Es fundamental que las empresas planifiquen la recuperación ante desastres. Recomendamos encarecidamente que prepares un plan integral de recuperación ante desastres (DR) que incluya elementos como:
Tu objetivo de punto de recuperación designado (RPO)
Tu objetivo designado de tiempo de recuperación (RTO)
Procesos automatizados que facilitan la alineación con estos objetivos
Utiliza las recomendaciones de esta página para prepararte y responder a los desastres.
Para obtener más información sobre las configuraciones proactivas de alta disponibilidad que pueden ayudar con la recuperación ante desastres, consulte Recomendaciones para la alta disponibilidad de Atlas.
Funcionalidades para la recuperación ante desastres de Atlas
Para obtener más información sobre las características de Atlas que admiten la recuperación ante desastres, consulte las siguientes páginas en el Centro de arquitectura de Atlas:
Recomendaciones para la recuperación ante desastres de Atlas
Utiliza las siguientes recomendaciones para la recuperación ante desastres: Plan DR para su organización. Estas recomendaciones proporcionan información sobre los pasos a seguir en evento de un desastre.
Es imperativo que pruebes regularmente los planes en esta sección (idealmente cada trimestre, pero al menos cada semestre). Realizar pruebas frecuentes ayuda al equipo de gestión de base de datos Empresarial (EDM) a estar preparado para responder ante desastres, además de ayudar a mantener actualizadas las instrucciones.
Es posible que algunas pruebas de recuperación ante desastres requieran acciones que no pueden ser realizadas por los usuarios de EDM. En estos casos, abra un caso de soporte con el fin de realizar interrupciones del servicio artificiales al menos una semana antes de la fecha en que planea llevar a cabo un ejercicio de prueba.
El siguiente diagrama compara diferentes escenarios de recuperación ante desastres y configuraciones de implementación. La tabla muestra los beneficios relativos del Objetivo de Tiempo de Recuperación (RTO) y del Objetivo de Punto de Recuperación (RPO) frente a la complejidad de la implementación y el costo para cada configuración. Cabe señalar que las elecciones del set de réplicas (conmutación automática por error) no provocan pérdida de datos, mientras que la recuperación a partir de copias de seguridad podría implicar cierta pérdida de datos dependiendo de la frecuencia de la copia de seguridad. "Fallo del plano de control" se refiere a problemas con la infraestructura de gestión de Atlas, en lugar de con los nodos de datos.

