障害復旧を計画することは、組織にとって重要です。次のような要素を含む包括的な障害復旧(DR)プランを作成することを強くお勧めします。
指定された目標復旧時点(RPO)
指定されたリカバリ時間目的 (RTO)
これらの目的との整合性を容易にする自動化プロセス
災害への備えと対応のため、このページの推奨事項を活用してください。
障害復旧に役立つプロアクティブな高可用性構成の詳細については、「Atlas の高可用性に関する推奨事項」を参照してください。
Atlas の障害復旧に関する機能
障害復旧をサポートする Atlas の機能については、Atlas アーキテクチャ センターの次のページをご覧ください。
Atlas の障害復旧に関する推奨事項
次の障害復旧に関する推奨事項を参照して、組織用の DR プランを作成します。これらの推奨事項は、災害イベントが発生した場合に取るべき手順に関する情報を提供します。
このセクションのプランは定期的に(できますが、少なくとも四半期ごとに)テストする必要があります。テストは、エンタープライズ データベース管理(EDM)チームが障害発生に対応する準備ができていると同時に、指示を最新に保つのにも役立ちます。
一部の障害復旧テストでは、EDM ユーザーでは実行できないアクションが必要になる場合があります。このような場合は、テストを実行中予定の の少なくとも 1 週間前に、強制停止を実行するためにサポートケースを開きます。
次の図は、さまざまな障害復旧シナリオと配置構成を比較したものです。この表は、相対的なリカバリ時間目的(RTO)とリカバリ点目的(RPO)の利点と、各構成の配置の複雑さとコストに対する利点を示しています。レプリカセットの選挙( 自動フェイルオーバー)によってデータが失われることはありませんが、バックアップからの回復にはバックアップ頻度によってはデータが失われる可能性があることに注意してください。「コントロールプレーンの障害」とは、データ ノードではなく Atlas のマネジメントのインフラストラクチャの問題を指します。

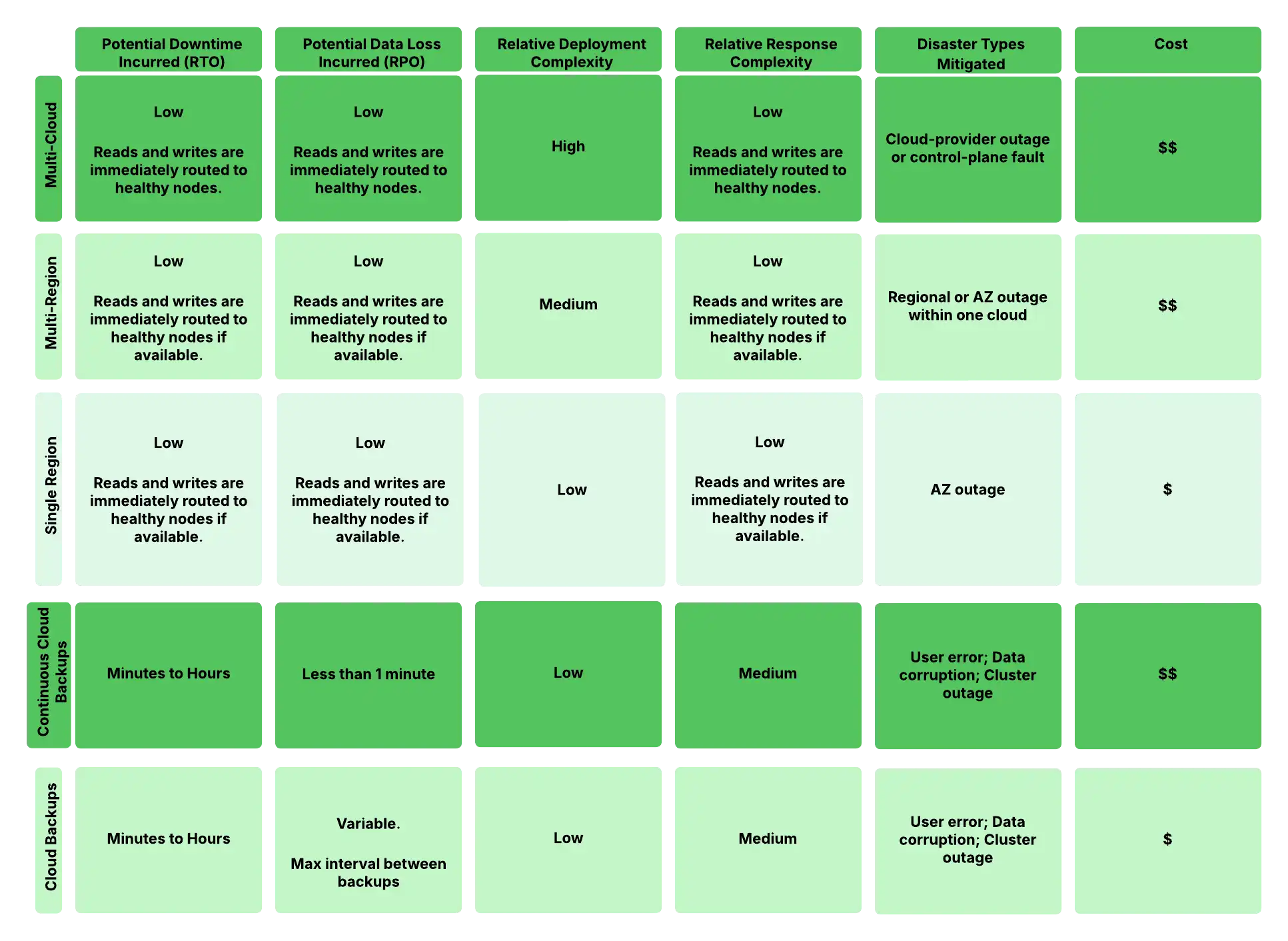
図の 1。障害復旧構成の複雑さと RTO/RPO のトレードオフ。
Atlas クラスターを配置できる各クラウドプロバイダーは、停止の影響を軽減するデフォルトのデータ冗長性を提供します。
AWS は、AWS リージョン内の少なくとも 3 つのアベイラビリティーゾーンにわたって複数のデバイスにオブジェクトを保存します。
Microsoft Azure は、選択したリージョン内の単一のデータセンター内でデータを 3 回複製するローカル冗長ストレージ(LRS)を使用します。
Google Cloud Platformは、バックアップ リージョンの複数のゾーンにデータを分散します。
障害復旧を強化するためには、スナップショットと oplog のコピーを他のリージョンに自動的に作成するように Atlas を設定できます。これにより、プライマリリージョンで停止が発生した場合でも、他のリージョンに保存されているスナップショットコピーを使用してクラスターを復元することができます。
Atlas は、リージョンの可用性に基づいて最も効率的なオプションを選択し、復元速度を最適化します。また、これらのコピーが存在するリージョンに復元する場合は、コピーされたスナップショットを使用します。さらに、リージョン停止時により元のスナップショットにアクセスできない場合、Atlas は使用可能な最も近いスナップショットコピーを使用して復元し、ダウンタイムを最小限に抑え、回復力を向上させます。詳しくは、エクスポート クラウド バックアップ スナップショットを参照してください。
マルチリージョンおよびマルチクラウド配置では、クラスター ノードを異なるロケーションまたはクラウドプロバイダーに分散することで、障害復旧機能が強化されます。この分散により、1 つのリージョンまたはクラウドプロバイダーが停止時した場合でも、アプリケーションは影響を受けないロケーションでノードを使用して運用を続けることができます。
