Definición
$densifyNuevo en la versión 5.1.
Crea nuevos documentos en una secuencia de documentos donde faltan ciertos valores en un campo.
Puede usar
$densifya:Rellenar vacíos en datos de series de tiempo.
Agregar valores faltantes entre grupos de datos.
Complete sus datos con un rango específico de valores.
Sintaxis
La etapa $densify tiene esta sintaxis:
{ $densify: { field: <fieldName>, partitionByFields: [ <field 1>, <field 2> ... <field n> ], range: { step: <number>, unit: <time unit>, bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ] } } }
La etapa $densify toma un documento con estos campos:
Campo | Necesidad | Descripción |
|---|---|---|
Requerido | El campo para densificar. Los valores de la Los documentos que no contienen el Para especificar un Para conocer las | |
Opcional | El conjunto de campos que actúa como clave compuesta para agrupar los documentos. En la Si omite este campo, Para ver un ejemplo, consulte Densificación con particiones. Para conocer las | |
Requerido | Un objeto que especifica cómo se densifican los datos. | |
Requerido | Puede especificar
Si
Si
Si
| |
Requerido | La cantidad en la que se incrementará el valor del campo en cada documento. Si se especifica rango.unit, | |
Obligatorio si el campo es una fecha. | La unidad a aplicar al campo step cuando se incrementan valores de fecha en el campo. Puedes especificar uno de los siguientes valores para
Para ver un ejemplo, consulta Densificar datos de series de tiempo. |
Comportamiento y restricciones
field Restricciones
Para documentos que contengan el campo especificado, $densify produce errores si:
Cualquier documento en la colección tiene un valor
fieldde tipo fecha y el campo unit no está especificado.Cualquier documento de la colección tiene un
fieldvalor de tipo numérico y se especifica el campo de unidad.El nombre
fieldcomienza con$. Tienes que renombrar el campo si deseas densificarlo. Para cambiar el nombre de los campos, usa$project.
partitionByFields Restricciones
$densify Errores si algún nombre de campo en el arreglo:
Evalúa a un valor que no es una cadena.
Comienza con
$.
range.bounds Comportamiento
Si range.bounds es un arreglo:
El límite inferior indica el valor inicial para los documentos añadidos, independientemente de los documentos que ya estén presentes en la colección.
El límite inferior es inclusivo.
El límite superior es exclusivo.
$densifyno filtra los documentos con valores de campo fuera de los límites especificados.
Orden de salida
$densify no garantiza el orden de clasificación de los documentos que produce.
Para garantizar el orden de clasificación, utiliza $sort en el campo por el que quieras clasificar.
Ejemplos
Densificar datos de series de tiempo
Crear una colección de weather que contenga lecturas de temperatura durante intervalos de cuatro horas.
db.weather.insertMany( [ { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T00:00:00.000Z"), "temp": 12 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T04:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T08:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T12:00:00.000Z"), "temp": 12 } ] )
Este ejemplo utiliza la etapa $densify para completar los intervalos de cuatro horas y lograr una granularidad horaria en los puntos de datos:
db.weather.aggregate( [ { $densify: { field: "timestamp", range: { step: 1, unit: "hour", bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ] } } } ] )
En el ejemplo:
La fase
$densifyrellena los vacíos de tiempo entre las temperaturas registradas.field: "timestamp"densifica el campotimestamp.
range:step: 1incrementa el campotimestampen 1 unidad.unit: hourdensifica el campotimestamppor hora.bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]establece el rango de tiempo que se densifica.
En el siguiente resultado, la etapa $densify llena los espacios de tiempo entre las horas de 00:00:00 y 08:00:00.
[ { _id: ObjectId("618c207c63056cfad0ca4309"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T00:00:00.000Z"), temp: 12 }, { timestamp: ISODate("2021-05-18T01:00:00.000Z") }, { timestamp: ISODate("2021-05-18T02:00:00.000Z") }, { timestamp: ISODate("2021-05-18T03:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430a"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T04:00:00.000Z"), temp: 11 }, { timestamp: ISODate("2021-05-18T05:00:00.000Z") }, { timestamp: ISODate("2021-05-18T06:00:00.000Z") }, { timestamp: ISODate("2021-05-18T07:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430b"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T08:00:00.000Z"), temp: 11 } { _id: ObjectId("618c207c63056cfad0ca430c"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T12:00:00.000Z"), temp: 12 } ]
Densificación con particiones
Crea una colección de coffee que contenga datos de dos variedades de granos de café:
db.coffee.insertMany( [ { "altitude": 600, "variety": "Arabica Typica", "score": 68.3 }, { "altitude": 750, "variety": "Arabica Typica", "score": 69.5 }, { "altitude": 950, "variety": "Arabica Typica", "score": 70.5 }, { "altitude": 1250, "variety": "Gesha", "score": 88.15 }, { "altitude": 1700, "variety": "Gesha", "score": 95.5, "price": 1029 } ] )
Densificar toda la gama de valores
Este ejemplo utiliza para densificar $densify el altitude campo para cada variety café:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "full", step: 200 } } } ] )
La agregación de ejemplo:
Divide los documentos por
varietypara crear un agrupamiento paraArabica Typicay otro paraGeshacafé.Especifica un
fullrango, lo que significa que los datos se densifican en todo el rango de documentos existentes para cada partición.Especifica un
stepde200, lo que significa que se crean nuevos documentos en intervalos dealtitudede200.
