このガイドでは、Voyage AIモデルを使用してセマンティック検索を実行する方法について説明します。このページには、再ランク付けによる検索、多言語、マルチモーダル、コンテキスト付きチャンク、大規模なコーパス検索など、基本的および高度なセマンティック検索のユースケースの例が含まれています。
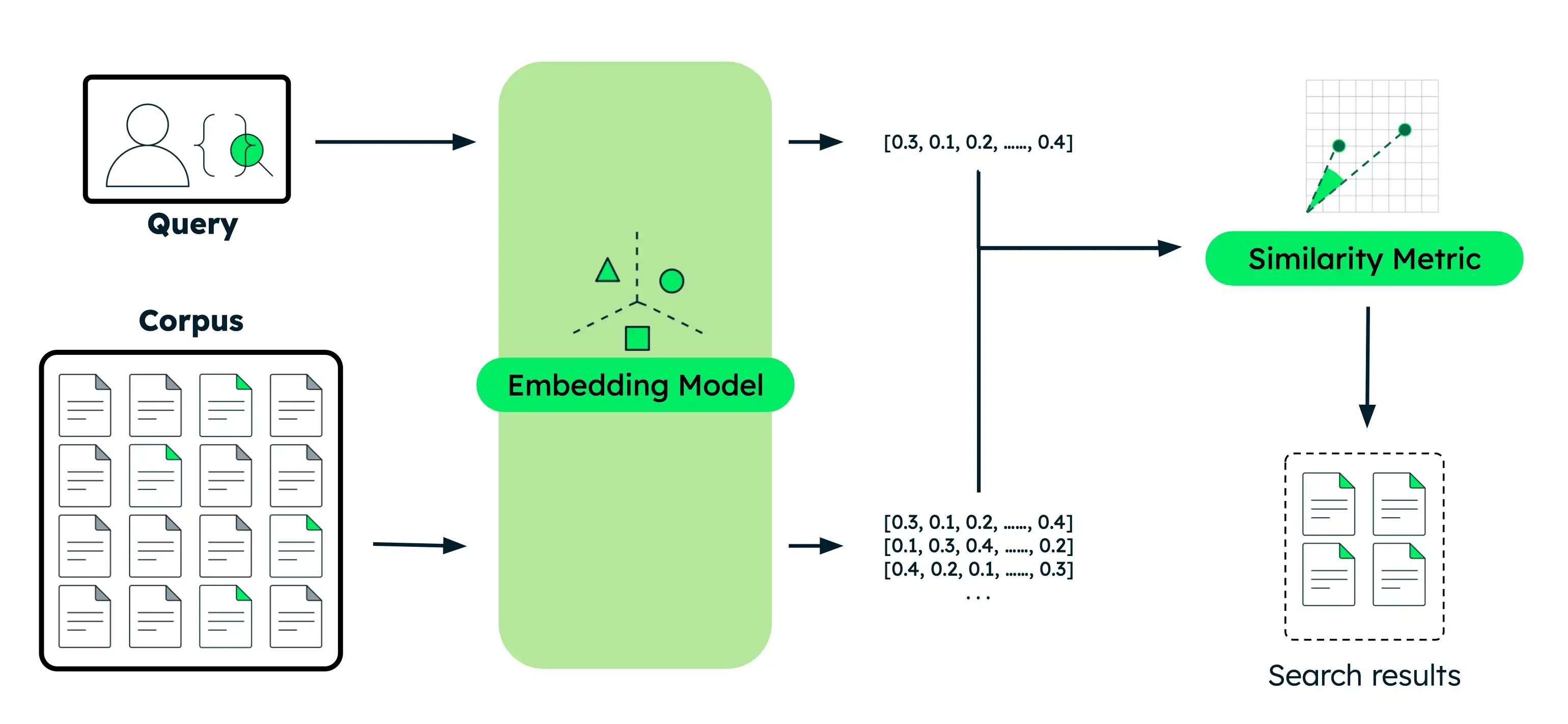
セマンティック検索の実行
このセクションでは、さまざまな Voyage AIモデルを使用したさまざまなセマンティック検索のユースケースのコード例を示します。各 の例に対して、同じ基本手順を実行します。
ドキュメントを埋め込み: データをその意味をキャプチャするベクトル埋め込みに変換します。こうしたデータは、テキスト、画像、ドキュメントチャンク、またはテキストの大規模なコレクションにすることができます。
クエリを埋め込む:検索クエリーをドキュメントと同じベクトル表現に変換します。
類似したドキュメントを検索します: クエリベクトルとドキュメントベクトルを比較して、最もセマンティックに類似した結果を識別します。
このチュートリアルの実行可能なバージョンをPythonノートとして操作します。
環境を設定します。
始める前に、プロジェクトディレクトリを作成し、ライブラリをインストールし、モデルAPIキーを設定します。
ターミナルで次のコマンドを実行して、このチュートリアル用の新しいディレクトリを作成し、必要なライブラリをインストールします。
mkdir voyage-semantic-search cd voyage-semantic-search pip install --upgrade voyageai numpy datasets モデルAPIキーをまだ作成していない場合は、手順に従って、モデル API キーを作成し、ターミナルで次のコマンドを実行して環境変数としてエクスポートします。
export VOYAGE_API_KEY="your-model-api-key"
セマンティック検索クエリを実行します。
セマンティック検索の各タイプのコード例については、各セクションを展開してください。
プロジェクトに
semantic_search_basic.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort documents by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices, 1): print(f"{rank}. {documents[idx]}") print(f" Similarity: {similarities[idx]:.4f}\n")
ターミナルで次のコマンドを実行します。
python semantic_search_basic.py
Query: 'When is Apple's conference call scheduled?' 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity: 0.2335 4. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Similarity: 0.1955 5. Photosynthesis in plants converts light energy into glucose and produces essential oxygen. Similarity: 0.1881 6. Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems. Similarity: 0.1601
プロジェクトに
semantic_search_reranker.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results before reranking print(f"Query: '{query}'\n") print("Before reranker (embedding similarity only):") for rank, idx in enumerate(ranked_indices[:3], 1): print(f"{rank}. {documents[idx]}") print(f" Similarity Score: {similarities[idx]:.4f}\n") # Rerank documents for improved accuracy rerank_results = vo.rerank( query=query, documents=documents, model="rerank-2.5" ) # Display results after reranking print("\nAfter reranker:") for rank, result in enumerate(rerank_results.results[:3], 1): print(f"{rank}. {documents[result.index]}") print(f" Relevance Score: {result.relevance_score:.4f}\n")
ターミナルで次のコマンドを実行します。
python semantic_search_reranker.py