マルチリージョンまたはマルチクラウド配置を構成する場合は、特定のリカバリ要件に基づいて適切なバックアップ保持期間を設定するなど、バックアップ戦略が分散された配置を考慮してください。
すべての配置パラダイムに共通する推奨事項
以下の推奨事項は、すべての配置パラダイムに適用されます。
このセクションでは、次の障害復旧手順について説明します。
単一ノードの停止時
部分的なリージョン停止でレプリカセット内の 1 つのノードが停止しても、ベストプラクティスに従っていれば、配置は引き続き利用可能です。セカンダリから読み取っている場合、セカンダリ ノードで障害が発生すると、プロビジョニングが不十分なクラスターの負荷が増加するため、パフォーマンスが低下したり、停止したりする可能性があります。
Atlas UI の プライマリ フェイルオーバーのテスト 機能または Atlas 管理APIエンドポイント を使用して、Atlas でプライマリノードの停止時をテストできます。
リージョン停止
マルチリージョンクラスターは、リージョンの停止時、自動的に選挙を実施し、必要に応じて新しいプライマリ ノードを特定します。このトポロジーの変更は自動的にアプリケーションに伝達され、必要な是正アクションを実行できます。リージョンの停止が発生した場合でもアプリケーションの稼働時間を維持するためには、アプリケーション自体もマルチリージョン トポロジーで配置する必要があります。この要件は、アプリケーションが統合する可能性のあるサードパーティサービスにも適用されます。詳細は、「マルチリージョン配置パラダイム」を参照してください。
単一リージョンの停止時またはマルチリージョンの停止時にクラスターの状態が低下する場合は、次の手順に従います。
識別したリージョンにノードを追加してください
停止時の原因による影響を受けやすいリージョン全体で通常の状態に必要な数のノードを追加します。
障害発生時にリージョンやノードを追加してレプリカセットを再構成するには、「地域障害時のレプリカセットの再構成」を参照してください。
Atlas UI の 停止時シミュレーション 機能または 停止時シミュレーションを開始する 管理APIエンドポイントを使用して、Atlas でリージョン停止時をテストできます。
クラウド プロバイダーの障害
マルチクラウドクラスターでは、クラウドプロバイダー全体で選挙可能なノードを選択して、高可用性を維持できます。プライマリノードが配置されているプロバイダーが利用できなくなった場合、Atlas は自動的に新しいプライマリ ノードを選択して 継続的な操作を確保します。例、AWS、Google Cloud、Microsoft Azureに選挙可能な ノードを作成して、1つのクラウドプロバイダーが停止時だった場合でも、別のプロバイダーの選挙可能な ノードが自動的にクラスターのプライマリノードを引き継ぐことができます。詳細については、マルチクラウド配置パラダイムを参照してください。
ほとんどのマルチリージョン Atlas クラスターは、1 つのリージョンの停止から自動的に復旧します。詳細は、「高可用性」セクションと「マルチリージョン配置」ページを参照してください。リージョンの停止で過半数のノードが停止した場合、過半数のノードを正常にするために、あと何ノードを追加する必要があるかを判断する必要があります。
非常に稀なケースとして、クラウドプロバイダー全体が利用不可になった場合、次の手順に従って配置を再度オンラインにします。
新しいクラスターを配置する代替のクラウドプロバイダーを特定する
クラウドプロバイダーと情報のリストについては、「 クラウドプロバイダー 」を参照してください。
バックアップを複数のクラウドプロバイダーに保存している場合、クラウドプロバイダーの停止によりプライマリクラウドプロバイダーに保存されているバックアップが利用できなくなるため、停止が始まる前に取得されたクラスターの最新のスナップショットを見つけます。
バックアップ スナップショットの表示方法については、「M10+ バックアップ スナップショットの表示」をご覧ください。
前のステップから新しいクラスターに最新のスナップショットを復元します。
スナップショットを復元する方法については、「 クラスターの復元 」を参照してください。