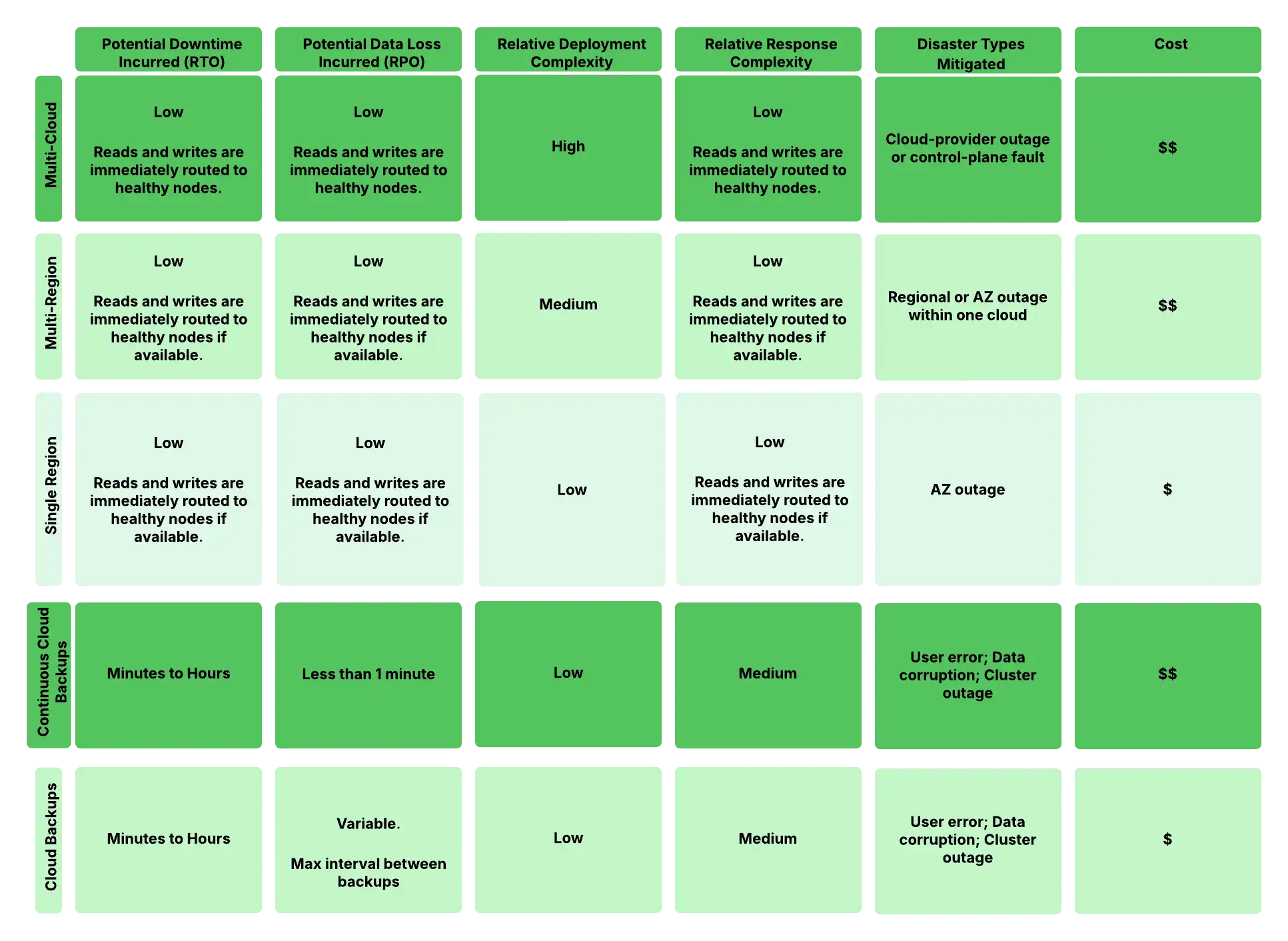
Figura 1. Complejidad de la configuración de recuperación ante desastres y compensaciones RTO/RPO.
Cada proveedor de nube en el que puedes implementar clústeres de Atlas proporciona redundancia de datos predeterminada que ayuda a mitigar cualquier interrupciones del servicio:
AWS almacena objetos en varios dispositivos en un mínimo de tres Zonas de Disponibilidad en una Región de AWS.
Microsoft Azure utiliza el almacenamiento localmente redundante (LRS), que replica tus datos tres veces dentro de un solo centro de datos en la región seleccionada.
Google Cloud distribuye tus datos a través de múltiples zonas en la región de copia de seguridad.
Para mejorar tu recuperación ante desastres, puedes configurar Atlas para crear copias automáticas de tus snapshots y oplogs en otras regiones. Esto garantiza que, incluso si la región primaria experimenta una Interrupción del servicio, el clúster pueda restaurar usando copias de snapshots almacenadas en otras regiones.
Atlas optimiza las velocidades de restauración seleccionando la opción más eficiente en función de la disponibilidad regional, empleando copias de snapshots si se está restaurando en una región donde ya existen dichas copias. Además, si la snapshot original no está disponible debido a una Interrupción del servicio regional, Atlas realizará la restauración utilizando la copia de snapshot disponible más cercana, minimizando el tiempo de inactividad y mejorando la resiliencia de la recuperación. Para aprender más, consulta Exportar snapshot de copias de seguridad en la nube.
Las implementaciones multirregionales y multicloud proporcionan capacidades mejoradas de recuperación ante desastres al distribuir los nodos de tu clúster en diferentes ubicaciones geográficas o proveedores en la nube. Esta distribución ayuda a garantizar que, si una región o proveedor de nube experimenta una Interrupción del servicio, tu aplicación pueda seguir funcionando utilizando nodos en ubicaciones no afectadas.
Cuando configuras implementaciones en multiregión o en multi-nube, asegúrate de que tu estrategia de copia de seguridad tenga en cuenta la naturaleza distribuida de tu implementación, incluyendo la configuración de períodos adecuados de retención de copias de seguridad basados en tus requisitos específicos de recuperación.
Todas las recomendaciones paradigmáticas de implementación
Las siguientes recomendaciones se aplican a todos los paradigmas de implementación.
