Para obtener los datos necesarios para renderizar una gráfica, Charts crea un Pipeline de Agregación de MongoDB y ejecuta el pipeline en el servidor de base de datos de MongoDB. La pipeline consiste en múltiples etapas, cada una de las cuales se genera según diferentes configuraciones especificadas por el autor de la gráfica.
Este documento explica cómo se utilizan las distintas configuraciones del Generador de Gráficos para construir la canalización de agregación. Puede ver la canalización utilizada para crear un gráfico seleccionando View Aggregation Pipeline opción en el menú desplegable de puntos suspensivos del Generador de gráficos en la parte superior derecha.
Los gráficos Atlas construyen una tubería que consta de los siguientes segmentos en el siguiente orden:
Nota
Al crear una gráfica, puedes configurar algunos, pero no todos, de los segmentos de la gráfica anterior. Cuando Charts genera el pipeline de agregación, omite los segmentos no especificados.
Ejemplo
La siguiente gráfica muestra el total de ventas de una empresa de suministros de oficina, clasificado por método de compra. Cada documento de la recopilación de datos representa una sola venta.
Usando este gráfico como ejemplo, exploraremos cómo las especificaciones para cada una de las configuraciones anteriores cambian el flujo de agregación generado por Atlas Charts.

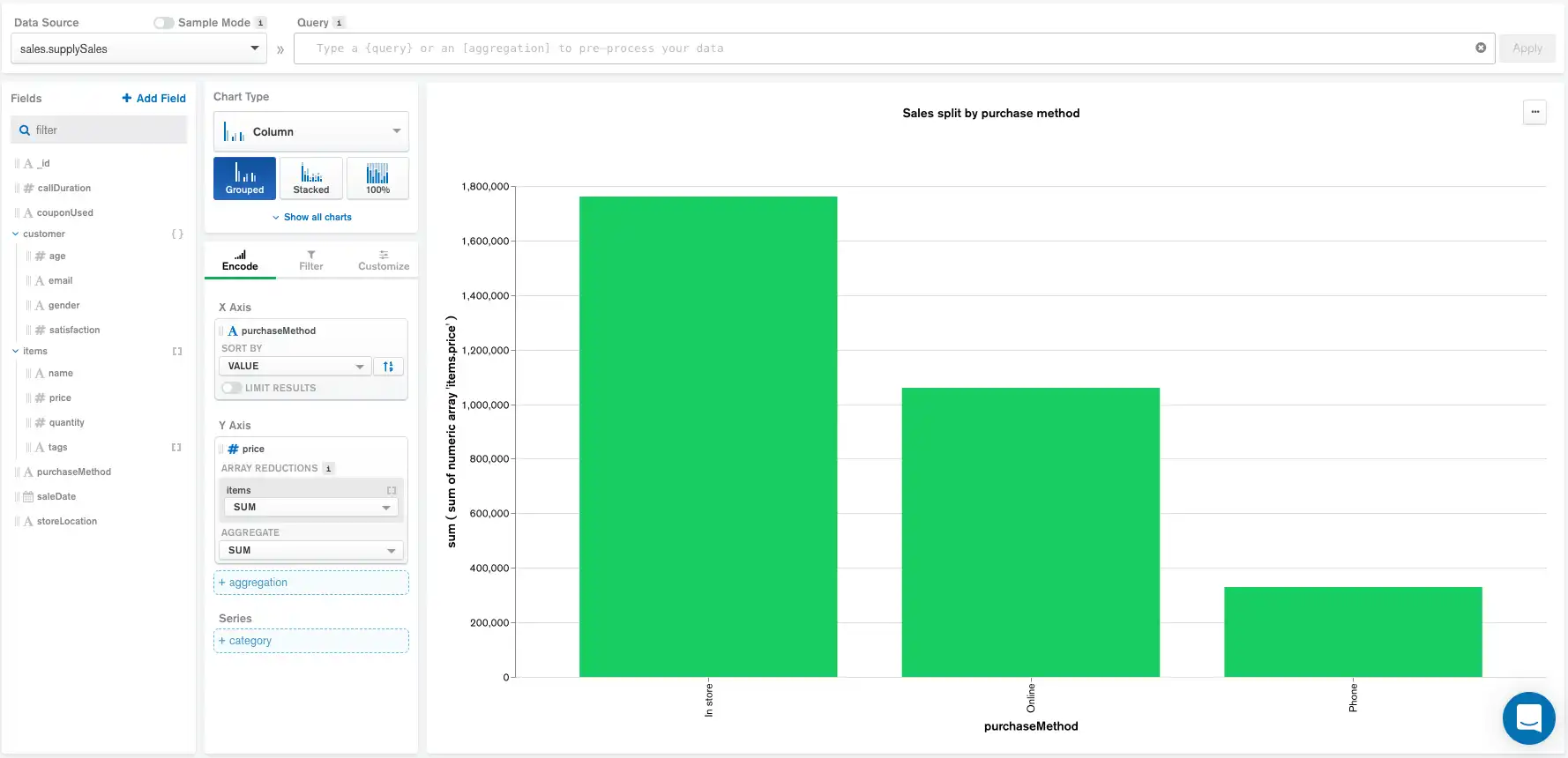
Codificación
Sin ningún Data Source pipeline, Query consultas de barra, campos calculados ni filtros añadidos en el panel Filter, Atlas Charts genera el siguiente pipeline de agregación:
1 { 2 "$addFields": { // Encoding 3 "__alias_0": { 4 "$sum": "$items.price" 5 } 6 } 7 }, 8 { 9 "$group": { 10 "_id": { 11 "__alias_1": "$purchaseMethod" 12 }, 13 "__alias_0": { 14 "$sum": "$__alias_0" 15 } 16 } 17 }, 18 { 19 "$project": { 20 "_id": 0, 21 "__alias_1": "$_id.__alias_1", 22 "__alias_0": 1 23 } 24 }, 25 { 26 "$project": { 27 "x": "$__alias_1", 28 "y": "$__alias_0", 29 "_id": 0 30 } 31 }, 32 33 { 34 "$addFields": { // Sorting 35 "__agg_sum": { 36 "$sum": [ 37 "$y" 38 ] 39 } 40 } 41 }, 42 { 43 "$sort": { 44 "__agg_sum": -1 45 } 46 }, 47 { 48 "$project": { 49 "__agg_sum": 0 50 } 51 }, 52 { 53 "$limit": 5000 54 }
En este punto, el pipeline consta de grupos del panel Encode, etapas para el orden de clasificación por defecto y el límite máximo de documentos, que está establecido en 5000 por Atlas Charts.