La agregación genera los siguientes documentos:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { variety: 'Gesha', altitude: 600 }, { variety: 'Gesha', altitude: 800 }, { variety: 'Gesha', altitude: 1000 }, { variety: 'Gesha', altitude: 1200 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1400 }, { variety: 'Gesha', altitude: 1600 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 }, { variety: 'Arabica Typica', altitude: 1000 }, { variety: 'Arabica Typica', altitude: 1200 }, { variety: 'Arabica Typica', altitude: 1400 }, { variety: 'Arabica Typica', altitude: 1600 } ]
Esta imagen muestra los documentos creados con $densify:

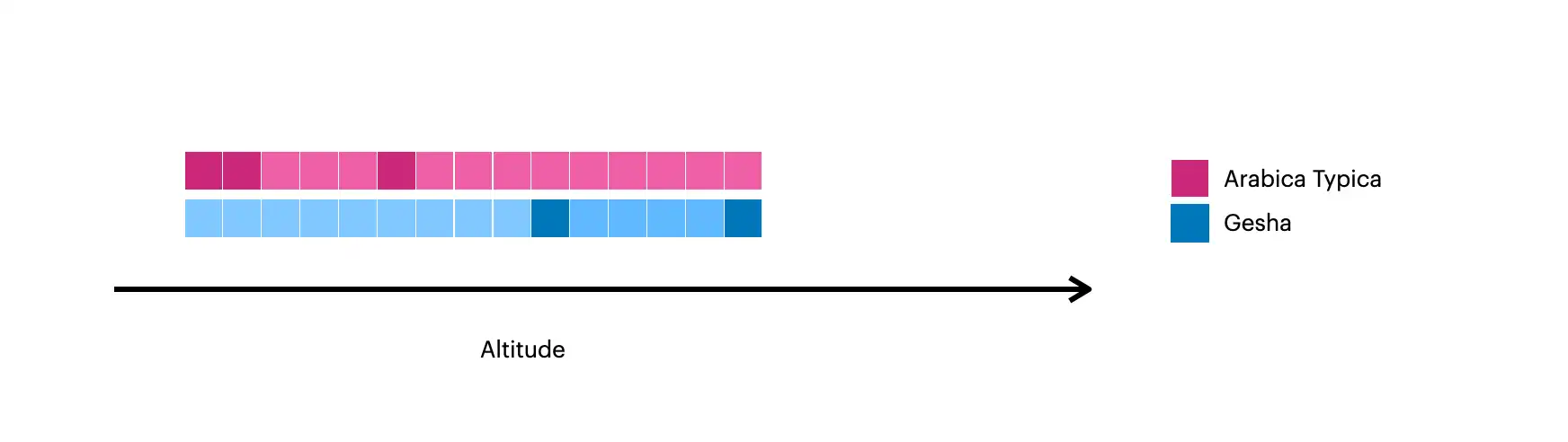
Los cuadrados más oscuros representan los documentos originales de la colección.
Los cuadros más claros representan los documentos creados con
$densify.
Densificar valores dentro de cada partición
Este ejemplo utiliza solo para densificar los espacios en $densify el altitude campo dentro de variety cada:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "partition", step: 200 } } } ] )
La agregación de ejemplo:
Divide los documentos por
varietypara crear un agrupamiento paraArabica Typicay otro paraGeshacafé.Se especifica un rango
partition, lo que significa que los datos se densifican dentro de cada partición.Para la partición
Arabica Typica, el rango es600-950.Para la partición
Gesha, el rango es1250-1700.
Especifica un
stepde200, lo que significa que se crean nuevos documentos en intervalos dealtitudede200.
