산업: 미디어, 통신
제품 및 도구: MongoDB Atlas, MongoDB Vector Search, MongoDB Atlas 스트림 처리
파트너: 보야지AI, Azure OpenAI
솔루션 개요
신규 사용자가 뉴스 사이트 방문하면 사용자가 관심을 잃고 사이트를 떠나기 전에 그들이 찾고 있는 내용을 이해할 수 있는 시간이 있습니다. 이로 인해 콜드 스타트 문제가 발생합니다: 이전 데이터가 없는 사용자에게 콘텐츠를 어떻게 추천하나요?
익명의 사용자가 귀하의 사이트 방문하여 세 개의 기사를 클릭한다고 가정해 보겠습니다.
"NVIdia는 새로운 AI 칩을 만듭니다"
"TSMC, 애리조나주에서 생산 확장"
"지연 속 인텔 주식 하락"
간단한 키워드 검색 인텔 또는 애리조나에 대한 다른 기사만 추천합니다. 그러나 지능형 시스템은 세 번의 클릭 모두 반도체 공급망과 관련이 있음을 인식합니다. 이를 통해 사용자의 인터넷 사용 기록과 키워드를 주식 하지 않더라도 "실리콘 밸리의 미래"와 같은 관련 기사를 추천할 수 있습니다.
이 기사의 솔루션은 클릭스트림 데이터를 수집 및 처리하여 사용자의 관심사에 대한 자연어 요약을 생성하고 사용자가 참여할 가능성이 더 높은 관련 기사를 추천하는 지능형 미디어 개인화 시스템을 구축합니다.
이 솔루션은 다음을 결합합니다.
클릭스트림 데이터에서 사용자 의도를 요약하는 실시간 데이터 수집, 보강 및 LLM 통합을위한 Atlas Stream Processing
시맨틱 검색 및 추천을 위한 자동화된 Voyage AI 임베딩을 갖춘Atlas Vector Search
참고 아키텍처
이 아키텍처는 MongoDB Atlas 사용하여 실시간 사용자 행동을 수집, 처리 및 반응하는 AI 기반 미디어 추천 엔진 빌드 방법을 보여줍니다.

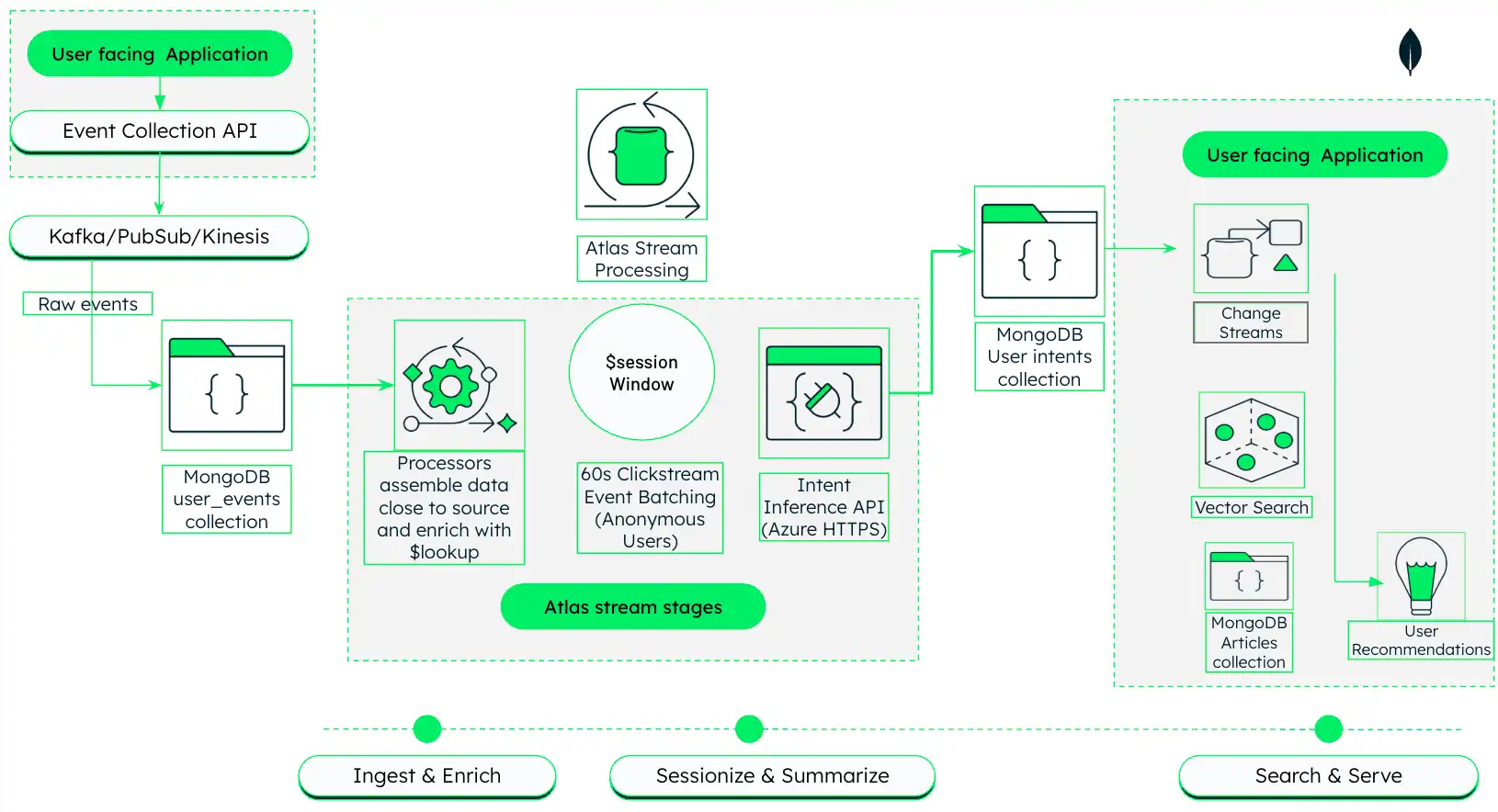
그림 1. Atlas Stream Processing 및 MongoDB Vector Search를 사용한 AI 기반 미디어 개인화 아키텍처
이 아키텍처는 세 단계로 작동하며, 자세한 내용은 다음 섹션에서 설명합니다.
수집 및 보강: 사용자용 애플리케이션 에서 원시 클릭스트림 이벤트를 캡처하고 Atlas Stream Processing 사용하여 실시간 아티클 메타데이터 와 결합합니다.
세션화 및 요약: 관련 클릭을 세션으로 그룹화하고 LLM을 사용하여 사용자 관심사에 대한 자연어 요약을 생성합니다.
검색 및 검색: 생성된 요약을 사용하여 시맨틱 벡터 검색 유도하고 개인화된 추천을 반환합니다.
1단계: 클릭스트림 데이터 수집 및 강화
첫 번째 단계에서 이 솔루션 아키텍처는 Atlas Stream Processing 사용하여 미디어 플랫폼에서 원시 클릭 스트림 데이터를 수집하고 데이터베이스 에 있는 아티클의 메타데이터 로 보강합니다.
데이터 소스를 설정합니다.
이 솔루션은 동일한 MongoDB cluster 의 news 데이터베이스 에서 다음 두 컬렉션을 사용합니다.
articles 컬렉션 카탈로그의 문서에 대한 메타데이터 포함되어 있습니다. 이 예시 에서 컬렉션 ClickstreamCluster 클러스터 의 news 데이터베이스 에 있습니다.
컬렉션 의 각 문서 문서를 나타내며 관련 메타데이터 포함합니다. 예시 들면 다음과 같습니다.