Query: 'When is Apple's conference call scheduled?' Before reranker (embedding similarity only): 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity Score: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity Score: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity Score: 0.2335 After reranker: 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Relevance Score: 0.9453 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Relevance Score: 0.2832 3. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Relevance Score: 0.2637
プロジェクトに
semantic_search_multilingual.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # English documents about technology companies english_docs = [ "Apple announced record-breaking revenue in its latest quarterly earnings report.", "The Mediterranean diet emphasizes fish, olive oil, and vegetables.", "Microsoft is investing heavily in artificial intelligence and cloud computing.", "Shakespeare's plays continue to influence modern literature and theater." ] # Spanish documents about technology companies spanish_docs = [ "Apple anunció ingresos récord en su último informe trimestral de ganancias.", "La dieta mediterránea enfatiza el pescado, el aceite de oliva y las verduras.", "Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube.", "Las obras de Shakespeare continúan influenciando la literatura y el teatro modernos." ] # Chinese documents about technology companies chinese_docs = [ "苹果公司在最新季度财报中宣布创纪录的收入。", "地中海饮食强调鱼类、橄榄油和蔬菜。", "微软正在大力投资人工智能和云计算。", "莎士比亚的作品继续影响现代文学和戏剧。" ] # Perform semantic search in English english_query = "tech company earnings" # Generate embeddings for English documents english_embeddings = vo.embed( texts=english_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for English query english_query_embedding = vo.embed( texts=[english_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product english_similarities = np.dot(english_embeddings, english_query_embedding) # Sort by similarity (highest to lowest) english_ranked = np.argsort(-english_similarities) print(f"English Query: '{english_query}'\n") for rank, idx in enumerate(english_ranked[:2], 1): print(f"{rank}. {english_docs[idx]}") print(f" Similarity: {english_similarities[idx]:.4f}\n") # Perform semantic search in Spanish spanish_query = "ganancias de empresas tecnológicas" # Generate embeddings for Spanish documents spanish_embeddings = vo.embed( texts=spanish_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Spanish query spanish_query_embedding = vo.embed( texts=[spanish_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product spanish_similarities = np.dot(spanish_embeddings, spanish_query_embedding) # Sort by similarity (highest to lowest) spanish_ranked = np.argsort(-spanish_similarities) print(f"Spanish Query: '{spanish_query}'\n") for rank, idx in enumerate(spanish_ranked[:2], 1): print(f"{rank}. {spanish_docs[idx]}") print(f" Similarity: {spanish_similarities[idx]:.4f}\n") # Perform semantic search in Chinese chinese_query = "科技公司收益" # Generate embeddings for Chinese documents chinese_embeddings = vo.embed( texts=chinese_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Chinese query chinese_query_embedding = vo.embed( texts=[chinese_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product chinese_similarities = np.dot(chinese_embeddings, chinese_query_embedding) # Sort by similarity (highest to lowest) chinese_ranked = np.argsort(-chinese_similarities) print(f"Chinese Query: '{chinese_query}'\n") for rank, idx in enumerate(chinese_ranked[:2], 1): print(f"{rank}. {chinese_docs[idx]}") print(f" Similarity: {chinese_similarities[idx]:.4f}\n")
ターミナルで次のコマンドを実行します。
python semantic_search_multilingual.py
English Query: 'tech company earnings' 1. Apple announced record-breaking revenue in its latest quarterly earnings report. Similarity: 0.5172 2. Microsoft is investing heavily in artificial intelligence and cloud computing. Similarity: 0.4745 Spanish Query: 'ganancias de empresas tecnológicas' 1. Apple anunció ingresos récord en su último informe trimestral de ganancias. Similarity: 0.5232 2. Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube. Similarity: 0.4871 Chinese Query: '科技公司收益' 1. 苹果公司在最新季度财报中宣布创纪录的收入。 Similarity: 0.4725 2. 微软正在大力投资人工智能和云计算。 Similarity: 0.4426
サンプルイメージを検索し、プロジェクトディレクトリに保存します。次のコード例では、犬、犬、猫のイメージがあることを前提としています。
プロジェクトに
semantic_search_multimodal.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np from PIL import Image # Initialize Voyage AI client vo = voyageai.Client() # Prepare interleaved text + image inputs interleaved_inputs = [ ["An orange cat", Image.open('cat.jpg')], ["A golden retriever", Image.open('dog.jpg')], ["A banana", Image.open('banana.jpg')], ] # Prepare image-only inputs image_only_inputs = [ [Image.open('cat.jpg')], [Image.open('dog.jpg')], [Image.open('banana.jpg')], ] # Labels for display labels = ["cat.jpg", "dog.jpg", "banana.jpg"] # Search query query = "a cute pet" # Generate embeddings for interleaved text + image inputs interleaved_embeddings = vo.multimodal_embed( inputs=interleaved_inputs, model="voyage-multimodal-3.5" ).embeddings # Generate embedding for query query_embedding = vo.multimodal_embed( inputs=[[query]], model="voyage-multimodal-3.5" ).embeddings[0] # Calculate similarity scores using dot product interleaved_similarities = np.dot(interleaved_embeddings, query_embedding) # Sort by similarity (highest to lowest) interleaved_ranked = np.argsort(-interleaved_similarities) print(f"Query: '{query}'\n") print("Search with interleaved text + image:") for rank, idx in enumerate(interleaved_ranked, 1): print(f"{rank}. {interleaved_inputs[idx][0]}") print(f" Similarity: {interleaved_similarities[idx]:.4f}\n") # Generate embeddings for image-only inputs image_only_embeddings = vo.multimodal_embed( inputs=image_only_inputs, model="voyage-multimodal-3.5" ).embeddings # Calculate similarity scores using dot product image_only_similarities = np.dot(image_only_embeddings, query_embedding) # Sort by similarity (highest to lowest) image_only_ranked = np.argsort(-image_only_similarities) print("\nSearch with image-only:") for rank, idx in enumerate(image_only_ranked, 1): print(f"{rank}. {labels[idx]}") print(f" Similarity: {image_only_similarities[idx]:.4f}\n")
ターミナルで次のコマンドを実行します。
python semantic_search_multimodal.py
Query: 'a cute pet' Search with interleaved text + image: 1. An orange cat Similarity: 0.2685 2. A golden retriever Similarity: 0.2325 3. A banana Similarity: 0.1564 Search with image-only: 1. dog.jpg Similarity: 0.2485 2. cat.jpg Similarity: 0.2438 3. banana.jpg Similarity: 0.1210
プロジェクトに
semantic_search_contextualized.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents (each document is a list of chunks that share context) documents = [ [ "This is the SEC filing on Greenery Corp.'s Q2 2024 performance.", "The company's revenue increased by 7% compared to the previous quarter." ], [ "This is the SEC filing on Leafy Inc.'s Q2 2024 performance.", "The company's revenue increased by 15% compared to the previous quarter." ], [ "This is the SEC filing on Elephant Ltd.'s Q2 2024 performance.", "The company's revenue decreased by 2% compared to the previous quarter." ] ] # Search query query = "What was the revenue growth for Leafy Inc. in Q2 2024?" # Generate contextualized embeddings (preserves relationships between chunks) contextualized_result = vo.contextualized_embed( inputs=documents, model="voyage-context-3", input_type="document" ) # Flatten the embeddings and chunks for semantic search contextualized_embeddings = [] all_chunks = [] chunk_to_doc = [] # Maps chunk index