이 튜토리얼에서는 RAG 애플리케이션 평가하는 방법을 학습 . 평가를 통해 올바른 모델을 선택하고, 모델의 성능이프로토타입에서 프로덕션 환경으로 전환되는지 확인하고, 성능 회귀를 파악하는 데 도움이 됩니다.
구체적으로 다음 조치를 수행합니다.
환경을 설정합니다.
평가 데이터 세트를 다운로드합니다.
문서 청크 및 임베딩을 생성합니다.
임베딩을 Atlas에 삽입합니다.
검색을 위해 임베딩 모델을 비교합니다.
생성을 위한 완료 모델을 비교합니다.
전체 RAG 성능을 측정합니다.
MongoDB Charts 로 시간 경과에 따른 성능 추적.
참고
이 튜토리얼에서는 LLM 모델이 아닌 LLM 애플리케이션을 평가하는 데 중점을 둡니다. LLM 모델을 평가하려면 다양한 작업에서 특정 모델의 성능을 측정해야 합니다. LLM 애플리케이션 평가는 프롬프트 및 리트리버와 같은 LLM 애플리케이션 의 다양한 구성 요소와 시스템 전체를 평가하는 것입니다.
이 튜토리얼의 실행 가능한 버전을 Python 노트북으로 사용합니다.
배경
이 튜토리얼에서는 RAGAS 오픈 소스 평가 프레임워크 사용하여 다음 지표 로 RAG 성능을 측정합니다.
검색 지표: 컨텍스트 정밀도 및 컨텍스트 리콜은 리트리버가 관련 정보를 얼마나 잘 찾는지를 측정합니다.
생성 지표: 충실도 및 답변 관련성은 LLM이 정확하고 관련성 높은 응답을 얼마나 잘 생성하는지 측정합니다.
전체 지표: 답변 유사성 및 답변 정확성은 생성된 답변을 실제 실제와 비교합니다.
이러한 지표 에 대해 자세히 학습 RAGAS 문서에서 RAGAS 지표를 참조하세요.
이 튜토리얼에서는 Hugging Face의 ragas-wikiqa 데이터 세트를 사용하며, 여기에는 대략 개의 230 일반 지식 질문과 실제 진실 답변이 포함되어 있습니다.
전제 조건
이 튜토리얼을 완료하려면 다음 조건을 충족해야 합니다.
MongoDB 버전 이상 실행 MongoDB Atlas cluster 6.0.11 . IP 주소 가 프로젝트의 액세스 목록에 있는지 확인합니다.
OpenAI의 임베딩 및 채팅 완료 모델을 사용하기 위한 OpenAI API 키입니다.
다음으로 구성된 터미널입니다.
환경 설정
평가 데이터 세트 다운로드
Hugging Face에서 ragas-wikiqa 데이터 세트를 다운로드하여 pandas 데이터 프레임으로 변환합니다.
from datasets import load_dataset import pandas as pd data = load_dataset("explodinggradients/ragas-wikiqa", split="train") df = pd.DataFrame(data)
데이터 세트에는 다음과 같은 열이 포함되어 있습니다.
question: 사용자 질문correct_answer: 실제 진실 답변context: 질문에 답변 하는 참고 텍스트 목록
문서 청크 만들기
포함하기 전에 참조 텍스트를 작은 청크로 분할합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text by tokens using the tiktoken tokenizer text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( encoding_name="cl100k_base", keep_separator=False, chunk_size=200, chunk_overlap=30 ) def split_texts(texts): chunked_texts = [] for text in texts: chunks = text_splitter.create_documents([text]) chunked_texts.extend([chunk.page_content for chunk in chunks]) return chunked_texts # Split the context field into chunks df["chunks"] = df["context"].apply(lambda x: split_texts(x)) # Aggregate list of all chunks all_chunks = df["chunks"].tolist() docs = [item for chunk in all_chunks for item in chunk]
팁
검색을 평가할 때 다양한 청크 전략을 실험해 보세요. 이 튜토리얼은 임베딩 모델 평가에 중점을 둡니다.
임베딩 생성 및 MongoDB Charts 에 수집
청크 문서를 임베드하여 Atlas 에 수집합니다. 비교하려는 각 임베딩 모델에 대해 별도의 컬렉션을 만듭니다.
임베딩 함수 정의
OpenAI API 사용하여 임베딩을 생성하는 함수를 만듭니다.
from typing import List def get_embeddings(docs: List[str], model: str) -> List[List[float]]: """Generate embeddings using the OpenAI API.""" docs = [doc.replace("\n", " ") for doc in docs] response = openai_client.embeddings.create(input=docs, model=model) return [r.embedding for r in response.data]
Atlas 로 임베딩 수집
청크 문서를 Atlas 컬렉션에 임베드하고 수집합니다.
from pymongo import MongoClient from tqdm.auto import tqdm client = MongoClient(MONGODB_URI) DB_NAME = "ragas_evals" db = client[DB_NAME] batch_size = 128 EVAL_EMBEDDING_MODELS = ["text-embedding-ada-002", "text-embedding-3-small"] for model in EVAL_EMBEDDING_MODELS: embedded_docs = [] print(f"Getting embeddings for the {model} model") for i in tqdm(range(0, len(docs), batch_size)): end = min(len(docs), i + batch_size) batch = docs[i:end] batch_embeddings = get_embeddings(batch, model) batch_embedded_docs = [ {"text": batch[i], "embedding": batch_embeddings[i]} for i in range(len(batch)) ] embedded_docs.extend(batch_embedded_docs) collection = db[model] collection.delete_many({}) collection.insert_many(embedded_docs) print(f"Finished inserting embeddings for the {model} model")
벡터 검색 인덱스 만들기
각 컬렉션 에 대해 MongoDB Vector Search 인덱스 만듭니다. 인덱스 이름이 vector_index인 다음 인덱스 정의를 사용합니다.
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
인덱스 만드는 방법을 학습 MongoDB 벡터 검색 인덱스 만들기를 참조하세요.
팁
text-embedding-ada-002 와 text-embedding-3-small 모두 1536 차원을 가지므로 두 컬렉션 모두에 동일한 인덱스 정의가 적용됩니다.
임베딩 모델 비교
LLM에 적합한 컨텍스트를 조회 하려면 다양한 임베딩 모델을 비교하세요. 이 튜토리얼에서는 text-embedding-ada-002 와 를 text-embedding-3-small 비교합니다.
리트리버 함수 만들기
LangChain과 MongoDB Atlas 사용하여 벡터 저장 리트리버를 가져오는 함수를 만듭니다.
from langchain_openai import OpenAIEmbeddings from langchain_mongodb import MongoDBAtlasVectorSearch from langchain_core.vectorstores import VectorStoreRetriever def get_retriever(model: str, k: int) -> VectorStoreRetriever: """ Get a vector store retriever for a given embedding model. Args: model (str): Embedding model to use k (int): Number of results to retrieve Returns: VectorStoreRetriever: A vector store retriever object """ embeddings = OpenAIEmbeddings(model=model) vector_store = MongoDBAtlasVectorSearch.from_connection_string( connection_string=MONGODB_URI, namespace=f"{DB_NAME}.{model}", embedding=embeddings, index_name="vector_index", text_key="text", ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": k} ) return retriever
리트리버 평가
RAGAS 라이브러리의 context_precision 및 context_recall 지표 사용하여 각 임베딩 모델을 평가합니다.
from datasets import Dataset from ragas import evaluate, RunConfig from ragas.metrics import context_precision, context_recall import nest_asyncio # Allow nested use of asyncio (used by RAGAS) nest_asyncio.apply() for model in EVAL_EMBEDDING_MODELS: data = {"question": [], "ground_truth": [], "contexts": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH retriever = get_retriever(model, 2) # Get relevant documents for the evaluation dataset for i in tqdm(range(0, len(QUESTIONS))): data["contexts"].append( [doc.page_content for doc in retriever.invoke(QUESTIONS[i])] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[context_precision, context_recall], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
샘플 데이터 세트의 임베딩 모델에 대한 평가 결과는 다음과 같습니다.
모델 | 컨텍스트 정밀도 | 컨텍스트 리콜 |
|---|---|---|
text-embedding-ada-002 | 0.9310 | 0.8561 |
text-embedding-3-small | 0.9116 | 0.8826 |
이러한 결과를 기반으로 text-embedding-ada-002 는 가장 관련성이 높은 결과의 순위를 더 높게 지정하지만 text-embedding-3-small 는 실측 답변과 더 일치하는 컨텍스트를 검색합니다. 이 튜토리얼에서는 text-embedding-3-small 를 임베딩 모델로 사용합니다.
완료 모델 비교
이제 최상의 임베딩 모델을 선택했으므로 RAG 애플리케이션 의 생성 구성 요소에 대한 완료 모델을 비교합니다.
RAG 체인 생성
LangChain을 사용하여 RAG 체인을 빌드하는 함수를 만듭니다.
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.runnables.base import RunnableSequence from langchain_core.output_parsers import StrOutputParser def get_rag_chain(retriever: VectorStoreRetriever, model: str) -> RunnableSequence: """ Create a basic RAG chain. Args: retriever (VectorStoreRetriever): Vector store retriever object model (str): Chat completion model to use Returns: RunnableSequence: A RAG chain """ # Generate context using the retriever, and pass the user question through retrieve = { "context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough(), } template = """Answer the question based only on the following context: \ {context} Question: {question} """ # Define the chat prompt prompt = ChatPromptTemplate.from_template(template) # Define the model for chat completion llm = ChatOpenAI(temperature=0, model=model) # Parse output as a string parse_output = StrOutputParser() # RAG chain rag_chain = retrieve | prompt | llm | parse_output return rag_chain
완성 모델 평가
faithfulness 및 answer_relevancy 지표 사용하여 다양한 완료 모델을 평가합니다.
from ragas.metrics import faithfulness, answer_relevancy for model in ["gpt-3.5-turbo-1106", "gpt-3.5-turbo"]: data = {"question": [], "ground_truth": [], "contexts": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) rag_chain = get_rag_chain(retriever, model) for i in tqdm(range(0, len(QUESTIONS))): question = QUESTIONS[i] data["answer"].append(rag_chain.invoke(question)) data["contexts"].append( [doc.page_content for doc in retriever.invoke(question)] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
샘플 데이터 세트의 완료 모델에 대한 평가 결과는 다음과 같습니다.
모델 | 충실도 | 답변 관련성 |
|---|---|---|
gpt-3.5-터보 | 0.9714 | 0.9087 |
gpt-3.5-터보-1106 | 0.9671 | 0.9105 |
이러한 결과에 따르면 최신 gpt-3.5-turbo 버전은 더 사실적으로 일관적인 결과를 생성하는 반면, 이전 버전은 지정된 프롬프트와 더 관련된 답변을 생성합니다. 이 튜토리얼에서는 gpt-3.5-turbo 을 완료 모델로 사용합니다.
팁
지표 중 하나를 선택하고 싶지 않은 경우 가중치 합계를 사용하여 통합 지표 생성하거나 평가에 사용되는 프롬프트를 사용자 지정하는 것이 좋습니다.
전체 성능 측정
최고 성능 모델을 사용하여 RAG 애플리케이션 의 전체 성능을 평가합니다.