{ "_id": { "$oid": "696493bfbc1084032ac0adfe" }, "title": "Ukraine updates, Day 6: ‘We are sacrificing our lives for freedom,’ Zelenskyy gets standing ovation after speech to European parliament", "link": "https://nationalpost.com/news/world/ukraine-updates-day-6-russia-kyiv", "keywords": null, "creator": [ "National Post Wire Services" ], "video_url": null, "description": "Russia escalated shelling overnight of key cities in Ukraine as its troops on the ground move slowly in a large convoy toward the capital, Kyiv", "content": "8:20 a.m. EST — Ukraine's Zelenskyy tells EU: 'Prove that you are with us\" Read More", "pubDate": "2022-03-01 13:45:04", "expire_at": "Wed, 07 Sep 2022 13:45:04 GMT", "image_url": null, "source_id": "nationalpost", "country": [ "canada" ], "category": [ "top" ], "language": "english" }
user_events 컬렉션 사용자용 애플리케이션 에서 수집한 원시 클릭스트림 이벤트가 포함되어 있습니다. 이 예시 에서 컬렉션 ClickstreamCluster 클러스터 의 news 데이터베이스 에 있습니다.
선호하는 이벤트 컬렉션 시스템을 사용하여 클릭스트림 데이터 소스 설정하다 수 있습니다. 참조 아키텍처 다이어그램에 표시된 메서드를 다시 만들려면 사용자 대면 애플리케이션 에서 이벤트 컬렉션 API 구현 Apache Kafka 주제 에 클릭 이벤트를 전송합니다. 그런 다음 MongoDB Kafka Sink Connector를 사용하여 클릭스트림 주제 에서 읽고 MongoDB cluster의 컬렉션 에 쓰기 (write) user_events .
아티클을 클릭할 때마다 session_id, article_id, timestamp 등의 필드가 있는 이벤트 문서 생성됩니다. 예시 들면 다음과 같습니다.
{ "_id": { "$oid": "696a1ecd66a51be18fffb8fa" }, "user_id": "user-2", "session_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "timestamp": { "$date": "2026-01-16T16:49:41.208Z" }, "event_type": "read", "article_id": { "$oid": "696493e6bc1084032ac116ed" }, "device": "desktop", "metadata": { "time_on_page": 54, "referral": "https://guzman.com/main/search/listmain.jsp" } }
Stream Processing Workspace을 생성합니다.
Atlas 에서 프로젝트의 Stream Processing 페이지로 Go 합니다.
아직 표시되지 않은 경우 탐색 표시줄의 Organizations 메뉴에서 프로젝트가 포함된 조직을 선택합니다.
아직 표시되지 않은 경우 내비게이션 바의 Projects 메뉴에서 프로젝트를 선택합니다.
사이드바에서 Streaming Data 제목 아래의 Stream Processing를 클릭합니다.
스트림 처리 페이지가 표시됩니다.
Create a workspace를 클릭합니다.
Create a stream processing workspace 페이지에서 작업 공간을 다음과 같이 설정합니다.
Tier:
SP30Provider:
AWSRegion:
us-east-1Workspace Name:
article-personalization
클릭스트림과 아티클 데이터에 대한 연결을 추가합니다.
스트림 프로세서는 보강을 수행하기 위해 클릭스트림 데이터와 아티클 메타데이터 모두에 대한 연결이 필요합니다. 두 데이터 소스 모두 동일한 Atlas cluster 에 있어야 합니다.
스트림 처리 작업 공간의 창에서 Manage를 클릭하세요.
Connection Registry 탭에서 오른쪽 상단의 + Add Connection 을 클릭합니다.
Edit Connection 페이지에서 다음과 같이 연결을 구성합니다.
연결 유형:
Atlas Database연결 이름:
usereventsAtlas Cluster: 클릭스트림 및 아티클 데이터가 있는 클러스터 의 이름(
ClickstreamCluster예시:)다음으로 실행:
Read and write to any database
연결을 만들려면 Save changes 을 클릭합니다.