Agregar consultas
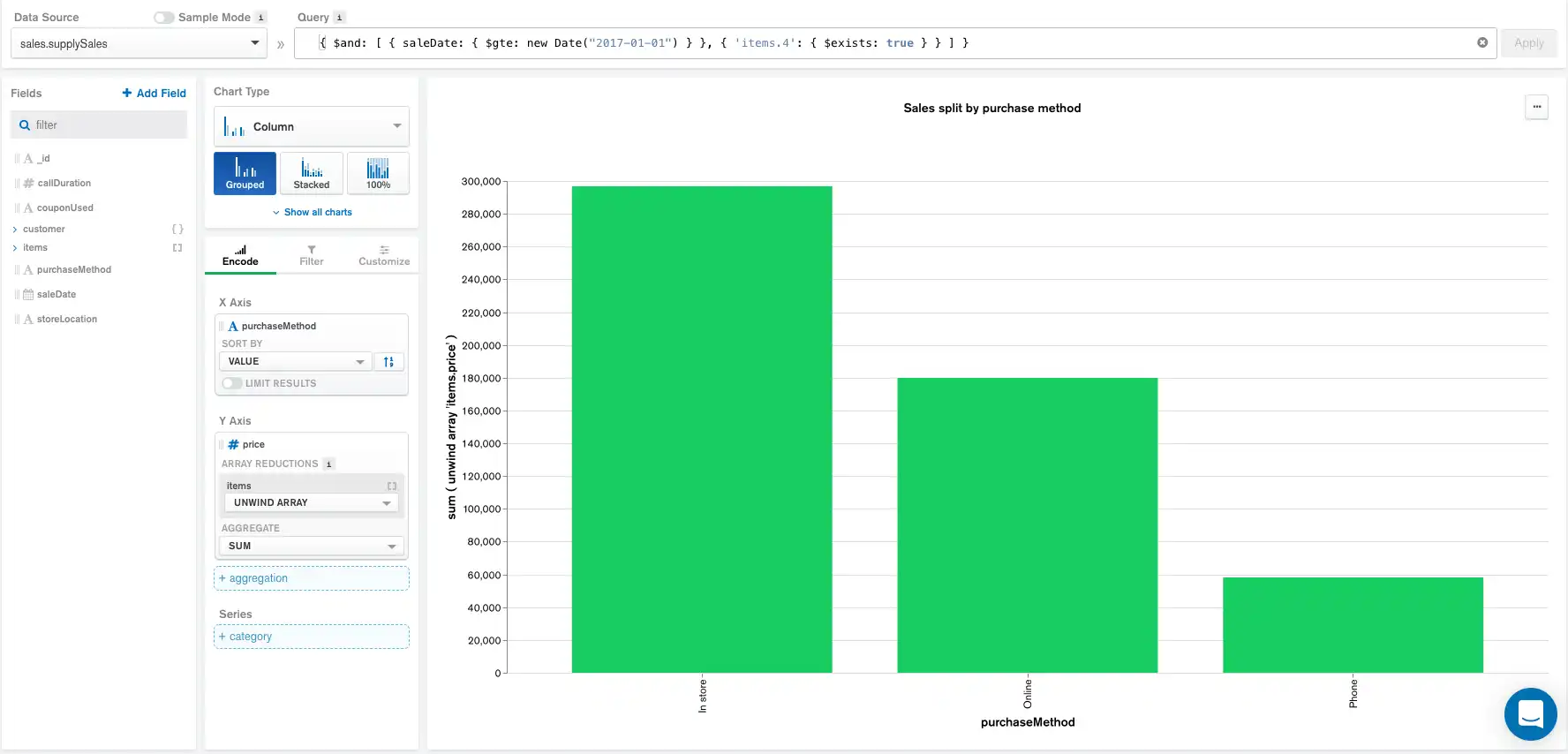
La consulta a continuación restringe los documentos mostrados solo a aquellos con un saleDate igual o más reciente que January 1, 2017 con al menos 5 elementos en el arreglo items. items es un arreglo donde cada elemento es un artículo comprado durante una venta.
query:
{ $and: [ { saleDate: { $gte: new Date("2017-01-01") } }, { 'items.4': { $exists: true } } ] }
La aplicación de la Query anterior en la barra genera la siguiente gráfica y pipeline de agregación:

pipeline de agregación:
1 { 2 "$match": { // Query 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { 21 "__alias_0": { 22 "$sum": "$items.price" 23 } 24 } 25 }, 26 { 27 "$group": { 28 "_id": { 29 "__alias_1": "$purchaseMethod" 30 }, 31 "__alias_0": { 32 "$sum": "$__alias_0" 33 } 34 } 35 }, 36 { 37 "$project": { 38 "_id": 0, 39 "__alias_1": "$_id.__alias_1", 40 "__alias_0": 1 41 } 42 }, 43 { 44 "$project": { 45 "x": "$__alias_1", 46 "y": "$__alias_0", 47 "_id": 0 48 } 49 }, 50 { 51 "$addFields": { 52 "__agg_sum": { 53 "$sum": [ 54 "$y" 55 ] 56 } 57 } 58 }, 59 { 60 "$sort": { 61 "__agg_sum": -1 62 } 63 }, 64 { 65 "$project": { 66 "__agg_sum": 0 67 } 68 }, 69 { 70 "$limit": 5000 71 }
El pipeline de agregación ahora comienza con la query aplicada, y está seguido por los grupos seleccionados en el panel Encode y el límite máximo de documentos.