古いクラスターに接続するアプリケーションを新しく作成されたクラスターに切り替える
新しい接続文字列を見つけるには、クライアント ライブラリ経由で接続 を参照してください。アプリケーションスタックを新しいクラウドプロバイダーに再デプロイする必要がある可能性が高いため、アプリケーションスタックを検討します。
Atlas の停止時
非常に稀なケースですが、Atlas Control Plane と Atlas UI が使用できない場合でも、クラスターは引き続き利用およびアクセス可能です。詳しくは、「プラットフォームの Reliability」をご覧ください。この問題をさらに調査するには、高優先順位のサポートチケットを開きます。
リソースのキャパシティーの問題
計算リソース(ディスク容量、RAM、CPU など)のキャパシティーの問題は、計画が不十分であったり、データベース トラフィックが予期せぬものであった場合に発生する可能性があります。この現象は、災害の結果ではない可能性があります。
計算リソースが最大割り当て量に達し、災害を引き起こした場合は、次の手順を実行します。
リアルタイム パフォーマンス パネル または Atlas メトリクスを使用して、どの計算リソースが最大使用量になっているかを識別する
Atlas UIでリソース使用率を表示するには、「 リアルタイム パフォーマンスのモニタリング 」を参照してください。
Atlas Administration APIを使用してメトリクスを表示するには、「 モニタリングとログ 」を参照してください。
必要なリソースを割り当てます
Atlas はこの変更を順次実行するため、アプリケーションに大きな影響を与えることはありません。
より多くのリソースを割り当てる方法については、「 クラスターの編集 」を参照してください。
リソースの故障
重要
これは、システム全体のダウンタイムを短縮することを目的とした一時的な解決策です。基礎となる問題が解決されたら、新しく作成したクラスターのデータを元のクラスターにマージし、すべてのアプリケーションを元のクラスターに戻し点。
計算リソースが故障し、クラスターが利用不可になった場合、次の手順に従います。
最新のバックアップを新しく作成されたクラスターに復元する
スナップショットを復元する方法については、「 クラスターの復元 」を参照してください。
本番データの削除
人為的なミスやデータベース上に構築されたアプリケーションのバグにより、プロダクション データが誤って削除される可能性があります。クラスター自体が誤って削除された場合、Atlas はボリュームを一時的に保持する可能性があります。
コレクションまたはデータベースの内容が削除された場合は、次の手順に従ってデータを復元します。
データが含まれている場合は、コレクションまたはデータベースの現在の状態のコピーを作成します
mongoexport を使用してコピーを作成できます。
データを復元
削除が過去 72 時間以内に発生し、継続的なバックアップを設定した場合は、ポイント イン タイム(PIT)リストアを使用して、削除が発生する直前の時点にリストアします。
過去 72 時間で削除が発生していない場合は、削除が発生する前の最新のバックアップをクラスターに復元します。
詳しくは、「 クラスターの復元 」を参照してください。
データのコピーを作成した場合は、エクスポートした新しいデータをインポートします。
mongoimport をアップサートモードで使用してデータをインポートし、変更または追加されたデータがコレクションまたはデータベースに適切に反映されていることを確認します。
ドライバーの故障
ドライバーに障害が発生した場合は、次の手順を実行します。
データの破損
重要
これは、システム全体のダウンタイムを短縮することを目的とした一時的な解決策です。基礎となる問題が解決されたら、新しく作成したクラスターのデータを元のクラスターにマージし、すべてのアプリケーションを元のクラスターに戻し点。
基礎データが破損した場合は、次の手順に従います。
最新のバックアップを新しく作成されたクラスターに復元する
スナップショットを復元する方法については、「 クラスターの復元 」を参照してください。