영구 스트림 프로세서를 생성합니다.
user_events 컬렉션 에서 원시 클릭스트림 이벤트를 읽고 아티클 메타데이터 로 이벤트를 보강하는 단계로 이름이 userIntentSummarizer 인 스트림 프로세서를 만듭니다.
Atlas 프로젝트 의 Stream Processing 페이지에서 Manage 스트림 처리 작업 공간의 창에서 를 클릭합니다.
JSON editor에서 다음 JSON 정의를 복사하여 JSON 편집기 텍스트 상자에 붙여넣어
userIntentSummarizer이러한 단계를 통해 이라는 이름의 스트림 프로세서를 정의합니다.$source:user_eventsnews연결된 클릭스트림 클러스터 (userevents연결)의 데이터베이스 에 있는 컬렉션 에서 원시 클릭스트림 이벤트를 읽습니다.$lookuparticlesarticle_id:description필드 기반으로 컬렉션 과 원시 클릭스트림 이벤트를keywords조인하고,, 및 필드에서 관련 아티클 메타데이터title가져옵니다.$addFields: 필드description의,keywords및 필드를titlearticle_details이벤트 스트림 의 최상위 수준으로 프로젝션하여 다운스트림 단계에서 쉽게 액세스할 수 있도록 합니다.$project: 다운스트림 처리 위한 관련 필드 를 프로젝션 합니다 .
{ "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, 변경 사항을 저장하려면 Update stream processor을 클릭합니다.
2단계: 사용자 행동 세션화 및 요약
이 단계에서는 스트림 프로세서 파이프라인 확장하여 관련 클릭을 세션으로 그룹 하고 LLM을 사용하여 사용자의 관심사를 설명하는 각 세션에 대한 자연어 요약을 생성합니다.
LLM 제공자 스트림 처리 작업 공간에 연결합니다.
스트림 프로세서가 파이프라인 에서 직접 LLM을 호출하여 데이터를 보강할 활성화 있도록 LLM 제공자 ( 예시: Azure OpenAI)에 외부 HTTPS 연결을 추가합니다.
스트림 처리 작업 공간의 창에서 Manage를 클릭하세요.
Connection Registry 탭에서 오른쪽 상단의 + Add Connection 을 클릭합니다.
다음과 같이 연결을 구성합니다.
연결 유형:
HTTPS연결 이름:
azureopenaiURL: Azure OpenAI 인스턴스 의 엔드포인트 URL
헤더: 헤더에 다음 키-값 쌍을 추가합니다.
키:
Content-Type, 값:application/json키:
api-key, 값: Azure OpenAI API 키
단계를 사용하여 클릭스트림 $sessionWindow 데이터를 세션화합니다.
스트림 프로세서 파이프라인 에 단계를 추가하여 지정된 세션 간격을 기준으로 관련 이벤트를 세션으로 그룹 . 이 솔루션은 세션을 $sessionWindow session_id 초 이상의 비활성 간격이 없는 동일한 의 이벤트 60 시퀀스로 정의합니다.
보강 단계 후에 이 단계를 userIntentSummarizer 파이프라인 에 추가합니다.
{ "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }
단계를 사용하여 사용자 세션을 $https 요약합니다.
$https 스트림 처리 파이프라인 에서 직접 LLM 제공자 호출하려면 단계를 추가합니다. 이 솔루션은 Azure OpenAI를 호출하여 세션의 문서 제목을 기반으로 사용자의 관심사를 설명하는 각 세션의 자연어 요약을 생성합니다.
파이프라인 에 이 단계를 $sessionWindow 단계 이후에 추가합니다.
