MongoDB Atlas と Google Cloud のツール群を活用し、リアルタイムで音声操作が可能な車内体験をどのように構築するかを学ぶことができます。車両データ、ユーザー コンテキスト、自動車マニュアルの埋め込み情報を組み合わせることで、ドライバーのニーズに適応可能な、スマートかつスケーラブルな車内アシスタントを構築します。
業種: 製造 & モビリティ
製品: MongoDB Atlas、MongoDB Atlas Vector Search
パートナー: Google Cloud Platform、PowerSync
ソリューション概要
自動車会社は、インテリジェントでユーザーに適したデジタル システムで車両を区別するための負荷が増大しています。ドライブでの言語の役割はありますが、ほとんどの場合、ナビゲーションやロックを制御するなどの基本的なコマンドに限定されます。生成系AI を使用すると、ドライバーはこれらの制限を超え、パーソナライズされた動的なインタラクションを提供できます。
このソリューションでは、生成AIとMongoDB Atlasを基盤としたリアルタイム音声アシスタントをビルドする方法を示します。このアーキテクチャでは、データベース テレメトリ、ユーザーのプレファレンス、マニュアルを統合して、各ドライバーのニーズに適したデータベース ヘルパーを作成しています。MongoDB Atlas の柔軟なドキュメントモデルと組み込みのベクトル検索 を使用することで、開発者はデータの複雑さを効率化し、機能をより速く提供し、自動車内のエクスペリエンスを向上させることができます。
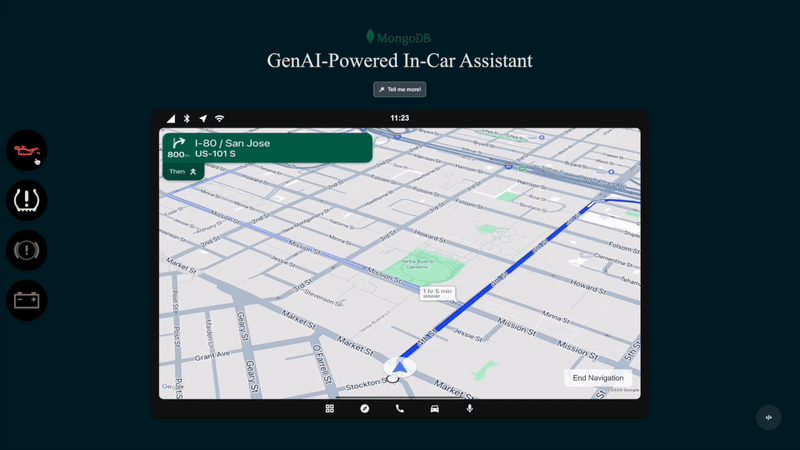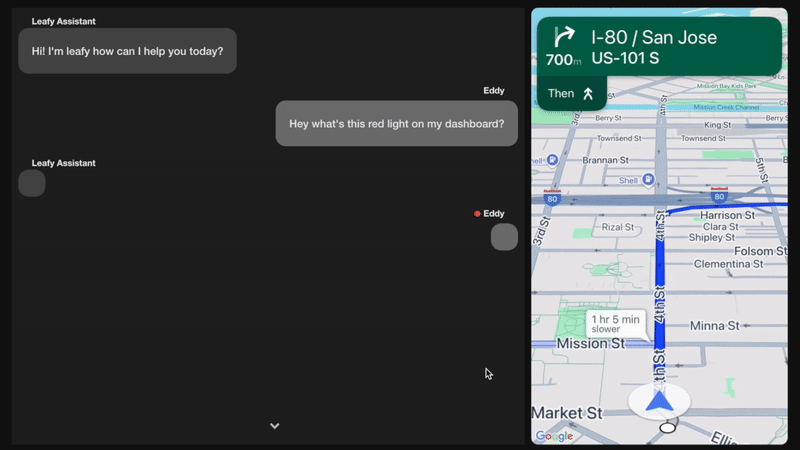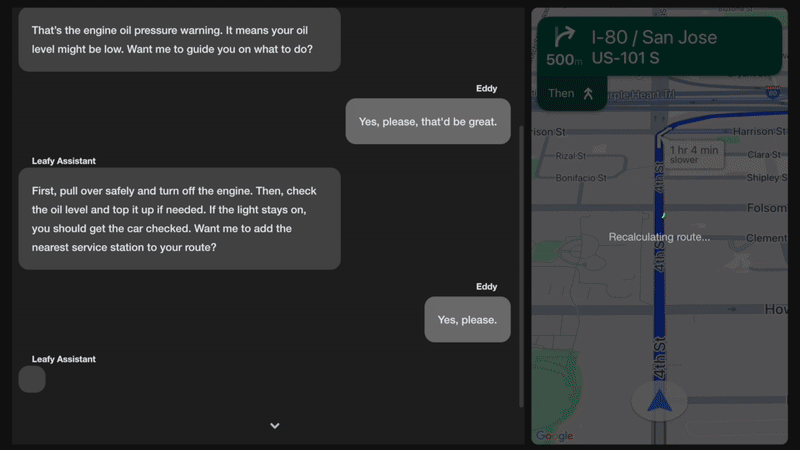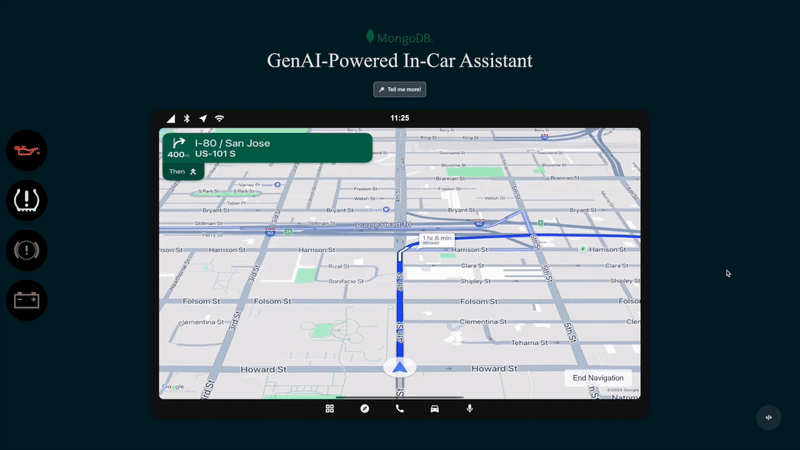
図 1. 車載生成系AI アシスタントのアクション
このソリューションを使用すると、次のことが可能になります。
構造化データと非構造化データを統合して、AI システムのコンテキストを強化します。
スケーラブルなクラウドネイティブ アーキテクチャにより、リアルタイムのインタラクションを可能にします。
Atlas Vector Search を活用したセマンティック検索でパーソナライズされたエクスペリエンスを提供します。
このソリューションは自動車業界に焦点を当てていますが、輸送、医療、ホスピタリティ、家電製品では 、カスタマーエンゲージメントを向上させ、摩擦を減らし、サポートを効率化するために適用できます。このアーキテクチャは、スマート ホーム 支援、デジタルコンフィギュレーション、 AI対応のメトリクス トリガー システムなど、音声転送でデータに基づくエクスペリエンスの基礎を提供します。さまざまな業種の企業が、ユーザーエクスペリエンスを変革するために、生成系AIとMongoDBを活用した音声の力を活用しています。
参照アーキテクチャ
このアーキテクチャでは、 MongoDB Atlas をデータレイヤーとして使用するとともに、Google Cloud のAI機能を使用して、高速でパーソナライズされた信頼性の高いインタラクションを確保します。

図 2。生成系 AI を活用した車内アシスタントのリファレンス アーキテクチャ
このソリューションは、 とクラウドでホストされているコンポーネントを使用します。
オンボードコンポーネント
これらは車両内でドライバーの近くで実行され、リアルタイムの音声対話を可能にします。
カーコンソール: ユーザーが支援者に問い合わせて応答を受け取る、自動車内のインターフェースです。このデモでは、実際の自動車に埋め込まれたシステムを表す Webアプリケーションを使用します。
ローカル データ ストレージ: 車両は、SQLite を基盤とした軽量エッジ データベースである PowerSync SDK を使用して、重要な信号をローカルに保存します。これにより、診断データへの迅速なアクセスが確保され、データが MongoDB Atlas と同期された状態が維持されます。
支援バックエンド: このコンポーネントは対話を管理します。Google Cloud Sink-to-Text を使用して、発音区別符号を取り扱います。クエリに応じて、直接応答するか、より多くのデータを取得するためのツールを呼び出すか、アクション を実行するためにツールを呼び出します。このデモには、次の 4 つのサンプルアクションが含まれています。
マニュアルを参照: Atlas ベクトル検索を使用して、自動車マニュアルから関連情報を取得します。
診断の実行: ローカルの車両データから現在の診断コードを取得します。
ルートを再計算: ドライバーが停車を追加すると、トリップが調整されます。
チャットを終了: 会話を円滑に終了します。
このソリューションでは、次のオブジェクトを使用して、 支援バックエンドのツールを定義します。ソリューションは、チャット機能を開始するときにオブジェクトを Google Cloud に渡します。
const functionDeclarations = [ { functionDeclarations: [ { name: "closeChat", description: "Closes the chat window when the conversation is finished. By default it always returns to the navigation view. Ask the user to confirm this action before executing.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: { view: { type: FunctionDeclarationSchemaType.STRING, enum: ["navigation"], description: "The next view to display after closing the chat.", }, }, required: ["view"], }, }, { name: "recalculateRoute", description: "Recalculates the route when a new stop is added. By default this function will find the nearest service station. Ask the user to confirm this action before executing.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: {}, }, }, { name: "consultManual", description: "Retrieves relevant information from the car manual.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: { query: { type: FunctionDeclarationSchemaType.STRING, description: "A question that represents an enriched version of what the user wants to retrieve from the manual. It must be in the form of a question.", }, }, required: ["query"], }, }, { name: "runDiagnostic", description: "Fetches active Diagnostic Trouble Codes (DTCs) in the format OBD II (SAE-J2012DA_201812) from the vehicle to assist with troubleshooting.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: {}, }, }, ], }, ];
クラウドコンポーネント
これらのコンポーネントは Google Cloud またはMongoDB Atlasに保存され、 AIインテリジェンス、 スケーラブルストレージ、データ処理機能を提供します。
データ取り込み: 自動車のマニュアルのような非構造化コンテンツが Google Cloud Storageにアップロードされます。これにより、Pub/Sub、Cloud Run、Document AI を使用してパイプラインがトリガーされ、PDF がチャンクに分割されます。Vertex AI はこれらのチャンクの埋め込みを生成し、その後セマンティック検索のために MongoDB Atlas に保存します。