La agregación genera los siguientes documentos:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1450 }, { variety: 'Gesha', altitude: 1650 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 } ]
Esta imagen muestra los documentos creados con $densify:

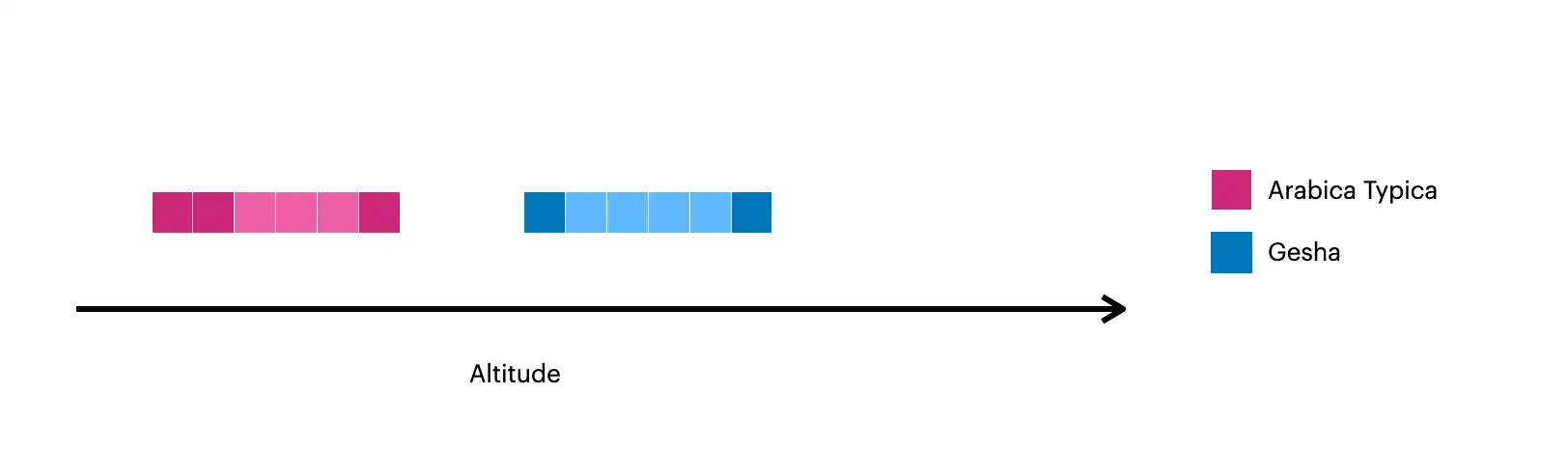
Los cuadrados más oscuros representan los documentos originales de la colección.
Los cuadros más claros representan los documentos creados con
$densify.
Los ejemplos de C# de esta página utilizan la sample_weatherdata.data colección de los conjuntos de datos de ejemplo de Atlas. Para aprender a crear un clúster gratuito de MongoDB Atlas y cargar los conjuntos de datos de ejemplo, consulte la sección "Comenzar" en la documentación del controlador MongoDB.NET/C#.
Las siguientes clases Weather y Point modelan los documentos en la colección sample_weatherdata.data:
public class Weather { public Guid Id { get; set; } public Point Position { get; set; } [] public DateTime Timestamp { get; set; } } public class Point { public float[] Coordinates { get; set; } }
La colección sample_weatherdata.data contiene los siguientes documentos, que incluyen mediciones para el mismo campo position con una diferencia de una hora:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
Para utilizar el driver de MongoDB .NET/C# para añadir una etapa $densify a una pipeline de agregación, llame al Densify()método en un PipelineDefinition objeto.
El siguiente ejemplo crea una etapa de canalización que añade un documento cada 15minutos entre los dos documentos anteriores. El código agrupa estos documentos según los valores de su campo Position.Coordinates.
var densifyTimeRange = new DensifyDateTimeRange( new DensifyLowerUpperDateTimeBounds( lowerBound: new DateTime(1984, 3, 5, 8, 0, 0), upperBound: new DateTime(1984, 3, 5, 9, 0, 0) ), step: 15, unit: DensifyDateTimeUnit.Minutes ); var pipeline = new EmptyPipelineDefinition<Weather>() .Densify( field: w => w.Timestamp, range: densifyTimeRange, partitionByFields: [w => w.Position.Coordinates]);
La etapa de agregación anterior genera los siguientes documentos destacados en la colección:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:15:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:30:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:45:00 EST 1984 }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
Los ejemplos de Node.js en esta página utilizan la colección sample_weatherdata.data de los conjuntos de datos de muestra de Atlas. Para aprender a crear un clúster gratuito de MongoDB Atlas y cargar los conjuntos de datos de muestra, se puede consultar Primeros pasos en la documentación del driver de MongoDB Node.js.
La colección sample_weatherdata.data contiene los siguientes documentos, que incluyen mediciones para el mismo campo position con una diferencia de una hora:
{_id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, {_id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }
Para utilizar el controlador de MongoDB Node.js para agregar una etapa de $densify a una canalización de agregación, utilice el Operador $densify en un objeto de canalización.
El siguiente ejemplo crea una etapa de pipeline que añade un documento cada intervalo de 15minutos entre los dos documentos anteriores. A continuación, el código agrupa estos documentos según los valores de su campo position.coordinates. Luego, el ejemplo ejecuta la pipeline de agregación:
const pipeline = [ { $densify: { field: "ts", partitionByFields: ["position.coordinates"], range: { step: 15, unit: "minute", bounds: [new Date(1984, 3, 5, 8, 0, 0), new Date(1984, 3, 5, 9, 0, 0)] } } } ]; const cursor = collection.aggregate(pipeline); return cursor;
La etapa de agregación anterior genera los siguientes documentos destacados en la colección:
{ _id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:15:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:30:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:45:00.000Z }, { _id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }