Your application is growing. It has more active users, more features, and generates more data every day. Your database is now becoming a bottleneck for the rest of your application. Database sharding could be the solution to your problems, but many do not have a clear understanding of what it is and, especially, when to use it. In this article, we’ll cover the basics of database sharding, its best use cases, and the different ways you can implement it.
Table of contents
- What is database sharding?
- Evaluating alternatives
- Advantages and disadvantages of sharding
- How does database sharding work?
- Sharding architecture and types
- FAQs
What is database sharding?
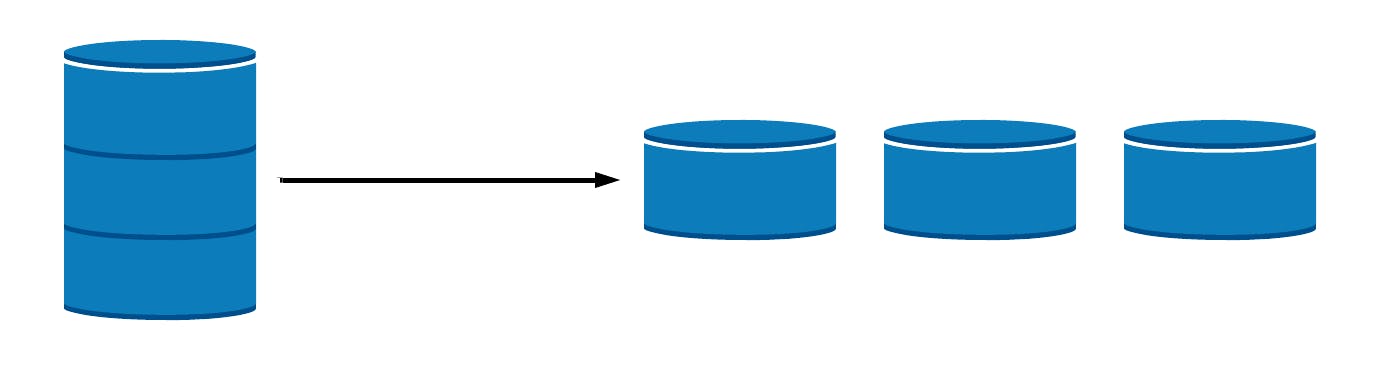
Sharding is a method for distributing a single dataset across multiple databases, which can then be stored on multiple machines. This allows for larger datasets to be split into smaller chunks and stored in multiple data nodes, increasing the total storage capacity of the system. See more on the basics of sharding here.
Similarly, by distributing the data across multiple machines, a sharded database can handle more requests than a single machine can.
Sharding is a form of scaling known as horizontal scaling or scale-out, as additional nodes are brought on to share the load. Horizontal scaling allows for near-limitless scalability to handle big data and intense workloads. In contrast, vertical scaling refers to increasing the power of a single machine or single server through a more powerful CPU, increased RAM, or increased storage capacity.
Do you need database sharding?
Database sharding, as with any distributed architecture, does not come for free. There is overhead and complexity in setting up shards, maintaining the data on each shard, and properly routing requests across those shards. Before you begin sharding, consider if one of the following alternative solutions will work for you.
Vertical scaling
By simply upgrading your machine, you can scale vertically without the complexity of sharding. Adding RAM, upgrading your computer (CPU), or increasing the storage available to your database are simple solutions that do not require you to change the design of either your database architecture or your application.
Specialized services or databases
Depending on your use case, it may make more sense to simply shift a subset of the burden onto other providers or even a separate database. For example, blob or file storage can be moved directly to a cloud provider such as Amazon S3. Analytics or full-text search can be handled by specialized services or a data warehouse. Offloading this particular functionality can make more sense than trying to shard your entire database.
Replication
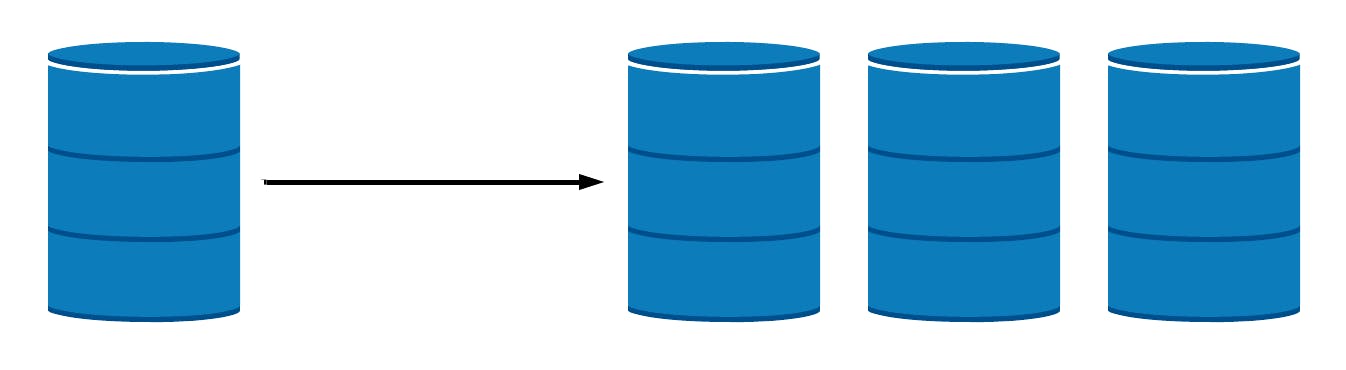
If your data workload is primarily read-focused, replication increases availability and read performance while avoiding some of the complexity of database sharding. By simply spinning up additional copies of the database, read performance can be increased either through load balancing or through geo-located query routing. However, replication introduces complexity on write-focused workloads, as each write must be copied to every replicated node.
On the other hand, if your core application database contains large amounts of data, requires high read and high write volume, and/or you have specific availability requirements, a sharded database may be the way forward. Let’s look at the advantages and disadvantages of sharding.
Advantages of sharding
Sharding allows you to scale your database to handle increased load to a nearly unlimited degree by providing increased read/write throughput, storage capacity, and high availability. Let’s look at each of those in a little more detail.
- Increased read/write throughput — By distributing the dataset across multiple shards, both read and write operation capacity is increased as long as read and write operations are confined to a single shard.
- Increased storage capacity — Similarly, by increasing the number of shards, you can also increase overall total storage capacity, allowing near-infinite scalability.
- High availability — Finally, shards provide high availability in two ways. First, since each shard is a replica set, every piece of data is replicated. Second, even if an entire shard becomes unavailable since the data is distributed, the database as a whole still remains partially functional, with part of the schema on different shards.
Disadvantages of sharding
Sharding does come with several drawbacks, namely overhead in query result compilation, complexity of administration, and increased infrastructure costs.
- Query overhead — Each sharded database must have a separate machine or service which understands how to route a querying operation to the appropriate shard. This introduces additional latency on every operation. Furthermore, if the data required for the query is horizontally partitioned across multiple shards, the router must then query each shard and merge the result together. This can make an otherwise simple operation quite expensive and slow down response times.
- Complexity of administration — With a single unsharded database, only the database server itself requires upkeep and maintenance. With every sharded database, on top of managing the shards themselves, there are additional service nodes to maintain. Plus, in cases where replication is being used, any data updates must be mirrored across each replicated node. Overall, a sharded database is a more complex system which requires more administration.
- Increased infrastructure costs — Sharding by its nature requires additional machines and compute power over a single database server. While this allows your database to grow beyond the limits of a single machine, each additional shard comes with higher costs. The cost of a distributed database system, especially if it is missing the proper optimization, can be significant.
Having considered the pros and cons, let’s move forward and discuss implementation.
How does sharding work?
In order to shard a database, we must answer several fundamental questions. The answers will determine your implementation.
First, how will the data be distributed across shards? This is the fundamental question behind any sharded database. The answer to this question will have effects on both performance and maintenance. More detail on this can be found in the “Sharding Architectures and Types” section.
Second, what types of queries will be routed across shards? If the workload is primarily read operations, replicating data will be highly effective at increasing performance, and you may not need sharding at all. In contrast, a mixed read-write workload or even a primarily write-based workload will require a different architecture.
Finally, how will these shards be maintained? Once you have sharded a database, over time, data will need to be redistributed among the various shards, and new shards may need to be created. Depending on the distribution of data, this can be an expensive process and should be considered ahead of time.
With these questions in mind, let’s consider some sharding architectures.
Sharding architectures and types
While there are many different sharding methods, we will consider four main kinds: ranged/dynamic sharding, algorithmic/hashed sharding, entity/relationship-based sharding, and geography-based sharding.
Ranged/dynamic sharding
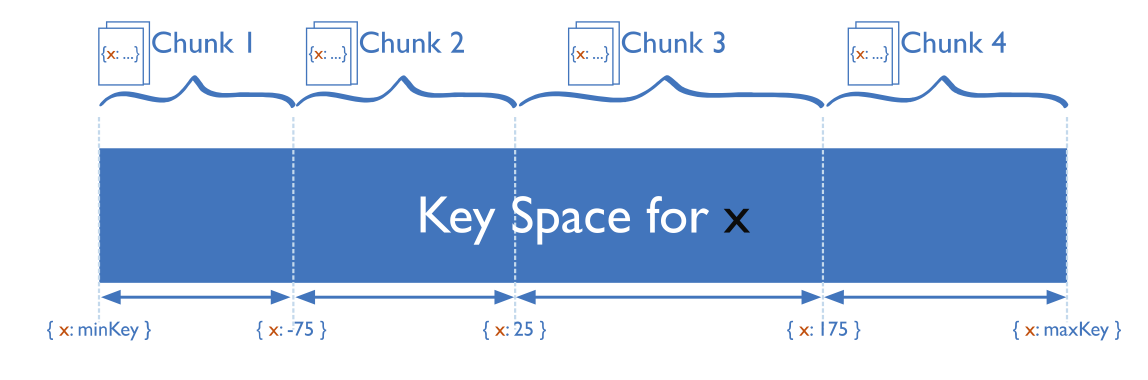
Ranged sharding, or dynamic sharding, takes a field on the record as an input and, based on a predefined range, allocates that record to the appropriate shard. Ranged sharding requires there to be a lookup table or service available for all queries or writes. For example, consider a set of data with IDs that range from 0-50. A simple lookup table might look like the following:
The field on which the range is based is also known as the shard key. Naturally, the choice of shard key, as well as the ranges, are critical in making range-based sharding effective. A poor choice of shard key will lead to unbalanced shards, which leads to decreased performance. An effective shard key will allow for queries to be targeted to a minimum number of shards. In our example above, if we query for all records with IDs 10-30, then only shards A and B will need to be queried.
Two key attributes of an effective shard key are high cardinality and well-distributed frequency. Cardinality refers to the number of possible values of that key. If a shard key only has three possible values, then there can only be a maximum of three shards. Frequency refers to the distribution of the data along the possible values. If 95% of records occur with a single shard key value then, due to this hotspot, 95% of the records will be allocated to a single shard. Consider both of these attributes when selecting a shard key.
Range-based sharding is an easy-to-understand method of horizontal partitioning, but the effectiveness of it will depend heavily on the availability of a suitable shard key and the selection of appropriate ranges. Additionally, the lookup service can become a bottleneck, although the amount of data is small enough that this typically is not an issue.
Algorithmic/hashed sharding
Algorithmic sharding or hashed sharding, takes a record as an input and applies a hash function or algorithm to it which generates an output or hash value. This output is then used to allocate each record to the appropriate shard.
The function can take any subset of values on the record as inputs. Perhaps the simplest example of a hash function is to use the modulus operator with the number of shards, as follows:
Hash Value=ID % Number of Shards
This is similar to range-based sharding — a set of fields determines the allocation of the record to a given shard. Hashing the inputs allows more even distribution across shards even when there is not a suitable shard key, and no lookup table needs to be maintained. However, there are a few drawbacks.
First, query operations for multiple records are more likely to get distributed across multiple shards. Whereas ranged sharding reflects the natural structure of the data across shards, hashed sharding typically disregards the meaning of the data. This is reflected in increased broadcast operation occurrence.
Second, resharding can be expensive. Any update to the number of shards likely requires rebalancing all shards to moving around records. It will be difficult to do this while avoiding a system outage.
Entity-/relationship-based sharding
Entity-based sharding keeps related data together on a single physical shard. In a relational database (such as PostgreSQL, MySQL, or SQL Server), related data is often spread across several different tables.
For instance, consider the case of a shopping database with users and payment methods. Each user has a set of payment methods that is tied tightly with that user. As such, keeping related data together on the same shard can reduce the need for broadcast operations, increasing performance.
Geography-based sharding
Geography-based sharding, or geosharding, also keeps related data together on a single shard, but in this case, the data is related by geography. This is essentially ranged sharding where the shard key contains geographic information and the shards themselves are geo-located.
For example, consider a dataset where each record contains a “country” field. In this case, we can both increase overall performance and decrease system latency by creating a shard for each country or region, and storing the appropriate data on that shard. This is a simple example, and there are many other ways to allocate your geoshards which are beyond the scope of this article.
Summary
We’ve defined what sharding is, discussed when to use it, and explored different sharding architectures. Sharding is a great solution for applications with large data requirements and high-volume read/write workloads, but it does come with additional complexity. Consider whether the benefits outweigh the costs or whether there is a simpler solution before you begin implementation.