言語 API の処理: Google Cloud の Text-to-Spark と STOP-to-Text は、自然な言語インタラクションを処理します。Vertex AI は、検索クエリ用のテキスト埋め込みを提供し、ヘルパーが使用する LLM である Geomi を強化します。
データの保存と取得: MongoDB Atlas は以下を保存します。
Atlas Vector Search を用いた検索のためのマニュアルチャンク埋め込み。
ユーザー設定とセッション データ。
車両信号—最新の値と完全な時系列テレメトリの両方。
Atlas Vector Search は、ユーザーの質問を最も関連するマニュアル セクションと照合するために使用され、検索拡張生成(RAG)フローを有効にします。MongoDB では、構造化データ、半構造化データ、ベクトルデータを1つの場所でネイティブにサポートしているため、支援ロジックが簡素化され、開発が迅速化します。
データ同期: このソリューションは PowerSync を使用して、自動車とクラウド間の双方向同期を行います。
車両からクラウドへ: 車両は診断コード、速度、加速度などのテレメトリデータを送信します。クラウドの実行関数はこれを処理し、Atlas に保存します。
クラウドから車両へ: OTA 更新やリモート ロックなど、車両に対して遠隔で送信される更新や操作を有効にします。
変換AIのMongoDB
MongoDB Atlas は、このソリューション アーキテクチャを次のように改善します。
運用データとベクトルデータを統合: 車両、ベクトル埋め込み、ユーザー セッションは 1 つのプラットフォームにまとめて保存されます。
より関連性の高い応答を有効にします: Atlas Vector Search は、大きなドキュメントから適切なチャンクを即座に検索し、正確でコンテキストに応じた応答を実現します。
エンタープライズ規模向けに構築: 1 つのモデルでも、グローバルなフリートでも、MongoDB Atlas は組み込みの水平スケーラビリティ、高可用性、エンタープライズグレードのセキュリティを提供します。
エッジとクラウドの同期を簡素化: PowerSync と MongoDB が連携して、車内環境とクラウド環境をスムーズに橋渡しします。
このアーキテクチャは、サポートする車両と同様に を増やす、開発、適応するように設計されています。MongoDBを中心にコードを使用することで、オートメーションはデータのプルーニングにはあまり依存せず、ロードに実際に影響を与えるようなスマートで便利なエクスペリエンスを提供することで集中できます。
データモデルアプローチ
データの品質、構造、アクセス可能性は、 AIベースのエクスペリエンスでは非常に重要です。このソリューションでは、MongoDB の document model により、インテリジェントなインテリジェントなキャパシティーを構築する開発者に柔軟性、速度、増やすことが可能になります。
厳密なテーブルと複雑な結合に依存する従来の**関係データベース**とは異なり、 MongoDB はデータを柔軟な**ドキュメント**として**保存**します。これにより、自動車テレメトリや埋め込み知識チャンクなどのリアルタイムのデータ構造を、コード内で使用される際に正確に表現することが容易になります。そのため、反復処理をより速くし、ダウンタイムなしでモデルを適応させ、アプリケーションの進化に合わせて新機能をビルドできます。
イノベーションとスピードを重視して構築
ドキュメントモデルは開発者向けに設計されています。MongoDB の柔軟なスキーマにより、データモデルを簡単に変更および更新できます。新しい自動車機能がロールアウトされたり、ユーザーの期待が変化したりすると、チームはコストのかかる移行やアプリのダウンタイムなしで、その場でデータモデルを高度化できます。さらに、各ドキュメントは自己完結型であるため、クエリの高速化と簡素化を実現します。
AI ワークロードに自然な選択
生成系AI は、豊富で多彩、非構造化されていないデータを重視しています。埋め込み、 コンテキストに応じたメタデータ、構造化参照はすべてAIシステムの改善に役立ちます。MongoDBでは、次のアクションを実行できます。
ベクトル埋め込み、メタデータ、ソースコンテンツを 1 つのドキュメントにまとめて格納します。
システム間を移動することなく、構造化データとベクトルデータを統合します。
ベクトル場と非ベクトル場を一緒にクエリして、コンテキストに応じた正確な結果を得ることができます。