Adición de campos calculados
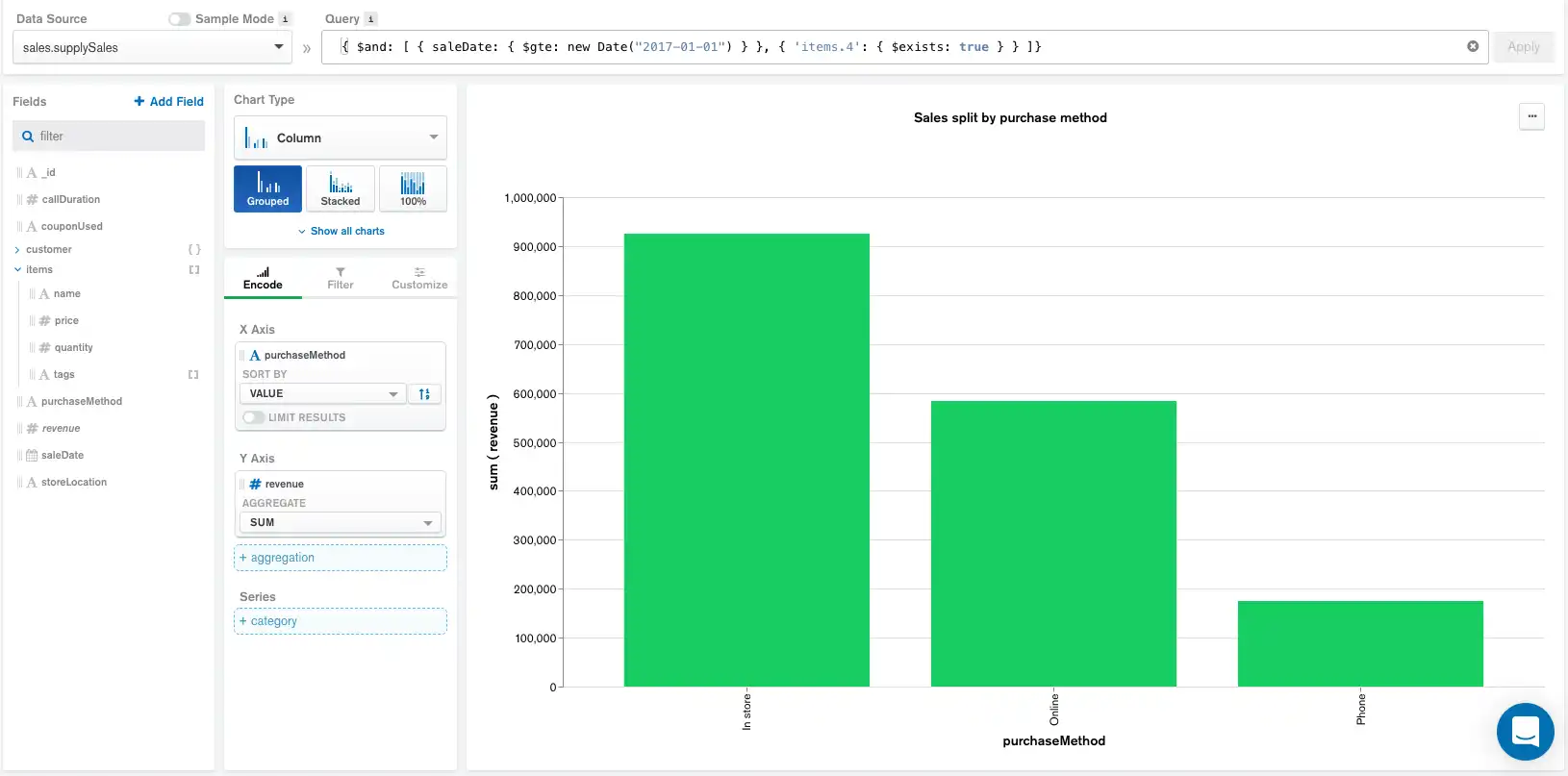
También podemos cambiar la gráfica para mostrar la ganancia total generada categorizado por método de compra. Para realizar esta tarea, crearemos un campo calculado para obtener la ganancia total multiplicando el precio por la cantidad. Al agregar este nuevo campo calculado, además de la query anterior, se produce la siguiente gráfica y pipeline:
Expresión de campo calculado:

pipeline de agregación:
1 { 2 "$match": { 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { // Calculated Field 21 "revenue": { 22 "$reduce": { 23 "input": "$items", 24 "initialValue": 0, 25 "in": { 26 "$sum": [ 27 "$$value", 28 { 29 "$multiply": [ 30 "$$this.price", 31 "$$this.quantity" 32 ] 33 } 34 ] 35 } 36 } 37 } 38 } 39 }, 40 { 41 "$group": { 42 "_id": { 43 "__alias_0": "$purchaseMethod" 44 }, 45 "__alias_1": { 46 "$sum": "$revenue" 47 } 48 } 49 }, 50 { 51 "$project": { 52 "_id": 0, 53 "__alias_0": "$_id.