to document index for doc_idx, result in enumerate(contextualized_result.results): for emb, chunk in zip(result.embeddings, documents[doc_idx]): contextualized_embeddings.append(emb) all_chunks.append(chunk) chunk_to_doc.append(doc_idx) # Generate contextualized query embedding query_embedding_ctx = vo.contextualized_embed( inputs=[[query]], model="voyage-context-3", input_type="query" ).results[0].embeddings[0] # Calculate similarity scores using dot product similarities_ctx = np.dot(contextualized_embeddings, query_embedding_ctx) # Sort by similarity (highest to lowest) ranked_indices_ctx = np.argsort(-similarities_ctx) # Display top 3 results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices_ctx[:3], 1): doc_idx = chunk_to_doc[idx] print(f"{rank}. {all_chunks[idx]}") print(f" (From document: {documents[doc_idx][0]})") print(f" Similarity: {similarities_ctx[idx]:.4f}\n")
ターミナルで次のコマンドを実行します。
python semantic_search_contextualized.py
Query: 'What was the revenue growth for Leafy Inc. in Q2 2024?' 1. The company's revenue increased by 15% compared to the previous quarter. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.7138 2. This is the SEC filing on Leafy Inc.'s Q2 2024 performance. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.6630 3. The company's revenue increased by 7% compared to the previous quarter. (From document: This is the SEC filing on Greenery Corp.'s Q2 2024 performance.) Similarity: 0.5531
プロジェクトに
semantic_search_large_corpus.pyという名前のファイルを作成し、次のコードをそのファイルに貼り付けます。
import voyageai import numpy as np from datasets import load_dataset from collections import defaultdict # Initialize Voyage AI client vo = voyageai.Client() # Load legal benchmark dataset corpus_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "corpus")["corpus"] queries_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "queries")["queries"] qrels_ds = load_dataset("mteb/legalbench_consumer_contracts_qa")["test"] # Extract corpus and query data corpus_ids = [row["_id"] for row in corpus_ds] corpus_texts = [row["text"] for row in corpus_ds] query_ids = [row["_id"] for row in queries_ds] query_texts = [row["text"] for row in queries_ds] # Build relevance mapping (defaultdict creates sets for missing keys) qrels = defaultdict(set) for row in qrels_ds: if row["score"] > 0: qrels[row["query-id"]].add(row["corpus-id"]) # Generate embeddings for the entire corpus print(f"Generating embeddings for {len(corpus_texts)} documents...") corpus_embeddings = vo.embed( texts=corpus_texts, model="voyage-4-large", input_type="document" ).embeddings # Select a sample query query_idx = 1 query = query_texts[query_idx] query_id = query_ids[query_idx] # Generate embedding for the query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(corpus_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display top 5 results print(f"Query: {query}\n") print("Top 5 Results:") for rank, idx in enumerate(ranked_indices[:5], 1): doc_id = corpus_ids[idx] is_relevant = "✓" if doc_id in qrels[query_id] else "✗" print(f"{rank}. [{is_relevant}] Document ID: {doc_id}") print(f" Similarity: {similarities[idx]:.4f}") print(f" Text: {corpus_texts[idx][:100]}...\n") # Show the ground truth most relevant document most_relevant_id = list(qrels[query_id])[0] most_relevant_idx = corpus_ids.index(most_relevant_id) print(f"Ground truth most relevant document:") print(f"Document ID: {most_relevant_id}") print(f"Rank in results: {np.where(ranked_indices == most_relevant_idx)[0][0] + 1}") print(f"Similarity: {similarities[most_relevant_idx]:.4f}")
ターミナルで次のコマンドを実行します。
python semantic_search_large_corpus.py
Generating embeddings for 154 documents... Query: Will Google come to a users assistance in the event of an alleged violation of such users IP rights? Top 5 Results: 1. [✓] Document ID: 9NIQ0Wobtq Similarity: 0.6047 Text: Your content Some of our services give you the opportunity to make your content publicly available ... 2. [✗] Document ID: gAk7Gdp0CX Similarity: 0.5515 Text: Taking action in case of problems Before taking action as described below, well provide you with adv... 3. [✗] Document ID: S87XwXaHCP Similarity: 0.5178 Text: Privacy and Data Protection Our Privacy Center explains how we treat your personal data. By using th... 4. [✗] Document ID: 8IRh1E2JDB Similarity: 0.5134 Text: OUR PROPERTY The Service is protected by copyright, trademark, and other US and foreign laws. These ... 5. [✗] Document ID: 50OXirZRiR Similarity: 0.5098 Text: Uploading Content If you have a YouTube channel, you may be able to upload Content to the Service. Y... Ground truth most relevant document: Document ID: 9NIQ0Wobtq Rank in results: 1 Similarity: 0.6047
例について
次の表は、このページの例をまとめたものです。
例 | 使用されるモデル | 結果の理解 |
|---|---|---|
基本セマンティック検索 |
| Apple テレカン のドキュメント は1 番目の にランクされ、無関係なドキュメントよりも大幅に高く、正確なセマンティック一致を示しています。 |
Reranker によるセマンティック検索 |
| 再ランク付けにより、 クエリとドキュメントの完全な関係を分析し、検索の精度が向上します。類似性を埋め込むだけでは、正しいドキュメントが中程度のスコアで最初にランク付けされますが、reranker は関連性スコアを大幅に引き上げ、関連性のない結果との区別を向上させます。 |