例 1: カーマニュアルの埋め込み
検索拡張生成 (RAG) アプローチを使用する場合、チャンクと埋め込みの品質は AI の応答の品質に直接影響します。十分にセグメント化されないコンテンツやコンテキストが欠落している場合、あいまいな答えや不正確な答えが返される可能性があります。技術マニュアルには、高密度のテキスト、図、ドメイン固有の用語が含まれていることが多いため、適切な情報を検索するのが困難です。
このソリューションは、マニュアルの各チャンクをドキュメントとして表します。ドキュメントには、テキストとそのベクトル埋め込みだけでなく、メタデータタイプ(例:安全性と診断)、ページ番号、チャンク長、関連するチャンクへのリンク。この追加のコンテキストは、情報がどのように相互に関連するかをシステムが理解するのに役立ちます。これは、高度に技術的なトピックや相互に依存するトピックでは特に重要です。
MongoDB の柔軟なドキュメントモデルにより、この複雑さを簡単にキャプチャできます。マニュアルが進化したり、新しいニーズが発生したりすると、 完全なスキーマ移行 を必要とせずに、フィールドを段階的に追加したり、構造を調整したりできます。これにより、より正確な取得が可能になり、より有用なAI応答が可能になります。
次の例ドキュメントは、手動チャンクを表します。
{ "_id": { "$oid": "67cc4b09c128338a8133b59a" }, "text": "Oil Pressure Warning Lamp. If it illuminates when the engine is running this indicates a malfunction. Stop your vehicle as soon as it is safe to do so and switch the engine off. Check the engine oil level. If the oil level is sufficient, this indicates a system malfunction.", "page_numbers": [ 23 ], "content_type": [ "safety", "diagnostic" ], "metadata": { "page_count": 1, "chunk_length": 1045 }, "id": "chunk_0053", "prev_chunk_id": "chunk_0052", "next_chunk_id": "chunk_0054", "related_chunks": [ { "id": "chunk_0048", "content_type": [ "safety" ], "relation_type": "same_context" }, { "id": "chunk_0049", "content_type": [ "safety" ], "relation_type": "same_context" }, ... ], "embedding": [ -0.002636542310938239, -0.005587903782725334, ... ], "embedding_timestamp": "2025-03-08T13:50:00.887107" }
例 2: 車両信号データ
自動車シグナルの場合、このソリューションは COVESA 自動車シグナル仕様(VSS) を使用してデータをモデル化します。VSS は、速度、速度、または診断トラブル コード(DTC)などのリアルタイムシグナルを記述するための標準化された階層構造を提供します。オープンで拡張可能な形式であるため、プラットフォーム間でのコラボレーション、システム統合、データの再利用が可能になります。
MongoDB の document model はネストされた構造をネイティブに**取り扱っている**ため、VSS 階層を表現するのは簡単です。シグナルは VSS モデルに表示されるのと同様に論理的にグループ化でき、 仕様のツリーベース構造と一致します。

図3。VSS データモデルは、柔軟に組み合わせることができるモジュールでビルドされた階層的なツリー構造です。出典: https://covesa.global/vehicle-signal-specification/
この構造により、開発が迅速化され、 AIツールとワークフローがクリーンで構造化された、意味のあるデータにコンシステントにアクセスできるようになります。
