Esta sección contiene las siguientes páginas, que proporcionan información sobre nuestro punto de referencia de rendimiento de búsqueda vectorial de MongoDB y cómo se puede utilizar para probar, evaluar y mejorar nuestro propio rendimiento de búsqueda vectorial:
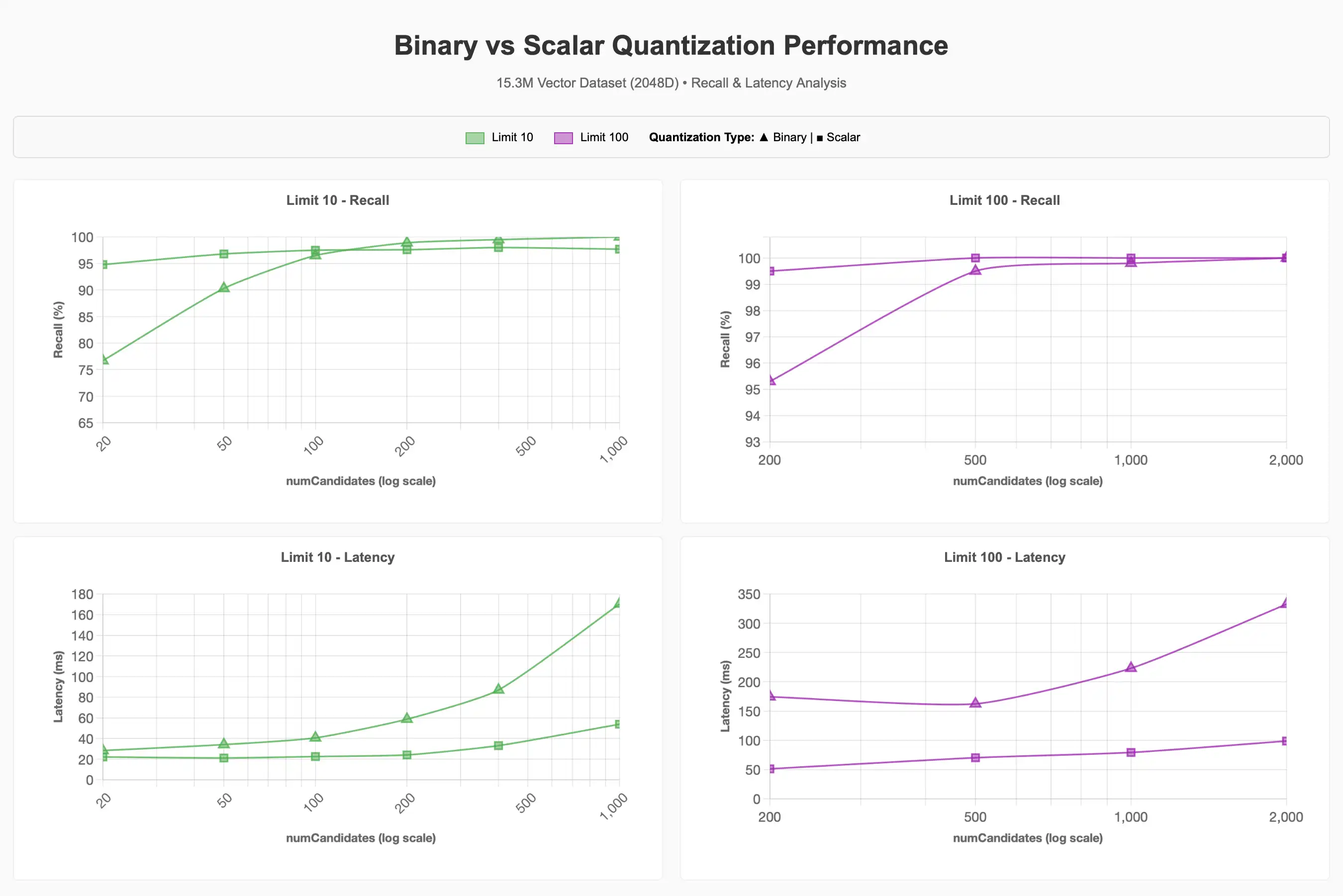
Para ver la gráfica completa, consulte la Artefacto Claude.
Cómo usar este benchmark
El objetivo primario de estas páginas es reducir significativamente la fricción para la primera prueba de vectores a escala (>10M vectores) al evaluar el rendimiento de la búsqueda vectorial de MongoDB.
Estas páginas proporcionan un conjunto de configuraciones iniciales (dimensionalidad del modelo de incrustación, régimen de cuantificación, numCandidates selección, criterios de filtrado, configuración de Search nodo) que puedes usar para ejecutar pruebas con confianza. Es posible que debas modificar tu configuración según el conjunto de datos y los patrones de query relevantes para tu caso de uso, ya que esto solo está pensado como punto de partida.
Recomendaciones de lectura
Al leer estas páginas, te recomendamos que te concentres en los asuntos principales más relevantes para tu caso de uso. Proporcionamos orientación para los siguientes asuntos principales: recuperación, costo y latencia/rendimiento.
Utiliza la orientación que sea más adecuada para tu caso de uso:
Lee estas secciones en el siguiente orden:
Las siguientes secciones de la Descripción general de benchmark:
Las siguientes secciones de los Resultados de benchmark:
Lee estas secciones en el siguiente orden:
Las siguientes secciones de la Descripción general de benchmark:
Las siguientes secciones de los Resultados de benchmark:
Lee estas secciones en el siguiente orden:
Sección Descripción general de benchmark completa
Sección Resultados de benchmark completa
Registro de cambios
fecha | Descripción |
|---|---|
2025-07-21 | Versión de la guía de benchmark y resultados que muestran cómo MongoDB Vector Search escala en 5.5 M. Conjunto de datos multidimensional y de 15.3 M 2048d de Amazon con incrustaciones |