大規模言語モデル(LLM)とセマンティック検索を使用して、YouTube のトランザクションと要約のサービスをビルドします。
ユースケース: Gen AI
業種: メディア
製品: MongoDB Atlas、MongoDB Atlas Vector Search
パートナー: LgChuin
ソリューション概要
Youtube などのプラットフォーム上の情報コンテンツの量とバリエーションでは、関連するビデオをすばやく見つけて書き換えて要約することが、知識収集のために重要です。
このソリューションでは、YouTube のビデオを変換して要約するための 生成系AIベースのビデオ要約アプリを構築しますこのアプリケーションは、ビデオからテキストへの生成とセマンティック検索に、Atlas Vector Search による LLM とベクトル埋め込みを使用します。このアプローチは、ソフトウェア開発などの業界を支援することができ、プロは 生成AIビデオの要約 によってテクノロジーをより速く学ぶことができます。
参照アーキテクチャ
MongoDBがない場合、ビデオ要約ツールは次のワークフローを使用します。

図 1. MongoDB を使用しないリファレンス アーキテクチャ
このソリューションでは、 MongoDB .で次のアーキテクチャを使用します。

図 1. MongoDB を使用したリファレンス アーキテクチャ
まず、このソリューションは YoutubeLoader を使用して Youtube リンクを処理し、ビデオメタデータとトランザクションを取得します。次に、 PythonスクリプトがLLM を使用してビデオ トランザクションを取得し、要約します。
AI埋め込みモデルを使用すると、集約されたトランザクションをMongoDB Atlasに保存される埋め込みに変換します。さらに、オプティマイザーとAI はビデオ フレームワークから直接リアルタイムコード分析を実行し、検索可能なテキストベースのバージョンのビデオ情報とAIベースの説明を生成します。
ソリューションは、この処理されたデータをMongoDB Atlasのドキュメントに保存し、 ビデオメタデータ、そのトランザクション、およびAI が生成したサマリーを含みます。次に、ユーザーはMongoDB Atlas Vector Searchを使用してこれらのドキュメントを検索できます。
データモデルアプローチ
次のコード ブロックは、このソリューションによって生成されたドキュメントの例です。
{ "videoURL": "https://youtu.be/exampleID", "metadata":{ "title": "How to use GO with MongoDB", "author": "MongoDB", "publishDate": "2023-01-24", "viewCount": 1449, "length": "1533s", "thumbnail": "https://exmpl.com/thumb.jpg" }, "transcript": "Full transcript…", "summary": "Tutorial on using Go with MongoDB.", "codeAnalysis": [ "Main function in Go initializes the MongoDB client.", "Imports AWS Lambda package for serverless architecture." ] }
各 YouTube 動画から抽出されたデータは、以下の要素で構成されています。
videoURL: Youtube ビデオへの直接リンク。metadata: タイトル、アップロード者、日付などのビデオの詳細。transcript: ビデオ内のリージョンの内容のテキスト表現。summary: トランスクリプトの簡潔AI生成バージョン。codeAnalysis: AI分析コード例一覧。
ソリューションのビルド
このソリューションのコードはGitHubリポジトリで入手できます。次の手順で説明する具体的な手順については、 README を参照してください。
MongoDB Atlas Vector Searchインデックスの作成
要約されたトランザクションをベクトル検索の埋め込みに変換し、これらをMongoDB Atlasに保存します。
Atlas ベクトル検索を使用してインデックスを作成する方法については、 MongoDB ベクトル検索クイック スタート を参照してください。
次の図は、 ベクトル検索インデックス の作成時に使用できるパラメータ値を示しています。

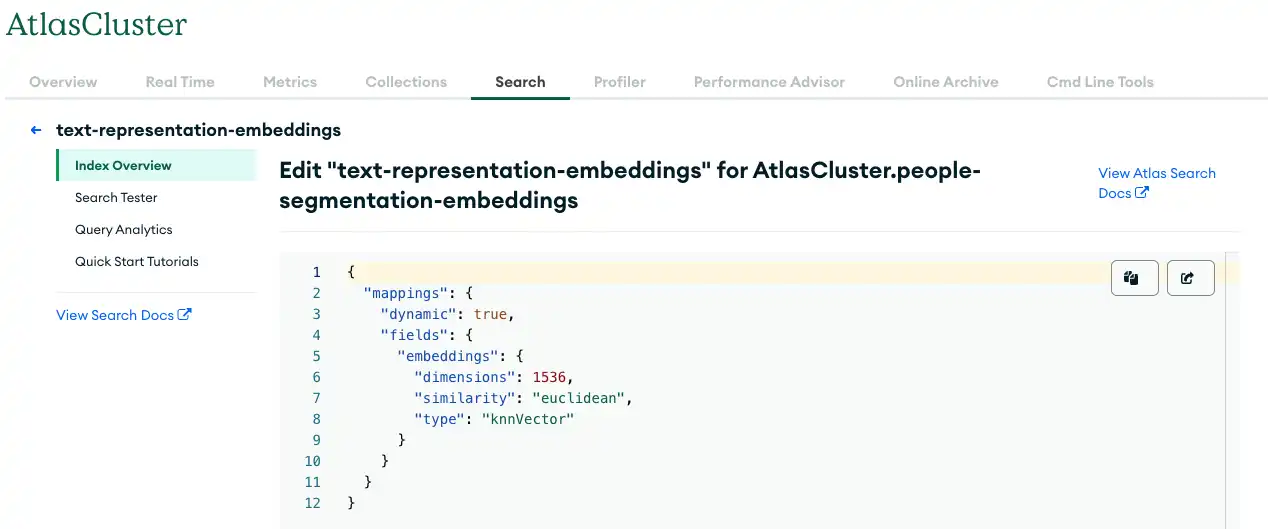
図3。ベクトル検索を使用した MongoDB Atlas へのデータの保存
オーケストレーションレイヤーを作成する
このソリューションは、オーケストレーションレイヤーを使用して、ソリューションのさまざまなサービスを調整し、複雑なワークフローを管理します。オーケストレーションレイヤーは、次のクラスで構成されています。これらは、 ソリューションのGitHubリポジトリ:で確認できます。
VideoServiceFacade:VideoService、SearchService、VideoProcessResultクラスのコーディネーターとして機能します。このシステムは、トランザクションの生成と要約のためのユーザーのプロンプトとリクエストを取り扱います。VideoService: トランザクションのサマリーを実行します。VideoProcessResult:メタデータ、可能なアクション、最適な検索クエリ用語など、処理されたビデオの結果をカプセル化します。SearchService: MongoDB Atlasで検索します。
キーポイント
Atlas ベクトル検索 は自然言語検索を可能にします: このソリューションは Atlas ベクトル検索にベクトルインデックスを作成して保存し、LM で生成された埋め込みと出力をMongoDB Atlasに保存します。これにより、ユーザーは 1 つのプラットフォームで、キーワードが完全に一致しない可能性のある関連する情報を検索できます。
LangChainは生成系AIを基盤としたアプリケーションを実現します:LangChainはMongoDBとシームレスに統合し、強力なAI駆動型プラットフォームを構築します。
作成者
Fabio Falavinha, MongoDB
David Macias, MongoDB