次のドキュメントは、VSS に準拠する自動車シグナルの表現の例です。
{ "_id": { "$oid": "67e58d5f672b23090e57d478" }, "VehicleIdentification": { "VIN": "1HGCM82633A004352" }, "Speed": 0, "TraveledDistance": 0, "CurrentLocation": { "Timestamp": "2020-01-01T00:00:00Z", "Latitude": 0, "Longitude": 0, "Altitude": 0 }, "Acceleration": { "Lateral": 0, "Longitudinal": 0, "Vertical": 0 }, "Diagnostics": { "DTCCount": 0, "DTCList": [] } }
MongoDB のドキュメントモデルはデータを保存するだけではありません。実稼働環境の複雑さを反映するため、リアルタイムで応答し、ユーザーのニーズに適応し、プラットフォームに応じて拡張するシステムをビルドすることが容易になります。自動車診断を保存する場合でも、ベクトルでエンコードされたマニュアルを保存する場合でも、 MongoDB はインテリジェント エクスペリエンスをより速くビルドするためのツールを提供します。
ソリューションのビルド
このソリューションのビルドは、以下に説明する手順に分割できます。MongoDB Atlas を使用してデータをホストし、Google Cloud をAIサービスに使用し、PowerSync を使用して自動車データをストリーミングし、フルスタックアプリを使用してすべてを連携します。必要なアセットとリソースはすべてGitHubリポジトリで確認できます。詳しくは、リポジトリの README を参照してください。
デモデータベースを複製する
Atlas アカウント内でクラスターをプロビジョニングし、デモに必要なデータをデータベースに入力します。リポジトリ内にデータ ダンプを見つけることができ、必要なすべてのデータとメタデータを含むデータベースを簡単な mongorestore コマンドですばやく複製できます。
Google Cloud 環境を設定してください
Google Cloud Platformプロジェクトを作成し、必要な API を有効にします。 Speech-to-Text、 Text-to-Speech、 Document AI、 Vertex AI。ローカル開発では、アプリのデフォルト認証情報を設定して、アプリがGoogle サービスでシームレスに認証できるようにします。手順について詳しくは、 Google Cloud Platformドキュメント を参照してください。
アプリケーションを実行する
リポジトリをローカルにクローンし、提供されたテンプレートを使用して .envファイルを作成します。環境が構成されたら、npm install を実行して依存関係をインストールし、npm run
dev で開発サーバーを起動します。アプリは http://localhost:3000 で入手できます。
キーポイント
対話型AI は適切なデータ基盤から始まります: 豊富でコンテキストに応じたアクセス可能なデータは、インテリジェントな代替手段を強化します。MongoDB Atlas は、構造化テレメトリ、非構造化マニュアル、ベクトル埋め込みを単一の開発者向けプラットフォームに統合し、データサイロを排除し、関連性のリアルタイム応答の提供を容易にします。
MongoDB は、工場から最終ラインまでのイノベーションを加速します: 最新の自動車アプリケーションは、予測によるメンテナンスと診断からデジタル ログ取得 システムまで、柔軟性と速度を要求します。MongoDB の 柔軟なスキーマ、リアルタイム同期機能、水平スケーラビリティにより、チームの移動がより速くなり、より効果的にコラボレーションを行い、他のチームと違う機能を提供することができます。
ドライバーは、次の生成の単語をサポートする準備ができています: 電気自動車、オートメーション、スマート セーフ システムにより、カスタマーは自動車内のシステムに高い期待を持っています。生成系AIにより、従業員はニュアンスのあるインタラクティブな対話を提供できます。MongoDBは、これらのエクスペリエンスを増やすに ビルドするためのツールを開発者に提供します。
作成者
Dr. Humza Akhtar, MongoDB
Rami Pinto、MongoDB