있습니다.