__alias_0", 54 "__alias_1": 1 55 } 56 }, 57 { 58 "$project": { 59 "x": "$__alias_0", 60 "y": "$__alias_1", 61 "_id": 0 62 } 63 }, 64 { 65 "$addFields": { 66 "__agg_sum": { 67 "$sum": [ 68 "$y" 69 ] 70 } 71 } 72 }, 73 { 74 "$sort": { 75 "__agg_sum": -1 76 } 77 }, 78 { 79 "$project": { 80 "__agg_sum": 0 81 } 82 }, 83 { 84 "$limit": 5000 85 }
La canalización actualizada ahora incluye el campo calculado justo debajo de la consulta aplicada en la barra Query mientras que el orden del resto de los componentes permanece sin cambios.
Agregar filtros
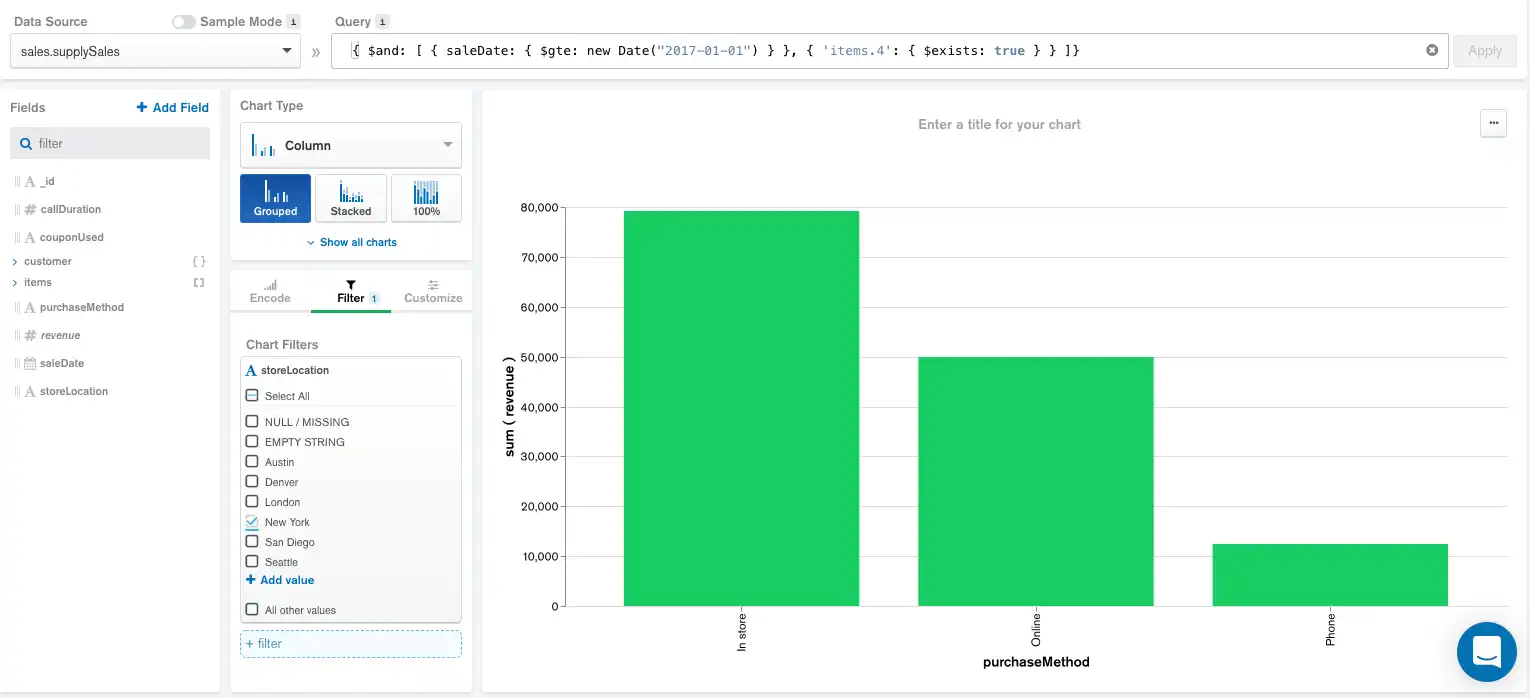
Esta gráfica se puede refinar aún más añadiendo un filtro en el panel Filter para seleccionar solo las ventas en tienda realizadas en la ubicación de Nueva York. Agregar este filtro produce la siguiente gráfica y pipeline de agregación:

pipeline de agregación:
1 { 2 "$match": { 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { 21 "revenue": { 22 "$reduce": { 23 "input": "$items", 24 "initialValue": 0, 25 "in": { 26 "$sum": [ 27 "$$value", 28 { 29 "$multiply": [ 30 "$$this.price", 31 "$$this.quantity" 32 ] 33 } 34 ] 35 } 36 } 37 } 38 } 39 }, 40 { 41 "$match": { // Filter 42 "storeLocation": { 43 "$in": [ 44 "New York" 45 ] 46 } 47 } 48 }, 49 { 50 "$group": { 51 "_id": { 52 "__alias_0": "$purchaseMethod" 53 }, 54 "__alias_1": { 55 "$sum": "$revenue" 56 } 57 } 58 }, 59 { 60 "$project": { 61 "_id": 0, 62 "__alias_0": "$_id.__alias_0", 63 "__alias_1": 1 64 } 65 }, 66 { 67 "$project": { 68 "x": "$__alias_0", 69 "y": "$__alias_1", 70 "_id": 0 71 } 72 }, 73 { 74 "$addFields": { 75 "__agg_sum": { 76 "$sum": [ 77 "$y" 78 ] 79 } 80 } 81 }, 82 { 83 "$sort": { 84 "__agg_sum": -1 85 } 86 }, 87 { 88 "$project": { 89 "__agg_sum": 0 90 } 91 }, 92 { 93 "$limit": 5000 94 }
El pipeline ahora incluye el filtro storeLocation justo debajo del campo calculado, mientras que el orden del resto de los componentes sigue siendo el mismo.