Esta sección cubre los siguientes procedimientos de recuperación ante desastres:
Interrupción del servicio de Nodo Único
Si un solo nodo en su conjunto de réplicas falla debido a una interrupción regional parcial, su implementación debería seguir estando disponible, suponiendo que haya seguido las mejores prácticas. Si está leyendo desde secundarios, podría experimentar un rendimiento degradado o posibles interrupciones del servicio en el evento de que un secundario falle, debido a la mayor carga en el clúster que queda sub-provisionado.
Puede probar una interrupción del nodo principal en Atlas mediante la función Probar conmutación por error principal de la interfaz de usuario de Atlas o el punto final de la API de administración de Atlas de Probar conmutación por error.
Interrupción del servicio regional
En caso de una interrupción regional, los clústeres multirregionales realizarán automáticamente una elección e identificarán un nuevo nodo principal si es necesario. Este cambio de topología se comunicará automáticamente a la aplicación, lo que le permitirá tomar las medidas correctivas necesarias. Para mantener la disponibilidad de la aplicación en caso de una interrupción regional, esta también debe implementarse con una topología multirregional. Este requisito se extiende a cualquier servicio de terceros con el que se integre la aplicación. Para obtener más información, consulte el Paradigma de Implementación Multirregional.
Si una interrupción en una sola región o en varias regiones degrada el estado de su clúster, siga estos pasos:
Determinar qué regiones es poco probable que se vean afectadas por la Interrupción del servicio actual
Dependiendo de la causa de la interrupción, es posible que próximamente otras regiones también experimenten interrupciones no programadas. Por ejemplo, si las interrupciones se debieron a un desastre natural en la costa este de Estados Unidos, debería evitar estas regiones por si surgen problemas adicionales.
Añade nodos a las regiones que identificaste
Agregue la cantidad necesaria de nodos para un estado normal en regiones que probablemente no se vean afectadas por la causa de la Interrupción del servicio.
Para reconfigurar un conjunto de réplicas durante una interrupción agregando regiones o nodos, consulte Reconfigurar un conjunto de réplicas durante una interrupción regional.
se puede probar una interrupción del servicio de región en Atlas utilizando la funcionalidad Simular Interrupción del servicio de la Interfaz de Usuario de Atlas o el endpoint de la API de administración de Atlas Iniciar una simulación de Interrupción del servicio.
Interrupción del proveedor de la nube
Con clústeres multinube, puede seleccionar nodos seleccionables entre proveedores de nube para mantener una alta disponibilidad. Si el proveedor donde está implementado su nodo principal deja de estar disponible, Atlas selecciona automáticamente nuevos nodos principales para garantizar la continuidad del funcionamiento. Por ejemplo, puede crear nodos seleccionables en AWS, Google Cloud y Microsoft Azure para garantizar que, si un proveedor de nube sufre una interrupción, un nodo seleccionable de otro proveedor pueda asumir automáticamente el control como nodo principal de su clúster. Para obtener más información, consulte Paradigma de Implementación Multinube.
La mayoría de los clústeres Atlas multirregionales se recuperan automáticamente de una interrupción en una sola región. Para obtener más información, consulte la sección Alta disponibilidad y la página Implementación multirregional. En caso de que las interrupciones regionales hayan afectado a la mayoría de los nodos, debe determinar cuántos nodos más necesita agregar para que la mayoría de los nodos funcionen correctamente.
En el muy improbable evento de que un proveedor de nube completo no esté disponible, sigue estos pasos para restaurar tu implementación en linea:
Identifique el proveedor de nube alternativo en el que desea implementar su nuevo clúster
Para obtener una lista de proveedores de nube e información, consulta Proveedores de nube.
Si almacena copias de seguridad en varios proveedores de la nube, como una interrupción del servicio del proveedor de la nube implica que cualquier copia de seguridad almacenada en el proveedor de nube primario es necesariamente inaccesible, encuentre la snapshot más reciente disponible tomada del clúster antes de que comenzara la interrupción del servicio
Para saber cómo ver sus instantáneas de respaldo, consulte Ver10instantáneas de respaldo M +.
Crear un nuevo clúster con el proveedor de nube alternativo
Tu nuevo clúster debe tener una topología idéntica al clúster original.
Alternativamente, en lugar de crear un clúster completamente nuevo, también puedes agregar nuevos nodos alojados por un proveedor de nube alternativo al clúster existente.
Restaura la snapshot más reciente del paso anterior en el nuevo clúster
Para aprender a restaurar tu snapshot, consulta Restaurar tu clúster.
Transfiere cualquier aplicación que se conecte al clúster antiguo al clúster recién creado
Para encontrar la nueva cadena de conexión,consulte Conectarse mediante bibliotecas de cliente. Revise la pila de aplicaciones, ya que probablemente necesite volver a implementarla en el nuevo proveedor de nube.
Interrupción del servicio de Atlas
En el evento altamente improbable de que el plano de control de Atlas y la Interfaz de Usuario de Atlas no estén disponibles, tu clúster seguirá estando disponible y accesible. Para aprender más, consulta Fiabilidad de la plataforma. Abre un ticket de soporte de alta prioridad para investigar esto más a fondo.
Problemas de capacidad de recursos
Los problemas de capacidad de recursos computacionales (como espacio en disco, RAM o CPU) pueden deberse a una mala planificación o a tráfico inesperado en la base de datos. Este comportamiento podría no ser el resultado de un desastre.
Si un recurso computacional alcanza la cantidad máxima asignada y causa un desastre, siga estos pasos:
Identifique qué recurso computacional está maximizado mediante el Panel de rendimiento en tiempo real o las métricas Atlas
Para ver la utilización de sus recursos en la interfaz de usuario de Atlas, consulte Supervisar el rendimiento en tiempo real.
Para ver las métricas con la API de administración de Atlas, consulta Supervisión y registros.
Asignar los recursos necesarios
Ten en cuenta que Atlas realizará este cambio de forma paulatina, por lo que no debería tener ningún impacto importante en tus aplicaciones.
Para aprender a asignar más recursos, consulta Edita un clúster.
Fallo de recurso
Importante
Esta es una solución temporal destinada a acortar el tiempo de inactividad general del sistema. Una vez que el problema subyacente se resuelva, fusione los datos del clúster recién creado en el clúster original y dirija todas las aplicaciones de nuevo al clúster original.
Si un recurso computacional falla y causa que el clúster se vuelva inaccesible, sigue estos pasos:
Abre un ticket de soportede alta prioridad
Restaura la copia de seguridad más reciente en el clúster recién creado
Para aprender a restaurar tu snapshot, consulta Restaurar tu clúster.
Eliminación de datos de producción
Los datos de producción podrían eliminarse accidentalmente debido a un error humano o a un fallo en la aplicación basada en la base de datos. Si el clúster se eliminara accidentalmente, Atlas podría conservar el volumen temporalmente.
Si el contenido de una colección o base de datos ha sido eliminado, sigue estos pasos para restaurar tus datos:
Cree una copia del estado actual de la colección o base de datos, si contiene algún dato
Puede utilizar mongoexport para crear una copia.
Restaurar sus datos
Si la eliminación ocurrió en las últimas 72 horas y configuraste la copia de seguridad continua, utiliza la restauración Point-in-Time (PIT) para restaurar desde el punto en el tiempo justo antes de que ocurriera la eliminación.
Si la eliminación no ocurrió en las últimas 72 horas, restaurar la copia de seguridad más reciente de antes de que ocurriera la eliminación en el clúster.
Para obtener más información, consulta Restaurar tu clúster.
Si creaste una copia de tus datos, importa los nuevos datos que exportaste
Puedes usar mongoimport con modo inserción para importar tus datos y asegurarte de que cualquier dato modificado o agregado se refleje correctamente en la colección o base de datos.
Error del controlador
Si un controlador falla, siga estos pasos:
Identifique la versión de controlador adecuada para resolver el problema
Si está utilizando un controlador obsoleto, compruebe si la actualización a una versión más reciente resuelve el problema. La mayoría de los problemas de los controladores se solucionan en versiones más recientes.
Si has actualizado recientemente tu driver y sospechas que la nueva versión introdujo el problema, considera volver a la versión anterior que funcionaba.
Corrupción de datos
Importante
Esta es una solución temporal destinada a acortar el tiempo de inactividad general del sistema. Una vez que el problema subyacente se resuelva, fusione los datos del clúster recién creado en el clúster original y dirija todas las aplicaciones de nuevo al clúster original.
Si sus datos subyacentes se corrompen, siga estos pasos:
Abre un ticket de soportede alta prioridad
Restaura la copia de seguridad más reciente en el clúster recién creado
Para aprender a restaurar tu snapshot, consulta Restaurar tu clúster.