from ragas.metrics import answer_similarity, answer_correctness data = {"question": [], "ground_truth": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) # Use the best completion model from the generator evaluation rag_chain = get_rag_chain(retriever, "gpt-3.5-turbo") for question in tqdm(QUESTIONS): data["answer"].append(rag_chain.invoke(question)) dataset = Dataset.from_dict(data) run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[answer_similarity, answer_correctness], run_config=run_config, raise_exceptions=False, ) print(f"Overall metrics: {result}")
이 평가는 RAG 체인이 샘플 데이터 세트에서 의 답변 0.5922 0.8873 유사성과 의 답변 정확성을 생성한다는 것을 보여줍니다.
결과 분석
결과를 더 자세히 조사하려면 결과를 pandas 데이터 프레임으로 변환하고 점수가 낮은 답변을 필터하다 .
result_df = result.to_pandas() result_df[result_df["answer_correctness"] < 0.7]
시각적 분석을 위해 질문과 지표 의 히트맵을 만듭니다.
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) sns.heatmap( result_df[1:10].set_index("question")[["answer_similarity", "answer_correctness"]], annot=True, cmap="flare", ) plt.show()
앞의 코드는 다음과 같은 히트맵을 출력합니다.

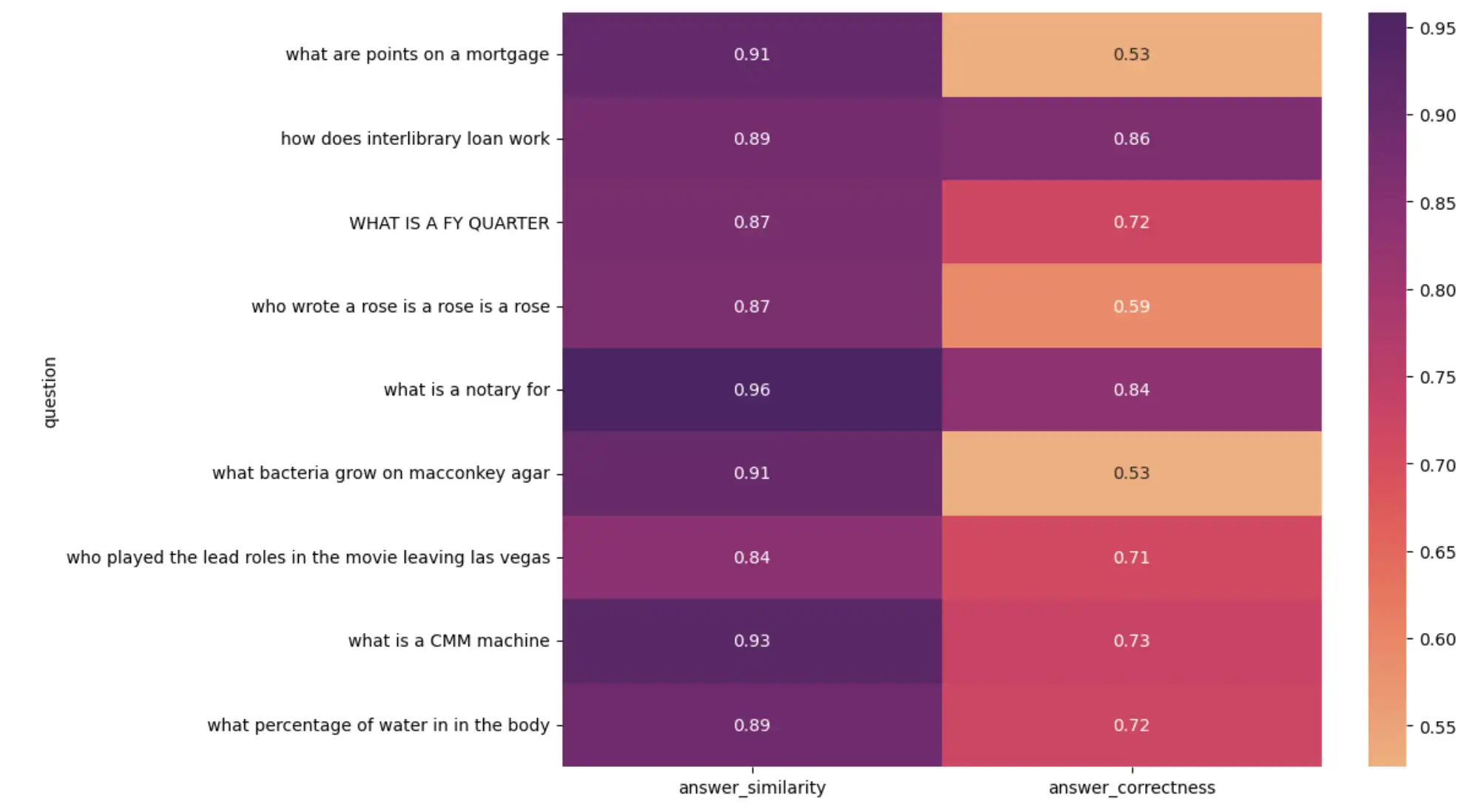
RAG 애플리케이션 성능을 시각화하는 히트맵
점수가 낮은 결과를 조사한 결과 다음과 같은 결과를 찾을 수 있습니다.
평가 데이터 세트의 일부 실제 답변이 잘못되었습니다.LLM에서생성된 답변 정확하지만 실제 실측과 일치하지 않으므로 점수가 낮습니다.
일부 실제 답변은 전체 문장인 반면,LLM에서생성된 답변 단일 단어 또는 숫자입니다.
이러한 결과는 LLM 평가를 즉시 확인하고 정확한 평가 데이터 세트를 선별하는 것이 중요하다는 것을 강조합니다.
시간 경과에 따른 성능 추적
평가는 일회성 이벤트 되어서는 안 됩니다. 시스템의 구성 요소를 변경할 때마다 변경 사항을 평가하여 성능에 영향 평가합니다. 애플리케이션 이 프로덕션 환경에 들어가면 실시간 성능을 모니터 하고 변경 사항을 감지합니다.
Charts 사용하여 LLM 애플리케이션 의 성능을 모니터 . 추적 하려는 평가 결과와 피드백 지표 Atlas 컬렉션 에 씁니다.
from datetime import datetime result["timestamp"] = datetime.now() collection = db["metrics"] collection.insert_one(result)
이 코드는 평가 결과에 timestamp 필드 추가하고 이를 ragas_evals 데이터베이스 의 metrics 컬렉션 에 씁니다. Atlas 의 문서 는 다음과 같습니다.
{ "answer_similarity": 0.8873, "answer_correctness": 0.5922, "timestamp": "2024-04-07T23:27:30.655+00:00" }
MongoDB Charts 에서 대시보드 만들어 시간 경과에 따른 지표 시각화합니다. 차트 및 대시보드를 만드는 방법을 학습 Charts 빌드를 참조하세요.
요약
이 튜토리얼에서는 RAGAS 프레임워크 와 MongoDB Atlas 사용하여 RAG 애플리케이션 평가하는 방법을 학습했습니다. 검색을 위한 임베딩 모델과 생성을 위한 완료 모델을 비교하고, 애플리케이션 의 전체 성능을 측정했습니다. 또한 MongoDB Charts 사용하여 시간 경과에 따른 성능을 추적 방법도 학습했습니다.
MongoDB 사용하여 RAG 애플리케이션을 빌드하는 방법에 대해 자세히 학습 다음 리소스를 참조하세요.