多言語セマンティック検索 |
| Voyageモデルは、さまざまな言語にわたってセマンティック検索を効果的に実行します。この例では、英語、スペイン語、中国語の 3 つの個別の検索が示されており、それぞれの言語内でテクノロジー会社の売上に最も関連するドキュメントを正しく識別しています。 |
マルチモーダル セマンティック検索 |
| このモデルは、テキスト、画像、ビデオのインターリーブ、およびイメージのみとビデオのみの検索をサポートしています。どちらの場合も、犬と猫のイメージは、無関係なバナーのイメージよりも大幅に高く、視覚的コンテンツが正確に取得されていることが示されます。説明的なテキストを含むインターリーブ入力では、画像のみの入力よりもわずかに高い類似性スコアが生成されます。 |
コンテキストに基づくチャンク埋め込み |
| 15% の収益増加チャンクは、 Leafy Inc.ドキュメントにリンクされているため、1 番目にランク付けされます。Green グループの同様の 7% 増加チャンクのスコアは低く、モデルがドキュメントのコンテキストを正確に考慮して、類似したチャンクとを区別する方法を示しています。 |
大規模なコレクションを使用したセマンティック検索 |
| ユーザー コンテンツに関する真実のドキュメントは、 154 ドキュメントの中で 1 番目にランク付けされ、セマンティックな複雑さにもかかわらず増やす効果的な取得が行われます。 |
- 埋め込みへのアクセス
例ではPythonクライアントである
voyageai.Client()が使用されます。これは、VOYAGE_API_KEY環境変数からAPIキーを自動的に読み取ります。API は応答オブジェクトを返します。実際の埋め込みベクトルにアクセスするには、.embeddings属性を使用します。result = vo.embed(texts=["example"], model="voyage-4-large", input_type="document") embeddings = result.embeddings # List of embedding vectors - 類似性の計算
これらの例では、Numpy のドット積関数(
np.dot())を使用して、クエリとドキュメント埋め込み間の類似性スコアを計算します。Voyage AI埋め込みは長さ 1 に正規化されているため、ドット積はコサイン類似度と数学的に同等です。結果を類似性でランク付けするために、例では Numpy の
argsort()関数を使用して上位 N の結果を表示します。負の記号は降順でソートされるため、最も類似性の高いスコアが最初に表示されます。- 入力型パラメーター
- Voyage AIモデルによるベクトルの作成方法を最適化するには、
input_typeパラメーターをqueryまたはdocumentに設定します。このパラメーターを省略しないでください。詳細については、「入力タイプの指定」を参照してください。
詳細については、Voyage AIモデルへのアクセスを参照するか、完全なAPI仕様を調べてください。
セマンティック検索とは
セマンティック検索とは、データのセマンティックまたは基礎の意味に基づいて結果を返す検索メソッドです。テキスト一致を検索する従来の全文検索とは異なり、セマンティック検索は多次元空間内の検索クエリーに近いベクトルを検索します。ベクトルがクエリに近づくほど、それらの意味は大きくなります。
例
従来のテキスト検索では完全一致のみが返されるため、データ内のタームとは異なるタームでユーザーが検索する場合に結果が制限されていました。例、データにコンピューター マウスとワイルドマウスに関するドキュメントが含まれている場合、コンピューター マウスに関する情報を検索しようとしているときに「mous」を検索すると、誤った一致が発生します。
ただし、セマンティック検索では、レプリカセットに重複がない場合でも、単語またはフレーズ間の基礎となる関係がキャプチャされます。コンピューター製品を探しているときに「mouse」を検索すると、より関連性の高い結果が得られます。これは、正確な検索タームに関係なく、セマンティック検索では検索クエリのセマンティック意味をデータと比較して、最も関連性の高い結果のみが返されるためです。

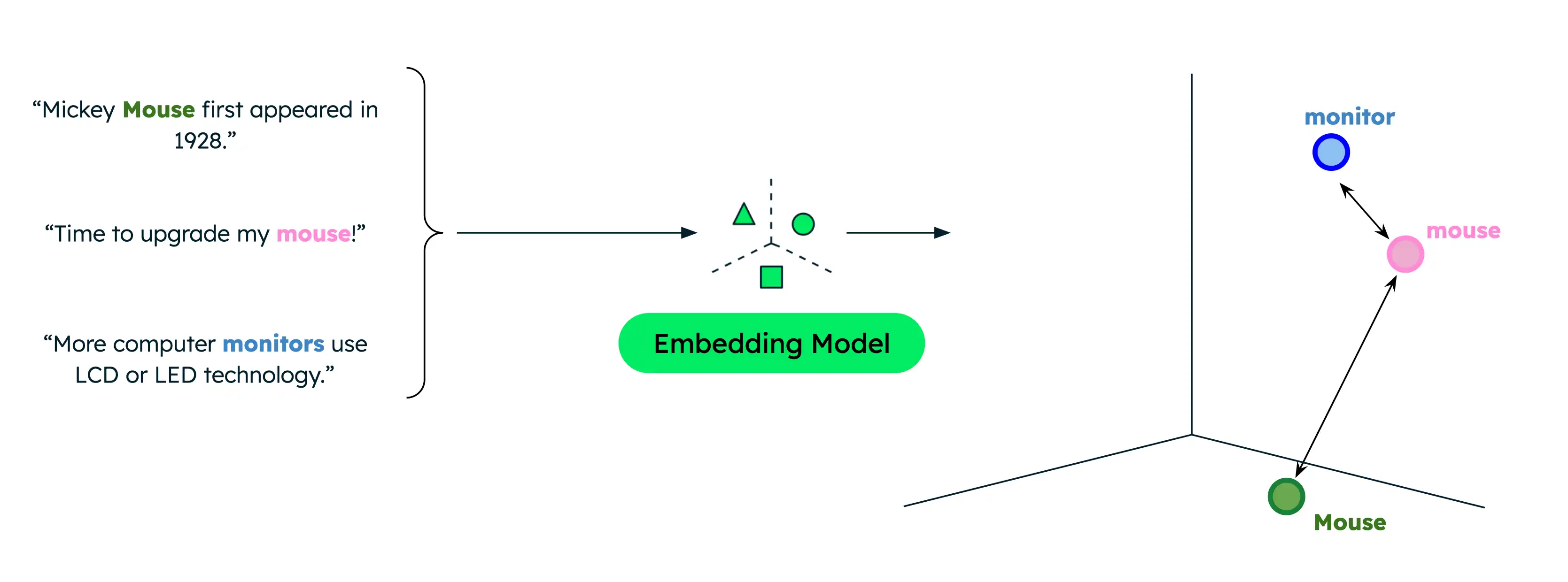
類似性関数は、2 つのベクトルが互いにどのように近いか、およびそれらがどの程度類似しているかを測定します。一般的な関数には、ドット積、コサイン類似度、ユークリッド距離などがあります。Voyage AI埋め込みは長さ 1 に正規化されています。つまり、次のことを意味します。
コサイン類似度はドット積類似度と同じですが、後者はより迅速に計算できます。
コサイン類似度とユークリッド距離の結果は同一のランキングになります。
本番環境のセマンティック検索
ベクトルをメモリに保存し、独自の検索パイプラインを実装することはプロトタイプ作成や実験に適していますが、実稼働アプリケーションではベクトルデータベースとエンタープライズ検索ソリューションを使用すると、より大きなコレクションから効率的な取得を実行できます。
MongoDB はベクトルストレージと検索のネイティブ サポートを備えているため、他のデータと並行してベクトル埋め込みを保存および検索するのに便利です。MongoDB Vector Search を使用してセマンティック検索を実行するチュートリアルを完了するには、「 Atlas クラスターのデータに対してセマンティック検索を実行する方法 」を参照してください。
次のステップ
セマンティック検索と LLM を組み合わせて、RAGアプリケーション を実装します。