{ "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions the create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }
참고
스트림 프로세서 자체는 '지능형'입니다. 데이터가 디스크에 도달하기 전에 제목 목록을 의미론적 요약( 예시 : '사용자가 반도체 제조 물류를 조사하고 있습니다')으로 변환합니다. 이는 일반적으로 원시 세션 데이터를 데이터베이스 에 쓰기 (write) 다음 애플리케이션 서버 에서 외부 API 호출하는 기존 배치 처리 파이프라인과 근본적으로 다릅니다.
새 컬렉션 에 세션 요약을 씁니다.
파이프라인 에 다음 단계를 추가하여 LLM 출력에서 요약을 추출하고 새 컬렉션 에 쓰기 (write) .
$match: 데이터베이스 에 불완전한 데이터가 기록되지 않도록 LLM 호출이 실패하고 오류를 반환한 세션을 모두 필터링합니다.$addFields:summaryLLM 출력에서 필드 추출하여 문서 의 최상위 수준에 추가합니다.$project: 문서 에서 원시 LLM 출력을 제거하여 노이즈와 저장 비용을 줄입니다.: 클릭스트림 클러스터 ( 연결)의 데이터베이스 에
$merge있는 라는 새 컬렉션 에 결과 문서를user_intentnewsuserevents씁니다. 이 컬렉션 의 각 문서 사용자 세션을 나타내며 사용자의 관심사에 대한 요약을 포함합니다.
{ "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } }
스트림 프로세서를 시작합니다.
클릭스트림 데이터 요약을 시작할 준비가 되면 스트림 처리 작업 공간의 스트림 프로세서 목록에서 userIntentSummarizer 프로세서의 Start 아이콘을 클릭합니다.
이 파이프라인 사용자의 관심사를 포착하는 세션 요약이 포함된 문서를 user_intent 컬렉션 에 쓰기 (write) 해야 합니다. 예시 들면 다음과 같습니다.
{ "_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "summary": "The user seems interested in geopolitical developments, especially in the Middle East, US political strategies involving Trump, and legal aspects of government operations.", "titles": [ "Israel and Hamas agree to part of Trump's Gaza peace plan, will free hostages and prisoners", "Top officials from US and Qatar join talks aimed at brokering peace in Gaza", "How Trump secured a Gaza breakthrough", "Ontario's anti-tariff ad is clever, effective and legally sound, experts say", "Shutdown? Trump's been dismantling the government all year", "AP News Summary at 7:58 p.m. EDT" ] }
다음은 클릭스트림 데이터 수집, 아티클 메타데이터 로 보강, 사용자 행동 세션화, 요약을 위한 LLM 호출 등 userIntentSummarizer 단계 1 및 에 설명된 모든 작업을 수행하는 스트림 프로세서에 대한 전체 JSON 정의입니다. 사용자 인텐트 및 요약을 새 컬렉션 에 기록합니다.2
{ "name": "userIntentSummarizer", "pipeline": [ { "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, { "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }, { "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions then create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }, { "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } } ] }
3단계: 시맨틱 검색 및 맞춤 추천 제공
마지막으로 MongoDB Vector Search를 사용하여 이전 단계에서 생성된 세션 요약을 사용하여 문서 카탈로그에 시맨틱 검색 수행하여 개인화된 콘텐츠 추천을 유도합니다.
시맨틱 검색을 위한 기사 데이터를 준비합니다.
시맨틱 검색 수행하려면 먼저 기사 데이터에 대한 벡터 임베딩을 생성해야 합니다. 이렇게 하려면 vector_index 컬렉션 description 의 필드 articles 유형으로 autoEmbed 인덱싱하는 이라는 이름의 MongoDB Vector Search 인덱스 만듭니다. 이는 MongoDB Vector Search가 자동 임베딩을 사용하여 컬렉션 description 에 문서가 삽입되거나 업데이트될 때마다 필드 에 대한 벡터 임베딩을 자동으로 생성하도록 지시합니다.
중요
자동 임베딩은 MongoDB Community Edition v8.2 이상에서만 미리보기 기능 으로 사용할 수 있습니다. 기능 및 해당 설명서는 미리 보기 기간에 언제든지 변경될 수 있습니다. 자세히 학습 미리 보기 기능을 참조하세요.
Atlas 모든 버전의 MongoDB 에서 수동 임베딩을 지원합니다.
이 JSON 정의를 사용하여 이러한 필드에 벡터 인덱스 생성합니다.
description필드autoEmbed유형으로 지정하여 컬렉션 에 문서가 삽입되거나 업데이트될 때마다voyage-4-large임베딩 모델을 사용하여description필드 에 대한 벡터 임베딩을 자동으로 생성하도록 MongoDB Vector Search에 지시합니다.title필드filter유형으로 지정하여 필드 의 문자열 값을 사용하여 시맨틱 검색 위한 데이터를 사전 필터링합니다. 이를 통해 사용자가 이미 읽은 기사를 검색 결과에서 제외할 수 있습니다.
{ "fields": [ { "type": "autoEmbed", "modalitytype": "text", "path": "description", "model": "voyage-4-large" }, { "type": "filter", "path": "title" } ] }
시맨틱 검색 쿼리를 실행하여 개인화된 추천을 제공 .
사용자가 사이트 방문하면 현재 세션의 요약을 가져와 기사 카탈로그에 대한 벡터 검색 위한 쿼리 로 사용합니다. 인덱스 에서 자동 임베딩을 활성화했기 때문에 MongoDB Vector Search는 쿼리 시 요약에 대한 임베딩을 자동으로 생성하고 이를 유효한 쿼리 벡터로 사용합니다.
이 예시 summary 세션을 쿼리 벡터로 사용하고 titles 필드 기반으로 사용자가 이미 읽은 문서를 제외하는 간소화된 벡터 검색 쿼리 보여 줍니다.
[{ "$vectorSearch": { "index": "vector_index", // Vector index with autoEmbed on article descriptions "path": "description", "query": { "text": "<session-summary>" // Session summary from user_intent document }, "numCandidates": 100, "filter": { "title": { "$nin": [<read-titles>] } // Exclude articles the array of titles in the user_intent document } } }]
주요 학습 사항
이 아키텍처는 최신 데이터 제품을 구축하는 데 있어 몇 가지 중요한 발전을 보여줍니다.
지연 시간 감소: 스트림 프로세서 내에 LLM 호출을 직접 포함하면 여러 네트워크 홉과 중간 지속성 계층이 제거됩니다. 시스템은 원시 클릭을 거의 실시간으로 실행 가능한 인텐트로 변환합니다.
향상된 개발자 환경: JSON 기반 MQL 로 파이프라인을 정의하여 이미 MongoDB 쿼리를 알고 있는 팀이 새로운 DSL을 배우거나 추가 인프라를 프로비저닝 하지 않고도 고급 스트리밍 및 AI 기반 워크로드를 빌드 할 수 있도록 합니다.
시맨틱 개인화: 키워드 매칭과 야간 배치 작업을 넘어 사용자 행동을 듣고 생각하고 응답하는 시스템을 빌드 .
작성자
VinodKrishnan, 솔루션스 아키텍트, MongoDB
자세히 알아보기
Atlas Vector Search 시맨틱 검색 강화하고 실시간 분석 가능하게 하는 방법을 알아보려면 Atlas Vector Search 페이지를 방문하세요.
MongoDB 미디어 운영을 어떻게 혁신하고 있는지 학습 AI 기반 미디어 개인화: MongoDB 및 벡터 검색 문서를 읽어보세요.
MongoDB 최신 미디어 워크플로를 지원하는 방법을 알아보려면 미디어 및 엔터테이먼트용 MongoDB 페이지를 방문하세요.
Atlas Stream Processing 에 대해 자세히 학습 Atlas Stream Processing 설명서를 참조하세요.